1.コンピューターが処理できる方法で単語を表現する方法(「単語セグメンテーション」とも呼ばれます)
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.preprocessing.test import Tokenizer
sentences=['I love my dog',
'I.love my cat']
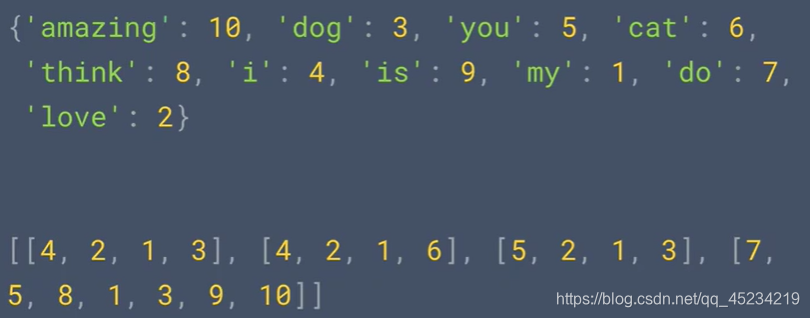
tokenizer=Tokenizer(num_words=100)
Tokenizerオブジェクトのインスタンスを作成し、ライブラリに最も頻繁に使用される100個の単語を保持します
tokenizer.fit_on_texts(sentences)
文中のすべてのテキストを表示し、テキストを対応する番号と一致させます
word_index= tokenizer.word_index
すべての単語のリストを取得し、すべての語彙と語彙を出力します(注:すべての大文字は小文字に変換されます。後で最初の埋め込みが行われるときに大文字に変換することを忘れないでください)
print(word_index)
出力:{'i':1、 'm':3、 'dog':4、 'cat':5、 'love':2}出力ワードとそれに対応する識別子
注:トークナイザーは非常にスマートです。犬の後に「!」が付いていても、私の犬が大好きです!のように、トークナイザーは犬を認識して自動的に「!」を削除します。
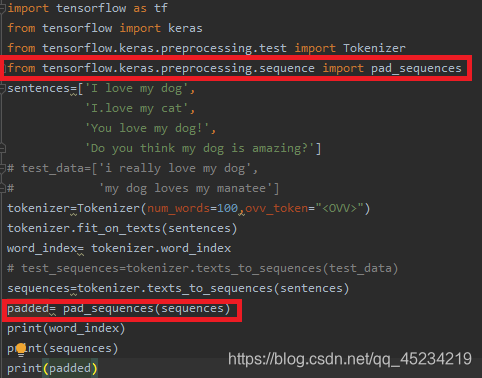
2.文の数列を作成し、上記の単語を含む文を数列に変換します
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.preprocessing.test import Tokenizer
sentences=['I love my dog',
'I.love my cat',
'Do you think my dog is amazing?']
tokenizer=Tokenizer(num_words=100)
tokenizer.fit_on_texts(sentences)
word_index= tokenizer.word_index
sequences=tokenizer.texts_to_sequences(sentences)
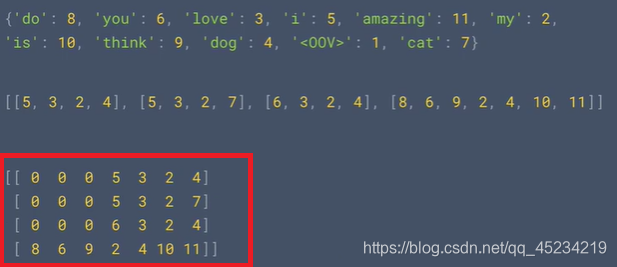
各文を表す一連の識別子を作成しました
print(word_index)
print(sequences)
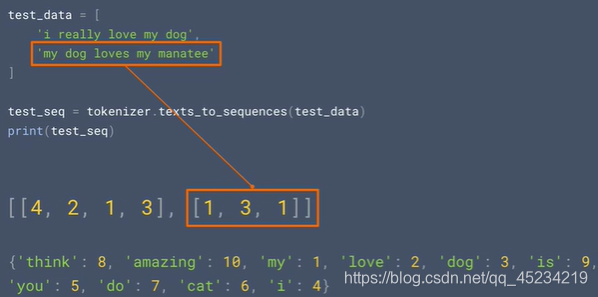
3.テストセットの文を並べ替えます
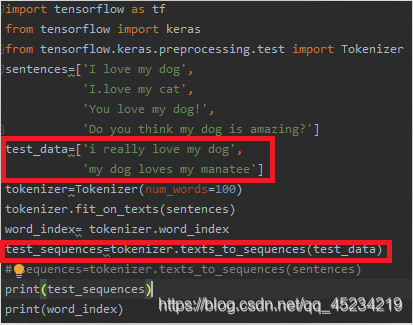
manateeとreallyand lovesは、word_indexに含まれず、このシーケンスを構成するコーパスに含まれない単語であるため、次のように出力されます。
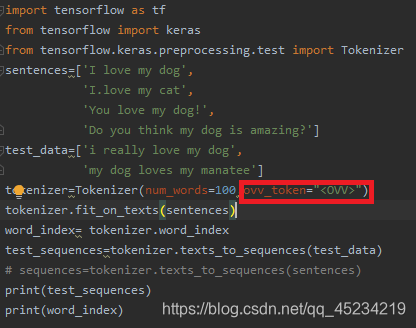
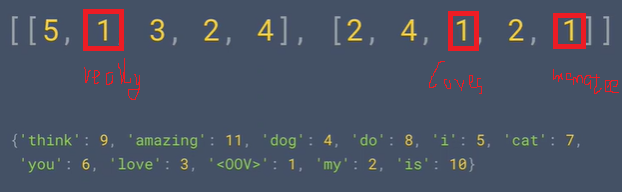
文の長さを失わないようにするには、ovv_token属性を使用して設定します。コーパス内の認識できないコンテンツを置き換えるまで
4.異なる長さの文を処理するには、パディングを使用して最初に塗りつぶし、短い文と最も長い文を同じ長さにします。