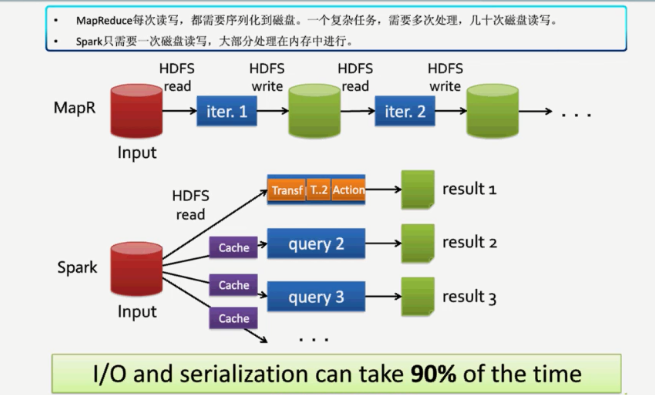


spark ml是基于spark 2.0环境,以DataFrame为数据处理单元。spark经历了三代,依次如下。DataFrame是个列式数据集,结构化的数据集,RDD是非结构化的,第二代比第一代因结构化数据计算的性能都要优秀些。第三代的dataset已经序列化的
数据,是encoding,已经转化为二进制,也就是spark自己已实现编码和反编码。因此,其性能因不需要要第三方结构来处理数据得到进一步提升。RDD会逐步退出历史舞台。
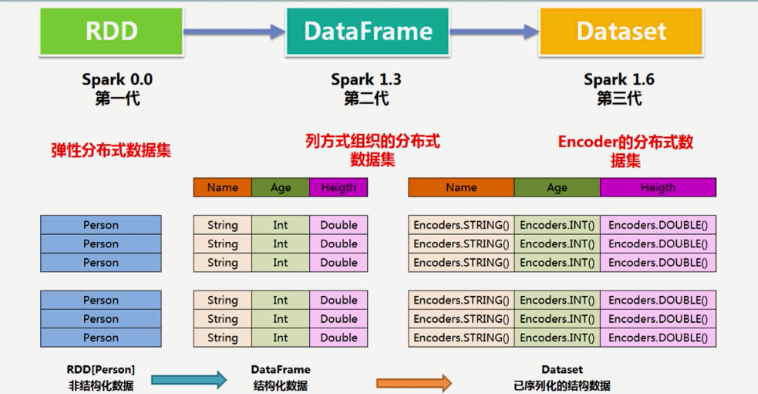


DataFrame按列处理数据,不是面向对象风格,不进行安全检查,只有在运行的时候才进行安全检查。

DataSet必须明确每一个列,是个强类型,在编译的时候进行类型检查。用case class定义。




RDD的创建

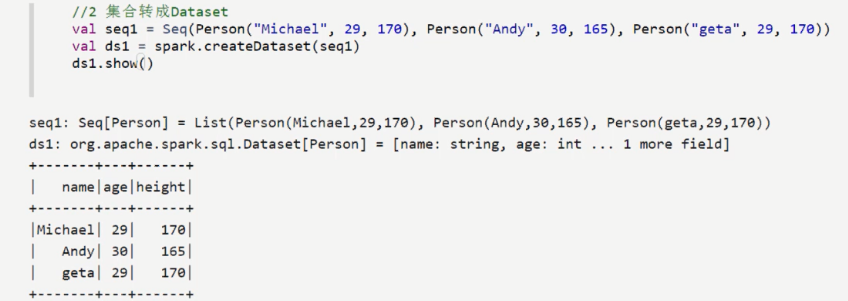
创建示例
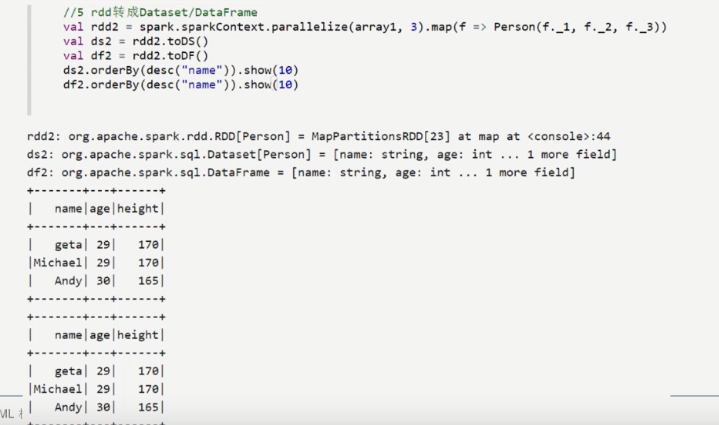
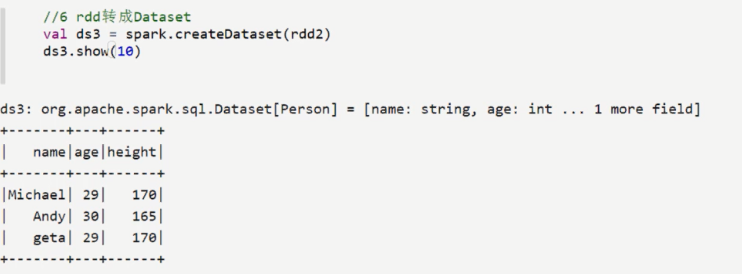
RDD转化为DataFram

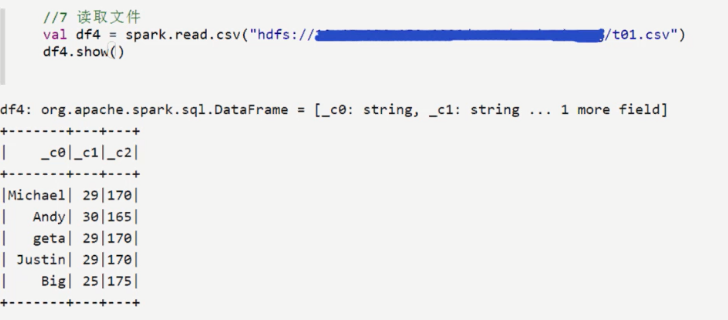
如果出现错误,可以从checkpoint恢复,不需要重新跑一边程序。
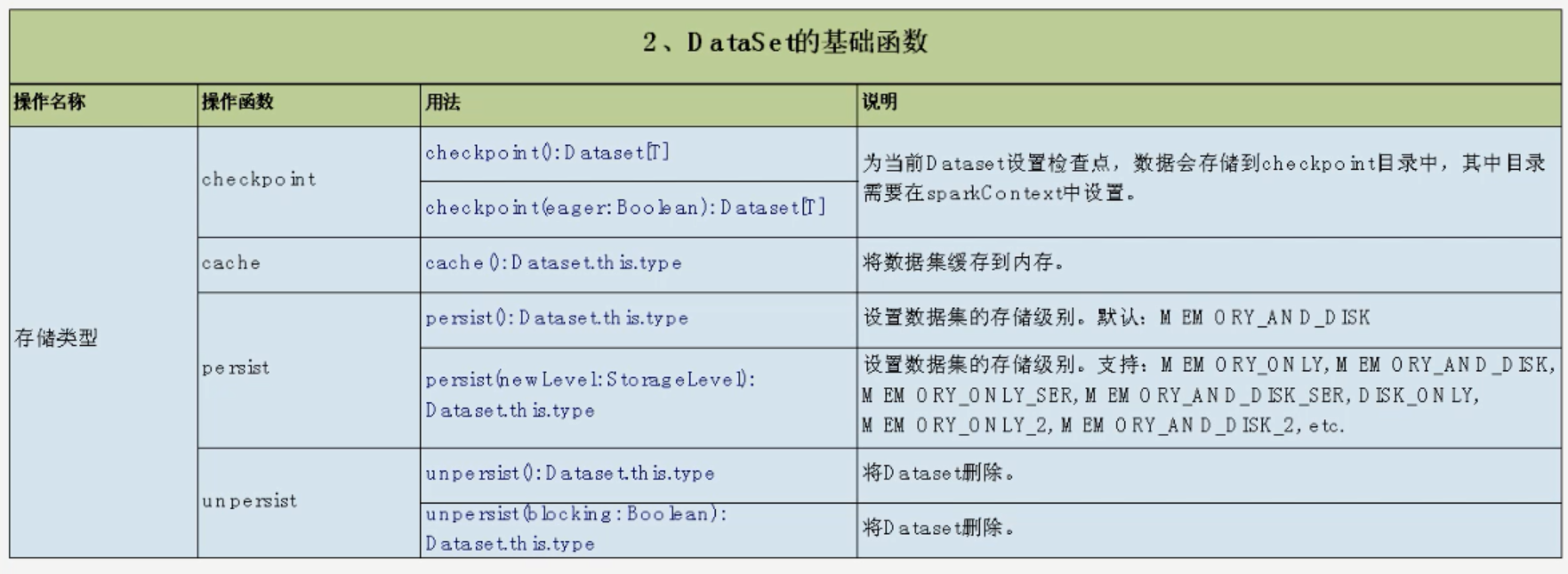
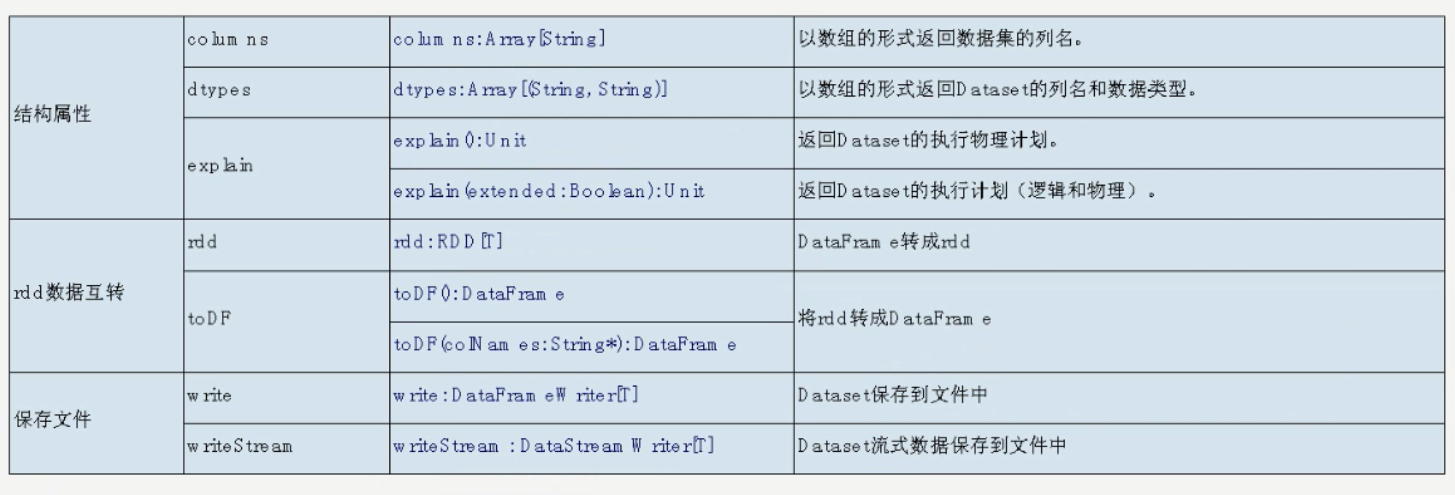
转化为临时sql表



转化为临时表可以进行sql操作。
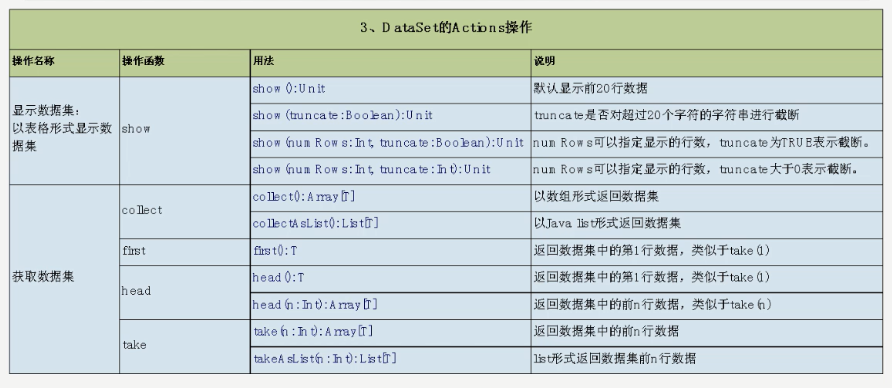

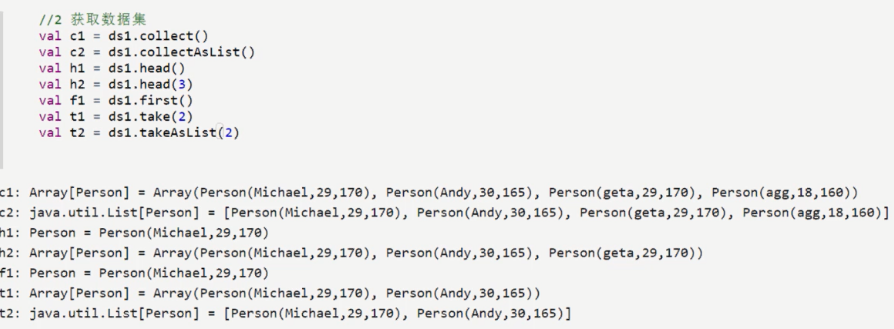

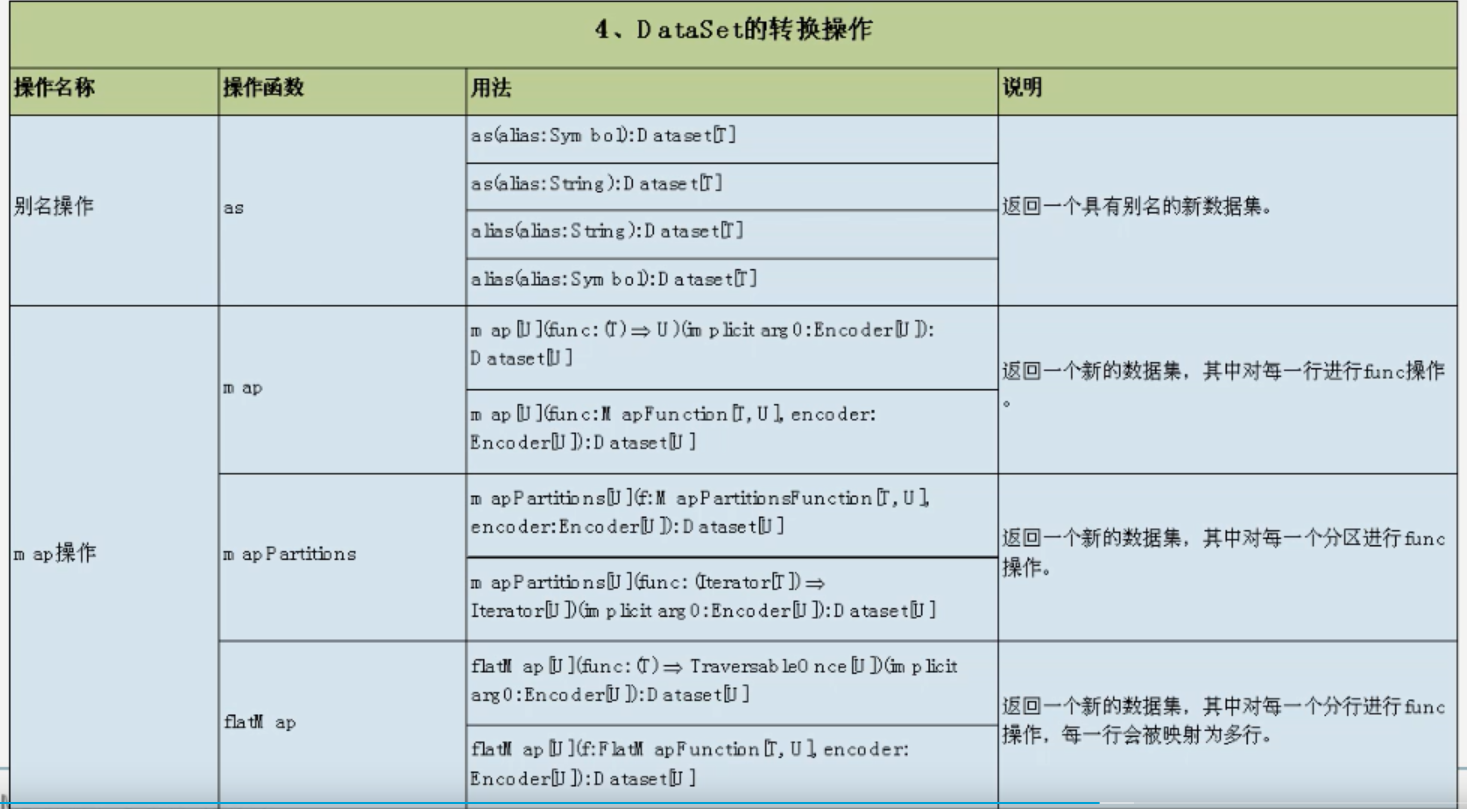
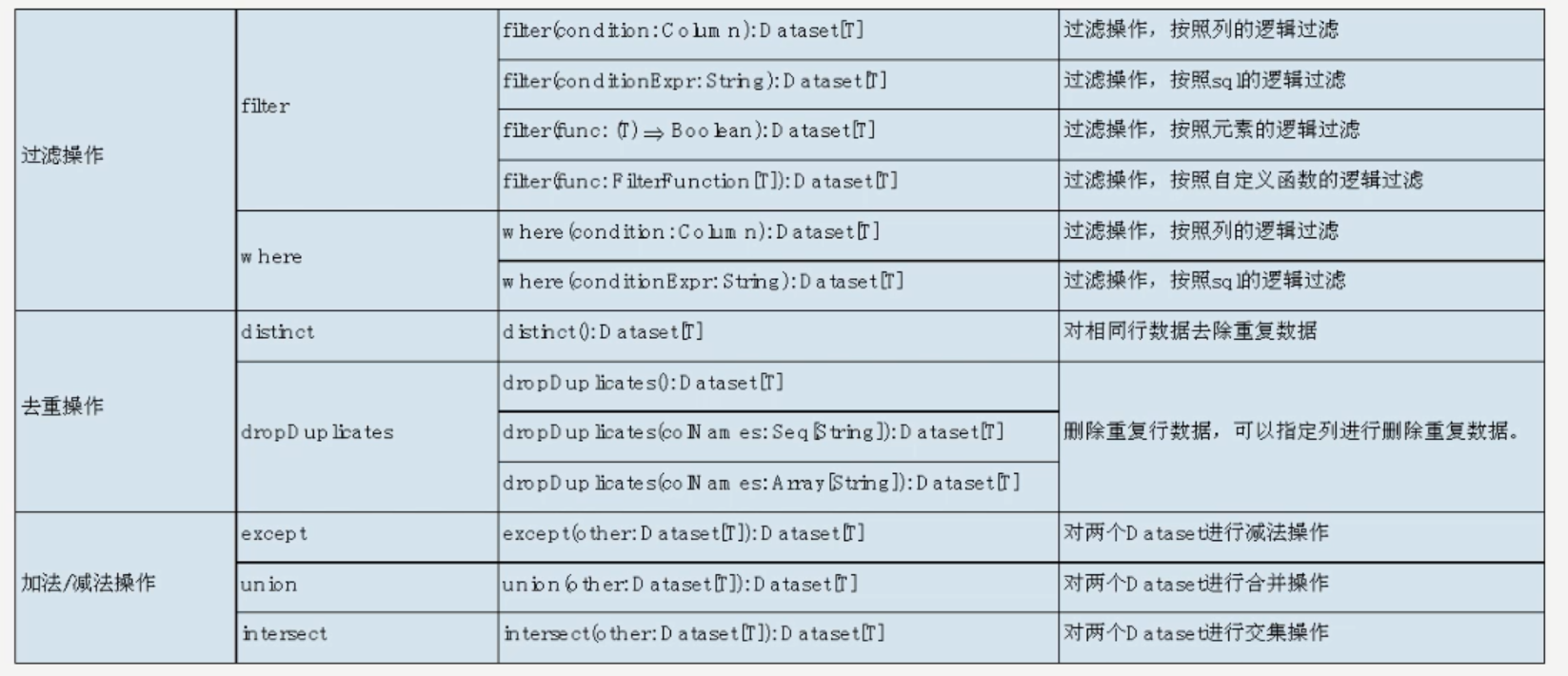




去重操作示例

Expr操作??
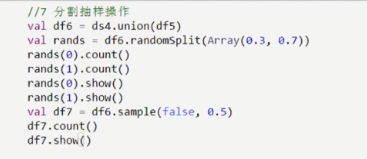
分割操作示例
withcolumn是增加一列,增加常数项

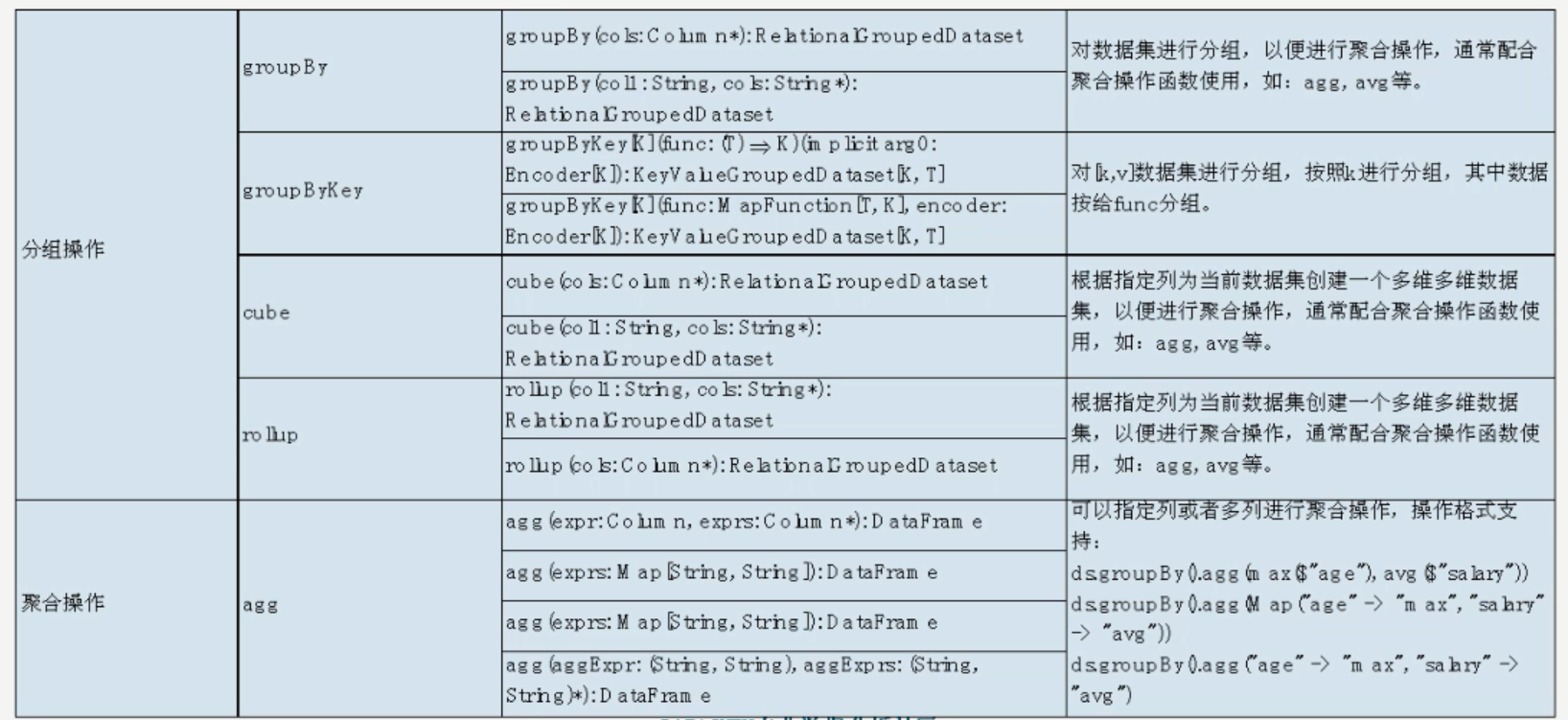
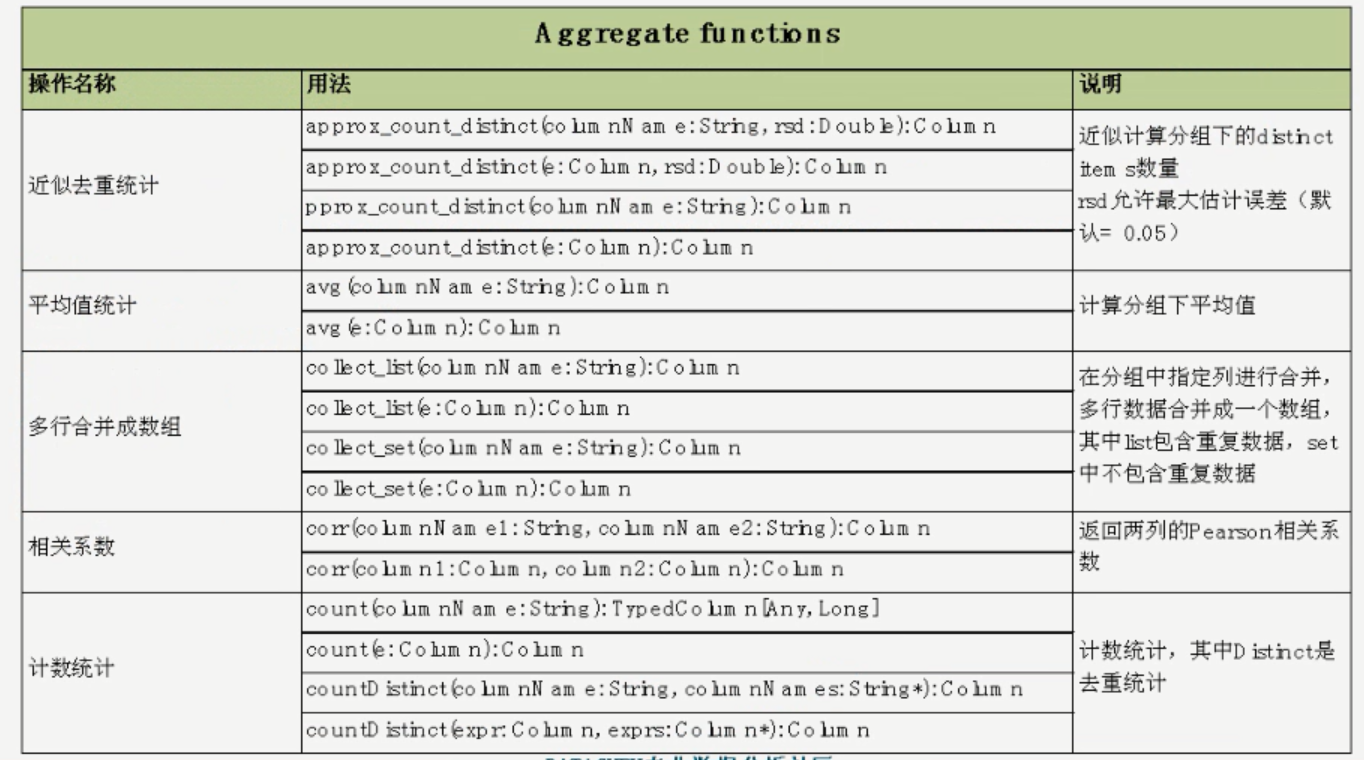
聚合操作示例


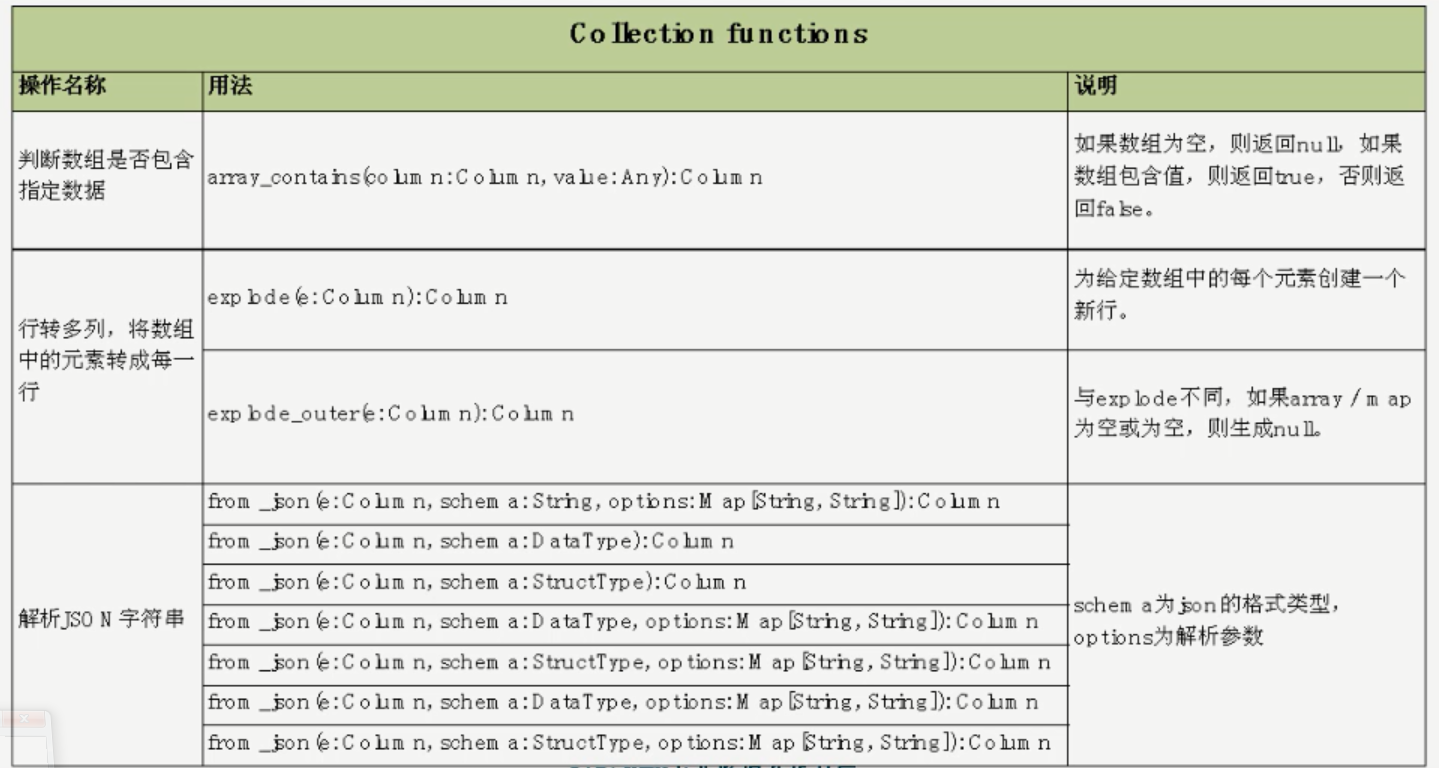
对json的支持
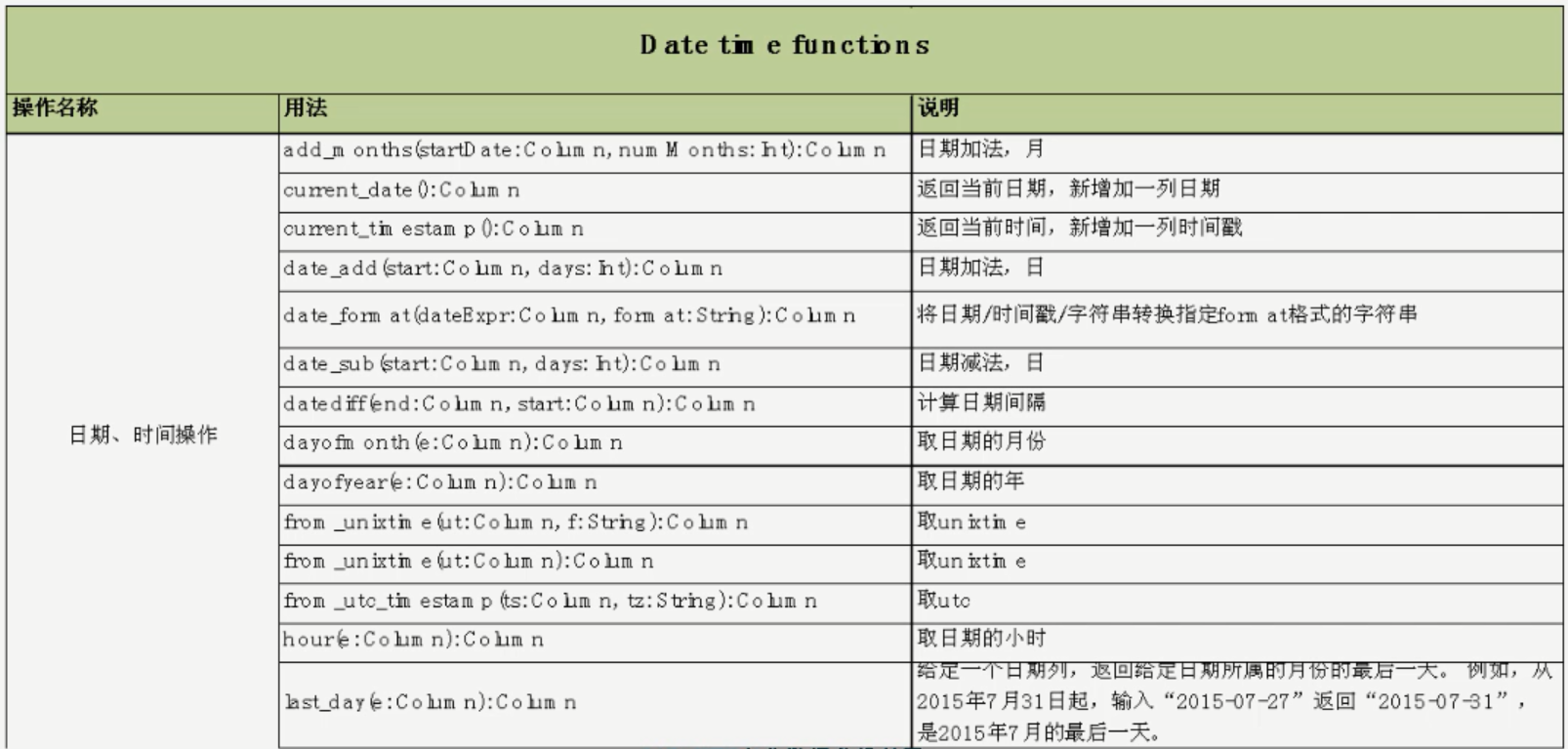
时间日期操作
支持数值运算


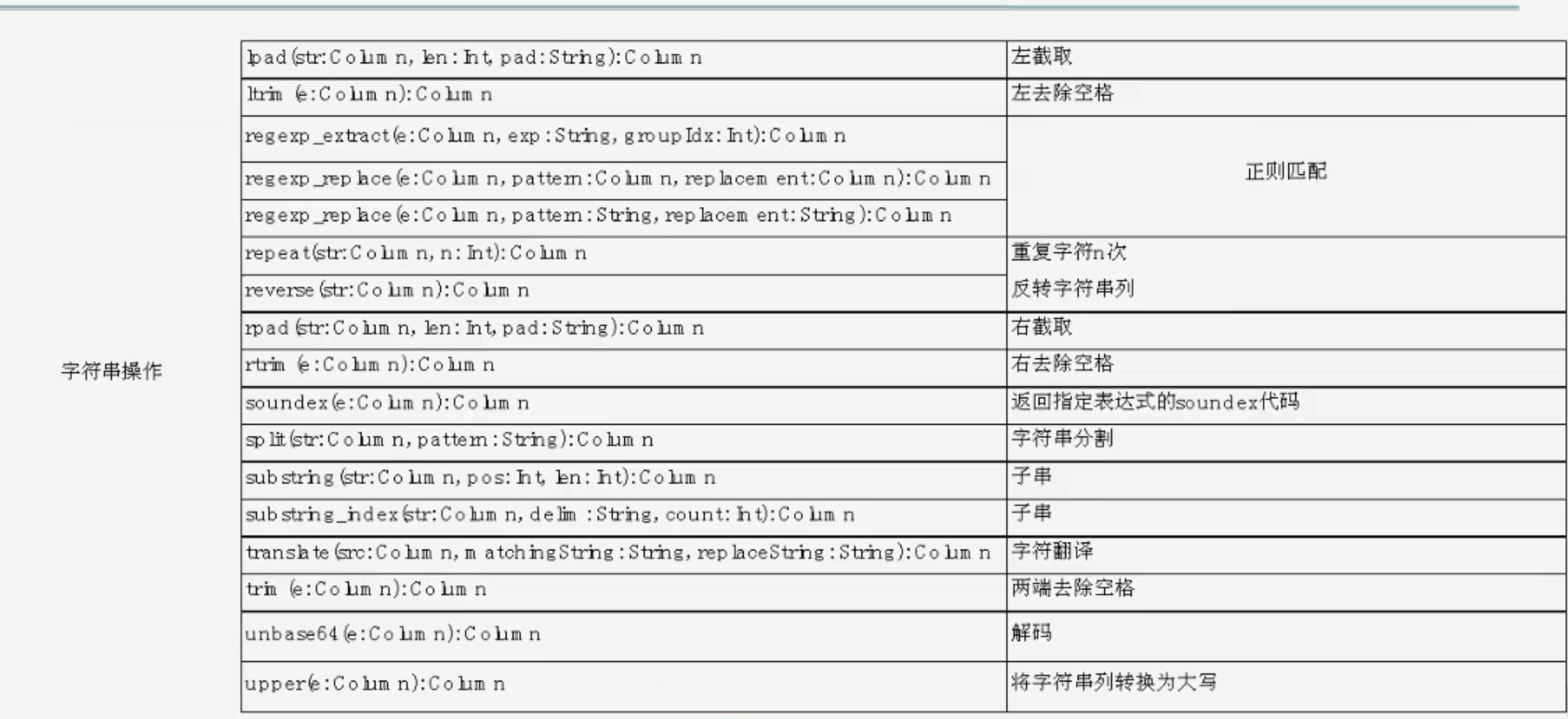
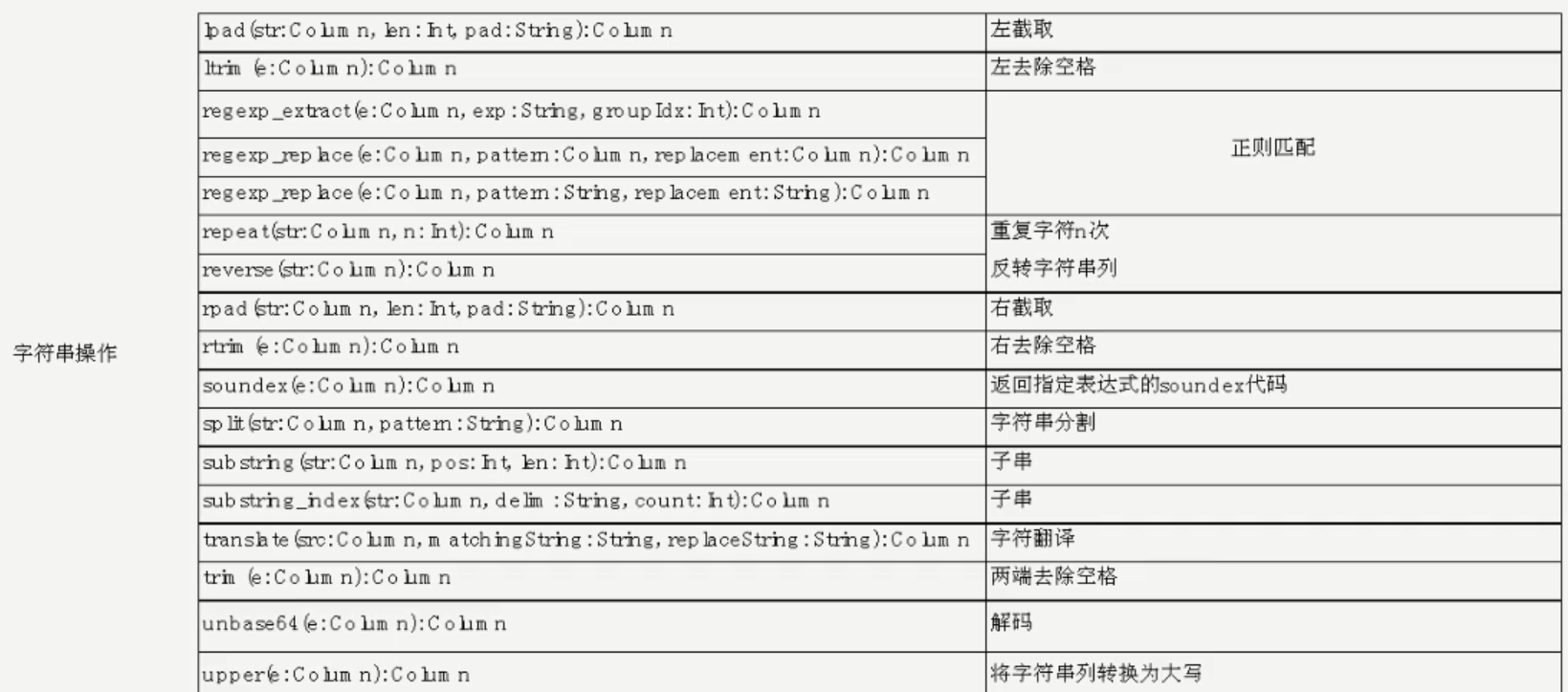
字符串操作