数据分组
首先导入所需要的模块
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from pandas import DataFrame,Series
import numpy as np
数据的读取
tips=sns.load_dataset('tips')
print(tips.head())
这个结果返回的是前五行数据。
head(n=5) 这个方法默认情况下是返回前五行数据,改变n,可以输出n行数据。
如n=10时输出:

读取过程中,也许会报错:

这个时候,我们可以检查源代码,点住load_dataset按ctrl加鼠标左键,发现原来这个数据是从网上读取的 。

通过找到这个网址进行下载:
不过,上面还有其他数据 ,把它们全部下载下来即可,是一个压缩包

不过,这里我有数据:
链接:https://pan.baidu.com/s/1NI9whg-fJ1CRyus2e25JxQ
提取码:obgz
下载下来即可:
也可以这样读取:
tips=pd.read_csv(open('./tips.csv'))
print(tips.head())
不过要把下载的文件放到同一个文件夹下面
group_1=tips['tip'].groupby(tips['sex'])
print(group_1) # group_1为GroupBy对象,是保存的中间数据,可以通过mean方法即可返回数据

data_mean=tips['tip'].groupby(tips['sex']).mean() #返回的是一个Series数据
print(data_mean)
data_mean_1=tips['tip'].groupby([tips['day'],tips['time']]).mean()
print(data_mean_1)

为了使结果更加清晰,可以通过作图发现
data_mean_1.plot(kind='barh')
plt.show()

GroupBy对象是可以迭代的,其构造为一组二元元组
for i,j in tips.groupby(tips['sex']):
print(i)
print(j)

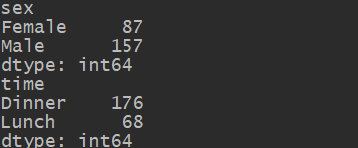
size方法可以返回各分组的大小
print(tips.groupby(tips['sex']).size())
print(tips.groupby(tips['time']).size())
按列名进行分组
print(tips.groupby('smoker').mean())
df_2=tips.groupby('smoker').mean()
df_2['total_bill'].plot(kind='bar')
plt.show()


tips是多列DataFrame的数据,如果只需要获取tip 列的数据,通过索引选取即可。但GroupBy对象也可以通过索引tip列,然后再进行聚合运算。
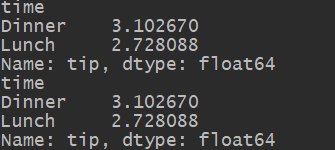
print(tips['tip'].groupby(tips['time']).mean())
print(tips.groupby('time')['tip'].mean())
按列表或元组分组
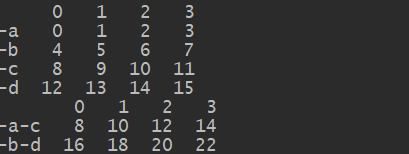
df_1=DataFrame(np.arange(8).reshape(4,2))
list_1=['-a','-b','-a','-b']
print(df_1)
print(df_1.groupby(list_1).sum())

按字典分组
如果原始的DataFrame中的分组信息很难确定或者不存在,可通过字典结构,定义分组信息。
df_3=DataFrame(np.arange(16).reshape(4,4),index=['-a','-b','-c','-d'])
print(df_3)
print(df_3.groupby(
{'-a': '-a-c',
'-b': '-b-d',
'-c': '-a-c',
'-d': '-b-d'
}).sum())
按函数分组
函数作为分组键的原理类似于字典,通过映射关系进行分组,但是函数分组更加灵活。
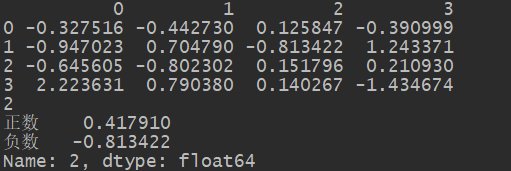
df_4=DataFrame(np.random.randn(4,4))
def f(x):
if x>0:
return '正数'
elif x==0:
return '零'
else:
return '负数'
print(df_4)
print(df_4[2].groupby(df_4[2].map(f)).sum())
对于层次化索引,可以通过级别进行分组
df_5=DataFrame(np.arange(12).reshape(4,3),index=
[['a','a','b','b'],['--a','--b','--a','--b']])
print(df_5)
print(df_5.groupby(level=0).sum())
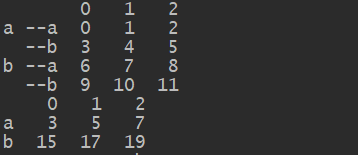
也可在列上进行分组
df_6=DataFrame(np.arange(12).reshape(3,4),columns=
[['a','a','b','b'],['--a','--b','--a','--b']])
print(df_6)
print(df_6.groupby(level=1,axis=1).sum())

