预测PM2.5项目报告
1、项目简介
建立一个模型,根据前9个小时的观测数据预测此时间点的PM2.5值。训练数据集为train.csv,测试数据集为test.csv。
2、项目流程
项目主流程图如图2-1所示。

图2-1 项目主流程图
3、项目实施
依据项目流程,分别进行设计模型,定义LOSS函数,寻找最佳模型步骤。
3.1 设计模型
本次采用的是Linear Regression模型,此模型的关键在于选择features,为此我绘制了训练数据集的各个测项和PM2.5的散点图,通过对散点图的分析,初步选择我认为必要的feature来建立模型。设计模型流程图如3-1所示。

图3-1 设计模型流程图
3.1.1 整理训练集合
训练集合是由多个训练样本组成的集合。一个训练样本是由9个时间点的观测数据组成的集合,其中观测数据包括AMB_TEMP、PM2.5...等18个测项,因此一个训练样本为18*9的矩阵。整理训练集合的Python代码段如下。
'''读取数据'''
data = pd.read_csv('train.csv') #DataFrame类型
del data['datetime']
del data['item']
'''整理训练集合'''
ItemNum=18
X_Train=[] #训练样本features集合
Y_Train=[] #训练样本目标PM2.5集合
for i in range(int(len(data)/ItemNum)):
day = data[i*ItemNum:(i+1)*ItemNum] #一天的观测数据
for j in range(15):
x = day.iloc[:, j:j + 9]
y = int(day.iloc[9,j+9])
X_Train.append(x)
Y_Train.append(y)
通过执行上面的Python代码,将3600个样本分别存入X_Train、Y_Train中。
3.1.2 绘制散点图
为了选择合适的features建立模型,必须初步推测各测项和PM2.5的关系,为此绘制了各测项和PM2.5的散点图。在散点图中一个训练样本的各测项平均值和对应的PM2.5值为一个坐标点,因此每幅散点图都有3600个点。其中绘制测项AMB_TEMP、CH4、CO、NMHC和PM2.5的散点图的Python代码如下,其他测项的散点图可仿照此绘制。
'''绘制散点图'''
x_AMB_TEMP=[]
x_CH4=[]
x_CO=[]
x_NMHC=[]
y=[]
for i in range(len(Y_Train)):
y.append(Y_Train[i])
x=X_Train[i]
#求各测项的平均值
x_AMB_TEMP_sum=0
x_CH4_sum=0
x_CO_sum=0
x_NMHC_sum=0
for j in range(9):
x_AMB_TEMP_sum=x_AMB_TEMP_sum+x.iloc[0,j]
x_CH4_sum = x_CH4_sum + x.iloc[1, j]
x_CO_sum = x_CO_sum + x.iloc[2, j]
x_NMHC_sum = x_NMHC_sum + x.iloc[3, j]
x_AMB_TEMP.append(x_AMB_TEMP_sum / 9)
x_CH4.append(x_CH4_sum / 9)
x_CO.append(x_CO_sum / 9)
x_NMHC.append(x_NMHC_sum / 9)
plt.figure(figsize=(10, 6))
plt.subplot(2, 2, 1)
plt.title('AMB_TEMP')
plt.scatter(x_AMB_TEMP, y)
plt.subplot(2, 2, 2)
plt.title('CH4')
plt.scatter(x_CH4, y)
plt.subplot(2, 2, 3)
plt.title('CO')
plt.scatter(x_CO, y)
plt.subplot(2, 2, 4)
plt.title('NMHC')
plt.scatter(x_NMHC, y)
plt.show()
所有测项和PM2.5的散点图如下





3.1.3 选择features
通过对上面的散点图的观察,我选择了PM10、PM2.5、SO2这三个测项为features。
3.1.4 建立模型
确定了features后,建立的Linear Regression模型如下。
或写成
其中x1到x9是前九个时间点的PM10值,x10到x18是前9个时间点的PM2.5值,x19到x27是前9个时间点的SO2值,w为对应参数,b为偏移项。
3.2 定义LOSS函数
建立好模型之后,下一步就要定义LOSS函数用来训练模型,主要过程如下图所示。
3.2.1 设计LOSS函数
由于本文采用小批量梯度下降算法,所以本文的LOSS函数定义如下。
其中m为每次更新参数时使用的样本数,yi为预测值,yireal为真实值。
3.2.2 小批量梯度下降
由于训练样本总数为3600,如果每次更新参数都使用全部样本,则更新速度很慢,所以采用小批量梯度下降算法,并且设定批量样本大小为50,即每次随机在训练样本中选取50个用来更新参数。算法Python代码如下。
'''小批量梯度下降''' dict={0:8,1:8,2:8,3:8,4:8,5:8,6:8,7:8,8:8,9:9,10:9,11:9,12:9,13:9,14:9,15:9,16:9,17:9,18:12,19:12,20:12,21:12,22:12,23:12,24:12,25:12,26:12} iteration_count = 10000 #迭代次数 learning_rate = 0.000001 #学习速率 b=0.0001 #初始化偏移项 parameters=[0.001]*27 #初始化27个参数 loss_history=[] for i in range(iteration_count): loss=0 b_grad=0 w_grad=[0]*27 examples=list(randint(0, len(X_Train)-1) for index in range(100)) for j in range(100): index=examples.pop() day = X_Train[index] partsum = b+parameters[0]*day.iloc[8,0]+parameters[1]*day.iloc[8,1]+parameters[2]*day.iloc[8,2]+parameters[3]*day.iloc[8,3]+parameters[4]*day.iloc[8,4]+parameters[5]*day.iloc[8,5]+parameters[6]*day.iloc[8,6]+parameters[7]*day.iloc[8,7]+parameters[8]*day.iloc[8,8]+parameters[9]*day.iloc[9,0]+parameters[10]*day.iloc[9,1]+parameters[11]*day.iloc[9,2]+parameters[12]*day.iloc[9,3]+parameters[13]*day.iloc[9,4]+parameters[14]*day.iloc[9,5]+parameters[15]*day.iloc[9,6]+parameters[16]*day.iloc[9,7]+parameters[17]*day.iloc[9,8]+parameters[18]*day.iloc[12,0]+parameters[19]*day.iloc[12,1]+parameters[20]*day.iloc[12,2]+parameters[21]*day.iloc[12,3]+parameters[22]*day.iloc[12,4]+parameters[23]*day.iloc[12,5]+parameters[24]*day.iloc[12,6]+parameters[25]*day.iloc[12,7]+parameters[26]*day.iloc[12,8]-Y_Train[index] loss=loss + partsum * partsum b_grad = b_grad + partsum for k in range(27): w_grad[k]=w_grad[k]+ partsum * day.iloc[dict[k],k % 9] loss_history.append(loss/2) #更新参数 b = b - learning_rate * b_grad for t in range(27): parameters[t] = parameters[t] - learning_rate * w_grad[t]
3.2.3 对比不同学习速率
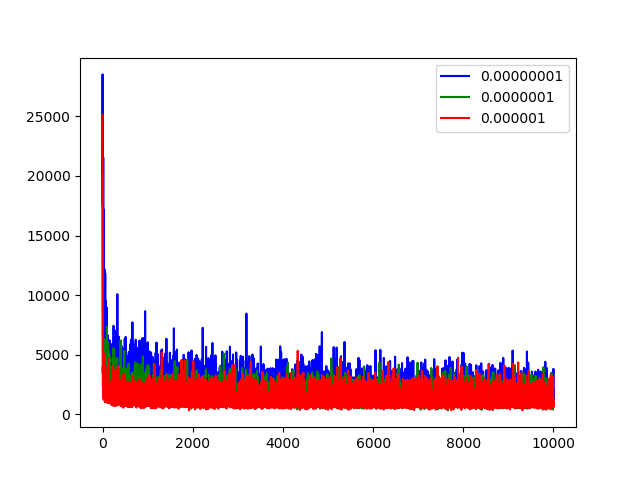
不同的学习速率(learning_rate)具有不同的收敛速度,并且学习速率不能太大也不能太小,否则可能无法收敛,我们的目标就是通过对比不同的学习速率效果选择合适的学习速率。本文对比了学习速率分别为0.000000001、0.0000001、0.000001时,LOSS函数的收敛速度,对比效果图如下。
通过上图的观测,当学习速率为0.000000001时,LOSS函数还没有收敛。综合比较,我们选择学习速率为0.000001。
3.3 评价模型
评价模型必须有一个评价标准和测试样本。评价标准定义为若预测值与真实值平均偏差程度低,则模型可认为比较好。其中预测值与真实值平均偏差程度为预测值和真实值之差的平方和的平均值。公式如下。
其中n为测试样本个数,yi为预测值,yireal为真实值。
通过上一节的模型训练,得到模型中的参数信息如下:b=0.094009700188,w1至w27为-0.00024414418871984743, 0.0065322380472670194, -0.034428213288519256, 0.036410439208129745, -0.00067351251182827402, -0.037578943624287556, 0.053131639445765086, -0.0093018295039533367, 0.084707161386488344, 0.0037371916283829784, -0.037190843223289374, 0.20288159487340029, -0.21007961390387928, -0.016299618105994947, 0.44793865194045185, -0.54222614521017842, 0.0020813724682745499, 0.99117775533044972, -0.1529018576868347, 0.034628423983869026, -0.016670605302613613, -0.031810946878594433, 0.0095443829627392084, -0.0091408654516170473, -0.066416776824896329, 0.13047679687846109, 0.37229316548067898。利用test.csv和answer.csv对模型进行评价,评价Python代码如下。
'''评价模型''' data1 = pd.read_csv('test.csv') del data1['id'] del data1['item'] X_Test=[] ItemNum=18 for i in range(int(len(data1)/ItemNum)): day = data1[i*ItemNum:(i+1)*ItemNum] #一天的观测数据 X_Test.append(day) Y_Test=[] data2 = pd.read_csv('answer.csv') for i in range(len(data2)): Y_Test.append(data2.iloc[i,1]) b=0.00371301266193 parameters=[-0.0024696993501677625, 0.0042664323568029619, -0.0086174899917209787, -0.017547874680980298, -0.01836289806786489, -0.0046459546176775678, -0.031425910733080147, 0.018037490234208024, 0.17448898242705385, 0.037982590870111861, 0.025666115101346722, 0.02295437149703404, 0.014272058968395849, 0.011573452230087483, 0.010984971346586308, -0.0061003639742210781, 0.19310213021199321, 0.45973205224805752, -0.0034995637680653086, 0.00094072189075279807, 0.00069329550591916357, 0.002966257320079194, 0.0050690506276038138, 0.007559004246038563, 0.013296350700555241, 0.027251049329127801, 0.039423988570899793] Y_predict=[] for i in range(len(X_Test)): day=X_Test[i] p=b+parameters[0]*day.iloc[8,0]+parameters[1]*day.iloc[8,1]+parameters[2]*day.iloc[8,2]+parameters[3]*day.iloc[8,3]+parameters[4]*day.iloc[8,4]+parameters[5]*day.iloc[8,5]+parameters[6]*day.iloc[8,6]+parameters[7]*day.iloc[8,7]+parameters[8]*day.iloc[8,8]+parameters[9]*day.iloc[9,0]+parameters[10]*day.iloc[9,1]+parameters[11]*day.iloc[9,2]+parameters[12]*day.iloc[9,3]+parameters[13]*day.iloc[9,4]+parameters[14]*day.iloc[9,5]+parameters[15]*day.iloc[9,6]+parameters[16]*day.iloc[9,7]+parameters[17]*day.iloc[9,8]+parameters[18]*day.iloc[12,0]+parameters[19]*day.iloc[12,1]+parameters[20]*day.iloc[12,2]+parameters[21]*day.iloc[12,3]+parameters[22]*day.iloc[12,4]+parameters[23]*day.iloc[12,5]+parameters[24]*day.iloc[12,6]+parameters[25]*day.iloc[12,7]+parameters[26]*day.iloc[12,8] Y_predict.append(p) def dev_degree(y_true,y_predict): #评价函数 sum=0 for i in range(len(y_predict)): sum=sum+(y_true[i]-y_predict[i])*(y_true[i]-y_predict[i]) return sum/len(y_predict) print(dev_degree(Y_Test,Y_predict))
计算得到预测值与真实值平均偏差程度为45.6833333333,另外计算模型的决定系数为0.906793065984,即表明我们有90%的几率相信这个预测值。
3.4 总结
在项目进行的过程中,遇到了许许多多的问题,总结如下几点。
1.在小批量梯度下降算法中,参数的初始值也很重要,如果初始值不合理,可以会使得收敛很慢。学习速率不是一定的,可以逐渐递进试探,得到较佳的学习速率,当然采用自适应学习速率法有可能更好。
2.在过程中踩到的最大的一个坑,居然是random.randint(a,b)函数,我一直以为是生成[a,b)之间的整数,导致列表越界,其实random.randint(a,b)函数是生成[a,b]之间的整数。
获取更多干货请关注微信公众号:追梦程序员。