原博客 https://blog.csdn.net/qq_21396469/article/details/78419609
写在前面
本文主要分为三个部分。
第一部分介绍了二叉搜索树的基本性质。
第二部分全面详细地讲述了二叉搜索树的各种基本操作。包括WALK/遍历、SEARCH/查找、MINIMUM/最小关键字、MAXIMUM/最大关键字、SUCCESSOR/后继、PREDECESSOR/前驱、INSERT/插入、DELETE/删除等。主要参考《算法导论》(中文第3版)中有关二叉搜索树的相关介绍说明。
对于每一种基本操作,都至少分三个重点进行讲解。它们分别是基本操作过程及原理(包含伪代码及C++实现)、时间复杂度分析以及举例分析(配图)。力求让每位读者可以直观地理解。
第三部分则是完整的代码实现及实例分析。
本文断断续续写了几天,各部分的举例分析也十分明了,为了讲得更清楚一些,所有的配图都是自行制作的。请尊重劳动成果,供人供己查阅,如有错误之处,欢迎指正。
原创文章,转载请注明出处。http://blog.csdn.net/qq_21396469/article/details/78419609
一、二叉搜索树简介与基本性质
1、定义
二叉搜索树(BST)又称二叉查找树或二叉排序树。一棵二叉搜索树是以二叉树来组织的,可以使用一个链表数据结构来表示,其中每一个结点就是一个对象。一般地,除了key和卫星数据(文末附注1)之外,每个结点还包含属性lchild、rchild和parent,分别指向结点的左孩子、右孩子和双亲(父结点)。如果某个孩子结点或父结点不存在,则相应属性的值为空(NIL)。根结点是树中唯一父指针为NIL的结点,而叶子结点的孩子结点指针也为NIL。
2、基本性质
根据《算法导论》(中文第3版)的相关介绍,二叉搜索树中的关键字总是以满足二叉搜索树性质的方式来存储:
设x是二叉搜索树中的一个结点。如果y是x左子树中的一个结点,那么y.key≤x.key。如果y是x右子树中的一个结点,那么y.key≥x.key。
在二叉搜索树中:
① 若任意结点的左子树不空,则左子树上所有结点的值均不大于它的根结点的值;
② 若任意结点的右子树不空,则右子树上所有结点的值均不小于它的根结点的值;
③ 任意结点的左、右子树也分别为二叉搜索树。
一棵典型的二叉搜索树如下:
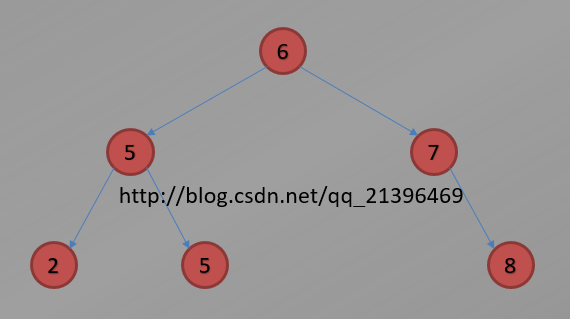
二、二叉搜索树的基本操作与代码实现
1、二叉搜索树的结点
正如前面所说,每个二叉搜索树的结点,包含关键字key、左孩子指针lchild、右孩子指针rchild以及父结点指针parent。在C++实现中,我们定义一个结点类BSTNode来表示一个结点,并初始化结点的关键字等于0,左右孩子指针和父结点指针为NIL。
/* 二叉搜索树节点 */
class BSTNode
{
private:
double key; // 关键字
BSTNode *lchild; // 左孩子
BSTNode *rchild; // 右孩子
BSTNode *parent; // 父节点
friend class BSTree;
public:
BSTNode(double k = 0.0, BSTNode *l = NULL, BSTNode *r = NULL, BSTNode *p = NULL) :key(k), lchild(l), rchild(r), parent(p){}
};
2、二叉搜索树的基本操作
对于一棵二叉搜索树来说,它支持许多动态集合操作,包括WALK(遍历)、SEARCH(查找)、MINIMUM(最小关键字)、MAXIMUM(最大关键字)、SUCCESSOR(后继)、PREDECESSOR(前驱)、INSERT(插入)、DELETE(删除)等。下面将依次讲解这些操作的具体过程及实现。
2.1 WALK(遍历)
2.1.1 中序遍历/INORDER-TREE-WALK
二叉搜索树的性质允许我们通过一个简单的递归算法来按序输出二叉搜索树中的所有关键字,这种算法称为中序遍历(inorder tree walk)算法。对于中序遍历来说,输出的子树根的关键字位于其左子树的关键字值和右子树的关键字值之间。其伪代码如下:

根据上述伪代码,我们可以很容易地写出中序遍历二叉搜索树的实现。
// 中序遍历
void inOrder_Tree_Walk(BSTNode *x)
{
if (x != NULL)
{
inOrder_Tree_Walk(x->lchild);
cout << x->key << " ";
inOrder_Tree_Walk(x->rchild);
}
}
得益于二叉搜索树的性质,当使用中序遍历来访问一棵二叉搜索树上的所有结点时,最后得到的访问序列恰好是所有结点关键字的升序序列。
2.1.2 先序遍历/PREORDER-TREE-WALK
跟中序遍历类似,先序遍历(preorder tree walk)算法也是通过递归来实现的。区别在于先序遍历输出的子树根的关键字在其左右子树的关键字值之前。我们同样可以写出先序遍历的伪代码:

同样,根据上述伪代码,我们可以很容易地写出先序遍历二叉搜索树的实现。