Zookeeper和Hadoop分布式集群搭建
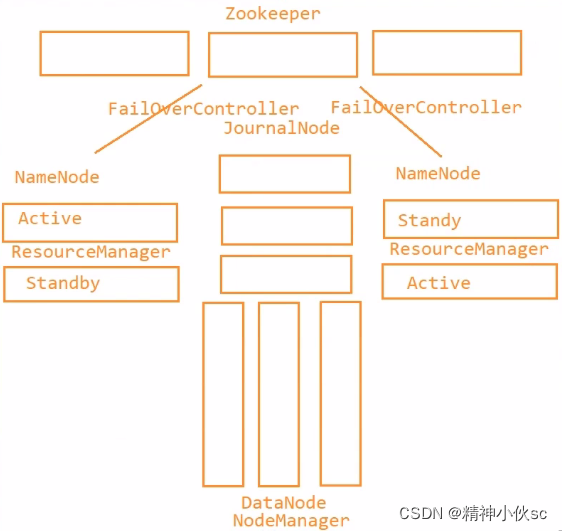
用三台虚拟机搭建如上集群
Zookeeper下载地址:
https://www.apache.org/dyn/closer.lua/zookeeper/zookeeper-3.5.8/apache-zookeeper-3.5.8-bin.tar.gz
Hadoop下载地址:https://archive.apache.org/dist/hadoop/common/hadoop-3.1.3/
环境配置:JDK1.8+Zookeeper3.5.8+hadoop-3.1.3(使用三台机器搭建实现上图集群)
1.三台主机关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
2.修改三台主机的主机名
vim /etc/hostname
改成hadoop01、hadoop02、hadoop03
3.将主机名和IP进行映射
vim /etc/hosts
然后将三台主机的主机名和IP配置
4.关闭SELINUX
vim /etc/selinux/config
将SELINUX的值改为disabled
5.三台主机重启
reboot
6.三台主机之间需要相互免密
ssh-keygen
ssh-copy-id root@hadoop01(发向三台,hadoop02,hadoop03服务器同理)
测试:ssh hadoop01(尝试连接),如果不需要密码,那么输入logout
7.在第一台主机上进入software目录,下载或者上传jdk8的安装包
tar -xvf jdk-8u321-linux-x64.tar.gz
配置环境变量 vim /etc/profile
末尾追加
export JAVA_HOME=/home/software/jdk1.8.0_321
export PATH=$JAVA_HOME/bin:$PATH
source /etc/profile
hadoop01,hadoop02同理
8.在第一台主机上进入software目录,下载或者上传apache-zookeeper-3.6.3-bin.tar.gz的安装包
tar -xvf apache-zookeeper-3.6.3-bin.tar.gz
9. 进入/home/software/zookeeper-3.6.3/conf下
mv zoo_sample.cfg zoo.cfg
修改其中参数dataDir=/home/software/zookeeper-3.6.3/tmp
末尾再加上
server.1=192.168.112.128:2888:3888
server.2=192.168.112.129:2888:3888
server.3=192.168.112.130:2888:3888
4lw.commands.whitelist=*
10.返回/home/software/zookeeper-3.6.3/下
mkdir tmp
cd tmp
新建myid并在文件中写入1
11.传到别的服务器并且修改所有myid文件
12.启动zookeeper
cd /home/software/zookeeper-3.6.3/bin
./zkServer.sh start
11.在第一台主机上进入software目录,下载或者上传hadoop的安装包
放入 /home/software目录下
解压
tar -xvf hadoop-3.1.3.tar.gz
12.进入Hadoop的配置目录
cd /home/software/hadoop-3.1.3.tar.gz/etc/hadoop
13.编辑文件
vim hadoop-env.sh
添加JAVA_HOME,例如
export JAVA_HOME=/home/software/jdk1.8.0_321
保存退出,重新生效
source hadoop-env.sh
14.编辑文件
vim core-site.xml
添加内容加入中
<!--指定文件系统名称,实际上是在Zookeeper上注册的名称-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns</value>
</property>
<!--数据存储目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/software/hadoop-3.1.3/tmp</value>
</property>
<!--Zookeeper连接地址-->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value>
</property>
15.编辑文件
vim hdfs-site.xml
添加内容加入中
<!--执行hdfs的nameservice为ns,注意要和core-site.xml中的名称保持一致-->
<property>
<name>dfs.nameservices</name>
<value>ns</value>
</property>
<!--ns集群下namenode的别名-->
<property>
<name>dfs.ha.namenodes.ns</name>
<value>nn1,nn2,nn3</value>
</property>
<!--nn1的RPC通信-->
<property>
<name>dfs.namenode.rpc-address.ns.nn1</name>
<value>hadoop01:9000</value>
</property>
<!--nn2的RPC通信-->
<property>
<name>dfs.namenode.rpc-address.ns.nn2</name>
<value>hadoop02:9000</value>
</property>
<!--nn3的RPC通信-->
<property>
<name>dfs.namenode.rpc-address.ns.nn3</name>
<value>hadoop03:9000</value>
</property>
<!--nn1的http通信-->
<property>
<name>dfs.namenode.http-address.ns.nn1</name>
<value>hadoop01:9870</value>
</property>
<!--nn2的http通信-->
<property>
<name>dfs.namenode.http-address.ns.nn2</name>
<value>hadoop02:9870</value>
</property>
<!--nn3的http通信-->
<property>
<name>dfs.namenode.http-address.ns.nn3</name>
<value>hadoop03:9870</value>
</property>
<!--指定namenode的元数据在JournamlNode上存放的位置,这样,namenode2可以从journalnode集群里的指定位置上获取信息,达到热备效果-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop01:8485;hadoop02:8485;hadoop03:8485/ns</value>
</property>
<!--指定JournamNode在本地磁盘存放数据的位置-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/software/hadoop-3.1.3/tmp/journal</value>
</property>
<!--配置namenode存放元数据的目录,可以不配置,如果不配置则默认放到hadoop.tmp.dir下-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///home/software/hadoop-3.1.3/tmp/hdfs/name</value>
</property>
<!--配置datanode存放元数据的目录,可以不配置,如果不配置则默认放到hadoop.tmp.dir下-->
<property>
<name>dfs.namenode.data.dir</name>
<value>file:///home/software/hadoop-3.1.3/tmp/hdfs/data</value>
</property>
<!--开启NameNode故障时自动切换-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!--配置失败自动切换实现方式-->
<property>
<name>dfs.client.failover.proxy.provider.ns</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!--配置隔离机制-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!--使用隔离机制时需要ssh免登录-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!--配置副本机制-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--设置用户的操作权限,false表示关闭权限验证,任何用户都可以操作-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
16.编辑文件
vim mapred-site.xml
添加内容加入中
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
17.编辑文件
vim yarn-site.xml
添加内容加入中
<!--配置yarn的高可用-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--在Zookeeper注册的名称-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>ns-yarn</value>
</property>
<!--指定两个resourcemanager的名称-->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!--配置rm1的主机-->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop01</value>
</property>
<!--配置rm2的主机-->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop03</value>
</property>
<!--开启yarn恢复机制-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--执行rm恢复机制实现类-->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!--配置zookeeper的地址-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value>
</property>
<!--指定nodemanager启动时加载server的方式为shuffleserver-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--指定resourcemanager地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop03</value>
</property>
18.编辑文件
vim workers
删掉localhost,将三台主机的主机名写上
19.进入Hadoop安装目录下的子目录sbin下
cd /home/software/hadoop-3.1.3/sbin/
20.编辑文件
vim start-dfs.sh
在文件头部添加
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
HDFS_JOURNALNODE_USER=root
HDFS_ZKFC_USER=root
21.编辑文件
vim start-yarn.sh
在文件头部添加
YARN_RESOURCEMANAGER_USER=root
YARN_NODEMANAGER_USER=root
HDFS_DATANODE_SECURE_USER=yarn
19.远程拷贝给另外两台主机
cd /home/software
scp -r hadoop-3.1.3 root@hadoop02:$ PWD
scp -r hadoop-3.1.3 root@hadoop03:$ PWD
22.三台主机配置环境变量
vim /etc/profile
在文件末尾添加
export HADOOP_HOME=/home/software/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
保存退出,重新生效
source /etc/profile
可以通过hadoop version来查看是否配置成功

23.三台主机需要启动Zookeeper
cd /home/software/zookeeper-3.5.7/bin
sh zkServer.sh start
sh zkServer.sh status
如果出现了1个leader+2个follower表示启动成功
24.在一台主机格式化Zookeeper-实际上就是在Zookeeper上注册节点
hdfs zkfc -formatZK
如果出现Successfully created /hadoop-ha/ns in ZK.表示格式化成功
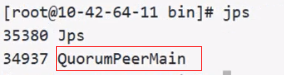
25.在三台主机上启动JournalNode
hdfs --daemon start journalnode(jps可查看多了一个JournalNode进程)
26.在第一台主机上格式化NameNode
hadoop namneode -format
如果出现Storage directory /home/software/hadoop-3.1.3/tmp/hdfs/name has been successfully formatted.表示格式化成功
(注意:格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到以往数据。如果集群在允许过程中报错,需要重新格式化NameNode的话,一定要先停止namenode和datanode进程,并且要刹车农户所有机器的data和logs目录,然后再进行格式化。)
27.在第一台主机上启动NameNode
hdfs --daemon start namenode
28.在第二台和第三台上格式化NameNode
hdfs namenode -bootstrapStandby
如果出现Storage directory /home/software/hadoop-3.1.3/tmp/hdfs/name has been successfully formatted.表示格式化成功
29.在第二台和第三台主机上启动NameNode
hdfs --daemon start namenode
30.在三台节点上启动DataNode
hdfs --daemon start datanode
31.在三个节点上启动zkfc
hdfs --daemon start zkfc
32.在第三台上启动YARN
start-yarn.sh
通过jps查看,第一台主机上出现:
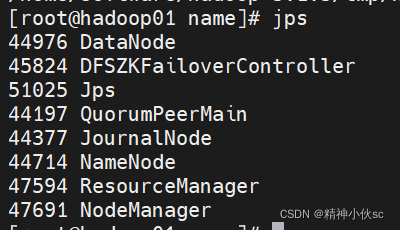
第二台主机上出现:
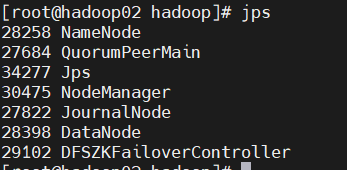
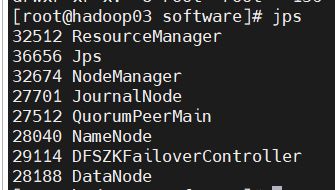
第三台主机上出现:
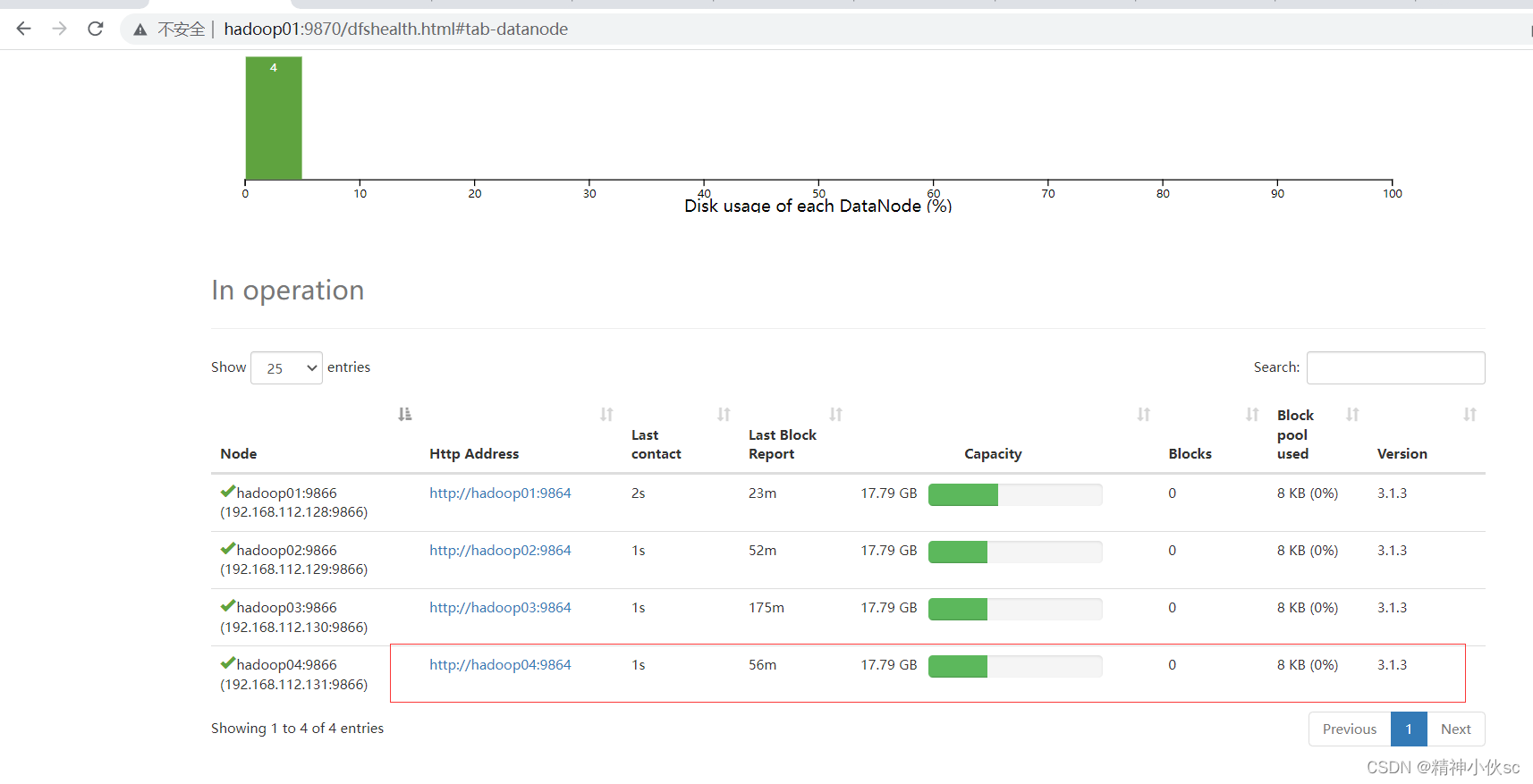
服役新节点
①先修改新节点的主机名
vim /etc/hostname
将主机名改成对应的名字,例如hadoop04
②进行主机名和IP的映射
vim /etc/hosts
需要将所有云主机的IP和主机名都进行映射
远程拷贝给其他主机
scp -r /etc/hosts root@haddoop01:/home/software
scp -r /etc/hosts root@haddoop02:/home/software
scp -r /etc/hosts root@haddoop03:/home/software
③重启
reboot
④配置免密互通
ssh-keyen
ssh-copy-id root@hadoop01
ssh hadoop01 —如果不需要密码,则输入logout
ssh-copy-id root@hadoop02
ssh hadoop02 —如果不需要密码,则输入logout
ssh-copy-id root@hadoop03
ssh hadoop03 —如果不需要密码,则输入logout
⑤所有的主机都需要和新添加的节点进行免密
ssh-copy-id root@hadoop04
ssh hadoop04 —如果不需要密码,则输入logout
⑥从其他节点拷贝一个Hadoop安装目录到第四个节点上
scp -r /home/software/hadoop-3.1.3 root@hadoop:/hadoop-3.1.3
⑦新添加的节点上,进入Hadoop的安装目录,然后删除对应的目录
cd /home/software/hadoop-3.1.3/
rm -rf tmp
rm -rf logs
⑧新节点配置环境
vim /etc/profile
在文件末尾添加
export HADOOP_HOME=/home/software/hadoop-3.1.3
export PATH=P A T H : PATH:PATH:HADOOP_HOME/bin:$HADOOP_HOME/sbin
保存退出,重新生效
⑨启动DataNode
hdfs --deomon start datanode
⑩启动YARN
yarn --daemon start nodemanager