中文官方文档:http://lightgbm.apachecn.org/cn/latest/Installation-Guide.html
英文官方文档:https://lightgbm.readthedocs.io/en/latest/
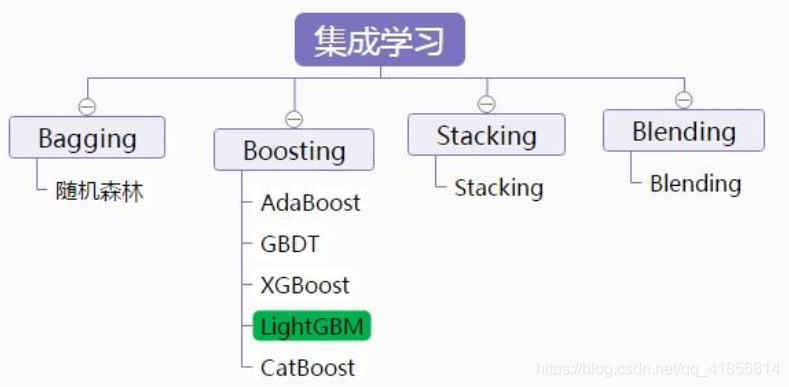
一、lightGBM安装
在anaconda中输入:pip install lightGBM即可
输入import lightgbm as lgb做测试
二、lightGBM改进
XGB有什么优缺点
优点:
- 1、XGB利用了二阶梯度来对节点进行划分,相对其他GBM、GBDT来说,精度更加高。
- 2、利用局部近似算法对分裂节点的贪心算法优化,取适当的eps时,可以保持算法的性能且提高算法的运算速度。
- 3、在损失函数中加入了L1/L2项,控制模型的复杂度,提高模型的鲁棒性。
- 4、提供并行计算能力,主要是在树节点求不同的候选的分裂点的Gain Infomation(分裂后,损失函数的差值)
- 5、Tree Shrinkage,column subsampling等不同的处理细节。
缺点:
- 1、需要pre-sorted,这个会耗掉很多的内存空间(2 * #data * # features)
- 2、数据分割点上,由于XGB对不同的数据特征使用pre-sorted算法而不同特征其排序顺序是不同的,所以分裂时需要对每个特征单独做依次分割,遍历次数为#data * #features来将数据分裂到左右子节点上。
- 3、尽管使用了局部近似计算,但是处理粒度还是太细了
- 4、由于pre-sorted处理数据,在寻找特征分裂点时(level-wise),会产生大量的cache随机访问。
因此LightGBM针对这些缺点进行了相应的改进
- LightGBM基于histogram算法代替pre-sorted所构建的数据结构,利用histogram后,会有很多有用的tricks。例如histogram做差,提高了cache命中率(主要是因为使用了leaf-wise)
- 在机器学习当中,我们面对大数据量时候都会使用采样的方式(根据样本权值)来提高训练速度。又或者在训练的时候赋予样本权值来关于于某一类样本(如Adaboost)。LightGBM利用了GOSS来做采样算法
- 由于histogram算法对稀疏数据的处理时间复杂度没有pre-sorted好。因为histogram并不管特征值是否为0。因此我们采用了EFB来预处理稀疏数据
- 1.直方图差加速:直方图算法的基本思想是先把连续的浮点特征值离散化成k个整数,同时构造一个宽度为k的直方图。在遍历数据的时候,根据离散化后的值作为索引在直方图中累积统计量,当遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点。内存消耗降低,计算上的代价也大幅降低
- 2.leaf-wise:每次从当前所有叶子中,找到分裂增益最大的一个叶子,然后分裂,如此循环。因此同Level-wise相比,在分裂次数相同的情况下,Leaf-wise可以降低更多的误差,得到更好的精度。可能会长出比较深的决策树,产生过拟合。因此LightGBM在Leaf-wise之上增加了一个最大深度限制,在保证高效率的同时防止过拟合。
- 3.特征并行和数据并行:特征并行的主要思想是在不同机器在不同的特征集合上分别寻找最优的分割点,然后在机器间同步最优的分割点。数据并行则是让不同的机器先在本地构造直方图,然后进行全局的合并,最后在合并的直方图上面寻找最优分割点。
- 4.直接支持类别特征:可以直接输入类别特征,不需要额外的0/1 展开,LightGBM 是第一个直接支持类别特征的 GBDT 工具。
三、常用参数解释
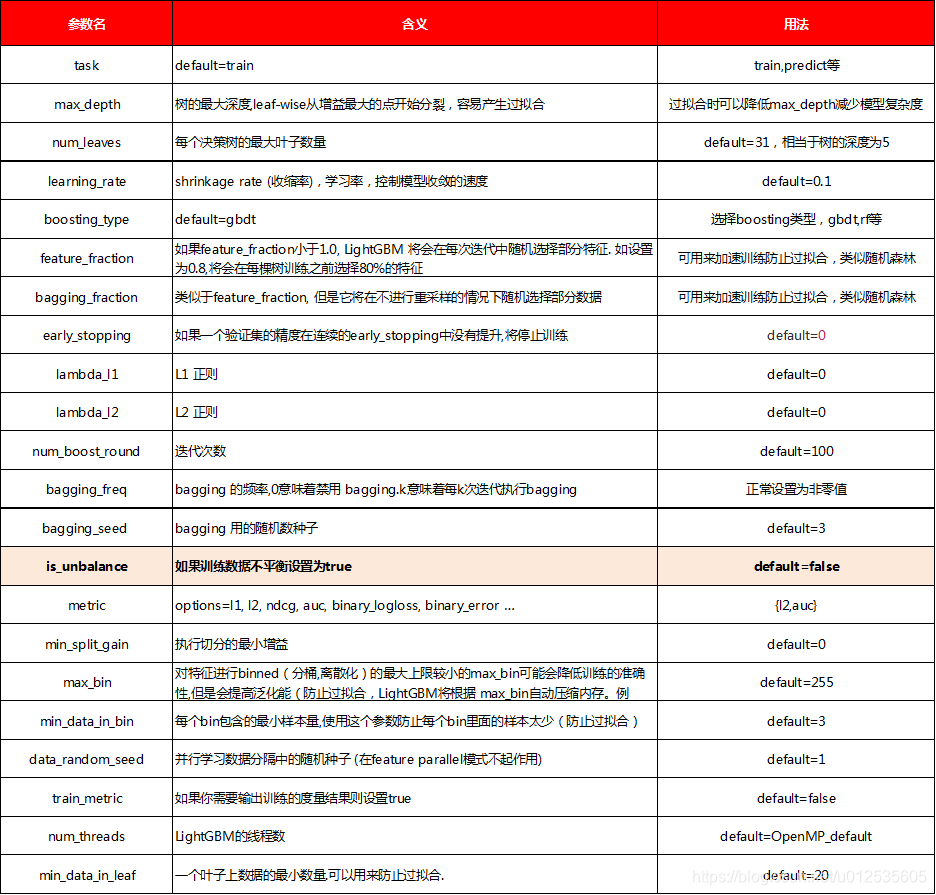
4.lightGBM使用
根据天池蒸汽赛代码进行使用和对比xgboost
天池大赛地址:https://tianchi.aliyun.com/competition/entrance/231693/information
import numpy as np
import pandas as pd
from lightgbm import LGBMRegressor
from xgboost import XGBClassifier,XGBRegressor
train = pd.read_csv('../xgboost算法/zhengqi_train.txt',sep = '\t')
test = pd.read_csv('../xgboost算法/zhengqi_test.txt',sep = '\t')
X_train.head()
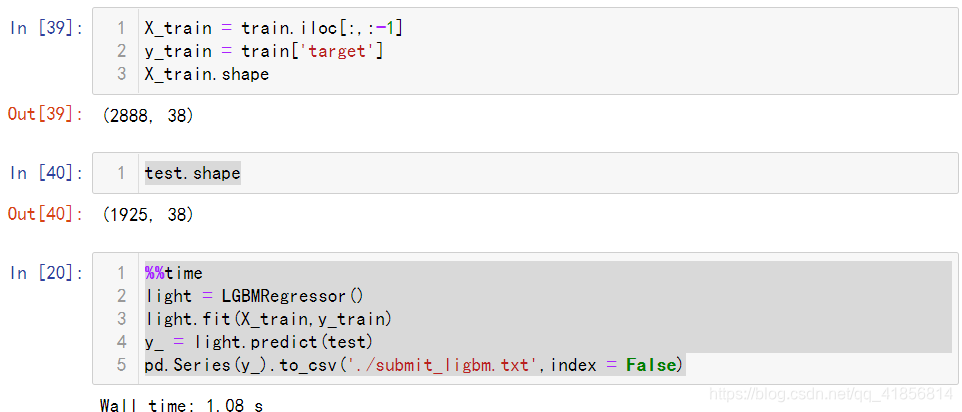
X_train = train.iloc[:,:-1]
y_train = train['target']
X_train.shape
test.shape
%%time
light = LGBMRegressor()
light.fit(X_train,y_train)
y_ = light.predict(test)
pd.Series(y_).to_csv('./submit_ligbm.txt',index = False)
%%time
xbg = XGBRegressor(n_estimators=3,max_depth=100)
xbg.fit(X_train,y_train)
y_ = xbg.predict(test)
pd.Series(y_).to_csv('./submit_xgb2.txt',index = False)
train.var().array
# 协方差 ,两个属性之间的关系,
# 协方差绝对值越大,连个属性之间的关系越密切
cov = train.cov()
cov
#删除波动数据后用 lightbgm算法
light = LGBMRegressor()
light.fit(X_train,y_train)
y_ = light.predict(test)
pd.Series(y_).to_csv('./submit_ligbm3.txt',index = False)
#删除波动数据后用 xgb算法对比
from xgboost import XGBRegressor
xgb = XGBRegressor()
xgb.fit(X_train,y_train)
y_ = xgb.predict(test)
pd.Series(y_).to_csv('./submit_xgb2.txt',index = False)
最终上传成绩提升了几个点无截图!
