操作系统之Linux实验进程管理
笔记内容:
1.进程查看
2.进程创建与管理
3.对一些基本问题的解释(后续完善)1.进程查看
查看进程优先级:ps –l
wwq@wwq-VirtualBox:~$ ps -l
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
0 S 1000 1581 1579 0 80 0 - 2234 wait pts/2 00:00:00 bash
0 T 1000 1648 1581 0 80 0 - 1467 signal pts/2 00:00:02 yes
0 R 1000 1650 1581 55 80 0 - 1467 - pts/2 00:06:22 yes
0 R 1000 1654 1581 0 80 0 - 1592 - pts/2 00:00:00 ps
相关名词的解释
F: 标志位 (flags), 具体有哪些值及其含义可以参考 man ps 里面关于 flags 的相关内容
S: 状态 (state), 下面那几个进程的状态为S表示是在 sleeping 状态(即等待状态)
UID:代表执行者的身份
PID: 当前进程号
PPID: 当前进程的父进程号
C: CPU 占用百分率
PRI: 进程调度优先级
NI: Nice 值
ADDR: 交换(swap) 地址
SZ: 虚拟内存大小 (virtual size)
WCHAN: 当前进程正在等待的事件(比如等待semphore,等待 IO 等)
STIME: 进程启动时间 (什么时候开始运行的)
TIME: 进程占用cpu时间
TTY: 进程对应控制终端 (可以没有)
CMD: 进程对应的命令行参数
其中State(状态):
D=不可中断的睡眠状态
R=运行
S=睡眠
T=跟踪/停止
Z=僵尸进程
2.进程创建与管理
Linux进程控制函数
#include <unistd.h>
#include <stdio.h>
int main ()
{
pid_t fpid; //fpid表示fork函数返回的值
int count=0;
fpid=fork();
if (fpid < 0)
printf("error in fork!");
else if (fpid == 0) {
printf("i am the child process, my process id is %d\n",getpid());
printf("我是爹的儿子\n");//对某些人来说中文看着更直白。
count++;
}
else {
printf("i am the parent process, my process id is %d\n",getpid());
printf("我是孩子他爹\n");
count++;
}
printf("统计结果是: %d/n",count);
return 0;
}
点击打开链接参考博客
命令行:gcc 1.c
Ls
./a.out
运行结果是:
i am the child process, my process id is 5574
我是爹的儿子
统计结果是: 1
i am the parent process, my process id is 5573
我是孩子他爹
统计结果是: 1
在语句fpid=fork()之前,只有一个进程在执行这段代码,但在这条语句之后,就变成两个进程在执行了,这两个进程的几乎完全相同,将要执行的下一条语句都是if(fpid<0)……
为什么两个进程的fpid不同呢,这与fork函数的特性有关。fork调用的一个奇妙之处就是它仅仅被调用一次,却能够返回两次,它可能有三种不同的返回值:
1)在父进程中,fork返回新创建子进程的进程ID;
2)在子进程中,fork返回0;
3)如果出现错误,fork返回一个负值;
在fork函数执行完毕后,如果创建新进程成功,则出现两个进程,一个是子进程,一个是父进程。在子进程中,fork函数返回0,在父进程中,fork返回新创建子进程的进程ID。我们可以通过fork返回的值来判断当前进程是子进程还是父进程。
引用一位网友的话来解释fpid的值为什么在父子进程中不同。“其实就相当于链表,进程形成了链表,父进程的fpid(p 意味point)指向子进程的进程id, 因为子进程没有子进程,所以其fpid为0.
fork出错可能有两种原因:
1)当前的进程数已经达到了系统规定的上限,这时errno的值被设置为EAGAIN。
2)系统内存不足,这时errno的值被设置为ENOMEM。
创建新进程成功后,系统中出现两个基本完全相同的进程,这两个进程执行没有固定的先后顺序,哪个进程先执行要看系统的进程调度策略。
每个进程都有一个独特(互不相同)的进程标识符(process ID),可以通过getpid()函数获得,还有一个记录父进程pid的变量,可以通过getppid()函数获得变量的值。
fork执行完毕后,出现两个进程,
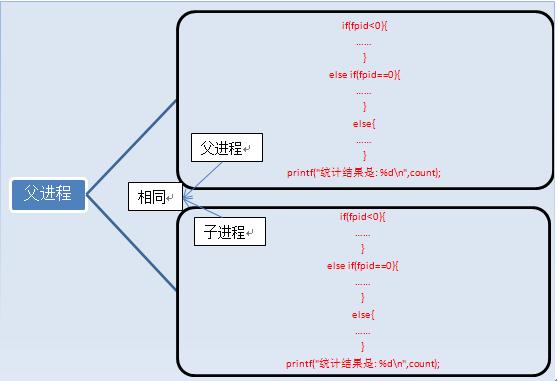
有人说两个进程的内容完全一样啊,怎么打印的结果不一样啊,那是因为判断条件的原因,上面列举的只是进程的代码和指令,还有变量啊。
执行完fork后,进程1的变量为count=0,fpid!=0(父进程)。进程2的变量为count=0,fpid=0(子进程),这两个进程的变量都是独立的,存在不同的地址中,不是共用的,这点要注意。可以说,我们就是通过fpid来识别和操作父子进程的。
还有人可能疑惑为什么不是从#include处开始复制代码的,这是因为fork是把进程当前的情况拷贝一份,执行fork时,进程已经执行完了int count=0;fork只拷贝下一个要执行的代码到新的进程。