ビッグデータ開発は大規模なデータの処理と分析を含む技術分野であり、ビッグデータ技術の継続的な開発と応用に伴い、ビッグデータ開発者の需要は徐々に増加しています。特にテクノロジー業界やデータ主導型企業では、雇用の見通しは比較的良好です。ビッグデータ開発の見通しには、雇用範囲の広さ、高給与と福利厚生、充実した会社と個人の福利厚生など、依然として多くの利点があります。現在、ビッグデータ開発サークルに参加したいと考えている友人がたくさんいますが、彼らは参加しません。学び方を知っている 学び方を知らない この問題に応えて、今日はビッグデータ学習ロードマップを共有します。

ロードマップは 7 つのステージに分かれています。
フェーズ 1 - データ ウェアハウス ベース
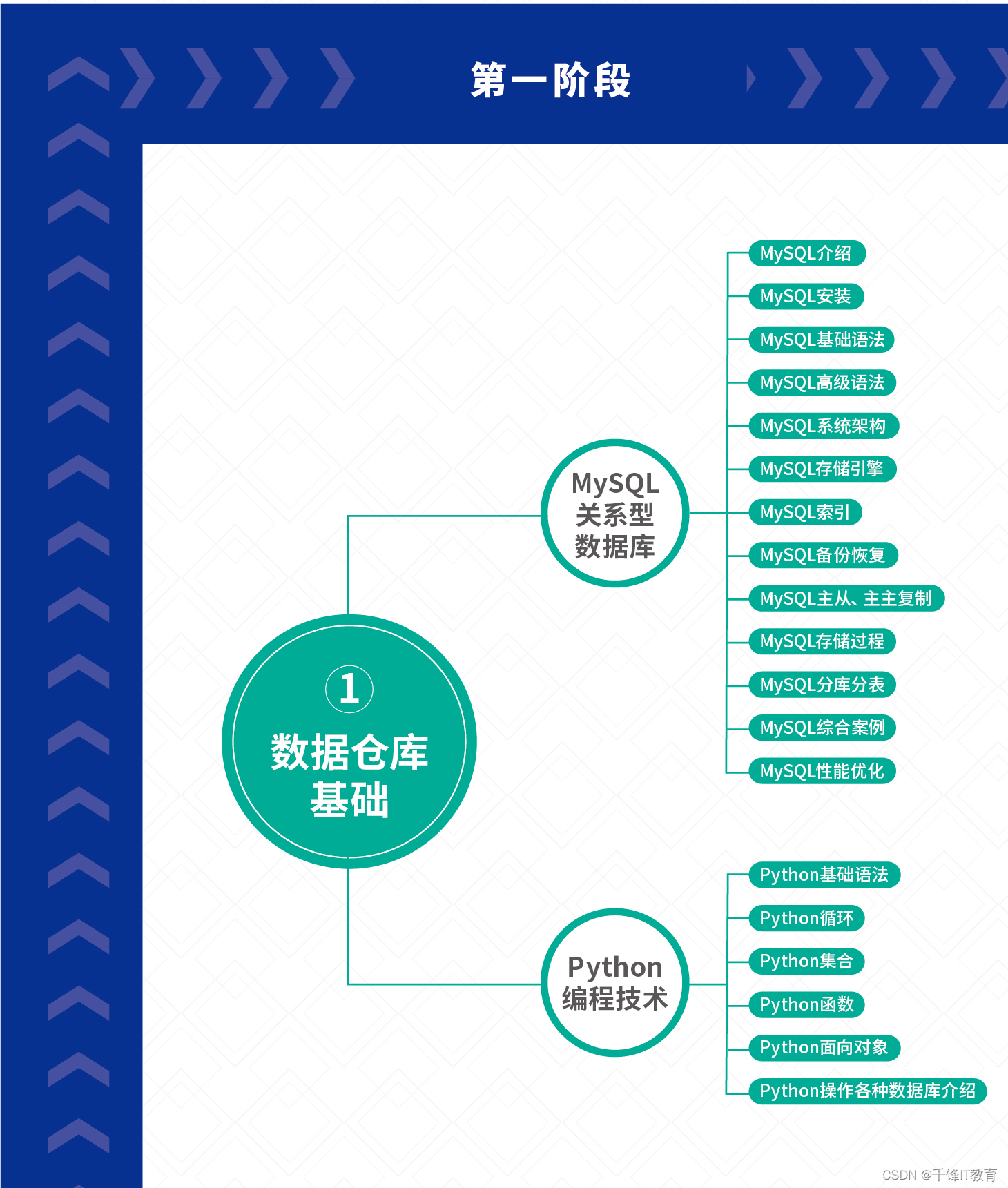
1.MysQLリレーショナルデータベース
(MySQL の概要、MySQL のインストール、MySQL の基本構文、MySQL の高度な構文、MySQL システム アーキテクチャ、MySQL ストレージ エンジン、MySQL インデックス、MySQL のバックアップとリカバリ、MySQL マスター/スレーブ、マスター/マスター レプリケーション、MySQL ストアド プロシージャ、MySQL データベースとテーブル、 MySQL の包括的なケース、MySQL パフォーマンスの最適化)
2.Pythonプログラミング技術
(Python の基本構文、Python ループ、Python コレクション、Python 関数、Python オブジェクト指向、およびさまざまなデータベースでの Python 操作の紹介)

フェーズ 2 - Linux と Hadoop
1.ハドゥープ
(ビッグ データの概要、Hadoop 3 点セット、HDFS システム アーキテクチャ、HDFS ブロック、HDFS FSImage と編集
HDFS チェックポイント、HDFS 読み取りおよび書き込みプロセス、HDFS シェル操作、YARN システム アーキテクチャ、YARN リソース スケジューリング戦略、YARN スケジューリング構成、YARN -ベースのジョブ送信)
2.Linuxオペレーティングシステム
(コマンド操作、権限管理、ソフトウェアインストール、システムカーネル解析)
3.シェルスクリプトプログラミング
(シェルの概要、基本的なシェル構文、高度なシェル構文、シェル プログラミングの事例)
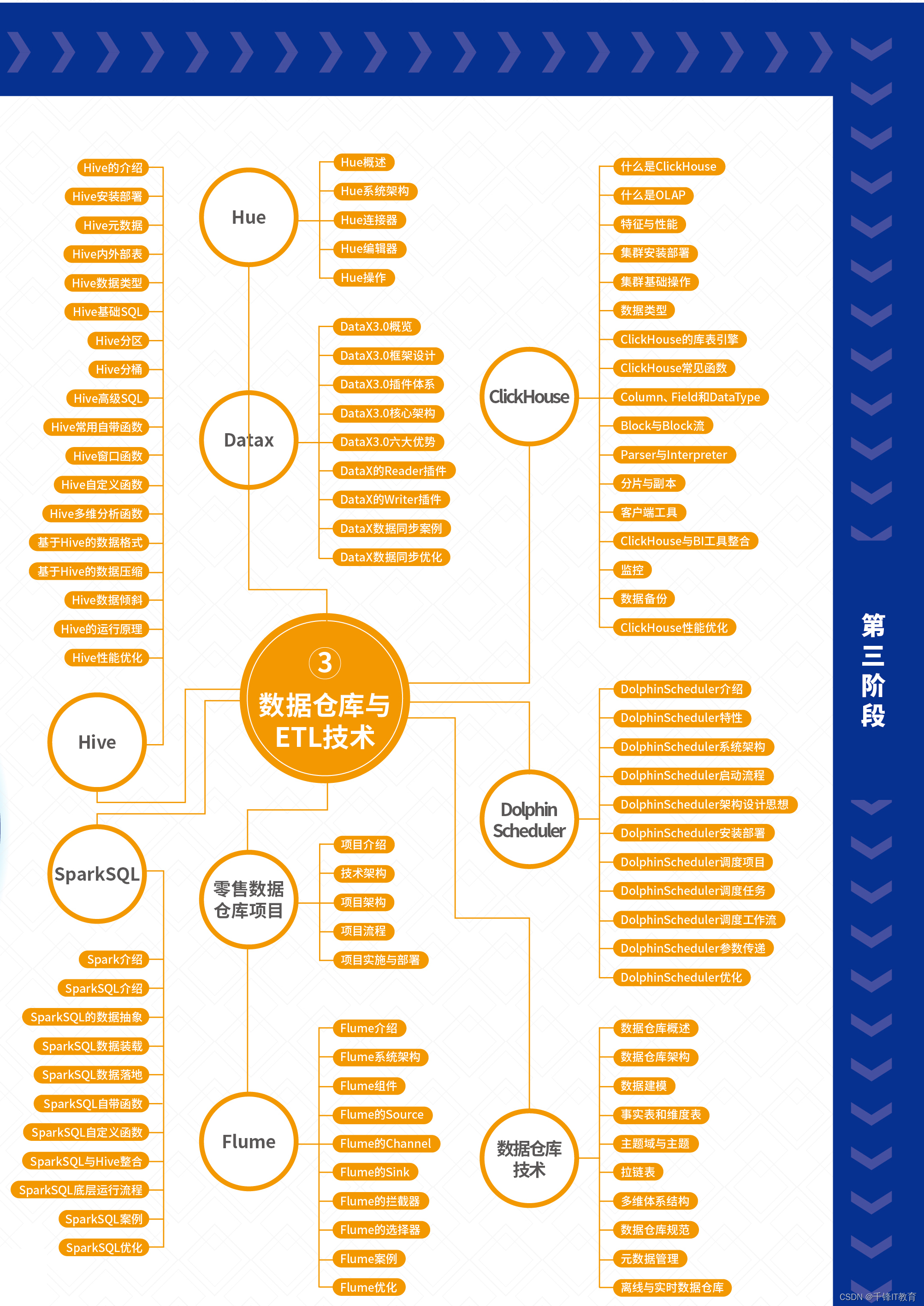
フェーズ 3 - データ ウェアハウスと ETL テクノロジー
1.ハイブ
(Hive の概要、Hive のインストールとデプロイメント、Hive メタデータ、Hive 内部テーブルと外部テーブル、Hive データ型、Hive 基本 SQL、Hive パーティショニング、Hive バケット化、Hive 高度な SQL、一般的に使用される Hive 組み込み関数、Hive ウィンドウ関数、Hiveカスタマイズ機能)
2.データックス
(DataX30 の概要、DataX3.0 フレームワーク設計、DataX3.0 プラグイン システム、DataX3.0 コア アーキテクチャ、DataX3.0 の 6 つの主要な利点、DataX Reader プラグイン、DataX Writer プラグイン、DataX データ同期ケース、DataXデータ同期の最適化)
3.色合い
(Hueの概要、Hueのシステムアーキテクチャ、Hueコネクタ、Hueエディタ、Hueの操作)
4.クリックハウス
(機能とパフォーマンス、クラスターのインストールと展開、基本的なクラスター操作、データ型、ClickHouse データベース テーブル エンジン、ClickHouse の共通関数、列、フィールドとデータ型、ブロックとブロック ストリーム、パーサーとインタープリター、シャーディングとコピー、クライアント ツール)
5.ドルフィンスケジューラー
(DolphinScheduler の概要、DolphinScheduler の機能、DolphinScheduler システム アーキテクチャ、DolphinScheduler の起動プロセス、DolphinScheduler アーキテクチャの設計アイデア、DolphinScheduler のインストールと展開、DolphinScheduler のスケジュール設定プロジェクト、DolphinScheduler のスケジュール設定タスク)
6. データウェアハウステクノロジー
(データ ウェアハウスの概要、データ ウェアハウス アーキテクチャ、データ モデリング、ファクト テーブルとディメンション テーブル、サブジェクト領域とトピック、ジッパー テーブル、多次元アーキテクチャ、データ ウェアハウス仕様、メタデータ管理、オフラインおよびリアルタイム データ ウェアハウス)
7.小売データウェアハウスプロジェクト
(プロジェクトの紹介、技術アーキテクチャ、プロジェクト アーキテクチャ、プロジェクト プロセス、プロジェクトの実装と展開)
8.フルーム
(Flume の概要、Flume システム アーキテクチャ、Flume コンポーネント、Flume のソース、Flume のチャネル、Flume のシンク、Flume のインターセプター、Flume のセレクター、Flume のケース、Flume の最適化)
9.SparkSQL
(Spark の概要、SparkSQL の概要、SparkSQL データの抽象化、SparkSQL データの読み込み、SparkSQL データの実装、SparkSQL 組み込み関数、SparkSQL カスタム関数、SparkSQL と Hive の統合、SparkSQL の基礎となる実行プロセス)
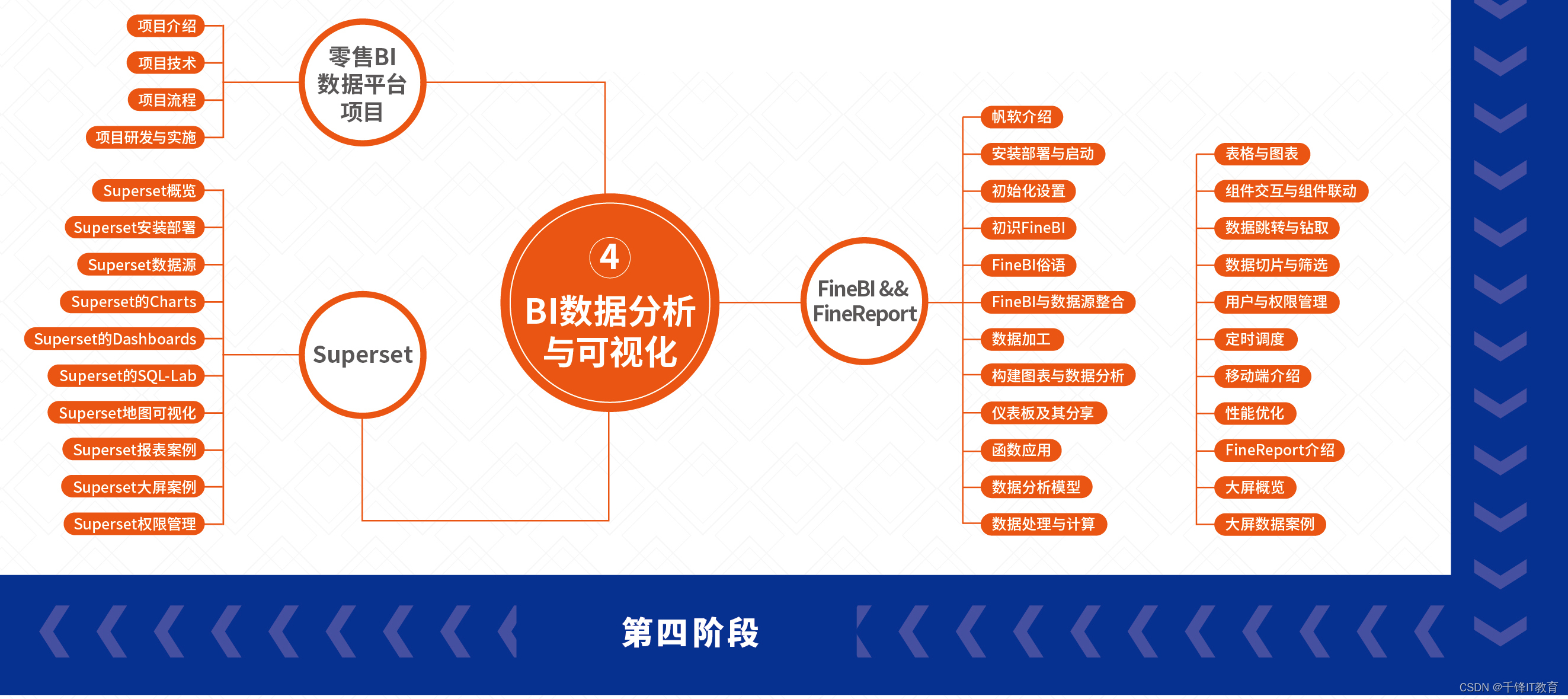
フェーズ 4 - BI データの分析と視覚化
1.小売BIデータプラットフォームプロジェクト
(プロジェクトの紹介、プロジェクトの技術、プロジェクトのプロセス、プロジェクトの研究開発と実施)
2.スーパーセット
(スーパーセットの概要、スーパーセットのインストールと展開、スーパーセット データ ソース、スーパーセット チャート、スーパーセット ダッシュボード、スーパーセット SOL-Lab、スーパーセット マップの視覚化、スーパーセット レポート ケース、スーパーセット大画面ケース、スーパーセット権限管理)
3.ファインBI&ファインレポート
(Fanruan の概要、インストール、展開と起動、初期設定、初めての FineBI の紹介、FineBI の名言、FineBI とデータ ソースの統合、データ処理、チャートとデータ分析の構築、ダッシュボードと共有、関数アプリケーション、データ分析モデル、データ処理 (コンポーネントと計算、テーブルとチャート、データのジャンプとドリル、データのスライスとフィルタリングとの相互作用とリンク)
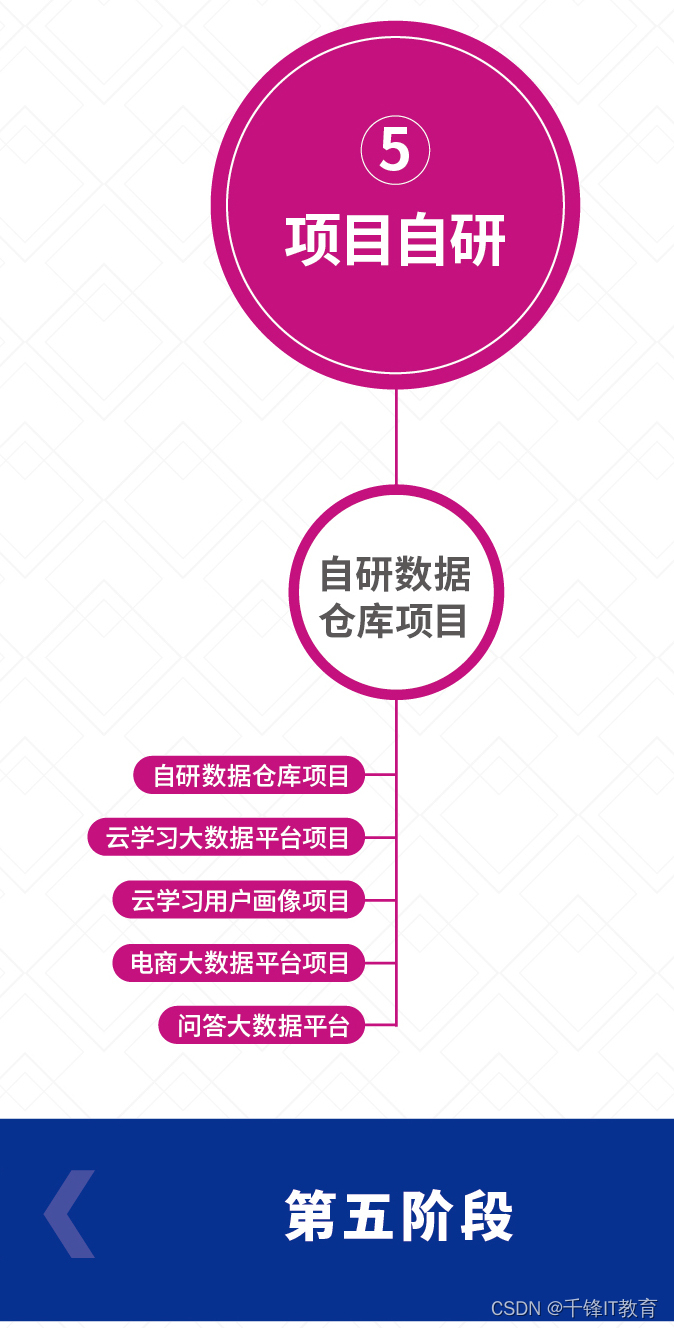
ステージ 5 - プロジェクトの自己研究
1. 自社開発データウェアハウスプロジェクト
(自社研究データウェアハウスプロジェクト、クラウド学習ビッグデータプラットフォームプロジェクト、クラウド学習ユーザーポートレートプロジェクト、Eコマースビッグデータプラットフォームプロジェクト、Q&Aビッグデータプラットフォーム)
処理と計算、テーブルとチャートのコンポーネントの相互作用とコンポーネントのリンク、データのジャンプとドリル、データのスライスとフィルタリング)
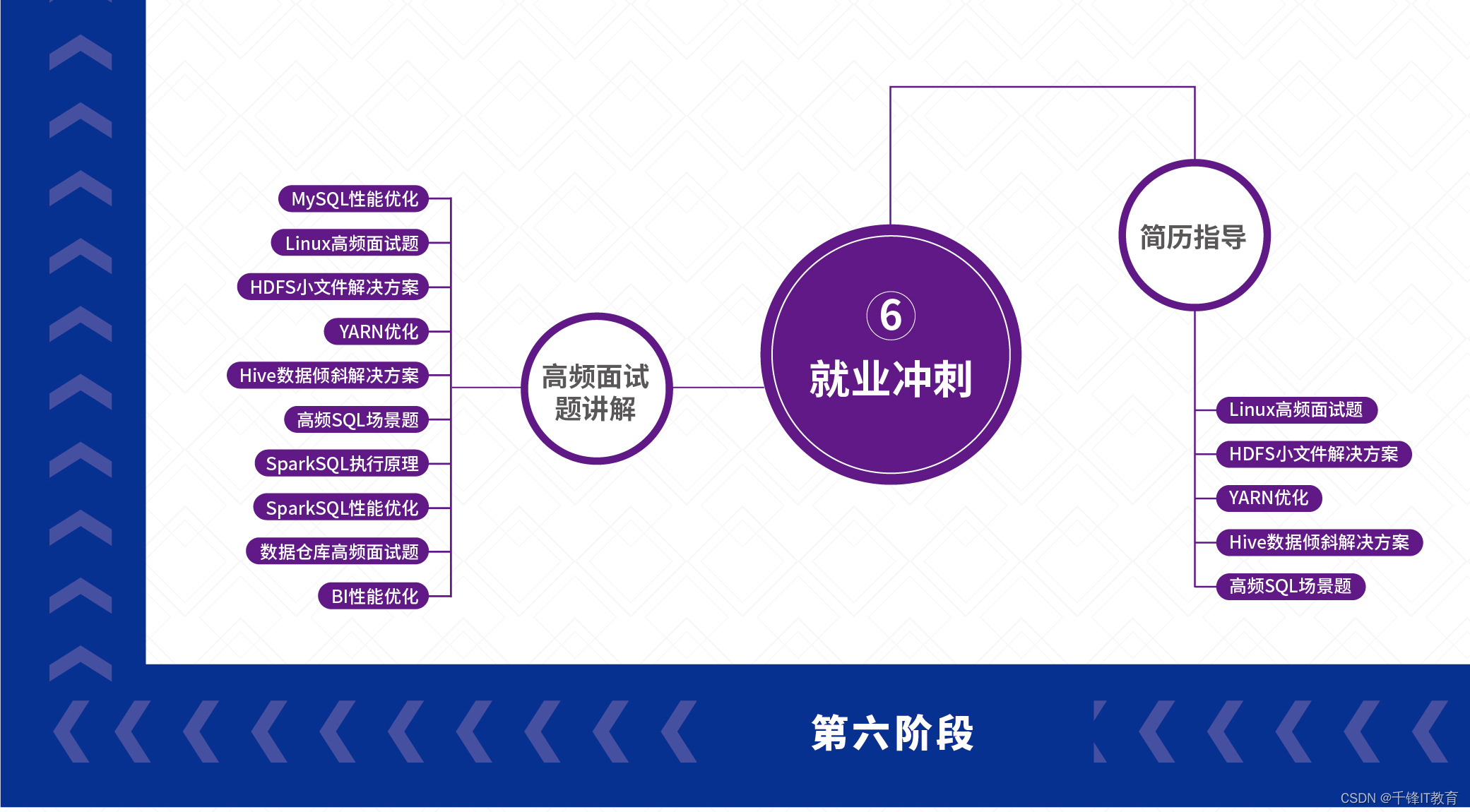
ステージ 6 - 雇用スプリント
1. 面接でよく聞かれる質問の解説
(MySQL パフォーマンスの最適化、Linux の高頻度インタビューの質問、HDFS 小さなファイル ソリューション、YARN の最適化、Hive データ スキュー ソリューション、高頻度の SQL シナリオの質問、SparkSQL 実行原理、SparkSQL パフォーマンスの最適化、データ ウェアハウスの高頻度インタビューの質問、BI パフォーマンス最適化)
2.指導再開
(Linux の高頻度のインタビューの質問、HDFS の小さなファイル ソリューション、YARN の最適化、Hive データ スキュー ソリューション、高頻度の SQL シナリオの質問)
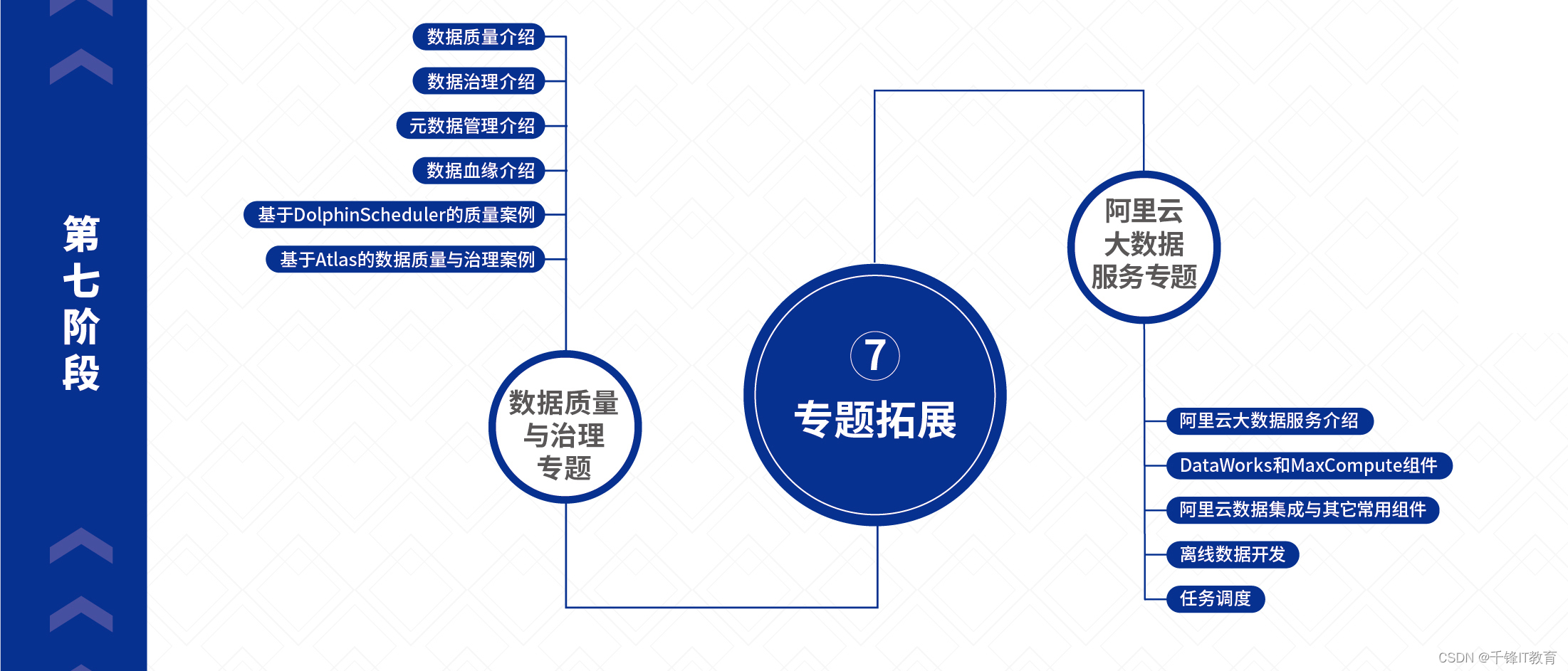
ステージ 7 - トピックの開発
1. データ品質とガバナンスのトピック
(データ品質入門、データガバナンス入門、メタデータ管理入門、データリネージ入門、DolphinSchedulerによる品質事例、Atlasによるデータ品質とガバナンスの事例)
2. Alibaba Cloud ビッグデータ サービスの特別トピック
(Alibaba Cloud ビッグ データ サービス、DataWorks および MaxCompute コンポーネント、Alibaba Cloud データ統合とその他の一般的なコンポーネント、オフライン データ開発、タスク スケジューリングの紹介)
上記はビッグデータの学習ルートです。ビッグデータを学習している、またはビッグデータを学習したい友人の助けになれば幸いです。