前言
本篇文章不讲解任何算法,只是针对CV的发展历程和当前应用算法进行简单介绍,希望不了解的或者想从事计算机视觉研究的小白们有个大概的认识
CV四大任务
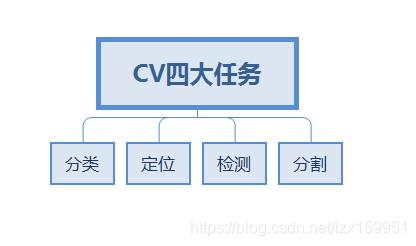
- 分类,也就是解释图片上的物体是什么
- 定位,图片上物体的位置在哪里
- 检测,就是对图片上的物体进行定位和分类
- 分割,精确到像素点进行分类,与我们所说的抠图类似。
一句话来讲,CV的任务就是分析图中有哪些物体,这些物体的位置是什么。基于这个基础,我们可以做很多事情,比如批量ps,或者人流量估计等等。
传统目标检测方法
- 确定滑动窗口
- 利用互动窗口提取出候选区域
- 对候选区域进行特征提取
- 使用分类器(实现已经训练好)进行分类,判断候选区域是否包含有效目标
- 对有所包含有效目标的候选区域进行合并
- 作图,绘制出检测目标轮廓框
我做个了动态图来解释这个方法(做的不好多包涵)
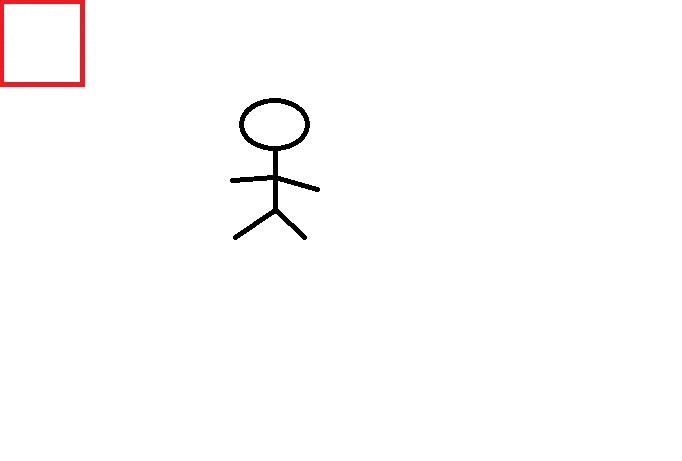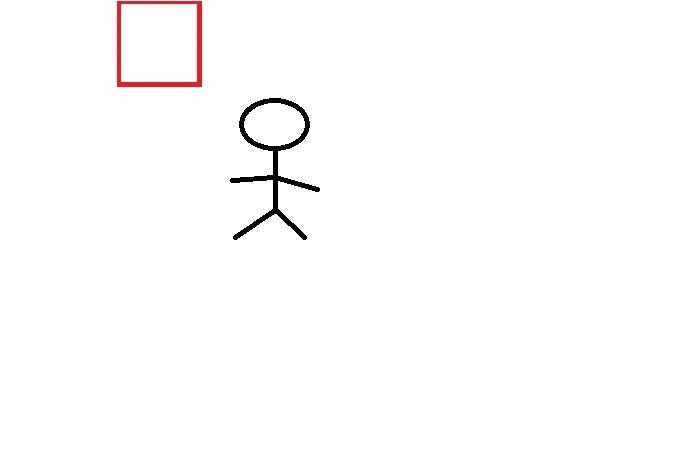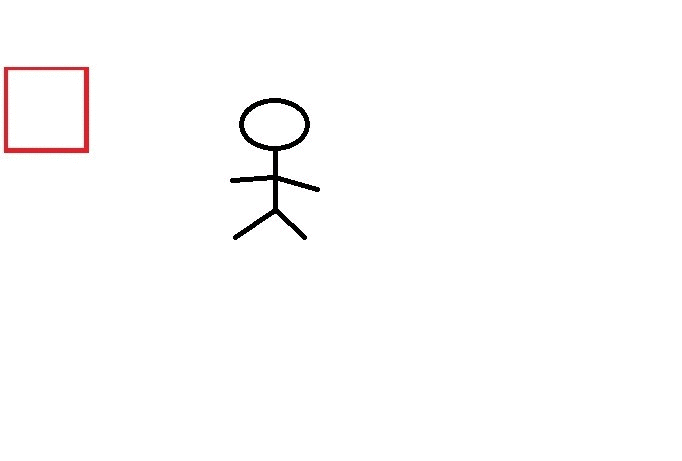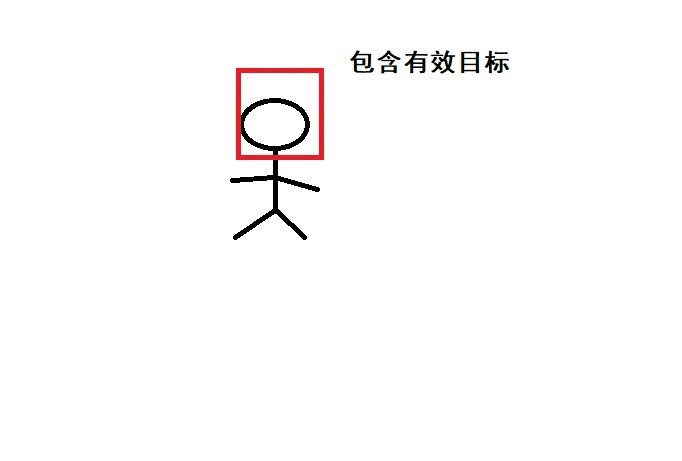
就是这样窗口的不断平移,下移,对红色窗口里的图像进行特征提取,判断是否包含有效区域。
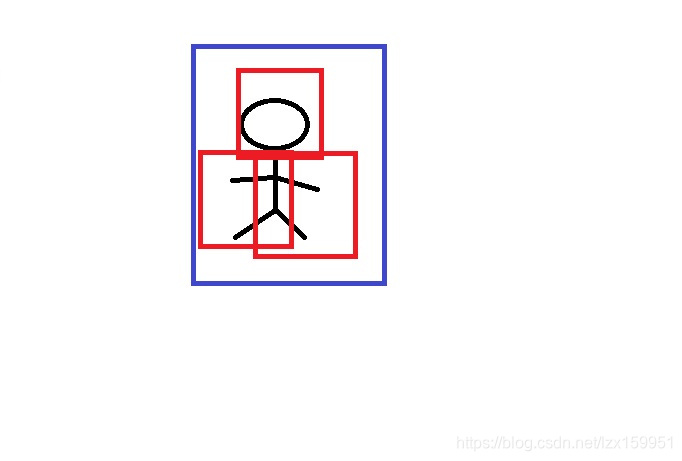
最终,经过红色窗口的不断移动,整张图遍历完毕,共有三处包含有效区域,最后将这三个有效区域进行合并,即为目标轮廓框。这种办法需要提前人工去裁定窗口大小,并且穷举遍历很消耗时间。
发展历程
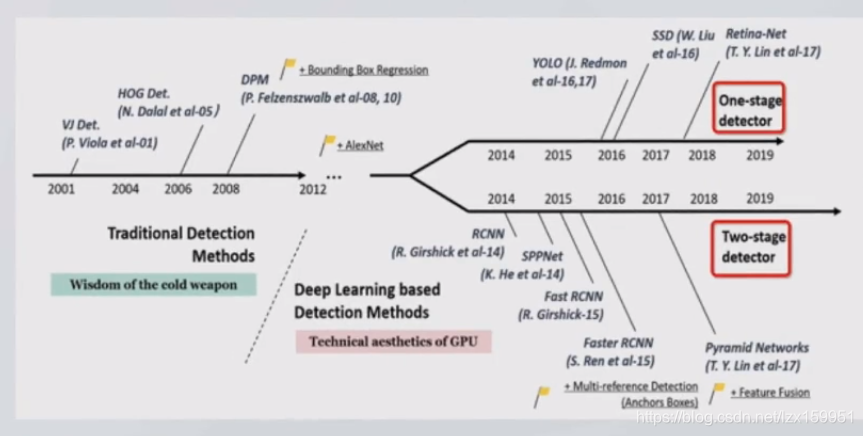
在2012年前,使用的都还是传统的目标检测算法,直到Alexnet算法的出现,目标检测分为两大阵营,分别是单阶段和多阶段。
单阶段:
直接提取特征来预测物体类别
所经历的步骤:特征提取->分类/回归
常见算法:YOLOv1、v2、v3、SSD、RetinaNet等
双阶段:
先进行目标区域(Region Proposal)的生成,再通过卷积神经网络进行分类
步骤:特征提取->生成PR->分类/回归
常见代表:R-CNN、Spp-Net、Fast R-CNN、Faster-RCNN等
算法分类
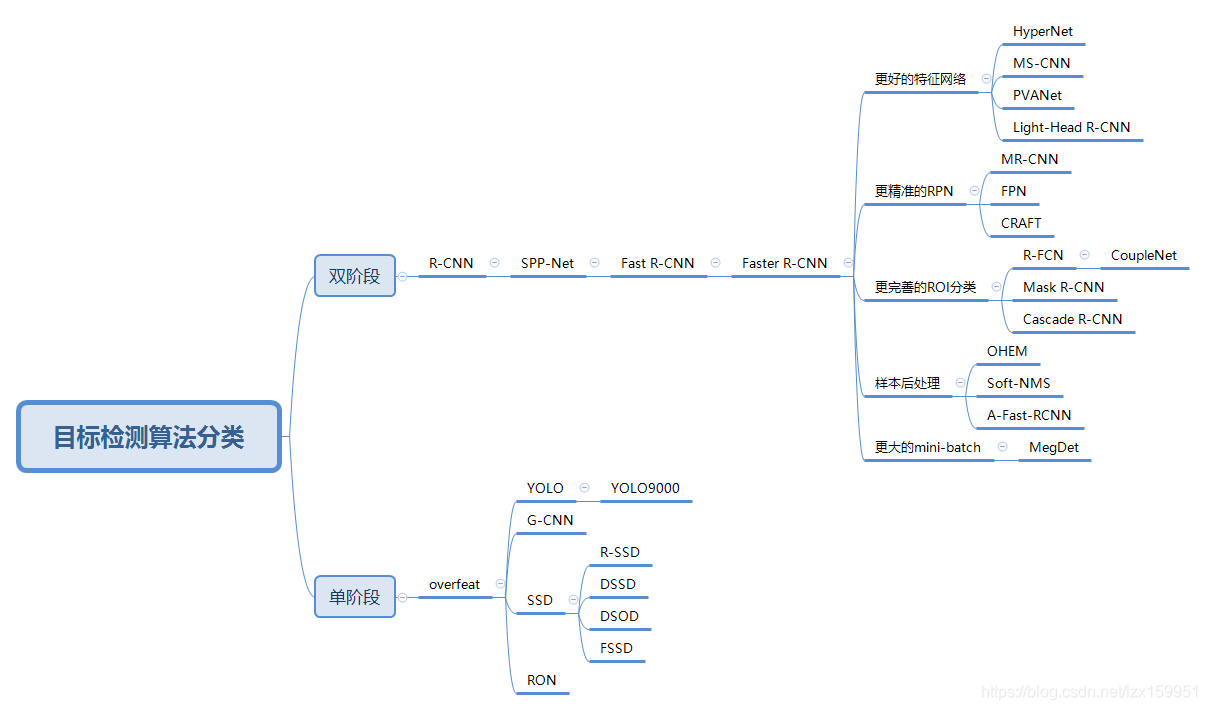
此图是通过xmind软件绘制的,如果有需要原文件的,请下方留言。
常用关键术语
- bbox(Bounding box):给出物体在图片中的定位区域,形状为长方形,给出左上角和右下角坐标。
- loU(intersection of Union):区域交叉程度,两个bbox的重叠程度,公式为 (A交B)/(A并B),用于评价预测结果和正是结果的差别,范围是0-1.
- mAP(mean average precision):当预测的包围盒和真是包围盒的交并比大于某一阈值时,则认为该预测正确。对于每个类别,我么能画出它的查准率-查全率曲线,平均准确率时曲线下方的面积,,之后再对所有类别的平均准确度求平均。
- Regional Proposal :候选区域,指去突出所有可能包含识别目标的哪些候选区域,想读与传统的滑动窗口而言,数量上回更少,质量更高。
- NMS(Non-maximum Suppression即非极大值抑制),时图像处理中用于消除多余的框,找到最佳物体检测位置的一个算法。
- Anchor Box(候选框):从原始或卷积后的图片中提取出来,然后用来判断是否存在要识别的目标的小的图片块。
- Selective Search(选择性搜索):利用颜色、纹理、尺寸、空间交叉来生成候选区域的算法,相较于传统的滑动窗口算法,Selective Search避免了穷举所产生的海量候选区域及其造成的低效。
