用户画像之Spark ML实现
1 Spark ML简单介绍
Spark ML是面向DataFrame编程的。Spark的核心开发是基于RDD(弹性分布式数据集),但是RDD,但是RDD的处理并不是非常灵活,如果要做一些结构化的处理,将RDD转换成DataFrame,DataFrame实际上就是行对象的RDD+schema,类似于原本的文本数据,加上schema,做一下结构的转换就变成数据库里面的表,表是有元数据的,有字段有类型。所以DataFrame处理起来更加灵活。
要进行机器学习是有一系列的流程,通常离线的处理现有一组数据集,然后进行预处理特征工程,完成之后分成训练集合测试集,基于训练集训练模型,然后选择算法,进行评估..这是可以形成一个管道的,整体是一个DAG有向无环图。
其实整个进行模型算法训练的过程就是一个管道,管道中就会有各种各样的组件,这些组件总体来说可以分成两类,①第一个是Transformers:transform()用于转换,把一个DataFrame转换为另一个DataFrame,如把原本的数据集拆分成测试集,那就是DataFrame的转换,像分词,抽样,模型的测试都是非常常见的转换操作,②第二种类型就是Estimators:fit()应用在DF上生成一个转换器算法,Estimators评估器,用到的函数是fit(),Estimators是为了生成一个转换器,在机器学习中会用到一些算法,需要去建模,根据训练集得到模型,模型本质上就是转换器,进行预测是用的这个模型进行预测,所以转换是基于这个模型进行预测,所以转换就是基于这个模型的转换器转换时他的实例来进行转换。
2 Spark ML的工作流程
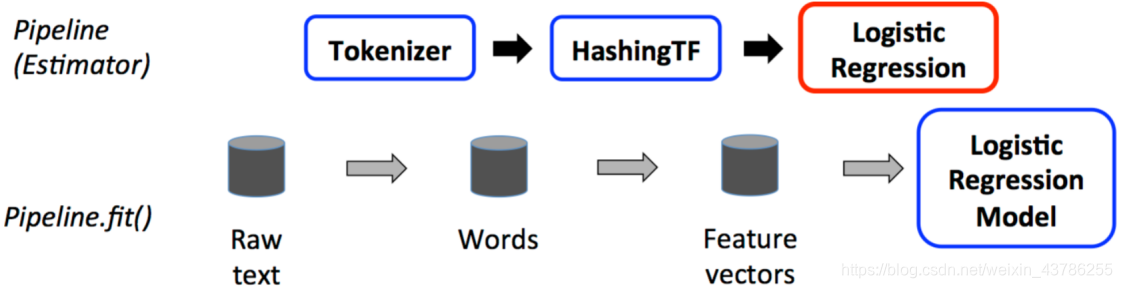
首先进行预处理,包括模型训练的整个过程是一个管道pipline,这个pipline的目的是为了得到一个Estimator,即得到一个模型,假如说用逻辑回归,输入的数据是普通的文本,首先进行Toknizer分词,分完次后计算他的词频,这两个本质上否是transform的操作,接下来就要创建一个逻辑回归的实例,本质上就是一个Estimator,得到一个转换器。

模型有了接下来就要做预测,不管是训练集还是测试集,都是要进行分词,计算词频的,这个piplineModel整个都是transform操作,这个模型逻辑回归就是上一步通过训练的到的模型。
参数是所有转换器和评估器共享的一个公共api,参数名Param是一个参数,可以通过setter单独定义;也可以通过ParamMap定义一个参数的集合(parameter,value),传递参数的两种方式:①通过setter为实例设置参数②传递ParamMap给fit或者transform方法
3 Estimator,Transformer,Param使用案例
(1)准备带标签和特征的数据
(2)创建逻辑回归的评估器
(3)使用setter方法设置参数
(4)使用存储在lr中的参数来训练一个模型
(5)使用ParamMap选择指定的参数
(6)准备测试数据
(7)预测结果
代码具体实现
(1)准备带标签和特征的数据
任何应用首先要把需要的类通过import引入,性别预测是分类问题,选择逻辑回归
import org.apache.spark.ml.classification.LogisticRegression
import org.apache.spark.ml.param.ParamMap
import org.apache.spark.ml.linalg.{Vector,Vectors}
import org.apache.spark.sql.Row定义一个初始的DataFrame,通过sqlContext创建,用Seq序列的方式创建一个集合,第一个参数是标签即目标值,后面的为特征,
val sqlContext=new org.apache.spark.sql.SQLContext(sc)
val training = sqlContext.createDataFrame(Seq(
(1.0, Vectors.dense(1.0,2.1,1.1)),
(0.0, Vectors.dense(3.0,2.0,-2.0)),
(0.0, Vectors.dense(3.0,0.3,1.0)),
(1.0, Vectors.dense(1.0,1.2,-1.5))
)).toDF("label","features")(2)创建逻辑回归的评估器,设置参数
val lr = new LogisticRegression()
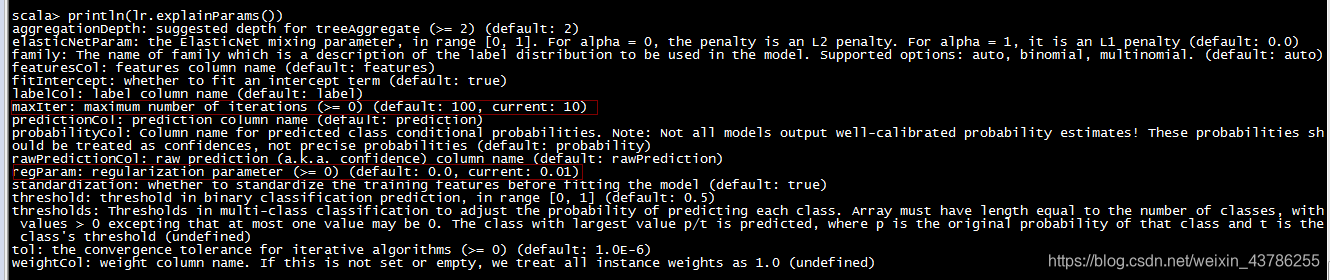
//评估器会带一些默认的参数,通过explainParams()查看
println(lr.explainParams())
//通过set方式修改迭代次数和正则化参数
lr.setMaxIter(10).setRegParam(0.01)
//定义模型,
val model1 = lr.fit(training)
//查看模型的参数
model1.parent.extractParamMap
//通过ParamMap设置参数
val paramMap = ParamMap(lr.maxIter -> 20).
put(lr.maxIter,30).
put(lr.regParam -> 0.1, lr.threshold -> 0.55)
val paramMap2 = ParamMap(lr.probabilityCol -> "myProbability")
//将两个ParamMap对象合并
val paramMapCombined = paramMap ++ paramMap2
//根据ParamMap设置的参数定义模型,
val model2 = lr.fit(training, paramMapCombined)
model2.parent.extractParamMap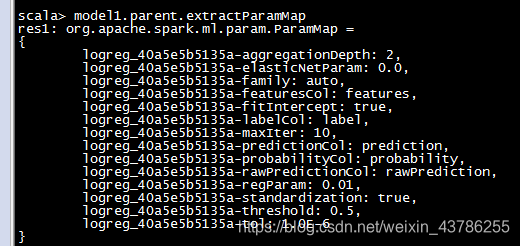
(3)准备测试数据
val test = sqlContext.createDataFrame(Seq(
(1.0, Vectors.dense(-1.2,1.8,1.3)),
(0.0, Vectors.dense(4.0,1.8,-0.1)),
(1.0, Vectors.dense(0.0,1.9,-1.5))
)).toDF("label","features")(4)预测结果
//调用模型1
model1.transform(test).select("label","features","probability","prediction").collect().foreach{case Row(label: Double, features: Vector, probability: Vector, prediction: Double) => println(s"($features, $label) -> probability=$probability, prediction=$prediction")}
4 构建Pipline和保存Pipline
步骤:
(1)准备训练的文档
(2)配置ML管道,包含三个stage:Tokenizer,HashingTF和LR
(3)安装管道到数据上
(4)保存管道到磁盘,包括安装好的和未安装好的
(5)加载管道
(6)准备测试文档
(7)预测结果
代码实现:
(1)引入需要的类
//用的数逻辑回归
import org.apache.spark.ml.classification.LogisticRegression
//因为特征工程处理的是特征向量,所以需要Vector,输入输出会用到
import org.apache.spark.ml.linalg.Vector
//行对象,为了输出美化
import org.apache.spark.sql.Row
//需要分词需要Tokenizer,需要转换计算词频需要HashingTF
import org.apache.spark.ml.feature.{Tokenizer,HashingTF}
//需要Pipeline将多个Transformers和Estimators连接起来以确定一个ML工作流程
import org.apache.spark.ml.{Pipeline,PipelineModel}(2)准备数据集
//含Sprak的为一类
val training = sqlContext.createDataFrame(Seq(
(0L, "Spark Write applications quickly in Java, Scala, Python, R, and SQL.", 1.0),
(1L, "Live and learn", 0.0),
(2L, "Spark Run workloads 100x faster.", 1.0),
(3L, "study hard and make progress every day", 0.0)
)).toDF("id","text","label")(3)定义管道中的Tokenizer,HashingTF,LR这三个组件
//创建tokenizer分词器
//setInputCol指明输入DataFrame中的哪一列是被处理的,输入参数是Dataframe中存在的列名
//setOutputCol设置新增加列的名字,及对输入的列变换后会产生一个新列,该方法设置增加新列的列名
val tokenizer = new Tokenizer().
setInputCol("text").
setOutputCol("words")
//创建hashingTF词频统计,他的inputcolumn是tokenizerget出来的
//setNumFeatures设置特征值的数量
val hashingTF = new HashingTF().
setNumFeatures(1000).
setInputCol(tokenizer.getOutputCol).
setOutputCol("features")
//创建逻辑回归对象,setMaxIter设置逻辑回归的迭代次数,setRegParam设置正则化
val lr = new LogisticRegression().
setMaxIter(10).setRegParam(0.01)(4)定义管道
//创建管道,setStages将各个计算阶段按照tokenizer,hashingTF,lr顺序,pipeline是没有安装好的管道
val pipeline = new Pipeline().
setStages(Array(tokenizer,hashingTF,lr))
//使用pipeline构建模型,model是安装好的管道
val model = pipeline.fit(training)(5)保存管道到磁盘
pipeline.save("/portrait/sparkML-LRpipeline")
model.save("/portrait/sparkML-LRmodel")(6)加载模型
//加载保存到磁盘中模型
val model2 = PipelineModel.load("/portrait/sparkML-LRmodel")(7)准备测试文档,通过回归预测,没有测试集
val test = sqlContext.createDataFrame(Seq(
(4L, "learn Spark"),
(5L, "hadoop hive"),
(6L, "bigdata hdfs a"),
(7L, "apache Spark")
)).toDF("id","text")(8)预测结果
model.transform(test).select("id","text","probability","prediction").collect().foreach{case Row(id: Long, text: String, probability: Vector, prediction: Double) => println(s"($id, $text) -> probability=$probability, prediction=$prediction")}5 通过网格参数和交叉验证进行模型调优
所谓的调优就是怎样根据数据选择好的模型,或者为整个模型整个管道选择好的参数,这里是关注参数的调优,模型就选择逻辑回归。参数调优就是给一组参数而不是一个参数,让模型自己选择。调优是基于管道整体进行调优。
(1)准备训练的文档
(2)配置ML管道,包含三个stage:Tokenizer,HashingTF和LR
(3)使用ParamGridBuilder构建一个参数网格
(4)使用CrossValidator来选择模型和参数,CrossValidator需要一个estimator,一个评估器参数集合,和一个evaluator
(5)运行交叉验证,选择最好的参数集
(6)准备测试数据
(7)预测结果
代码实现过程:
(1)引入需要的包
//用的数逻辑回归
import org.apache.spark.ml.classification.LogisticRegression
//因为特征工程处理的是特征向量,所以需要Vector,输入输出会用到
import org.apache.spark.ml.linalg.Vector
//行对象,为了输出美化
import org.apache.spark.sql.Row
//需要分词需要Tokenizer,需要转换计算词频需要HashingTF
import org.apache.spark.ml.feature.{Tokenizer,HashingTF}
//需要Pipeline将多个Transformers和Estimators连接起来以确定一个ML工作流程
import org.apache.spark.ml.{Pipeline,PipelineModel}
//因为是二元的,所以用BinaryClassificationEvaluator评估器
import org.apache.spark.ml.evaluation.BinaryClassificationEvaluator
//使用交叉校验CrossValidator,把所有参数排列组合,交叉进行校验。ParamGridBuilder参数网格
import org.apache.spark.ml.tuning.{CrossValidator,ParamGridBuilder}
//需要引入SQLContext
import org.apache.spark.sql.SQLContext(2)准备数据
val sqlContext=new SQLContext(sc)
val training = sqlContext.createDataFrame(Seq(
(0L, "Spark Write applications quickly in Java, Scala, Python, R, and SQL.", 1.0),
(1L, "Live and learn", 0.0),
(2L, "Spark Run workloads 100x faster.", 1.0),
(3L, "study hard and make progress every day", 0.0),
(4L, "Rdd Spark who", 1.0),
(5L, "good good study", 0.0),
(6L, "Spark faster", 1.0),
(7L, "day day up", 0.0),
(8L, "Spark program", 1.0),
(9L, "hello world", 0.0),
(10L, "hello Spark", 1.0),
(11L, "hi how are you", 0.0)
)).toDF("id","text","label")(3)构建管道
//创建tokenizer分词器
//setInputCol指明输入DataFrame中的哪一列是被处理的,输入参数是Dataframe中存在的列名
//setOutputCol设置新增加列的名字,及对输入的列变换后会产生一个新列,该方法设置增加新列的列名
val tokenizer = new Tokenizer().
setInputCol("text").
setOutputCol("words")
//创建hashingTF词频统计,他的inputcolumn是tokenizerget出来的
//特征值的数量网格调优
val hashingTF = new HashingTF().
setInputCol(tokenizer.getOutputCol).
setOutputCol("features")
//创建逻辑回归对象,setMaxIter设置,正则化参数网格调优
val lr = new LogisticRegression().
setMaxIter(10)
//创建管道,setStages将各个计算阶段按照tokenizer,hashingTF,lr顺序,pipeline是没有安装好的管道
val pipeline = new Pipeline().
setStages(Array(tokenizer,hashingTF,lr))(4)构建网格参数
//构建网格参数,addGrid添加网格,hashingTF.numFeatures设置hashingTF特征数量,
val paramGrid = new ParamGridBuilder().
addGrid(hashingTF.numFeatures, Array(10,100,1000)).
addGrid(lr.regParam, Array(0.1,0.01)).
build()(5)创建交叉验证CrossValidator对象
//创建CrossValidator交叉验证对象,setEstimator设置评估器,setEstimatorParamMaps设置参数集,setEvaluator设置评估器,setNumFolds创建交叉验证器,他会把训练集分成NumFolds份,实际生产要比2大
val cv = new CrossValidator().
setEstimator(pipeline).
setEstimatorParamMaps(paramGrid).
setEvaluator(new BinaryClassificationEvaluator()).
setNumFolds(2)(6)根据最优参数构建模型
//构借助参数网格,交叉验证,选择最优的参数构建模型
val cvModel = cv.fit(training)(7)添加测试数据
//添加测试集
val test = sqlContext.createDataFrame(Seq(
(12L, "learn Spark"),
(13L, "hadoop hive"),
(14L, "bigdata hdfs a"),
(15L, "apache Spark")
)).toDF("id","text")(8)预测结果
cvModel.transform(test).select("id","text","probability","prediction").collect().foreach{case Row(id: Long, text: String, probability: Vector, prediction: Double) => println(s"($id, $text) -> probability=$probability, prediction=$prediction")}
6 通过训练校验分类来调优模型
前面交叉验证是把数据分成多份,每一份把所有参数组合计算一次。而校验分类只需要把每一组参数计算一次,把数据自动分成训练集合校验集,这种方式依赖于比较大的数据量,如果数量不够生成的结果是不可信任的。不像校验验证数据集小没关系会交叉验证多次,所以即使数据量少但是计算多次,多次的结果足够评估选出最优的参数。所以TrainValidationSplit需要的数据量就要大,只会计算一次。这个例子采用线性回归。
与CrossValidator不同,TrainValidationSplit创建一个(训练,测试)数据集对。 它使用trainRatio参数将数据集分成这两个部分。 例如,trainRatio = 0.75,TrainValidationSplit将生成训练和测试数据集对,其中75%的数据用于训练,25%用于验证。
步骤:
(1)准备训练和测试数据
(2)使用ParamGridBuilder构建一个参数网格
(3)使用TrainValidationSplit来选择模型和参数,CrossValidator需要一个estimator,一个评估器参数集合,和一个evaluator
(4)运行校验分类选择最好的参数
(5)在测试数据上做测试,模型是参数组合中执行最好的一个
//使用线性回归求解
import org.apache.spark.ml.regression.LinearRegression
////因为是回归问题,所以用RegressionEvaluator回归评估器
import org.apache.spark.ml.evaluation.RegressionEvaluator
//使用ParamGridBuilder参数网格和,TrainValidationSplit
import org.apache.spark.ml.tuning.{TrainValidationSplit,ParamGridBuilder}
//需要引入SQLContext
import org.apache.spark.sql.SQLContext
val = sqlContext = new SQLContext(sc)
val data = sqlContext.read.format("libsvm").load("file:/data/sample_linear_regression_data.txt")
//randomSplits随机拆分,seed随机种子
val Array(training, test) = data.randomSplit(Array(0.75, 0.25), seed=12345)
//创建线性回归
val lr = new LinearRegression()
//elasticNetParam是Elastic net (回归)参数,取值介于0和1之间。
//fitIntercept是否允许阶段,默认是true。regParam参数定义规范化项的权重
val paramGrid = new ParamGridBuilder().
addGrid(lr.elasticNetParam, Array(0.0,0.5,1.0)).
addGrid(lr.fitIntercept).
addGrid(lr.regParam, Array(0.1,0.01)).
build()
//训练校验的比例setTrainRatio
val trainValidationSplit = new TrainValidationSplit().
setEstimator(lr).
setEstimatorParamMaps(paramGrid).
setEvaluator(new RegressionEvaluator).
setTrainRatio(0.8)
val model = trainValidationSplit.fit(training)
model.transform(test).select("features","label","prediction").show()
