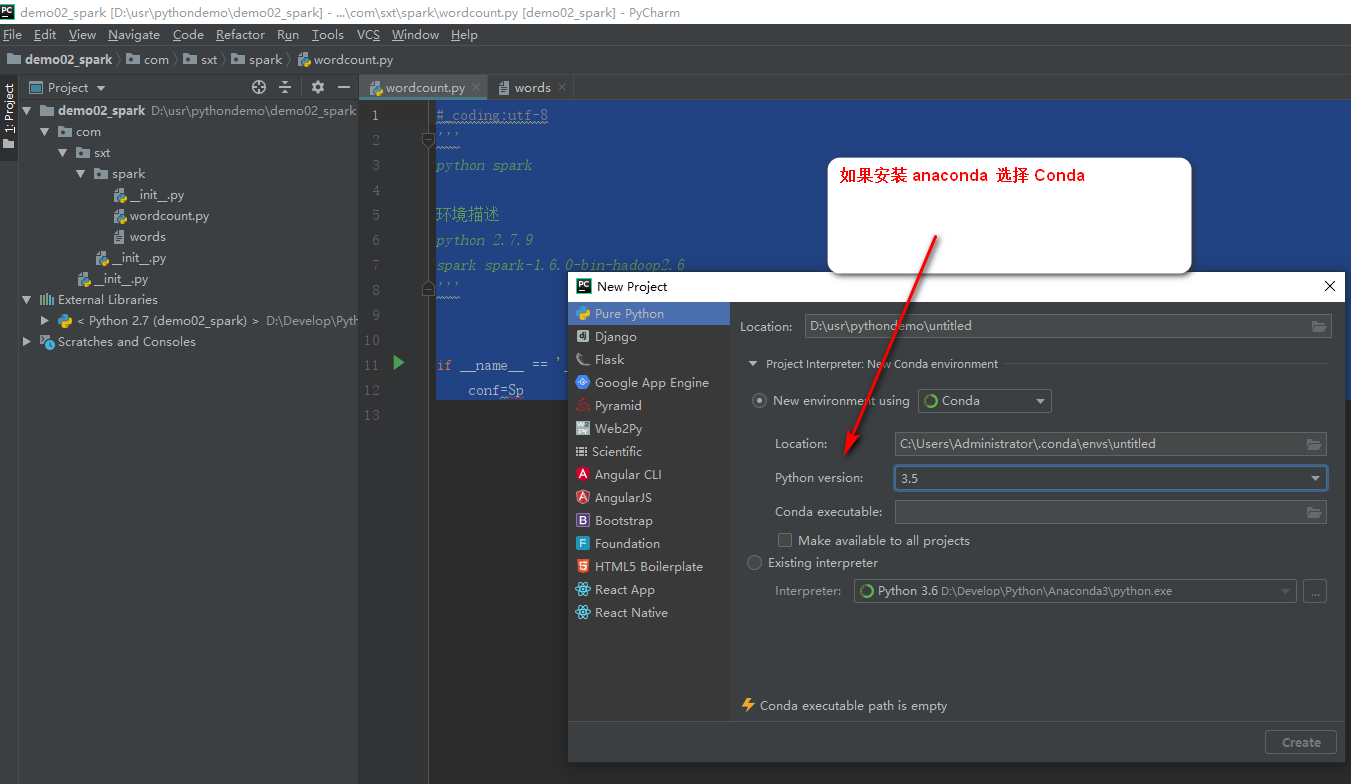
window系统 1. anaconda 或python spark环境变量 2. 配置spark home D:\Develop\spark-1.6.0-bin-hadoop2.6\spark-1.6.0-bin-hadoop2.6 3. C:\Users\Administrator>pip install py4j python for java cpython c 与java交互就是通过py4j pip uninstall py4j 4. 安装pyspark (不建议pip install ,) 为了版本对应,采用复制 D:\Develop\spark-1.6.0-bin-hadoop2.6\python\lib py4j-0.9-src pyspark 复制到 D:\Develop\Python\Anaconda3\Lib\site-packages C:\Users\Administrator>python >>> import py4j >>> import pyspark ## 不报错,则安装成功 idea 版本python插件下载
eclipse scala IDE 安装pydev插件
python spark 环境描述 python 2.7.9 spark spark-1.6.0-bin-hadoop2.6
安装pyspark (不建议pip install ,) 为了版本对应,采用复制,注意解压文件夹名称可能有两层,脱去外层pyspark @@@@@@@
D:\Develop\spark-1.6.0-bin-hadoop2.6\python\lib
py4j-0.9-src pyspark 复制到
D:\Develop\Python\Anaconda3\Lib\site-packages
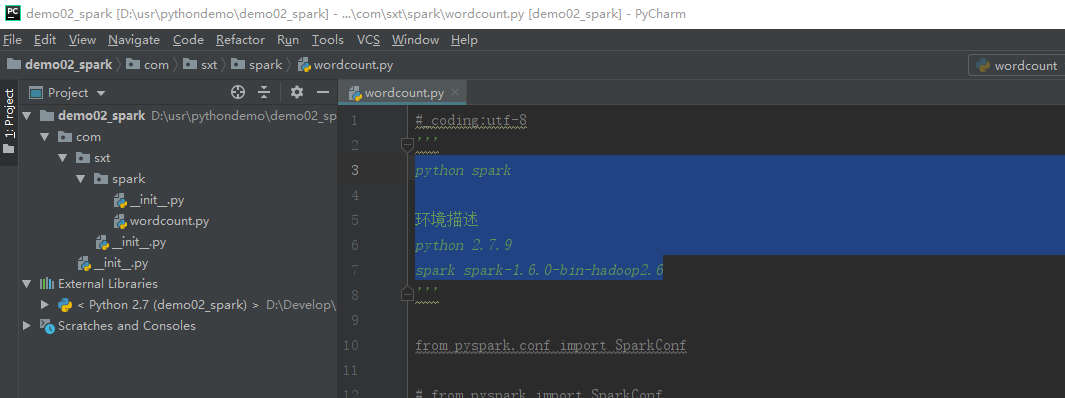
安装 pyDev pycharm 配置成功。但是不能自动提示。 scala IDE 版本太低,官网下载最新的版本,eclispe marketplace 安装老版和新版都报错。 最后:参考bing 必应搜索,【how to install pydev on eclipse scala ide】 http://www.planetofbits.com/python/how-to-install-python-pydev-plugin-in-eclipse/ 重新下载 eclipse ,下载 \PyDev 5.2.0 复制到eclipse dropins下。在eclispe marketplace中安装scala. ok.
eclipse 运行Python console 乱码(因为只支持gbk)


扫描二维码关注公众号,回复:
7421751 查看本文章

# coding:utf-8
'''
Created on 2019年10月3日
@author: Administrator
python wordcount
python print
'''
from pyspark.conf import SparkConf
from pyspark.context import SparkContext
print "hello"
print("world")
def showResult(one):
print(one)
if __name__ == '__main__':
conf = SparkConf()
conf.setMaster("local")
conf.setAppName("test")
sc=SparkContext(conf=conf)
lines = sc.textFile("./words")
words = lines.flatMap(lambda line:line.split(" "))
pairWords = words.map(lambda word:(word,1))
reduceResult=pairWords.reduceByKey(lambda v1,v2:v1+v2)
reduceResult.foreach(lambda one:showResult(one))
hello spark hello hdfs hello python hello scala hello hbase hello storm hello python hello scala hello hbase hello storm
## Demo2.py
# coding:utf-8
'''
Created on 2019年10月3日
@author: Administrator
'''
from os import sys
import random
if __name__ == '__main__':
file = sys.argv[0] ## 本文件的路径
outputPath = sys.argv[1]
print("%s,%s"%(file,outputPath)) ## 真正的参数
print(random.randint(0,255)) ## 包含0和255
pvuvdata
2019-10-01 192.168.112.101 uid123214 beijing www.taobao.com buy
2019-10-02 192.168.112.111 uid123223 beijing www.jingdong.com buy
2019-10-03 192.168.112.101 uid123214 beijing www.tencent.com login
2019-10-04 192.168.112.101 uid123214 shanghai www.taobao.com buy
2019-10-01 192.168.112.101 uid123214 guangdong www.taobao.com logout
2019-10-01 192.168.112.101 uid123214 shanghai www.taobao.com view
2019-10-02 192.168.112.111 uid123223 beijing www.jingdong.com comment
2019-10-03 192.168.112.101 uid123214 shanghai www.tencent.com login
2019-10-04 192.168.112.101 uid123214 beijing www.xiaomi.com buy
2019-10-01 192.168.112.101 uid123214 shanghai www.huawei.com buy
2019-10-03 192.168.112.101 uid123214 beijing www.tencent.com login
2019-10-04 192.168.112.101 uid123214 shanghai www.taobao.com buy
2019-10-01 192.168.112.101 uid123214 guangdong www.taobao.com logout
2019-10-01 192.168.112.101 uid123214 beijing www.taobao.com view
2019-10-02 192.168.112.111 uid123223 guangdong www.jingdong.com comment
2019-10-03 192.168.112.101 uid123214 beijing www.tencent.com login
2019-10-04 192.168.112.101 uid123214 guangdong www.xiaomi.com buy
2019-10-01 192.168.112.101 uid123214 beijing www.huawei.com buy
pvuv.py
# coding:utf-8
# import sys
# print(sys.getdefaultencoding()) ## ascii
# reload(sys)
# sys.setdefaultencoding("utf-8") ## 2.x版本
# print(sys.getdefaultencoding())
from pyspark.conf import SparkConf
from pyspark.context import SparkContext
from cProfile import label
from com.sxt.spark.wordcount import showResult
'''
Created on 2019年10月3日
@author: Administrator
'''
'''
6. PySpark统计PV,UV 部分代码
1). 统计PV,UV
2). 统计除了某个地区外的UV
3).统计每个网站最活跃的top2地区
4).统计每个网站最热门的操作
5).统计每个网站下最活跃的top3用户
'''
## 方法
def pv(lines):
pairSite = lines.map(lambda line:(line.split("\t")[4],1))
reduceResult = pairSite.reduceByKey(lambda v1,v2:v1+v2)
result = reduceResult.sortBy(lambda tp:tp[1],ascending=False)
result.foreach(lambda one:showResult(one))
def uv(lines):
distinct = lines.map(lambda line:line.split("\t")[1] +'_' + line.split("\t")[4]).distinct()
reduceResult= distinct.map(lambda distinct:(distinct.split("_")[1],1)).reduceByKey(lambda v1,v2:v1+v2)
result = reduceResult.sortBy(lambda tp:tp[1],ascending=False)
result.foreach(lambda one:showResult(one))
def uvExceptBJ(lines):
distinct = lines.filter(lambda line:line.split('\t')[3]<>'beijing').map(lambda line:line.split("\t")[1] +'_' + line.split("\t")[4]).distinct()
reduceResult= distinct.map(lambda distinct:(distinct.split("_")[1],1)).reduceByKey(lambda v1,v2:v1+v2)
result = reduceResult.sortBy(lambda tp:tp[1],ascending=False)
result.foreach(lambda one:showResult(one))
def getCurrentSiteTop2Location(one):
site = one[0]
locations = one[1]
locationDict = {}
for location in locations:
if location in locationDict:
locationDict[location] +=1
else:
locationDict[location] =1
sortedList = sorted(locationDict.items(),key=lambda kv : kv[1],reverse=True)
resultList = []
if len(sortedList) < 2:
resultList = sortedList
else:
for i in range(2):
resultList.append(sortedList[i])
return site,resultList
def getTop2Location(line):
site_locations = lines.map(lambda line:(line.split("\t")[4],line.split("\t")[3])).groupByKey()
result = site_locations.map(lambda one:getCurrentSiteTop2Location(one)).collect()
for elem in result:
print(elem)
def getSiteInfo(one):
userid = one[0]
sites = one[1]
dic = {}
for site in sites:
if site in dic:
dic[site] +=1
else:
dic[site] = 1
resultList = []
for site,count in dic.items():
resultList.append((site,(userid,count)))
return resultList
'''
如下一片程序感觉有错,我写
'''
def getCurrectSiteTop3User(one):
site = one[0]
uid_c_tuples = one[1]
top3List = ["","",""]
for uid_count in uid_c_tuples:
for i in range(len(top3List)):
if top3List[i] == "":
top3List[i] = uid_count
break
else:
if uid_count[1] > top3List[i][1]: ## 元组
for j in range(2,i,-1):
top3List[j] = top3List[j-1]
top3List[i] = uid_count
break
return site,top3List
'''
如下一片程序感觉有错,老师写
'''
def getCurSiteTop3User2(one):
site = one[0]
userid_count_Iterable = one[1]
top3List = ["","",""]
for userid_count in userid_count_Iterable:
for i in range(0,len(top3List)):
if top3List[i] == "":
top3List[i] = userid_count
break
else:
if userid_count[1]>top3List[i][1]:
for j in range(2,i,-1):
top3List[j] = top3List[j-1]
top3List[i] = userid_count
break
return site,top3List
def getTop3User(lines):
site_uid_count = lines.map(lambda line:(line.split('\t')[2],line.split("\t")[4])).groupByKey().flatMap(lambda one:getSiteInfo(one))
result = site_uid_count.groupByKey().map(lambda one:getCurrectSiteTop3User(one)).collect()
for ele in result:
print(ele)
if __name__ == '__main__':
# conf = SparkConf().setMaster("local").setAppName("test")
# sc = SparkContext()
# lines = sc.textFile("./pvuvdata")
# # pv(lines)
# # uv(lines)
# # uvExceptBJ(lines)
# # getTop2Location(lines)
#
# getTop3User(lines)
res = getCurrectSiteTop3User(("baidu",[('A',12),('B',5),('C',12),('D',1),('E',21),('F',20)]))
print(res)
res2 = getCurSiteTop3User2(("baidu",[('A',12),('B',5),('C',12),('D',1),('E',21),('F',20)]))
print(res)
python pycharm anaconda 版本切换为3.5