文章目录
WebMagic
WebMagic的设计参考了业界最优秀的爬虫Scrapy,而实现则应用了HttpClient、Jsoup等Java世界最成熟的工具,目标就是做一个Java语言Web爬虫的教科书般的实现。
特性:
- 简单的API,可快速上手
- 模块化的结构,可轻松扩展
- 提供多线程和分布式支持
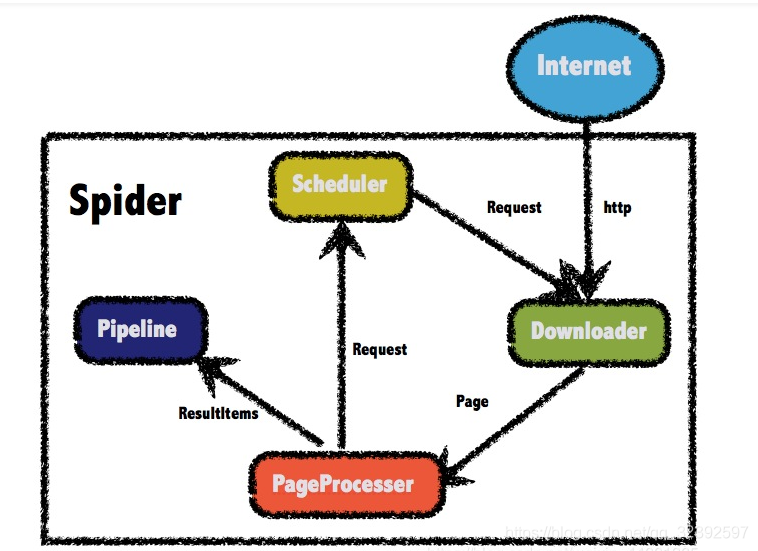
1. 结构组成
1.1 四个组件
WebMagic框架包含四个组件,PageProcessor、Scheduler、Downloader和Pipeline。
这四大组件对应爬虫生命周期中的处理、管理、下载和持久化等功能。
这四个组件都是Spider中的属性,爬虫框架通过Spider启动和管理。
- PageProcessor
负责解析页面,抽取有用信息,以及发现新的链接。WebMagic使用Jsoup作为HTML解析工具,并基于其开发了解析XPath的工具Xsoup,需要自己定义。 - Scheduler
负责管理待抓取的URL,以及一些去重的工作。一般无需自己定制Scheduler。 - Pipeline
负责抽取结果的处理,包括计算、持久化到文件、数据库等。WebMagic默认提供了“输出到控制台”和“保存到文件”两种结果处理方案。
Pipeline定义了结果保存的方式,如果你要保存到指定数据库,则需要编写对应的Pipeline。 - Downloader
负责从互联网上下载页面,以便后续处理。一般无需自己实现,默认使用了Apache HttpClient作为下载工具。
WebMagic总体架构图
1.2 数据流转对象
-
Request
Request是对URL地址的一层封装,一个Request对应一个URL地址。
它是PageProcessor与Downloader交互的载体,也是PageProcessor控制Downloader唯一方式。
除了URL本身外,它还包含一个Key-Value结构的字段extra。你可以在extra中保存一些特殊的属性,然后在其他地方读取,以完成不同的功能。例如附加上一个页面的一些信息等。 -
Page
Page代表了从Downloader下载到的一个页面——可能是HTML,也可能是JSON或者其他文本格式的内容。
Page是WebMagic抽取过程的核心对象,它提供一些方法可供抽取、结果保存等。 -
ResultItems
ResultItems相当于一个Map,它保存PageProcessor处理的结果,供Pipeline使用。它的API与Map很类似,值得注意的是它有一个字段skip,若设置为true,则不应被Pipeline处理。
1.3 项目目录
- com
- dao
- WebsiteDao.java
- entity
- Website.java
- service
- WebsiteService.java
- spider
- WebsitePipeline.java
- WebsiteProcess.java
- WebsiteApplication.java
2. 代码详解
爬取51job上关于大数据职位的数据,并保存到MySQL数据库中
2.1 启动类
@SpringBootApplication
@EnableScheduling //开启定时任务
public class WebsiteApplication {
public static void main(String[] args) {
SpringApplication.run(WebsiteApplication.class, args);
}
}
2.2 实体类(存储到数据库表的字段)
这里的声明字段均与数据库表中的字段一一对应的,我是手动写的,今天得知可以用mybatis的generate jar包自动引入生成字段,后续打算继续修改修改。
@Entity
public class Website {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long websiteId;
private String companyName;
private String companyAddr;
private String jobInfo;
private String jobName;
private String jobAddr;
private String companyInfo;
private String salary;}
2.3 爬虫类
@Component
public class WebsiteProcess implements PageProcessor {
@Override
public void process(Page page) {
// 解析页面,获取招聘信息详情的url地址
List<Selectable> nodes = page.getHtml().css("div.detlist.gbox div.e").nodes();
// 判断获取到的集合是否为空
if (nodes.size() == 0) {
// 如果为空,表示这是招聘详情页,解析页面,获取招聘详情信息,保存数据
this.saveWebsite(page);}else {
//如果不为空,表示这是列表页,解析出详情页的url地址,放到任务队列中
for(Selectable node:nodes){
// 获取到url地址
String jobInfoUrl = node.links().toString();
// System.out.println(jobInfoUrl);
//把获取到的详情页的url地址放到任务队列中
page.addTargetRequest(jobInfoUrl);
}
//获取下一 页按钮的url
//div的class是p_in 下面的li的class是bk
String bkUrl=page.getHtml().css("div.p_in li.bk").nodes().get(1).links().toString();//get(1)拿到第二个
// System.out.println(bkUrl);
//把下一页的url放到任务队列中
page.addTargetRequest(bkUrl);
}
}
// 解析页面,获取招聘详情信息,保存数据
private void saveWebsite(Page page) {
// 解析页面
Html html = page.getHtml();
List<Website> list = new ArrayList<>();
// System.out.println(str);
//创建招聘详情对象
Website website=new Website();
//获取数据,封装到对象中
//两种获取的方法,一种是直接html.css,另一种是使用Jsoup.parse解析html字符串
// 公司地址
String addr = page.getHtml().regex("<p class=\"fp\">.*?</span>([^<]+)</p>").toString();
page.putField("addr", addr);
// 工作地址
String addrjobStr = Jsoup.parse(html.css("div.in div.cn p.msg.ltype","title").toString()).text();
String JobAddr=addrjobStr.substring(0,addrjobStr.indexOf("|"));
page.putField("JobAddr", JobAddr);
//公司名称
String CompanyName= Jsoup.parse(html.css("div.cn p.cname a","title").toString()).text();
page.putField("CompanyName", CompanyName);
// 工作信息
List<Selectable> nodes = html.css("div.bmsg.job_msg.inbox p").nodes();
String jobInfo = null;
//由于工作信息有很多段,所以需要一段段提取
for(Selectable node:nodes){
String jobInfo1 = Jsoup.parse(node.toString()).text() ;
jobInfo = jobInfo1 +jobInfo;}
page.putField("jobInfo", jobInfo);
// 公司信息
String companyInfo = html.css("div.tmsg","text").toString();
page.putField("companyInfo", companyInfo);
// 工作名字
String JobName = Jsoup.parse(html.css("div.cn h1","title").toString()).text();
page.putField("JobName", JobName);
// 个人薪水
String Salary = Jsoup.parse(html.css("div.cn strong").toString()).text();
page.putField("Salary", Salary);
website.setCompanyName(CompanyName);
website.setCompanyAddr(addr);
website.setJobAddr(JobAddr);
website.setjobInfo(jobInfo);
website.setcompanyInfo(companyInfo);
website.setJobName(JobName);
website.setSalary(Salary);
//把结果保存起来
list.add(website);
page.putField("list", list);
}
private Site site = Site.me().setCharset("gbk")//设置编码
.setTimeOut(10*1000)//设置超时时间
.setRetrySleepTime(10*1000)//设置重试的间隔时间
.setRetryTimes(3);//设置重试的次数
@Override
public Site getSite() {
return this.site;
}
//这里注入websitePipeline
@Autowired
private WebsitePipeline websitePipeline;
//initialDelay当任务启动后,等多久执行方法
//fixedDelay每个多久执行方法
@Scheduled(initialDelay = 200 ,fixedDelay = 1000*100000)
public void process(){
/*
* Spider是WebMagic内部流程的核心。D
* ownloader、PageProcessor、Scheduler、Pipeline都是Spider的一个属性,
* 这些属性是可以自由设置的,通过设置这个属性可以实现不同的功能。 Spider也是WebMagic操作的入口,它封装了爬虫的创建、启动、停止、多线程等功能。
*/
Spider.create(new WebsiteProcess())
.setScheduler(new QueueScheduler().setDuplicateRemover(new BloomFilterDuplicateRemover(100000)))
.thread(10)
.addPipeline(websitePipeline)//指定把爬取的数据保存到websitePipeline类的ResultItems中
// .addPipeline(new WebsitePipeline("D:\\eclipse-workspace\\spider_website_info-master3\\data\\webmagic") {
// } )//把爬取的数据保存到指定文件中
.run();
}
}
2.4 获取爬到的数据并保存到数据库
@Component
public class WebsitePipeline implements Pipeline {
@Autowired
private WebsiteService websiteService;
@Override
public void process(ResultItems resultItems, Task task) {
// 与之前爬取的数据page.putField("list", list);对应
// 获取我们封装好的招聘详情对象
List<Website> list = resultItems.get("list");
// 判断我们的数据是否不为空
if (list != null){
// 不为空就保存到数据库中
websiteService.saveAll(list);
}
}
这里需要保存结果到数据库,因为我用的springboot框架,所以在application.yml中配置与数据库的连接

spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver #因为是MySQL数据库,可以根据不同数据库做替换
url: jdbc:mysql://localhost:3306/databasename?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&useSSL=false&useAffectedRows=true
username: root
password: yourpassword
jpa:
database: mysql
show-sql: true
#spring.jpa.hibernate.naming.physical-strategy=org.hibernate.boot.model.naming.PhysicalNamingStrategyStandardImpl
hibernate:
naming:
implicit-strategy: org.hibernate.boot.model.naming.ImplicitNamingStrategyLegacyJpaImpl
physical-strategy: org.hibernate.boot.model.naming.PhysicalNamingStrategyStandardImpl
这里没有贴上所有的代码,具体可以在我的github上去下载:https://github.com/wangjie182/spring-website-info
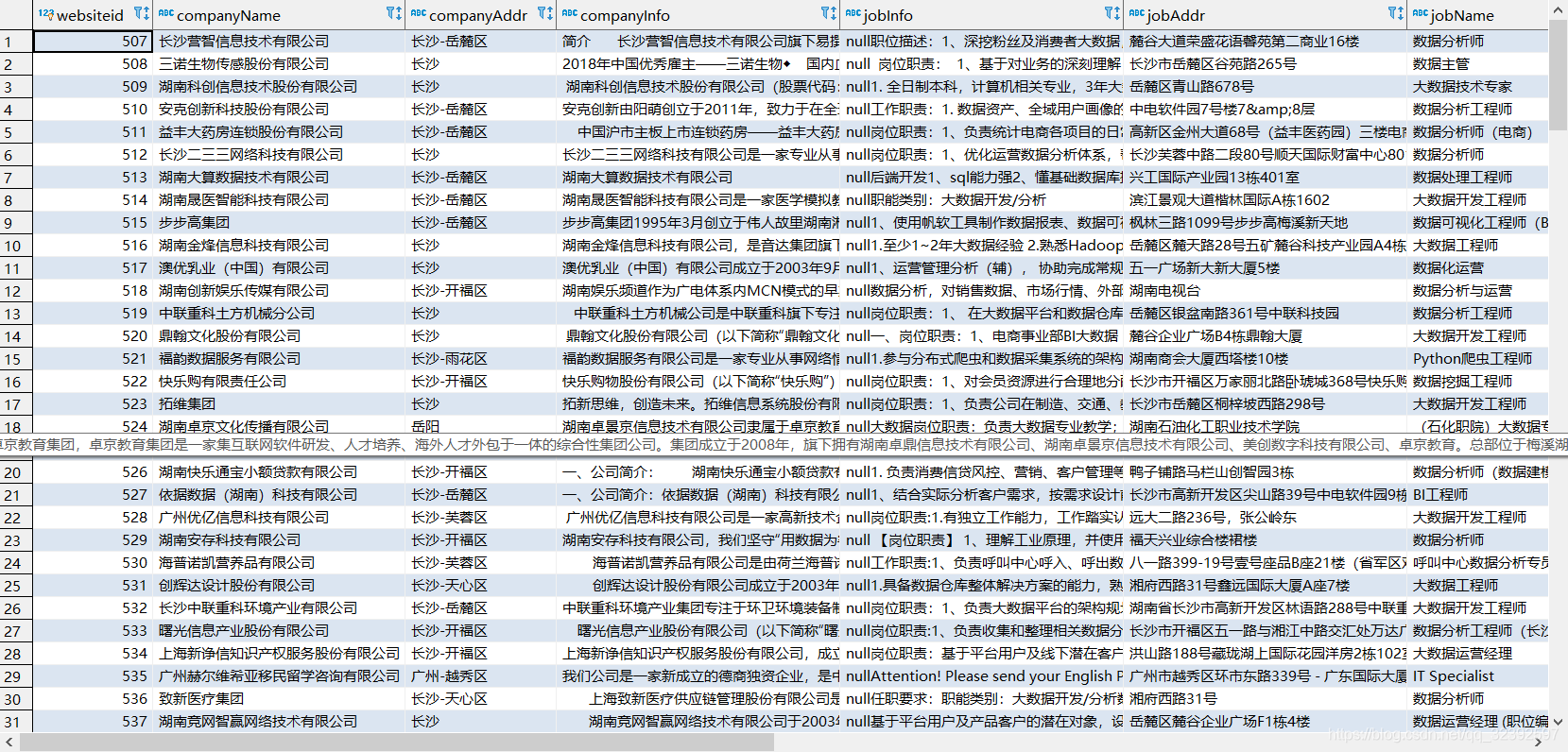
3. 运行结果
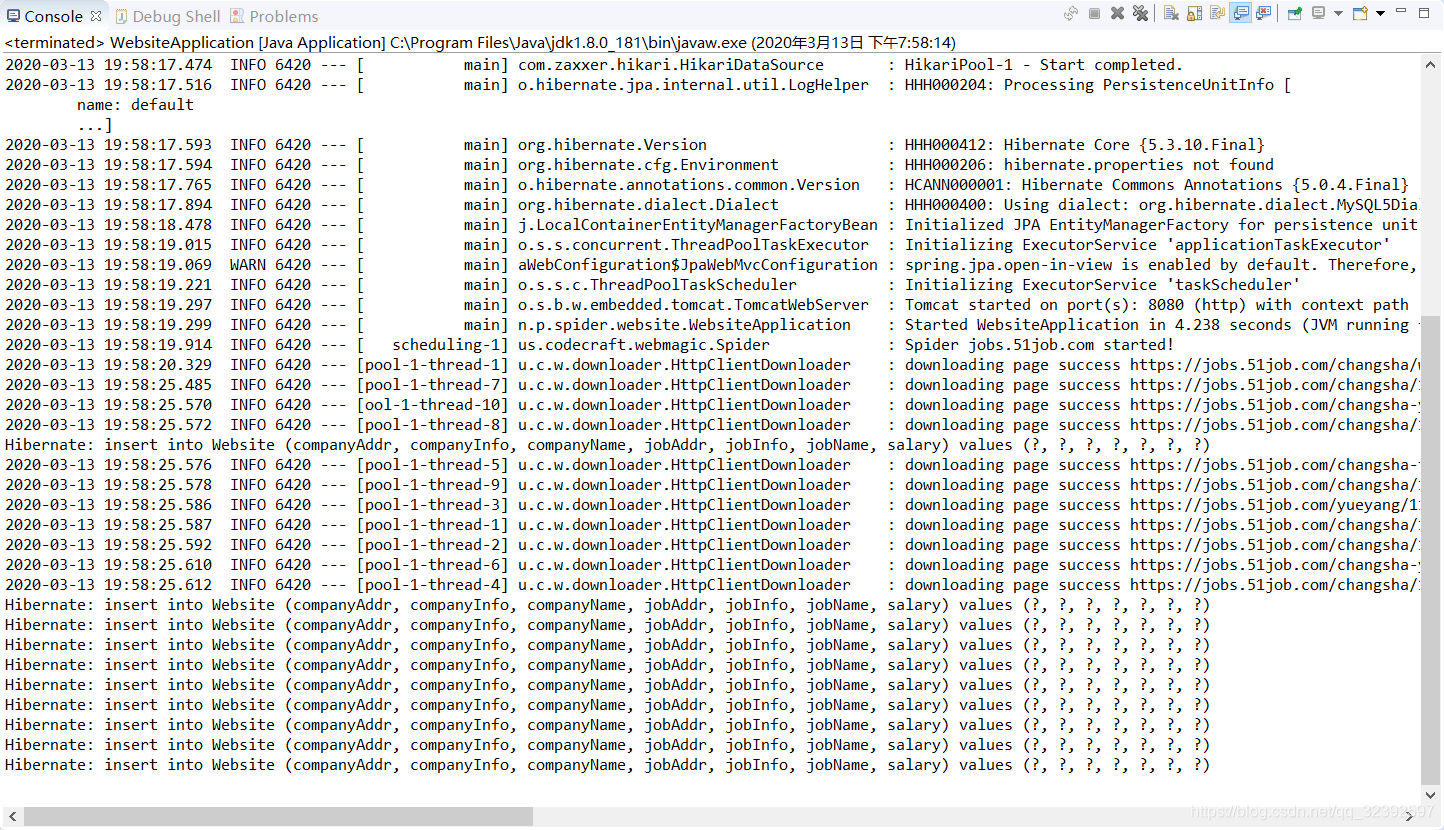
这里的运行结果输出有点问题,不知道是编码哪里错误导致的,不过数据库倒是没问题。