开篇
补上之前缺失的TensorFlow基础,这两天要放五一假了,又可以把缺上的东西拿来补一补,错失了很多大厂的面试机会,也深感自己基础的不扎实。之前的逻辑回归,我们讲的是二分类问题,但是现实中,我们要做的往往是多分类。所以训练一个多分类的模型是十分必要的,今天我们就来说说神经网络中最常见的多分类模型,softmax。
softmax
和逻辑回归的模型函数sigmoid一样,softmax也是神经网络中的一种激活函数,但它通常是放在最后一层的,也就是我们的输出层,它会输出每一个类别的概率,而概率最大的那个类别就是我们需要的结果,不同于大部分的激活函数,softmax会同时作用在它那一层的所有神经元来产生输出。下面让我们看具体的图示和公式形式。

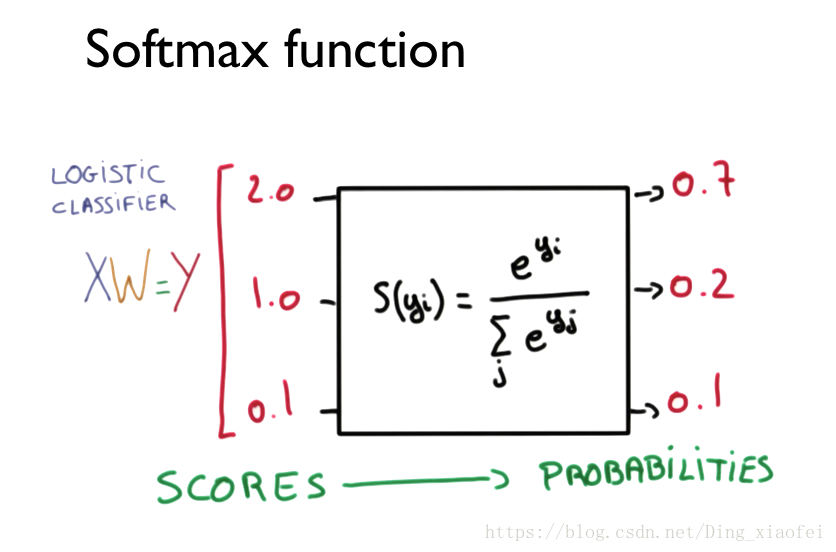
在TensorFlow中整个softmax函数可以写成这样
hypothesis = tf.nn.softmax(tf.matmul(X,W)+b)
依旧是我们的机器学习三要素,模型函数、损失函数、优化算法,softmax的模型函数和逻辑回归的模型函数差不多,都是可以由生成模型推导过来的,所以它们的输出结果以概率的形式呈现不足为奇。同时softmax的损失函数也是和逻辑回归的损失函数是类似的。当softmax只处理二分类问题的时候,它的数学表现形式是和逻辑回归一致的。
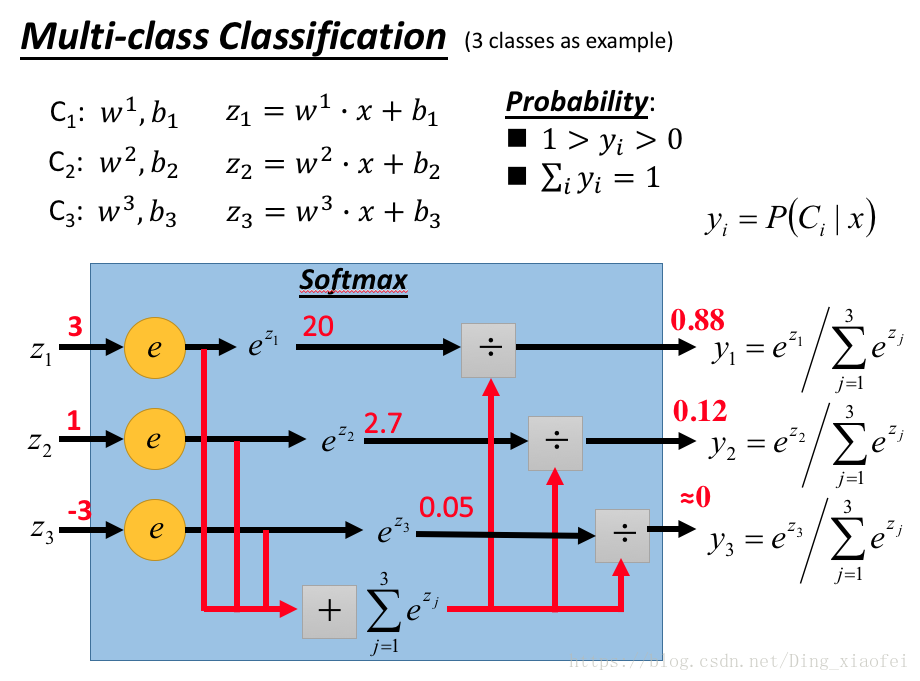
损失函数其实就是典型的交叉熵,有的教材也把它称之为对数似然函数。我更加愿意把它看做一个交叉熵,去衡量两个分布之间的相似性,如下图所示:
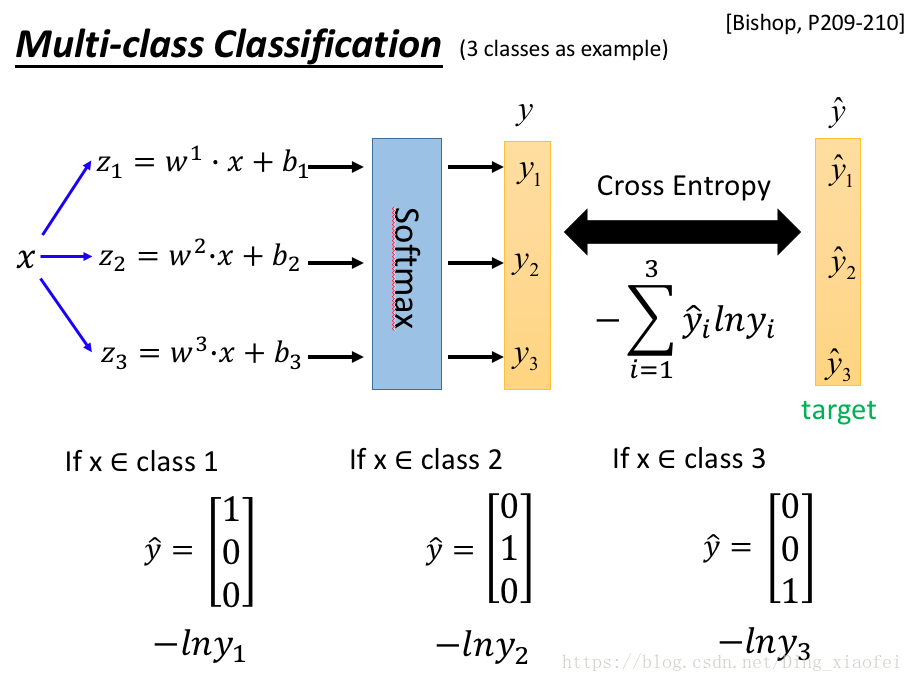
关于softmax再多几句废话,softmax在深度学习中有着很重要的作用,包括后面我们要提到的seq2seq模型,因为我们大部分的深度学习应用还是以分类为主的。分类是很重要的一块。
hypothesis = tf.nn.softmax(tf.matmul(X,W)+b)
# Cross entropy cost/loss
cost = tf.reduce_mean
(-tf.reduce_sum(Y * tf.log(hypothesis), axis=1))
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.1).
minimize(cost)
OK,附上完整的代码
# Lab 6 Softmax Classifier
import tensorflow as tf
tf.set_random_seed(777) # for reproducibility
x_data = [[1, 2, 1, 1],
[2, 1, 3, 2],
[3, 1, 3, 4],
[4, 1, 5, 5],
[1, 7, 5, 5],
[1, 2, 5, 6],
[1, 6, 6, 6],
[1, 7, 7, 7]]
y_data = [[0, 0, 1],
[0, 0, 1],
[0, 0, 1],
[0, 1, 0],
[0, 1, 0],
[0, 1, 0],
[1, 0, 0],
[1, 0, 0]]
X = tf.placeholder("float", [None, 4])
Y = tf.placeholder("float", [None, 3])
nb_classes = 3
W = tf.Variable(tf.random_normal([4, nb_classes]), name='weight')
b = tf.Variable(tf.random_normal([nb_classes]), name='bias')
# tf.nn.softmax computes softmax activations
# softmax = exp(logits) / reduce_sum(exp(logits), dim)
hypothesis = tf.nn.softmax(tf.matmul(X, W) + b)
# Cross entropy cost/loss
cost = tf.reduce_mean(-tf.reduce_sum(Y * tf.log(hypothesis), axis=1))
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.1).minimize(cost)
# Launch graph
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for step in range(2001):
sess.run(optimizer, feed_dict={X: x_data, Y: y_data})
if step % 200 == 0:
print(step, sess.run(cost, feed_dict={X: x_data, Y: y_data}))
print('--------------')
# Testing & One-hot encoding
a = sess.run(hypothesis, feed_dict={X: [[1, 11, 7, 9]]})
print(a, sess.run(tf.argmax(a, 1)))
print('--------------')
b = sess.run(hypothesis, feed_dict={X: [[1, 3, 4, 3]]})
print(b, sess.run(tf.argmax(b, 1)))
print('--------------')
c = sess.run(hypothesis, feed_dict={X: [[1, 1, 0, 1]]})
print(c, sess.run(tf.argmax(c, 1)))
print('--------------')
all = sess.run(hypothesis, feed_dict={
X: [[1, 11, 7, 9], [1, 3, 4, 3], [1, 1, 0, 1]]})
print(all, sess.run(tf.argmax(all, 1)))
'''
--------------
[[ 1.38904958e-03 9.98601854e-01 9.06129117e-06]] [1]
--------------
[[ 0.93119204 0.06290206 0.0059059 ]] [0]
--------------
[[ 1.27327668e-08 3.34112905e-04 9.99665856e-01]] [2]
--------------
[[ 1.38904958e-03 9.98601854e-01 9.06129117e-06]
[ 9.31192040e-01 6.29020557e-02 5.90589503e-03]
[ 1.27327668e-08 3.34112905e-04 9.99665856e-01]] [1 0 2]
'''