什么是大数据
- 电商推荐系统
- 大量订单如何存储(十年)
- 大量的订单如何计算(不关心算法)
- 天气预报
- 大量的天气数据如何存储
- 大量天气数据如何计算
- 核心问题
- 数据的存储:分布式文件系统(HDFS)
- 数据的计算:分布式计算(MapReduce、Spark RDD)
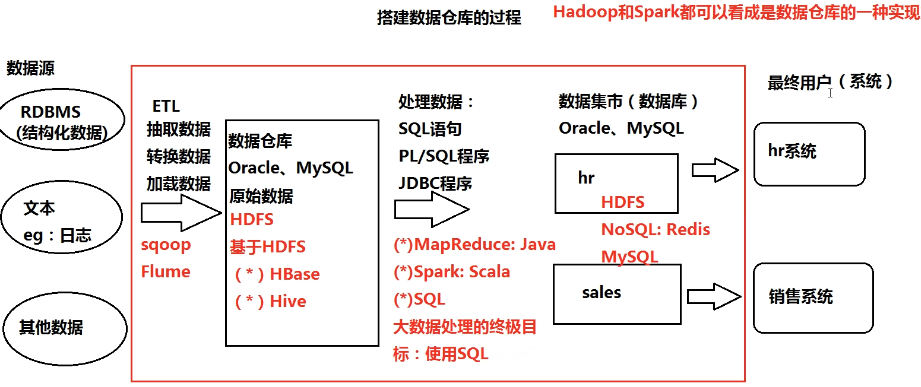
数据仓库
- 传统方式:搭建数据仓库(Data Warehouse)解决大数据问题
- 数据仓库就是一个数据库(Oracle、MySQL、MS)
- Oracle DBCA
- 一般只做查询(select)
- 大数据也是一般只做查询(分析,不修改数据)
- Hadoop和Spark都可看做数据仓库的一种实现方式
- Oracle、MySQL是单机版数据库,无法实现分布式集群
- 搭建过程
- 数据源
- RDBMS(结构化数据)
- 文本、日志等(非结构化数据)
- 其他数据
- 数据清洗:抽取、转换、加载数据(ETL)
- 原始数据保存到数据库(Oracle、MySQL)
- 处理数据(SQL、JDBC)
- 处理后的数据保存到数据集市(Oracle、MySQL)
- 提供给最终用户(系统)
- 数据源
OLTP和OLAP
- OLTP
- Online Transaction Processing 联机事务处理
- insert、update、delete
- 传统关系型数据库解决的问题
- OLAP
- Online Analytic Processing 联机分析处理,一般只做查询select(分析,不支持事务)
- 数据仓库是一种OLAP
- Hadoop、Spark可看做一种数据仓库解决方案
Google三篇论文
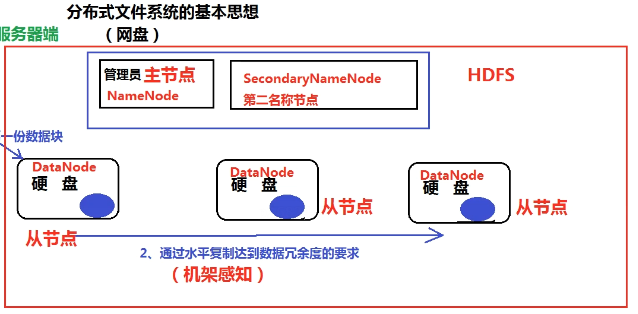
- GFS(Google File System)
- 分布式文件系统
- 硬盘不够大->加硬盘
- 硬盘不够安全->冗余
- Oracle费用:50万/年/CPU
- 大量使用pc服务器(去掉机箱、外设、硬盘)
- 数据存在内存,速度快,用冗余保证安全
- HDFS:通过数据块传输(128M),水平复制,默认冗余度3
- 机架感知:兼顾安全与效率(HDFS封装)
- 倒排索引(Reverted Index)
- 数据保存在了哪个硬盘上?
- 记录数据保存的位置信息(元信息)
- 索引:目录(索引表,保存行地址,类似书后名词索引按字母顺序排序),提高查询效率(没有索引时需要遍历)
- 单词保存在哪句话中?分词,建立目录(单词表),记录单词位置信息
- 可使用MapReduce建立倒排索引



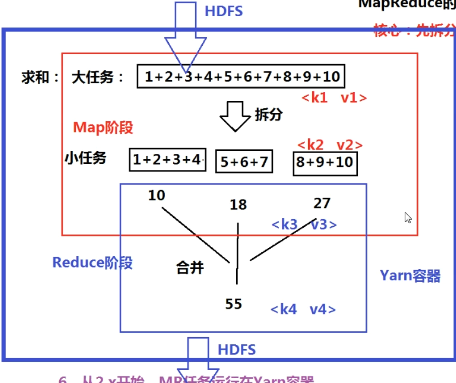
- MapReduce
- 分布计算模型
- 问题来源:PageRank(网页排名)
- 搜索结果中,Rank越高的Page排名越靠前
- 被指向越多的网页Rank越高
- 用矩阵记录Rank
- 用MapReduce计算大矩阵
- 思想:先拆分、再合并
- 编程模型
- MR任务:job=map+reduce
- Map的输出是Reduce的输入
- 一个MR任务,一共存在4对输入和输出
- 所有输入输出都是<key value>形式
- Map阶段:<k1 v1>输入,<k2 v2>输出
- Reduce阶段:<k3 v3>输入,<k4 v4>输出
- k2=k3,v2和v3数据类型一致,v3是一个集合,该集合中的每个值就是v2
- 如下图v3=(10,18,27)
- 所有<key value>数据类型必须是Hadoop自己的数据类型
- IntWritable LongWritable Text NullWritable
- Hadoop类型实现了Hadoop的序列化机制(Writable接口)
- 从2.x开始,MR运行在Yarn容器中(类似JSP部署在Tomcat)
- Yarn=ResourceManager(主节点)+NodeManager(从节点)
- MR任务处理的数据是HDFS的数据
- mapreduce实例:/share/hadoop/mapreduce/example
- web console:localhost:8088/cluster
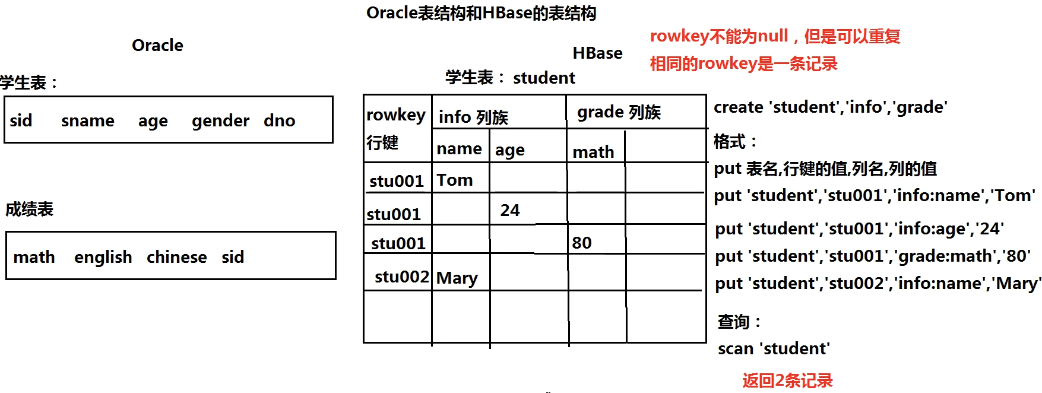
BigTable(大表)
- 关系型数据库
- 基于关系模型(用二维表保存数据)
- 行式数据库
- MySQL、Oracle
- insert update delete 性能高
- 常见NoSQL数据库
- Redis:内存数据库
- HBase:面向列
- MongoDB:面向文档(BSON文档:JSON的二进制)
- select 性能高
- 核心思想
- 把所有数据存入一张表
- 数据冗余
- 提高性能(空间换时间)
- 把同样的数据存入Oracle和大表
- HBase = ZooKeeper + HMaster(主节点) + RegionServer(从节点)