KNN,决策树两种算法都明确给出了“该数据实例到底属于哪一类”这类明确的回答,而这一篇讲到的朴素贝叶斯分类器,基于概率论的分类方法,将给出数据实例属于不同种类的概率(基于数据的后验概率),从而供我们选择一个最优的类别猜测结果。例如给定一组数据(x,y),可能的分类是C1,C2,这里我们基于之前给出的数据,求P(C1|x,y)和P(C2|x,y),比较两个概率的大小,判断(x,y)更可能属于哪个类别。这里我们先对朴素和贝叶斯做个基本的了解。
朴素:
顾名思义,朴素,即为简单,直白,在贝叶斯分类中,朴素意味着整个计算过程只做最原始,最简单的假设:
1.独立:
统计上的独立,有两个随机事件A,B,发生的概率分别为P(A)和P(B),AB两事件同时发生的概率为P(A),若P(AB)=P(A)xP(B),则A与B独立。在分类和文本检测中即一个特征或者单词出现的可能性与它和其他相邻单词没有关系。
2.等重要性:
即每个特征同等重要。虽然这个假设看起来有些瑕疵,但朴素贝叶斯的实际效果却很好。
贝叶斯:
贝叶斯公式用来描述两个条件概率之间的关系,比如 P(A|B) 和 P(B|A)。按照乘法法则,可以立刻导出:P(A∩B) = P(A)*P(B|A)=P(B)*P(A|B)。如上公式也可变形为:P(B|A) = P(A|B)*P(B) / P(A)。而有效计算条件概率的方法称为贝叶斯准则,贝叶斯准则告诉我们如何交换条件概率中的条件与结果:

c表示数据可能的分类结果,x为数据,这里的x可以是多维数据,不局限在一个维度。基于以上公式,我们可以根据先验信息(已知的数据)去求出p(x|c),p(c),p(x),从而得到p(c|x)。p(c)也称作是先验概率。
针对书中文本分类案例以及朴素假设后的贝叶斯计算:


wi为不同的字符,p(wi|ci)为不同字符在不同类别中出现的概率,p(ci)为先验概率,即类别出现的概率,分母部分为数据总体中每个数据出现的概率,由于分母与类别ci无关,所以p(w)在计算时可以忽略,这也是后文中为什么取对数只对分子取了对数,而对分母没有计算。
下面介绍几种常见的朴素贝叶斯分类器:
朴素贝叶斯分类器的思想是基于贝叶斯定理的一组监督学习算法,简单的假设特征之间相互独立且等同重要,给定一个类别y和从xi到xn的特征向量,通过计算先验概率p(c)和先验信息p(x|c)以及p(x),找到最大化的后验概率p(c|x),从而估计对应数据所属类别,而不同的朴素贝叶斯分类器大部分来自处理p(x|c)分布时所做的假设不同。
1.高斯朴素贝叶斯
GaussianNB实现了运用于分类的搞死朴素贝叶斯法,特征概率假设为高斯分布:

参数μ和sigam用极大似然估计。
2.多项分布朴素贝叶斯
MultinomialNB实现了服从多项分布数据的朴素贝叶斯算法,也适用于文本分类的两大经典朴素贝叶斯分类算法之一,往往以词向量表示,分布参数由每个x的Θ=(Θ1,Θ2,··,Θn)向量决定,n代表特征的数量(文本分类中即词汇量的大小),Θi是属于特征i的概率p(xi|c),Θi由平滑过的最大似然估计来估计,相对频率计数:
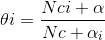
Nci是特征i在类c中出现的次数,Ny是c中所有特征出现总数。
3.多重伯努利分布朴素贝叶斯
BernoulliNB实现了多重伯努利分布数据的朴素贝叶斯训练和分类算法,每个特征假设是一个二元变量,这种算法要求样本以二元制特征变量表示,若有其他类数据,一个Bernoulli实例会将其二值化(取决于Bernoulli参数),决策规则基于:

与多项分布贝叶斯的规则不同,BernoulliNB明确惩罚类C中没有出现作为预测因子的特征i,而MultinomialNB则是简单的忽略了未出现的特征。在文本分类的例子中,次品向量可能用于训练这类分类器,特别的,伯努利分类器在更短的文档上表现不错。
有了这些基础知识,我们来看下书中的实例:
利用python进行文本分类,数据集给出了六句评论,3句属于侮辱性评论,3句属于非侮辱性评论,我们需要用这六条信息训练朴素贝叶斯分类器,并在给出一些文本时,判断这些文本更可能是是侮辱性的还是非侮辱性的评论。
from numpy import *
def loadDataSet():
postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
classVec = [0,1,0,1,0,1] #0代表好,1代表不好
return postingList,classVec
这一步给出了原始数据集,分别是6句评论对应的单词split以及对应句子的标签值。
def createVocabList(dataSet):
# """
# :params:
# :dataSet:输入字符列表,提取字符列表中的唯一值
# :return:包含datSet中不重复词条的列表
# """
vocabSet = set([])
for document in dataSet:
vocabSet = vocabSet | set(document) #集合取并
return list(vocabSet)
这一步使用了set()方法提取集合中的唯一unique值,并通过循环,得到输入文本的无重复文本。
def setOfWords2Vec(vocabList, inputSet):
# """
# :params:
# :vocablist:文本全部无重复词条
# :inputSet:输入待检测词条
# return:bool形列表,显示vocablist中词频
# """
returnVec = [0]*len(vocabList)
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] = 1
else: print ("the word: %s is not in my Vocabulary!" % word)
return returnVec这一步完成了字符向量到数字向量的转化,每当字符出现一次时,在vocablist对应位置的returnVec列表就增加一次字符出现的次数。
def trainNB0(trainMatrix,trainCategory): #""" #:params: #:trainMatri训练集 #:trainCategory训练集分类 #return p(C0|wi) p(C1|wi) p(Ci) #""" numTrainDocs = len(trainMatrix) numWords = len(trainMatrix[0]) pAbusive = sum(trainCategory)/float(numTrainDocs) p0Num = zeros(numWords); p1Num = zeros(numWords)#修改后的拉普拉斯修正 p0Denom = 0.0; p1Denom = 0.0 #类别数 因为类别为好和不好 所以类别数N为2 for i in range(numTrainDocs): if trainCategory[i] == 1: p1Num += trainMatrix[i] p1Denom += sum(trainMatrix[i]) else: p0Num += trainMatrix[i] p0Denom += sum(trainMatrix[i]) p1Vect = p1Num/p1Denom p0Vect = p0Num/p0Denom return p0Vect,p1Vect,pAbusive
这一步基于上一步得到的全部文本列表,计算每个字符在好的评论中出现的概率以及每个字符在不好的评论中出现的概率,并且计算出了先验概率P(评论 = 好),由于类别的取值是二值的,只有好坏之分,所以P(评论 = 不好) = 1-P(评论 = 好)。
先看一下p0Vect,p1Vect:
[ 0.04166667 0.08333333 0.04166667 0.04166667 0.04166667 0.04166667 0.04166667 0.04166667 0.04166667 0.04166667 0. 0.04166667 0.04166667 0. 0.04166667 0.04166667 0.04166667 0. 0. 0.04166667 0. 0.04166667 0. 0.125 0. 0.04166667 0. 0.04166667 0. 0. 0.04166667 0. ]
[ 0.10526316 0.05263158 0. 0. 0. 0. 0. 0. 0. 0. 0.05263158 0. 0. 0.05263158 0. 0. 0. 0.05263158 0.05263158 0.05263158 0.05263158 0. 0.05263158 0. 0.05263158 0. 0.05263158 0.05263158 0.10526316 0.05263158 0. 0.15789474]
由于要计算多个概率乘积以获得属于某个类别的概率,即计算p(w0|ci)p(w1|ci)···p(w1|cn),如果其中有一个概率为0,则无论该样本的其他属性是什么,哪怕其他属性上明显是好的评论,也会分类为不好的评论,这显然会影响分类器的性能,为此我们将所有词的出现数初始化为1,并将分母初始化为2。这里的修改涉及到数学中估计概率值时常用的‘平滑’,常用拉普拉斯修正(Laplacian correction),修正如下:


令N表示训练集D中可能的类别数,由于评论的类别数是好和坏,所以N=2,Ni表示第i个属性可能的取值数。除此之外,当数据集数量特别大时,小数连乘会造成溢出的现象,而小数位数过多时,系统会默认为0,为了避免这种处理,采取了对乘积取自然对数,化乘法为加法,避免了下溢或者浮点数舍入导致的错误,基于以上调整,我们对TrainNB0函数也做出了调整,看一下调整后的函数和输出p0Vect,p1Vect:
def trainNB0(trainMatrix,trainCategory): #""" #:params: #:trainMatri训练集 #:trainCategory训练集分类 #return p(C0|wi) p(C1|wi) p(Ci) #""" numTrainDocs = len(trainMatrix) numWords = len(trainMatrix[0]) pAbusive = sum(trainCategory)/float(numTrainDocs) p0Num = ones(numWords); p1Num = ones(numWords)#拉普拉斯修正 p0Denom = 2.0; p1Denom = 2.0 #类别数 因为类别为好和不好 所以类别数N为2 for i in range(numTrainDocs): if trainCategory[i] == 1: p1Num += trainMatrix[i] p1Denom += sum(trainMatrix[i]) else: p0Num += trainMatrix[i] p0Denom += sum(trainMatrix[i]) p1Vect = log(p1Num/p1Denom) p0Vect = log(p0Num/p0Denom) return p0Vect,p1Vect,pAbusive
[-2.15948425 -3.25809654 -2.56494936 -3.25809654 -2.56494936 -2.56494936 -2.56494936 -1.87180218 -2.56494936 -3.25809654 -2.56494936 -3.25809654 -2.56494936 -2.56494936 -2.56494936 -2.56494936 -3.25809654 -3.25809654 -2.56494936 -2.56494936 -2.56494936 -3.25809654 -3.25809654 -2.56494936 -3.25809654 -2.56494936 -3.25809654 -2.56494936 -2.56494936 -3.25809654 -2.56494936 -2.56494936]
[-2.35137526 -1.65822808 -3.04452244 -2.35137526 -3.04452244 -3.04452244 -3.04452244 -3.04452244 -3.04452244 -2.35137526 -3.04452244 -2.35137526 -3.04452244 -3.04452244 -2.35137526 -1.94591015 -1.94591015 -2.35137526 -3.04452244 -3.04452244 -2.35137526 -2.35137526 -2.35137526 -3.04452244 -2.35137526 -3.04452244 -2.35137526 -3.04452244 -3.04452244 -2.35137526 -3.04452244 -3.04452244]
这下字符向量不再包含0,我们的分类器可以更好的工作了。
def testingNB():
listOPosts,listClasses = loadDataSet()#导入数据集
myVocabList = createVocabList(listOPosts)#创建唯一值列表
trainMat=[]#初始化训练集合
for postinDoc in listOPosts:
trainMat.append(setOfWords2Vec(myVocabList, postinDoc))
print(listOPosts)
p0V,p1V,pAb = trainNB0(array(trainMat),array(listClasses))#生成p0v,p1v,pAb
testEntry = ['love', 'my', 'dalmation']#测试集1
thisDoc = array(setOfWords2Vec(myVocabList, testEntry))#转化为数字向量
print (testEntry,'classified as: ',classifyNB(thisDoc,p0V,p1V,pAb))
testEntry = ['stupid', 'garbage']#测试集2
thisDoc = array(setOfWords2Vec(myVocabList, testEntry))#转化数字向量
print (testEntry,'classified as: ',classifyNB(thisDoc,p0V,p1V,pAb))
def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1):#定义分类函数
p1 = sum(vec2Classify * p1Vec) + log(pClass1) #element-wise mult
p0 = sum(vec2Classify * p0Vec) + log(1.0 - pClass1)
if p1 > p0:比较概率,判断词条更可能属于哪个类别
return 1
else:
return 0
基于我们刚才算出来的p0v,p1v,pAb以及分类算法classifyNB,我们将两个训练集导出为数字向量形式用作验证算法,计算训练字符可能的分类,看一下输出结果:
['love', 'my', 'dalmation'] classified as: 0 ['stupid', 'garbage'] classified as: 1 [Finished in 0.7s]
这与我们最初的文本比较符合,love,my多出现在好(0)的评论,而stupid则出现在不好(1)的评论中。
另一种考虑:
就是针对给出的w=[w1,w2,...,wn],不用书上的方法形成数字向量vct,而是单独计算p(w1|ci),p(w2|ci)...以及先验概率p(c),以及p(w),大概的思路是这样的:
例如上例中给出的w=[w1,w2,w3]= ['love','my','dalmation'],利用简化的概率公式计算:


其中ci分别为好坏。
p0V,p1V,pAb = trainNB0(trainMat,listClasses)
#这里使用了最初未平滑的数字信息向量
#如果对应位置为0,则修改为0.001
for i in range(len(p0V)):
if p0V[i] == 0:
p0V[i] = 0.000001
for i in range(len(p1V)):
if p1V[i] == 0:
p1V[i] = 0.000001
[ 4.16666667e-02 1.25000000e-01 1.00000000e-06 8.33333333e-02 4.16666667e-02 4.16666667e-02 4.16666667e-02 4.16666667e-02 4.16666667e-02 4.16666667e-02 1.00000000e-06 4.16666667e-02 1.00000000e-06 4.16666667e-02 4.16666667e-02 1.00000000e-06 4.16666667e-02 1.00000000e-06 4.16666667e-02 4.16666667e-02 1.00000000e-06 4.16666667e-02 1.00000000e-06 4.16666667e-02 1.00000000e-06 1.00000000e-06 1.00000000e-06 4.16666667e-02 4.16666667e-02 4.16666667e-02 1.00000000e-06 4.16666667e-02]
[ 1.00000000e-06 1.00000000e-06 5.26315789e-02 5.26315789e-02 1.00000000e-06 1.00000000e-06 1.00000000e-06 1.00000000e-06 1.00000000e-06 1.00000000e-06 5.26315789e-02 1.00000000e-06 5.26315789e-02 1.00000000e-06 1.00000000e-06 5.26315789e-02 1.00000000e-06 5.26315789e-02 5.26315789e-02 1.05263158e-01 1.05263158e-01 1.00000000e-06 1.57894737e-01 1.00000000e-06 5.26315789e-02 5.26315789e-02 5.26315789e-02 5.26315789e-02 1.00000000e-06 1.00000000e-06 5.26315789e-02 1.00000000e-06]
以上是我们修改后得到的p0V,p1V,接下来我们打算定义函数,用于计算个概率值p(wi|ci),p(ci),p(wi),并保存到DataFrame中,用上面的概率公式计算:
def bagOFWord2VecMN(vocablist,inputSet):#与之前的字符转向量函数相同 returnVec = [0]* len(vocablist)#创建一个与vocablist等长的均为0的向量 for word in inputSet: if word in vocablist: returnVec[vocablist.index(word)] += 1#在文本中出现,则对应位置次数加一 return returnVec
returnVec中包含了各个字符出现的次数。
import pandas as pd info = pd.DataFrame(p0V,index = myVocabList,columns = ['P(w|0)']) info['P(w|1)'] = p1V #分别添加了两个columns p(w|0)与p(w|1) returnVec = [0]* len(myVocabList) for i in range(6): for word in myVocabList: if word in listOPosts[i]: returnVec[myVocabList.index(word)] += 1 #计算字符在总文本中出现的概率 returnVec = array(returnVec) pW = returnVec/sum(returnVec) info['p(w)'] = pW#添加columns p(w)
这里导入了pandas库,设置了colmns:p(w|0),p(w|1)以及p(w),看一下我们得到的DataFrame(Info)长什么样子:

我们得到了输入样本的一个Info信息阵,包括了每个字符在好评论,坏评论的概率,以及在总文本中出现的概率。接下来我们就可以用刚才的概率公式来计算了。为了看的直白一些,这里代码写的比较繁琐:
a = log(info['P(w|0)']['my']) b = log(0.5) c = log(info['p(w)']['my']) d = log(info['P(w|1)']['my']) e = log(0.5) f = log(info['p(w)']['my'])
这里先看一下训练集为单独的['my']时的分类效果:
a+b+c = -5.43517654927 d+e+f = -17.1712455655
根据概率,我们选择概率更大的a+b+c作为my的分类,即为0.
再看一下训练集为input_word = ['love','my','dalmation']
input_word2 = ['stupid','garbage']的效果:
input_word = ['love','my','dalmation']
input_word2 = ['stupid','garbage']
for i in input_word:
p0=0.0;p1=0.0
p0 += log(info['P(w|0)'][i])-log(info['p(w)'][i])
p1 += log(info['P(w|1)'][i])-log(info['p(w)'][i])
p0 = p0+log(0.5)
p1 = p1+log(0.5)
if p0 > p1:
print('0')
else:
print('1')调整for循环处的Input_word和input_word2,分别得到以下结果,和我们之前书上的分类效果相同,顺便我们在代码中也可以看到,p0和p1都减去了相同的log(info['p(w)][i]),因此比较p0,p1大小时,分母p(w)可以不用考虑的原因。
0 [Finished in 2.6s] 1 [Finished in 2.7s]
总结:
这篇文章主要用最朴素的例子介绍朴素贝叶斯分类算法,下一篇文章将对垃圾邮件的分类使用默认代码和sklearn库中三种NB算法共四种方法实现,并用交叉验证sklearn.cross_validation验证四种算法的准确率。本文末最后的这个‘另一种考虑’只是自己想出来的一种有点偷懒还不够严谨的朴素贝叶斯分类算法,虽然对于书中的例子效果较好,但由于0变成0.0001的数学的不严谨以及训练样本的数据量少,实际中效果会打一些折扣,权当是'另一种考虑'了。最后欢迎大家交流指正~