数据的分组和聚合
在数据分析中,我们时常会遇到把数据进行分组或者把数据进行聚合的操作,比如我说:我有一组瓜子二手车的数据里面包括了品牌名,所在城市,排放量,自动挡非自动挡等等,我想要分出自动挡和非自动挡两个类别应该怎么做,这就涉及到数据的分组操作。
import numpy as np
import pandas as pd
df1 = pd.DataFrame({'fruit':['apple','banana','orange','apple','banana'],
'color':['red','yellow','yellow','cyan','cyan'],
'price':[8.5,6.8,5.6,7.8,6.4]})
df1
# 输出
fruit color price
0 apple red 8.5
1 banana yellow 6.8
2 orange yellow 5.6
3 apple cyan 7.8
4 banana cyan 6.4
现在我们把上面dataframe按照fruit分类:
g = df1.groupby(by='fruit') # 组
print(g)
<pandas.core.groupby.groupby.DataFrameGroupBy object at 0x0000021E0948BA20>
# 我们得到的是一个分组后的对象 这个对象是可以迭代的
# 并且每个迭代的对象都是一个含有两个元素的元组
for name,group in g:
print(name) # 输出组名
print('-'*100)
print(group) # 数据块 dataframe类型
print(type(group))
# 输出
apple
----------------------------------------------------------------------------------------------------
fruit color price
0 apple red 8.5
3 apple cyan 7.8
<class 'pandas.core.frame.DataFrame'>
banana
----------------------------------------------------------------------------------------------------
fruit color price
1 banana yellow 6.8
4 banana cyan 6.4
<class 'pandas.core.frame.DataFrame'>
orange
----------------------------------------------------------------------------------------------------
fruit color price
2 orange yellow 5.6
<class 'pandas.core.frame.DataFrame'>
我们可以通过这个例子,将我们分组后的数据转换成字典的形式,方便我们取用:
a_lis = list([('a',1),('b',2)])
a_dic = dict(a_lis)
a_dic
# 输出
{'a': 1, 'b': 2}
所以:
# 选取任意数据块
dict(list(df1.groupby(by='fruit')))['apple']
# 输出的是dataframe的格式
fruit color price
0 apple red 8.5
3 apple cyan 7.8
我们也可以通过字典或者series可以进行分组:
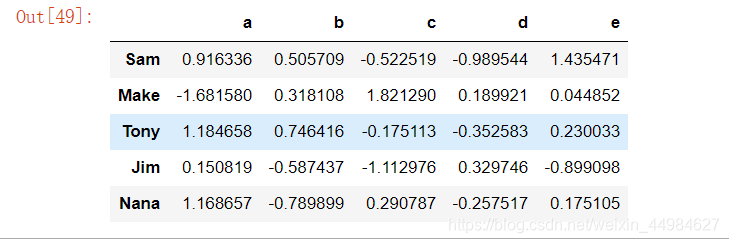
people = pd.DataFrame(np.random.randn(5, 5),
columns=['a', 'b', 'c', 'd', 'e'],
index=['Sam', 'Make', 'Tony', 'Jim', 'Nana'])
people
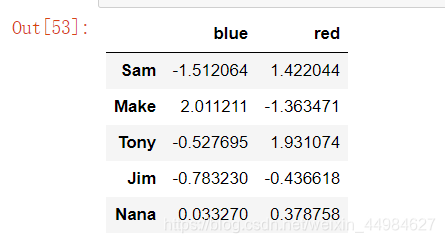
# 通过字典进行分组
m = {'a': 'red', 'b': 'red', 'c': 'blue','d': 'blue', 'e': 'red', 'f' : 'orange'}
# 指定 axis=1 是指定对列上的列名进行分组
people.groupby(m,axis=1).sum()
# 通过 series 进行分组
s1 = pd.Series(m)
s1
a red
b red
c blue
d blue
f orange
dtype: object
people.groupby(s1,axis=1).count()
#输出
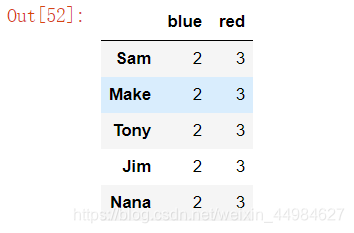
# 我们还可以通过函数分组
# 这里的意思是把名字的长度分组3个字 和4个字 因为axis=0是默认的
people.groupby(len).sum()
# 输出

聚合
| 函数名 | 描述 |
|---|---|
| count | 分组中非NA值的数量 |
| sum | 非NA值的和 |
| mean | 非NA值的平均值 |
| median | 非NA值的中位数 |
| std, var | 标准差和方差 |
| min, max | 非NA的最小值,最大值 |
| prod | 非NA值的乘积 |
| first, last | 非NA值的第一个,最后一个 |
下面我们根据水果来求平均值:
- 先分类,按照水果分类
- 利用求平均值函数求
g1 = df1.groupby(['fruit'])[['price']].mean() # stack() unstack()
g1
# 输出的是 dataframe
price
fruit
apple 8.15
banana 6.60
orange 5.60
g2 = df1.groupby(['fruit'])['price'].mean() # stack() unstack()
g2
# 输出的是 series
fruit
apple 8.15
banana 6.60
orange 5.60
Name: price, dtype: float64
# 我们在 price 这里加了两个括号 输出就变成了dataframe 这是语法糖的原因,因为对程序员友好,节省了大量的代码,所有称之为语法糖。
g3 = df1[[price]].groupby(df1['fruit']).mean()
# 效果如g1 只是写法不同
如果我们想要上面的索引不是水果名称而是0123则可以设置as_index参数:
# as_index 默认为True
df1.groupby('fruit',as_index=False)[['price']].mean()
fruit price
0 apple 8.15
1 banana 6.60
2 orange 5.60
除了上面的聚合函数,我们也可以自定义聚合函数:
# 自定义聚合函数
# 水果的差价 每种水果中不同颜色的差价 最大减最小
def diff(arr):
return arr.max() - arr.min()
# agg aggregate apply 三则可以相互替换
df1.groupby('fruit',as_index=True)[['price']].apply(diff)
price
fruit
apple 0.7
banana 0.4
orange 0.0
语法糖
语法糖:指计算机语言中添加的某种语法,这种语法对语言的功能并没有影响,但是更方便程序员使用。通常来说使用语法糖能够增加程序的可读性,从而减少程序代码出错的机会。
