一、作业要求
给定训练集train.csv,要求根据前9个小时的空气监测情况预测第10个小时的PM2.5含量。
训练集介绍:
- CSV文件,包含台湾丰原地区240天的气象观测资料(取每个月前20天的数据做训练集,12月X20天=240天,每月后10天数据用于测试,对学生不可见);
- 每天的监测时间点为0时,1时…到23时,共24个时间节点;
- 每天的检测指标包括CO、NO、PM2.5、PM10等气体浓度,是否降雨、刮风等气象信息,共计18项;
二、思路分析及代码实现
思路分析:
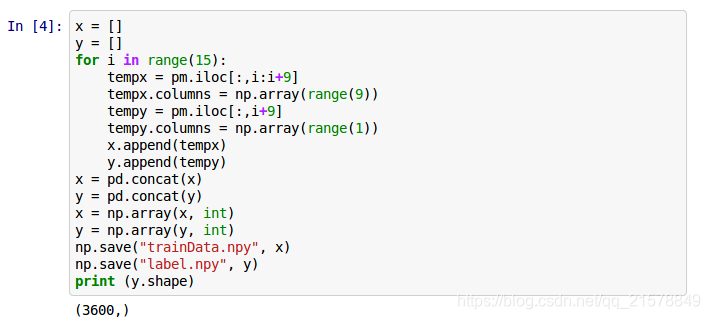
根据作业要求可知,需要用到连续9个时间点的气象观测数据,来预测第10个时间点的PM2.5含量。针对每一天来说,其包含的信息维度为(18,24)(18项指标,24个时间节点)。可以将0到8时的数据截取出来,形成一个维度为(18,9)的数据帧,作为训练数据,将9时的PM2.5含量取出来,作为该训练数据对应的label;同理可取1到9时的数据作为训练用的数据帧,10时的PM2.5含量作为label…以此分割,可将每天的信息分割为15个shape为(18,9)的数据帧和与之对应的15个label。 训练集中共包含240天的数据,因此共可获得240X15=3600个数据帧和与之对应的3600个label。
代码实现:
具体原理可参考:传送门
1. 数据预处理
读入文件,查看文件细目。
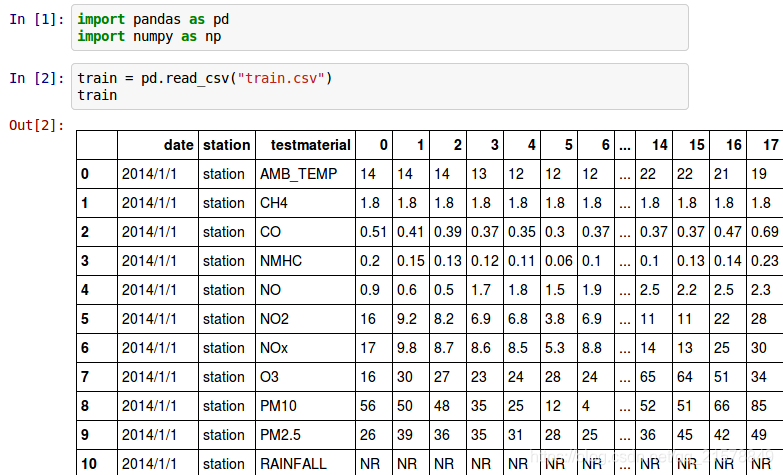
保留PM2.5行,去除其他行。
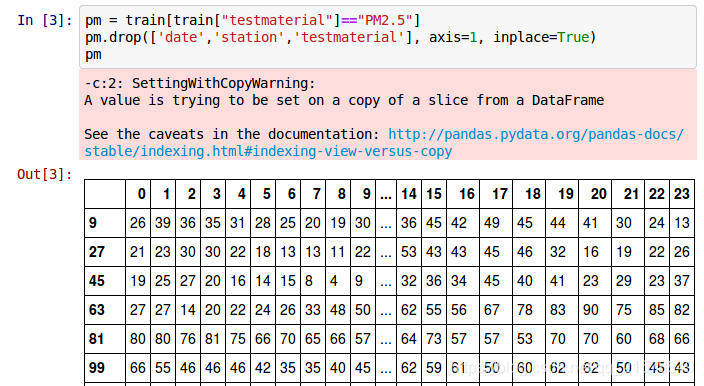
制作traindata和对应的label,并保留为python文件,方便调用。
2. 训练
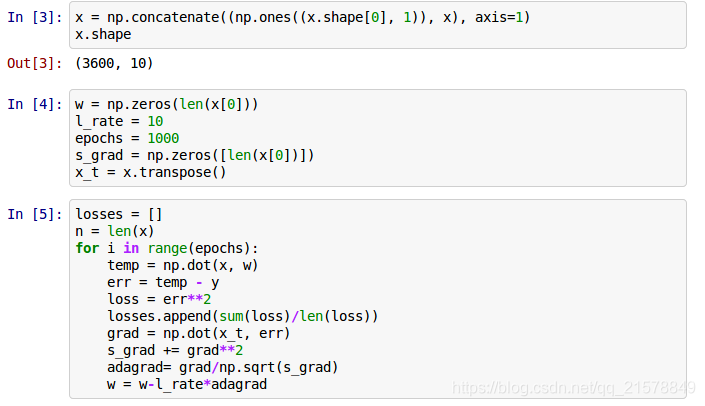
导入保存的数据。

开始利用梯度下降法进行训练。
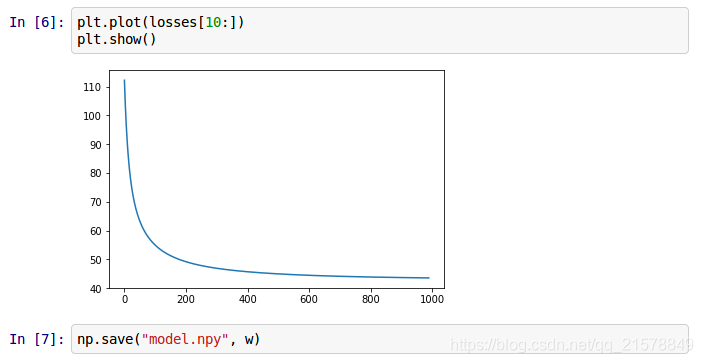
看看loss下降曲线,保留模型文件。
3. 预测
加载模型并进行预测。由于该测试集无label信息,故无法进行评估。

三、模型改进的方向
- 在从csv文件中提取数据帧和label时,本文以天为单位,每天分割出15个数据帧和15个label。事实上,时间是连续的,可以将每月的20天首尾连接,再从其中分割数据帧和label,可使数据帧样本数量大大提升,可能会使模型效果更优。
- 在构建模型时,应充分考虑PM2.5与其他大气成分之间的关系,构建更合理的模型。
- 分割训练集和验证集时,应该按照比例随机抽取数据帧作为训练集和验证集,而不是像本文那样简单地把前3200个数据样本作为训练集,后400个作为验证集。
数据集和代码见:代码地址
