对数据集进行分组并对各组应用一个函数,通常是数据分析工作中的重要环节。在将数据集加载、融合、准备好之后,通常就是计算分组统计或生成透视表。pandas提供了一个灵活高效的gruopby功能,它使你能以一种自然的方式对数据集进行切片、切块、摘要等操作。
=====================================
本系列内容:使用一个或多个键(形式可以是函数、数组或DataFrame列名)分割pandas对象。计算分组的概述统计。 应用组内转换或其他运算。 计算透视表或交叉表。 执行分位数分析以及其它统计分组分析。
对时间序列数据的聚合(groupby的特殊用法之一)也称作重采样
GroupBy机制
一个用于表示分组运算的术语"split-apply-combine"(拆分-应用-合并)。第一个阶段,pandas对象(无论 是Series、DataFrame还是其他的)中的数据会根据你所提供的一个或多个键被拆分(split)为多组。拆分操作是在对象的特定轴上执行的。然后,将一个函数应用(apply)到 各个分组并产生一个新值。最后,所有这些函数的执行结果会被合并(combine) 到最终的结果对象中。结果对象的形式一般取决于数据上所执行的操作。
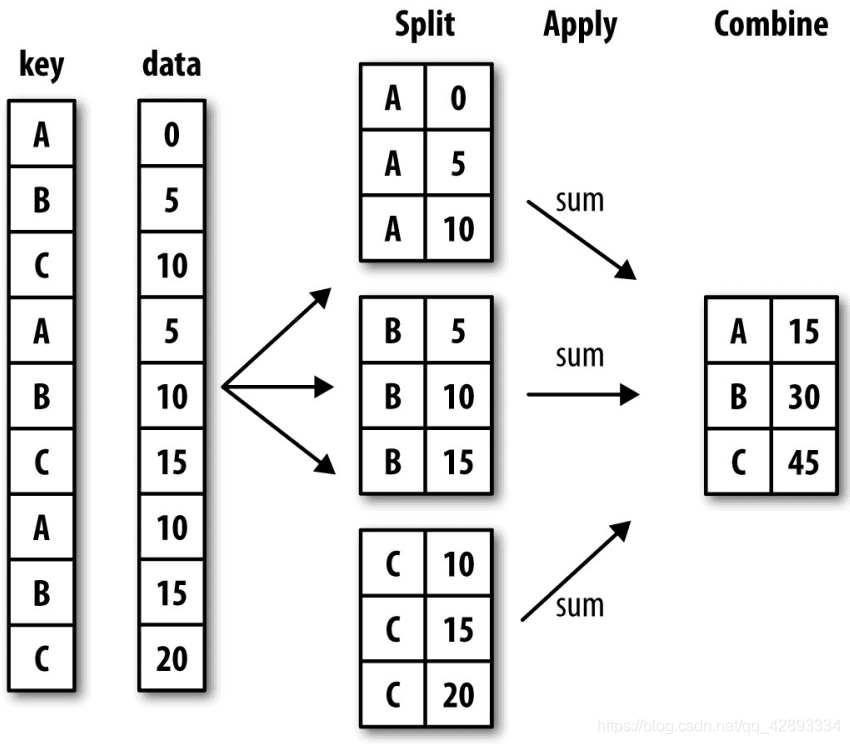
=====================================
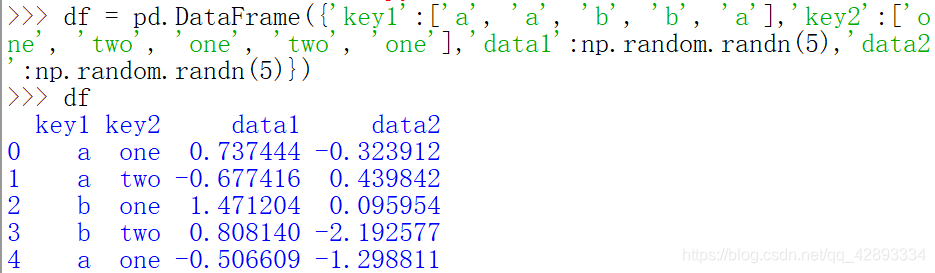
按key1进行分组,并计算data1列的平均值。访问data1,并根据key1调用groupby。

=====================================
变量grouped是一个GroupBy对象。它实际上还没有进行任何计算,只是含有一些有关分组键df[‘key1’]的中间数据而已。该对象已经有了接下来对各分组执行运算所需的一切信息。

=====================================
数据(Series)根据分组键进行了聚合,产生了一个新的Series,其索引为key1列中的唯一值。之所以结果中索引的名称为key1,是因为原始DataFrame的列df[‘key1’]就叫这个名字。

=====================================
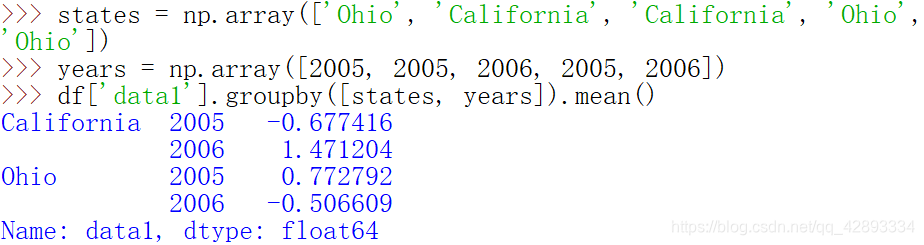
通过两个键对数据进行了分组,得到的Series具有一个层次化索引(由唯一的键对组成)

=====================================
分组键均为Series,分组键可以是任何长度适当的数组
=====================================
分组信息就位于相同的要处理DataFrame中。可以将列名(可以是字符串、数字或其他Python对象)用作分组键

=====================================
GroupBy的size方法,它可以返回一 个含有分组大小的Series

任何分组关键词中的缺失值,都会被从结果中除去
++++++++++++++++++++++++++++++++++++
