练习1:航班乘客变化分析
- 分析年度乘客总量变化情况(折线图)
- 分析乘客在一年中各月份的分布(柱状图)
from matplotlib import pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
data = sns.load_dataset('flights')
gb_year = data.groupby(['year'], as_index=False).sum() # as_index=False 将聚合后依旧保持为列,不会变成索引
print(gb_year)
year passengers
0 1949 1520
1 1950 1676
2 1951 2042
3 1952 2364
4 1953 2700
5 1954 2867
6 1955 3408
7 1956 3939
8 1957 4421
9 1958 4572
10 1959 5140
11 1960 5714
# 分析年度乘客总量变化情况(折线图)
def lineplot(x_data, y_data, x_label, y_label, title):
fig, ax = plt.subplots() # 注意是subplots,不是subplot
ax.plot(x_data, y_data, lw=2, color = '#539caf', alpha = 1)
ax.set_title(title)
ax.set_xlabel(x_label)
ax.set_ylabel(y_label)
lineplot(x_data=gb_year['year']
, y_data=gb_year['passengers']
, x_label='Year'
, y_label='Passengers'
, title='Year VS Passengers')
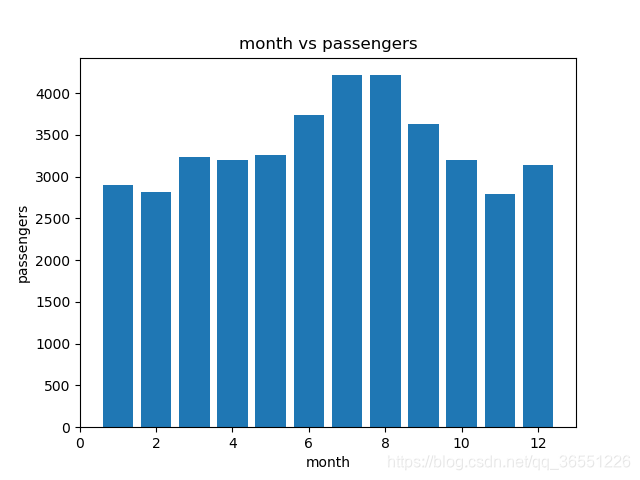
# 分析乘客在一年中各月份的分布(柱状图)
gb_month = data[['month', 'passengers']].groupby('month').sum()
print(gb_month) # 从data里取出month和passenges两列,做聚合相加
passengers
month
January 2901
February 2820
March 3242
April 3205
May 3262
June 3740
July 4216
August 4213
September 3629
October 3199
November 2794
December 3142
gb_month = pd.Series(gb_month['passengers'].values, index=(np.arange(1,13)))
print(gb_month)
1 2901
2 2820
3 3242
4 3205
5 3262
6 3740
7 4216
8 4213
9 3629
10 3199
11 2794
12 3142
dtype: int64
fig, ax = plt.subplots()
ax.bar(gb_month.index, gb_month.values)
plt.title('month vs passengers')
plt.xlabel('month')
plt.ylabel('passengers')
plt.show()

方法二
data_number = data.groupby(data['year']).sum()
data_number
passengers
year
1949 1520
1950 1676
1951 2042
1952 2364
1953 2700
1954 2867
1955 3408
1956 3939
1957 4421
1958 4572
1959 5140
1960 5714
plt.plot(data_number.index,data_number.values) # 直接用索引
12年各月份柱状图
gb_pass = data['passengers'].groupby([data['year'], data['month']]).sum().unstack() # 注意groupby内分开写, .unstack()将Series变为Dataframe
print(gb_pass)
year month
1949 January 112
February 118
March 132
April 129
May 121
June 135
July 148
August 148
September 136
October 119
November 104
December 118
1950 January 115
February 126
March 141
April 135
May 125
June 149
July 170
August 170
September 158
October 133
November 114
December 140
...
--------------->
month January February March ... October November December
year ...
1949 112 118 132 ... 119 104 118
1950 115 126 141 ... 133 114 140
1951 145 150 178 ... 162 146 166
1952 171 180 193 ... 191 172 194
1953 196 196 236 ... 211 180 201
1954 204 188 235 ... 229 203 229
1955 242 233 267 ... 274 237 278
1956 284 277 317 ... 306 271 306
1957 315 301 356 ... 347 305 336
1958 340 318 362 ... 359 310 337
1959 360 342 406 ... 407 362 405
1960 417 391 419 ... 461 390 432
gb_pass.plot(kind="bar",figsize=(23,8))

练习2:鸢尾花花型尺寸分析
- 萼片(sepal)和花瓣(petal)的大小关系(散点图)
- 不同种类(species)鸢尾花萼片和花瓣的大小关系(分类散点子图)
- 不同种类鸢尾花萼片和花瓣大小的分布情况(柱状图或者箱式图)
import matplotlib as mpl
from matplotlib import pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
data = sns.load_dataset("iris")
data['sepal_size'] = data['sepal_length'] * data['sepal_width']
data['petal_size'] = data['petal_length'] * data['petal_width']
print(data.head())
# 萼片(sepal)和花瓣(petal)的大小关系(散点图)
fig, ax = plt.subplots()
ax.scatter(data['sepal_size'], data['petal_size'], s=10, alpha=0.75, facecolor='#539caf') # color=好像没了
plt.title('sepal size and petal size')
plt.xlabel('sepal size')
plt.ylabel('petal size')
# 不同种类(species)鸢尾花萼片和花瓣的大小关系(分类散点子图)
species=data['species'].unique() # unique():返回参数数组中所有不同的值,并按照从小到大排序
data1=data[data['species']==species[0]]
data2=data[data['species']==species[1]]
data3=data[data['species']==species[2]]
fig, ax2 = plt.subplots()
ax2.scatter(data1['sepal_size'], data1['petal_size'], color='#ff0000', label=species[0])
ax2.scatter(data2['sepal_size'], data2['petal_size'], color='#00ff00', label=species[1])
ax2.scatter(data3['sepal_size'], data3['petal_size'], color='#0000ff', label=species[2])
ax2.legend(loc='best')
ax2.set_title('size with species')
ax2.set_xlabel('sepal_size')
ax2.set_ylabel('petal_size')
# 不同种类鸢尾花萼片和花瓣大小的分布情况(柱状图或者箱式图)
def boxplot(x_data, y_data, base_color, median_color, x_label, y_label, title):
fig, ax = plt.subplots()
# 设置样式
ax.boxplot(y_data
# 箱子是否颜色填充
, patch_artist = True
# 中位数线颜色
, medianprops = {'color': base_color}
# 箱子颜色设置,color:边框颜色,facecolor:填充颜色
, boxprops = {'color': base_color, 'facecolor': median_color}
# 猫须颜色whisker
, whiskerprops = {'color': median_color}
# 猫须界限颜色whisker cap
, capprops = {'color': base_color})
# 箱图与x_data保持一致
ax.set_xticklabels(x_data)
ax.set_xlabel(x_label)
ax.set_ylabel(y_label)
ax.set_title(title)
# 将各类的size放入列表
sepalsize = [data1['sepal_size'], data2['sepal_size'], data3['sepal_size']]
petalsize = [data1['petal_size'], data2['petal_size'], data3['petal_size']]
boxplot(x_data=species
, y_data=sepalsize
, base_color= 'b'
, median_color= 'r'
, x_label='species'
, y_label='size'
, title='species and size')
boxplot(x_data=species
, y_data=petalsize
, base_color= 'b'
, median_color= 'r'
, x_label='species'
, y_label='size'
, title='species and size')
plt.show()




练习3:餐厅小费情况分析
- 小费和总消费之间的关系(散点图)
- 男性顾客和女性顾客,谁更慷慨(分类箱式图)
- 抽烟与否是否会对小费金额产生影响(分类箱式图)
- 工作日和周末,什么时候顾客给的小费更慷慨(分类箱式图)
- 午饭和晚饭,哪一顿顾客更愿意给小费(分类箱式图)
- 就餐人数是否会对慷慨度产生影响(分类箱式图)
- 性别+抽烟的组合因素对慷慨度的影响(分组柱状图)
import matplotlib as mpl
from matplotlib import pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
data = sns.load_dataset("tips")
print(data.head())
# 小费和总消费之间的关系(散点图)
fig, ax1 = plt.subplots()
ax1.scatter(data['total_bill'], data['tip'], s=10, facecolor='r', alpha=0.75)
ax1.set_title('bill and tip')
ax1.set_xlabel('total bill')
ax1.set_ylabel('tip')
def boxplot(x_data, y_data, base_color, median_color, x_label, y_label, title):
fig, ax = plt.subplots()
ax.boxplot(y_data
, patch_artist = True
, medianprops= {'color':base_color}
, boxprops= {'color':base_color, 'facecolor':median_color}
, whiskerprops = {'color':median_color}
, capprops= {'color':base_color})
ax.set_xticklabels(x_data)
ax.set_ylabel(y_label)
ax.set_xlabel(x_label)
ax.set_title(title)
# 男性顾客和女性顾客,谁更慷慨(分类箱式图)
sex = data['sex'].unique()
sextip = [data[data['sex']==sex[0]]['tip'], data[data['sex']==sex[1]]['tip']]
boxplot(x_data=sex
, y_data=sextip
, base_color='b'
, median_color='r'
, x_label='sex'
, y_label='tip'
, title='sex and tips')
# 抽烟与否是否会对小费金额产生影响(分类箱式图)
smoke = data['smoker'].unique()
smoketip = [data[data['smoker']==smoke[0]]['tip'], data[data['smoker']==smoke[1]]['tip']]
boxplot(x_data=smoke
, y_data=smoketip
, base_color='b'
, median_color= 'r'
, x_label='smoker'
, y_label='tip'
, title='smoke and tip')
# 工作日和周末,什么时候顾客给的小费更慷慨(分类箱式图)
day=data['day'].unique()
print(day)
[Sun, Sat, Thur, Fri]
daytip=[data[data['day'].isin(day[:2])]['tip'],data[data['day'].isin(day[2:4])]['tip']]
boxplot(x_data = ['weekend','weekday']
, y_data = daytip
, base_color = 'b'
, median_color = 'r'
, x_label = 'Day'
, y_label = 'Tip'
, title = 'Distribution of Tip By Day')
# 午饭和晚饭,哪一顿顾客更愿意给小费(分类箱式图)
time = data['time'].unique()
timetip = [data[data['time']==time[0]]['tip'], data[data['time']==time[1]]['tip']]
boxplot(x_data=time
, y_data=timetip
, base_color='b'
, median_color='r'
, x_label='time'
, y_label='tip'
, title='time and tip')
# 就餐人数是否会对慷慨度产生影响(分类箱式图)
size = data['size'].unique()
sizetip = []
for i in range(len(size)):
sizetip.append(data[data['size']==size[i]]['tip'])
boxplot(x_data=size
, y_data=sizetip
, base_color='b'
, median_color='r'
, x_label='size'
, y_label='tip'
, title='size and tip')
# 性别+抽烟的组合因素对慷慨度的影响(分组柱状图)
def groupedbarplot(x_data, y_data_list, y_data_names, colors, x_label, y_label, title):
fig, ax = plt.subplots()
# 设置每一组柱状图的宽度
total_width = 0.8
# 设置每一个柱状图的宽度
ind_width = total_width / len(y_data_list)
# 计算每一个柱状图的中心偏移
alteration = np.arange(-total_width/2+ind_width/2, total_width/2+ind_width/2, ind_width)
# 分别绘制每一个柱状图
for i in range(0, len(y_data_list)):
# 横向散开绘制
ax.bar(x_data+alteration[i], y_data_list[i], color= colors[i], label=y_data_names[i], width= ind_width)
ax.set_ylabel(y_label)
ax.set_xlabel(x_label)
ax.set_title(title)
ax.legend(loc='upper right')
sexsmoke = data.groupby(['sex', 'smoker']).mean().unstack()['tip']
print(sexsmoke)
groupedbarplot(x_data=range(2)
, y_data_list=[sexsmoke['Yes'], sexsmoke['No']]
, y_data_names=['Yes', 'No']
, colors=['#539caf', '#7663b0']
, x_label='sex'
, y_label='tip'
, title='sex and smoke and tip')
ax=plt.gca() # 子图
ax.set_xticks(range(2))
ax.set_xticklabels(sexsmoke.index.values) # 打标签
plt.show()







练习4:泰坦尼克号海难幸存状况分析
- 不同仓位等级中幸存和遇难的乘客比例(堆积柱状图)
- 不同性别的幸存比例(堆积柱状图)
- 幸存和遇难乘客的票价分布(分类箱式图)
- 幸存和遇难乘客的年龄分布(分类箱式图)
- 不同上船港口的乘客仓位等级分布(分组柱状图)
- 幸存和遇难乘客堂兄弟姐妹的数量分布(分类箱式图)
- 幸存和遇难乘客父母子女的数量分布(分类箱式图)
- 单独乘船与否和幸存之间有没有联系(堆积柱状图或者分组柱状图)
import matplotlib as mpl
from matplotlib import pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
pd.set_option('display.max_columns', 100)
pd.set_option('display.max_rows', 100)
data = sns.load_dataset("titanic")
'''
survived:幸存与否 pclass:仓位等级 sex:性别
age:年龄 sibsp:堂兄弟姐妹数 parch:父母子女数
fare:票价 embarked:上船港口缩写 class:仓位等级
who:人员分类 adult_male:是否成年男性 deck:所在甲板
embark_town:上船港口 alive:是否幸存 alone:是否单独乘船
'''
print(data.head())
# 不同仓位等级中幸存和遇难的乘客比例(堆积柱状图)
def stackedbarplot(x_data, y_data_list, y_data_names, colors, x_label, y_label, title):
fig, ax = plt.subplots()
for i in range(len(y_data_list)):
if i == 0:
ax.bar(x_data, y_data_list[i], color=colors[i], align='center', label=y_data_names[i])
else:
ax.bar(x_data, y_data_list[i], color=colors[i], bottom=y_data_list[i - 1], align='center', label=y_data_names[i])
ax.set_ylabel(y_label)
ax.set_xlabel(x_label)
ax.set_title(title)
ax.legend(loc = 'upper right') # 设定图例位置
difclass = data.groupby(['pclass', 'survived']).size().unstack() # .size()就是长得啥样,要不然就是个内存地址
print(difclass)
survived 0 1
pclass
1 80 136
2 97 87
3 372 119
# 算占比
difclass['sum'] = difclass[0] + difclass[1]
difclass['Yes'] = difclass[1] / difclass['sum']
difclass['No'] = difclass[0] / difclass['sum']
print(difclass)
survived 0 1 sum Yes No
pclass
1 80 136 216 0.629630 0.370370
2 97 87 184 0.472826 0.527174
3 372 119 491 0.242363 0.757637
stackedbarplot(x_data=difclass.index.values
, y_data_list=[difclass['Yes'], difclass['No']]
, y_data_names=['Yes', 'No']
, colors = ['#539caf', '#7663b0']
, x_label = 'Pclass'
, y_label = 'Number of People'
, title = 'Number of People By Survived Or Not and Pclass')
# 不同性别的幸存比例(堆积柱状图)
difsex = data.groupby(['sex', 'survived']).size().unstack()
print(difsex)
survived 0 1
sex
female 81 233
male 468 109
difsex['sum'] = difsex[0] + difsex[1]
difsex['Yes'] = difsex[1] / difsex['sum']
difsex['No'] = difsex[0] / difsex['sum']
print(difsex)
survived 0 1 sum Yes No
sex
female 81 233 314 0.742038 0.257962
male 468 109 577 0.188908 0.811092
stackedbarplot(x_data=[0, 1]
, y_data_list=[difsex['Yes'], difsex['No']]
, y_data_names=['Yes', 'No']
, colors = ['#539caf', '#7663b0']
, x_label='sex'
, y_label='survive'
, title='sex and survive')
ax=plt.gca()
ax.set_xticks(range(2))
ax.set_xticklabels(sex_survived.index.values)
# 幸存和遇难乘客的票价分布(分类箱式图)
def boxplot(x_data, y_data, base_color, median_color, x_label, y_label, title):
fig, ax = plt.subplots()
ax.boxplot(y_data
, patch_artist= True
, medianprops= {'color': base_color}
, boxprops= {'color': base_color, 'facecolor': median_color}
, whiskerprops= {'color': median_color}
, capprops= {'color': base_color})
ax.set_xticklabels(x_data)
ax.set_ylabel(y_label)
ax.set_xlabel(x_label)
ax.set_title(title)
survive = data['survived'].unique()
survivefare = [data[data['survived']==survive[0]]['fare'], data[data['survived']==survive[1]]['fare']]
#print(survivefare)
boxplot(x_data=survive
, y_data=survivefare
, base_color='b'
, median_color='r'
, x_label='survived'
, y_label='fare'
, title='survived and fare')
# 幸存和遇难乘客的年龄分布(分类箱式图)
data['age'].fillna(0,inplace=True) # 由于age存在NaN,会报错,因此inplace=True,在原数据上将NaN修改为0
survive = data['survived'].unique()
surviveage = [data[data['survived']==survive[0]]['age'], data[data['survived']==survive[1]]['age']]
print(surviveage)
boxplot(x_data=survive
, y_data=surviveage
, base_color='b'
, median_color='r'
, x_label='survived'
, y_label='age'
, title='survived and age')
# 不同上船港口的乘客仓位等级分布(分组柱状图)
def groupedbarplot(x_data, y_data_list, y_data_names, colors, x_label, y_label, title):
fig, ax = plt.subplots()
total_width = 0.9
ind_width = total_width / len(y_data_list)
alteration = np.arange(-total_width/2+ind_width/2, total_width/2+ind_width/2, ind_width)
for i in range(len(y_data_list)):
ax.bar(x_data + alteration[i], y_data_list[i], color= colors[i], label=y_data_names[i], width=ind_width)
ax.set_ylabel(y_label)
ax.set_xlabel(x_label)
ax.set_title(title)
ax.legend(loc='upper right')
difembark = data.groupby(['embark_town', 'class']).size().unstack()
print(difembark)
class First Second Third
embark_town
Cherbourg 85 17 66
Queenstown 2 3 72
Southampton 127 164 353
groupedbarplot(x_data=range(3)
, y_data_list=[difembark['First'], difembark['Second'], difembark['Third']]
, y_data_names=['First', 'Secont', 'Third']
, colors=['#ff0000', '#00ff00', '#0000ff']
, x_label='Class'
, y_label='Number'
, title='Class and Number')
ax = plt.gca()
ax.set_xticks(range(3))
ax.set_xticklabels(difembark.index.values)
# 幸存和遇难乘客堂兄弟姐妹的数量分布(分类箱式图)
survive = data['survived'].unique()
survivesibsp = [data[data['survived']==survive[0]]['sibsp'], data[data['survived']==survive[1]]['sibsp']]
boxplot(x_data=survive
, y_data=survivesibsp
, base_color='b'
, median_color='r'
, x_label='survive'
, y_label='num of sibsp'
, title='num of sibsp')
# 幸存和遇难乘客父母子女的数量分布(分类箱式图)
survive = data['survived'].unique()
surviveparch = [data[data['survived']==survive[0]]['parch'], data[data['survived']==survive[1]]['parch']]
boxplot(x_data=survive
, y_data=surviveparch
, base_color='b'
, median_color='r'
, x_label='survive'
, y_label='num of parch'
, title='num of parch')
# 单独乘船与否和幸存之间有没有联系(堆积柱状图或者分组柱状图)
disalone = data.groupby(['alone', 'survived']).size().unstack()
print(disalone)
stackedbarplot(x_data=[0, 1]
, y_data_list=[disalone[0], disalone[1]]
, y_data_names=['Yes', 'No']
, colors=['#ff0000', '#00ff00']
, x_label='alone'
, y_label='survived'
, title='alone and survived')
ax = plt.gca()
ax.set_xticks(range(2))
ax.set_xticklabels(disalone.index.values)
plt.show()








关于**.size()**可以看这里
