Mapreduce单词计数
=================================================================================================
一. Mapreduce工作原理(简)


二. Mapreduce工作原理(繁)


三. 案例实操之单词计数
1.Mapper部分
package com.mr.wc;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMapper extends Mapper<LongWritable, Text,Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String data = value.toString();
String[] strings = data.split(" ");
for(String word : strings){
context.write(new Text(word),new IntWritable(1));
}
}
}

2. Reducer部分
package com.mr.wc;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WordCountReducer extends Reducer<Text, IntWritable,Text,IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum=0;
for(IntWritable v : values){
sum = sum + v.get(); //for循环内
}
context.write(key,new IntWritable(sum)); //for循环外
}
}
3.Driver部分
package com.mr.wc;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.Job;
public class WCDriver {
public static void main(String[] args) throws Exception{
Job job = Job.getInstance();
job.setMapperClass(WordCountMapper.class);//mapper在哪
job.setMapOutputKeyClass(Text.class);//mapper key类型
job.setMapOutputValueClass(IntWritable.class);//mapper value类型
job.setReducerClass(WordCountReducer.class);//reducer在哪
job.setMapOutputKeyClass(Text.class);//reducer key类型
job.setMapOutputValueClass(IntWritable.class);//reducer value类型
FileInputFormat.setInputPaths(job,new Path("D:\\wordcount.txt"));
FileOutputFormat.setOutputPath(job,new Path("D:\\map\\"));
boolean completion = job.waitForCompletion(true);
if(completion){
System.out.println("运行成功");
}
else
System.out.println("运行失败");
}
}
运行结果


可能遇到的运行报错:

或者是叫

解决方法:
1.将hadoop-2.7.3.tar.gz解压到本地某个路径,如D盘底下
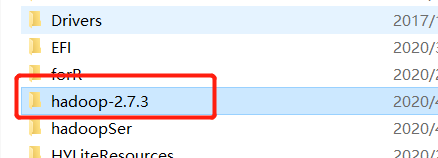
2.配置本机的hadoop环境变量



3.进入hadoop2.7.3文件夹,进去bin文件夹,放入这两个hadoop依赖的二进制文件winutils.exe和hadoop.dll动态链接库,(找我要,这里放不了链接)
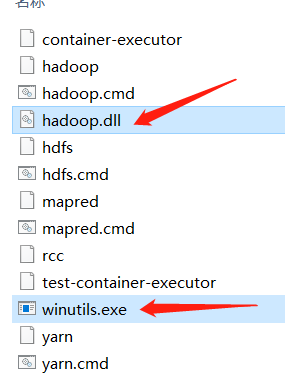
4.将hadoop.dll放入C:\windows\system32文件夹下

5. 重启idea
