
Enlace del artículo: https://arxiv.53yu.com/pdf/2104.12753.pdf?ref=https://githubhelp.com
Enlace del código: https://github.com/ChengyueGongR/PatchVisionTransformer
1. motivo
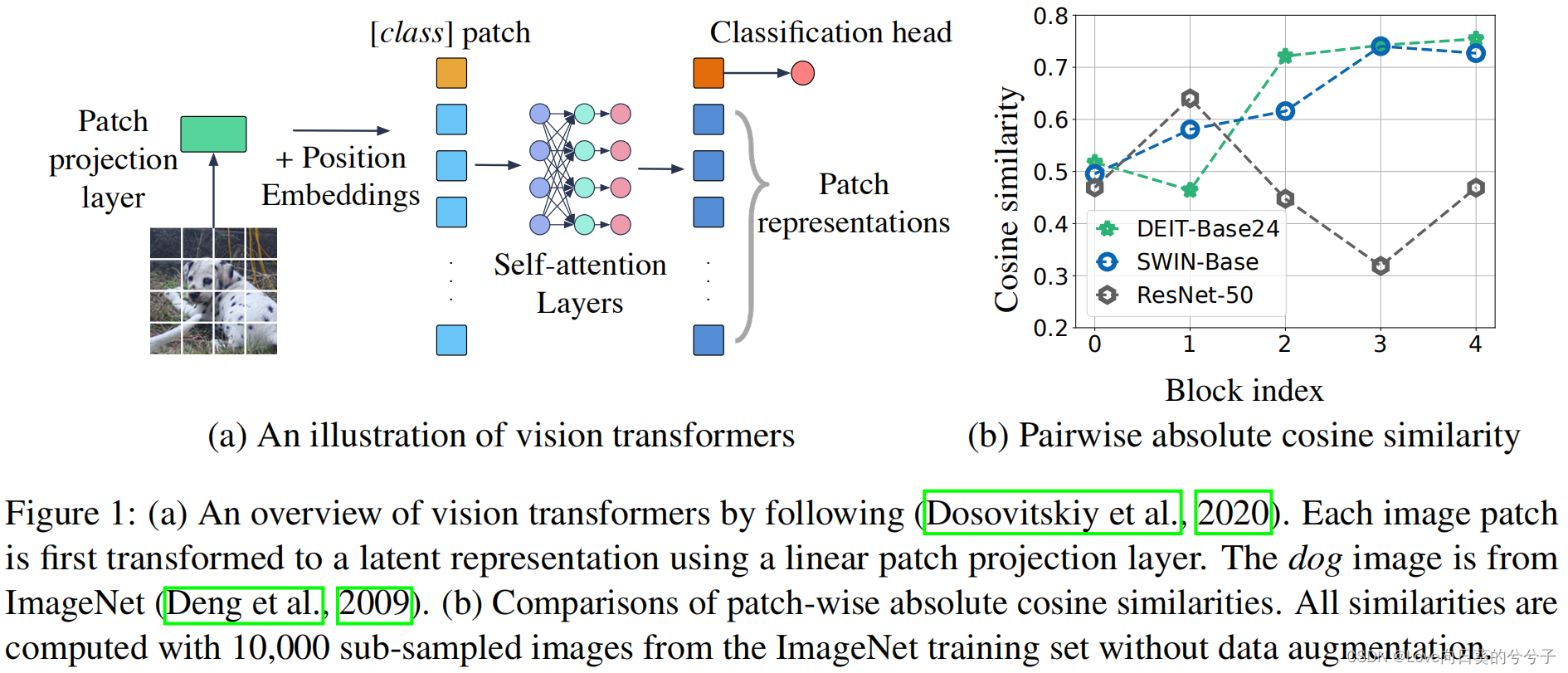
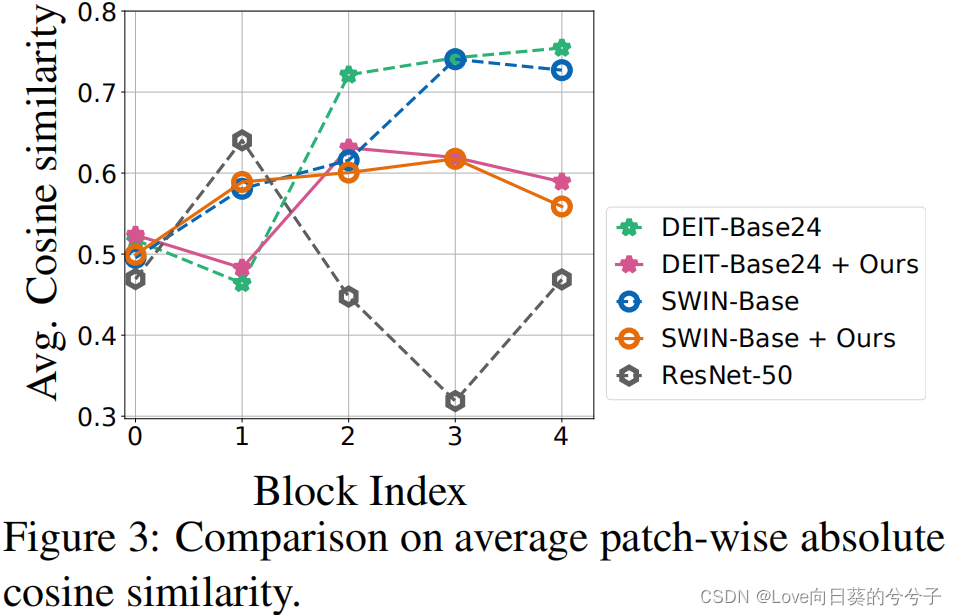
Vision Transformer ha demostrado un buen rendimiento en tareas desafiantes de visión por computadora. Sin embargo, se descubrió que el entrenamiento del Vision Transformer no es particularmente estable, especialmente a medida que el modelo se vuelve más ancho y profundo. Para estudiar las razones de la inestabilidad del entrenamiento, el autor extrae la representación de parche de cada capa de autoatención en dos variantes visuales populares de Transformer (DeiT, Swin-Transformer) y calcula la similitud absoluta promedio del coseno entre las representaciones de parche. Se encontró que en estas dos especies modelo, la similitud entre las representaciones de parches aumentó significativamente, como se muestra en la Figura 1(b) arriba. Este comportamiento reduce la expresividad general de la representación del parche y reduce la capacidad de aprendizaje de potentes transformadores visuales. Más específicamente, para los Transformers de visión profunda, el módulo de autoatención tiende a mapear diferentes parches en representaciones latentes similares, lo que resulta en pérdida de información y degradación del rendimiento . ( Es muy similar al problema que se resolverá en el artículo "REVISITAR EL SUAVIDAD EXCESO EN BERT DESDE LA PERSPECTIVA DEL GRÁFICO" , pero la forma de resolver el problema es diferente)
Nota: Si la secuencia de representación del parche de entrada es h = [ hclase, h 1, ⋯, hn] h =[h_{clase}, h_1, \cdots, h_n]h=[ hclase _ _ _ _,h1,⋯,hnorte] , entonces la fórmula de cálculo de similitud del coseno absoluto es la siguiente (aquí se ignora el parche de clase),
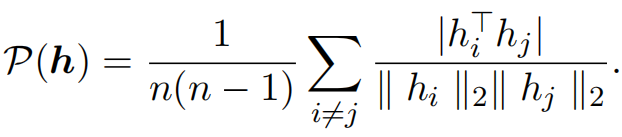
2. Método
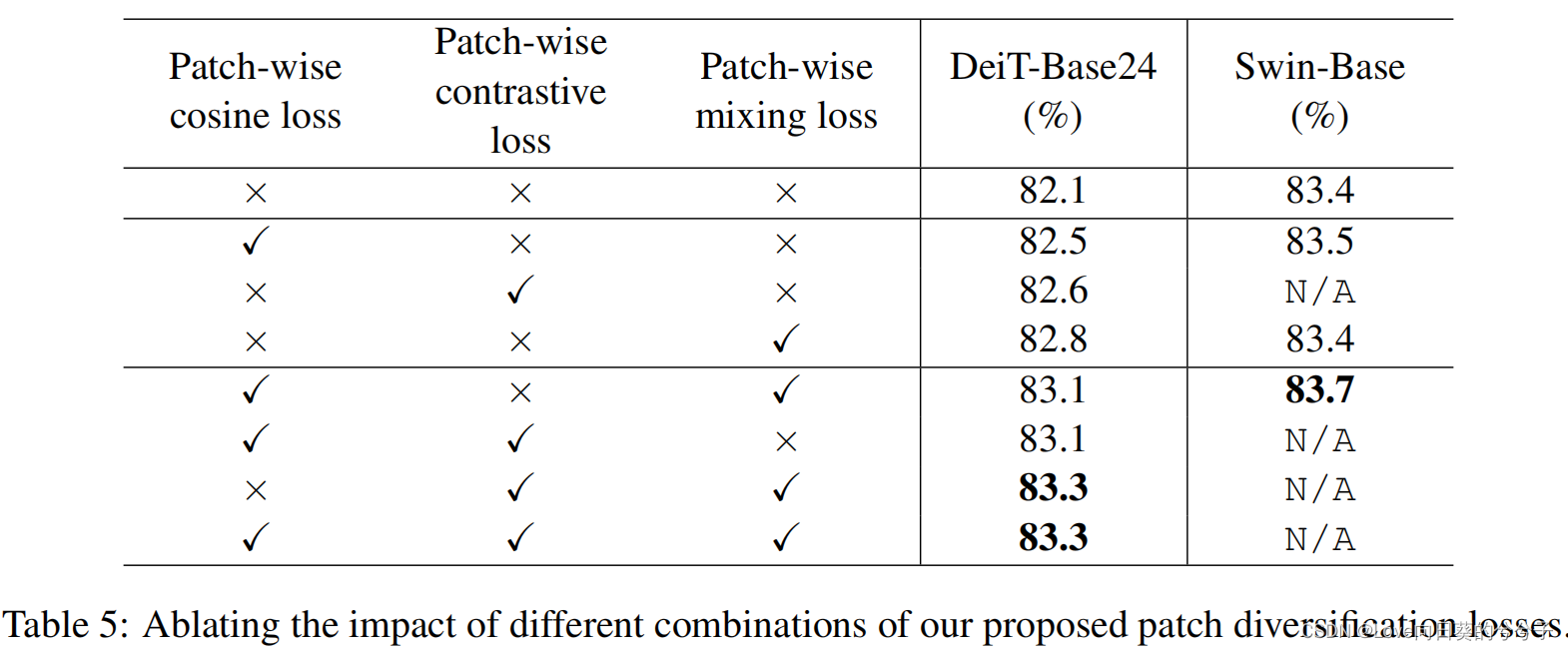
Para aliviar los problemas anteriores, este artículo no modifica ningún marco de modelo en el entrenamiento visual de Transformer , solo introduce una nueva función de pérdida para alentar explícitamente diferentes representaciones de parches para extraer características de manera más diferente. Específicamente, este artículo propone tres pérdidas diferentes, a saber,
1) Pérdida de coseno por parches: mejora directamente la diversidad entre diferentes representaciones de parches al penalizar la similitud de coseno por parches
2) Pérdida contrastiva por parches: una pérdida contrastiva basada en parches es Fomente que las representaciones entre parches correspondientes aprendidos entre la primera capa y las capas posteriores sean similares, y que las representaciones entre parches no correspondientes sean diferentes. (Esto se debe a que el autor observó que la representación del parche de entrada de la primera capa de autoatención solo depende de los píxeles de entrada y, por lo tanto, tiende a ser más diversa) 3
) Pérdida de mezcla por parche: una pérdida de mezcla por parche, similar a mezcla cortada. Combine parches de entrada de dos imágenes diferentes y utilice la representación del parche aprendida de cada imagen para predecir su etiqueta de clase correspondiente. En el caso de esta pérdida, la capa de autoatención se ve obligada a centrarse únicamente en los parches más relevantes para su propia categoría, aprendiendo así más características distintivas.
-
La pérdida de coseno por parche
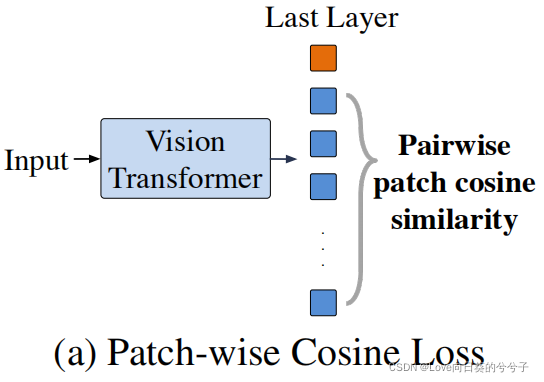
, como solución directa, propone minimizar directamente el valor absoluto de la similitud del coseno entre diferentes representaciones de parche, como se muestra en (a) arriba. Entrada dada xxEl último parche de x representa h [ L ] h^{[L]}h[ L ] , agregue una pérdida de coseno por parche al objetivo de entrenamiento:
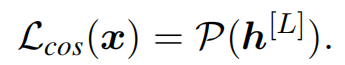
esta pérdida de regularización minimiza explícitamente la similitud de coseno por pares entre diferentes parches, lo que puede verse como una minimización del valor propio máximo de $$h El límite superior de, mejorando así la expresividad de la representación. -
Pérdida contrastiva por parches
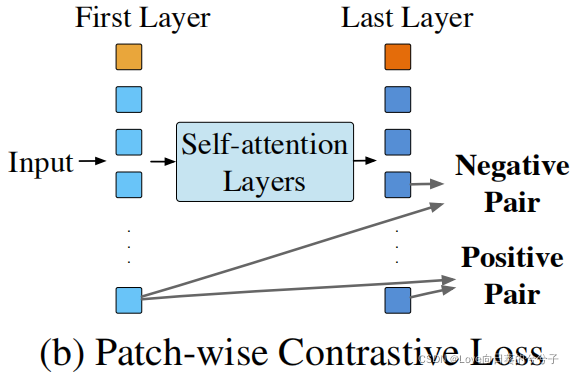
Las representaciones aprendidas en las primeras capas son más diversas que las aprendidas en las capas más profundas. Por lo tanto, se propone una pérdida contrastiva que utiliza representaciones de las primeras capas y regulariza parches más profundos para reducir la similitud de las representaciones de parches. Específicamente, dada la imagen de entrada xxx,h [ 1 ] = { hola [ 1 ] } ih^{[1]}=\{ h^{[1]}_i \}_ih[ 1 ]={ hi[ 1 ]}yo和h [ L ] = { hola [ L ] } ih^{[L]}=\{ h^{[L]}_i \}_ih[ L ]={ hi[ L ]}yoRepresentando los parches de la primera capa y la última capa respectivamente, restringimos cada hi [ L ] h^{[L]}_ihi[ L ]Hola [ 1 ] h^{[1]}_ihi[ 1 ]Similar a cualquier otro parche hj ≠ i [ 1 ] h^{[1]}_{j \neq i}hj= yo[ 1 ], es decir,
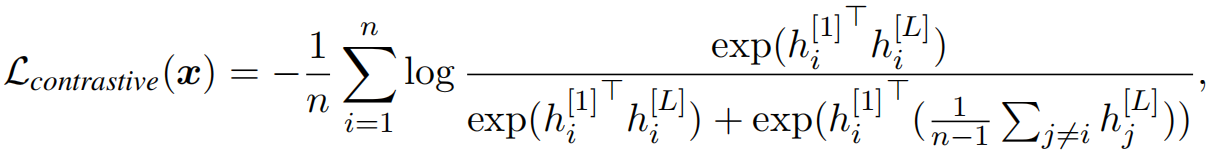
en el experimento, se detuvo el gradiente de h^{[1]}$. -
La pérdida de mezcla por parches
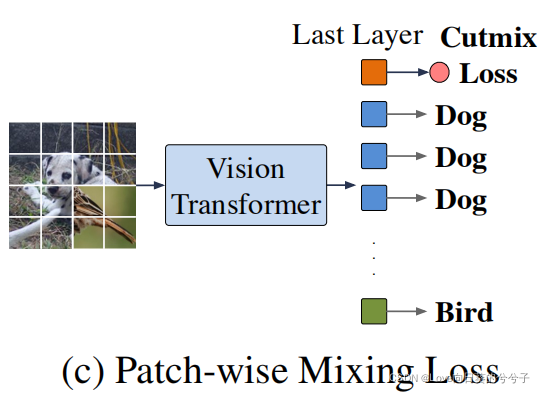
recomienda entrenar cada parche para predecir la etiqueta de clase, en lugar de simplemente usar parches de clase para la predicción final. Esto se puede combinar con el aumento de datos de Cutmix para proporcionar señales de entrenamiento adicionales al Transformer visual. Como se muestra en la Figura ©, los parches de entrada de dos imágenes diferentes se combinan y se adjunta un cabezal de clasificación lineal compartido a cada representación del parche de salida para su clasificación. La pérdida híbrida obliga a cada parche a centrarse únicamente en un subconjunto de parches de la misma imagen de entrada, ignorando los parches irrelevantes. Por lo tanto, evita eficazmente el simple promedio entre diferentes parches para producir una representación de parches más informativa y útil. La pérdida híbrida de este parche se puede expresar como
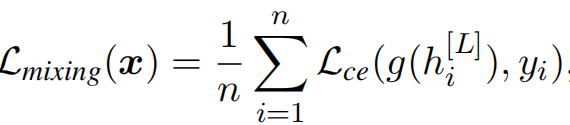
donde hi [ L ] h^{[L]}_ihi[ L ]Representa la representación del parche de la última capa, g es un encabezado de clasificación lineal adicional, yi y_iyyoRepresenta etiquetas de clases de parches, L ce \mathcal{L}_{ce}lc erepresenta la pérdida de entropía cruzada.
Finalmente, simplemente minimizando conjuntamente α 1 L cos + α 2 L contraste + α 3 L mezclando \alpha_1 \mathcal{L}_{cos} + \alpha_2 \mathcal{L}_{contrast} + \alpha_3 \mathcal {L }__{mezcla}a1lc o s+a2lcontrastar _ _ _ _ _ _ _+a3lmezclando _ _ _ _ _Combinación ponderada para mejorar el entrenamiento del transformador visual. No se requieren modificaciones de la red y no está vinculada a ninguna arquitectura específica. En los experimentos, este artículo simplemente establece α1 = α2 = α3 = 1 sin ningún ajuste de hiperparámetro específico.
3. Algunos resultados experimentales
- Resultados de clasificación de imágenes
1) Biblioteca ImageNet
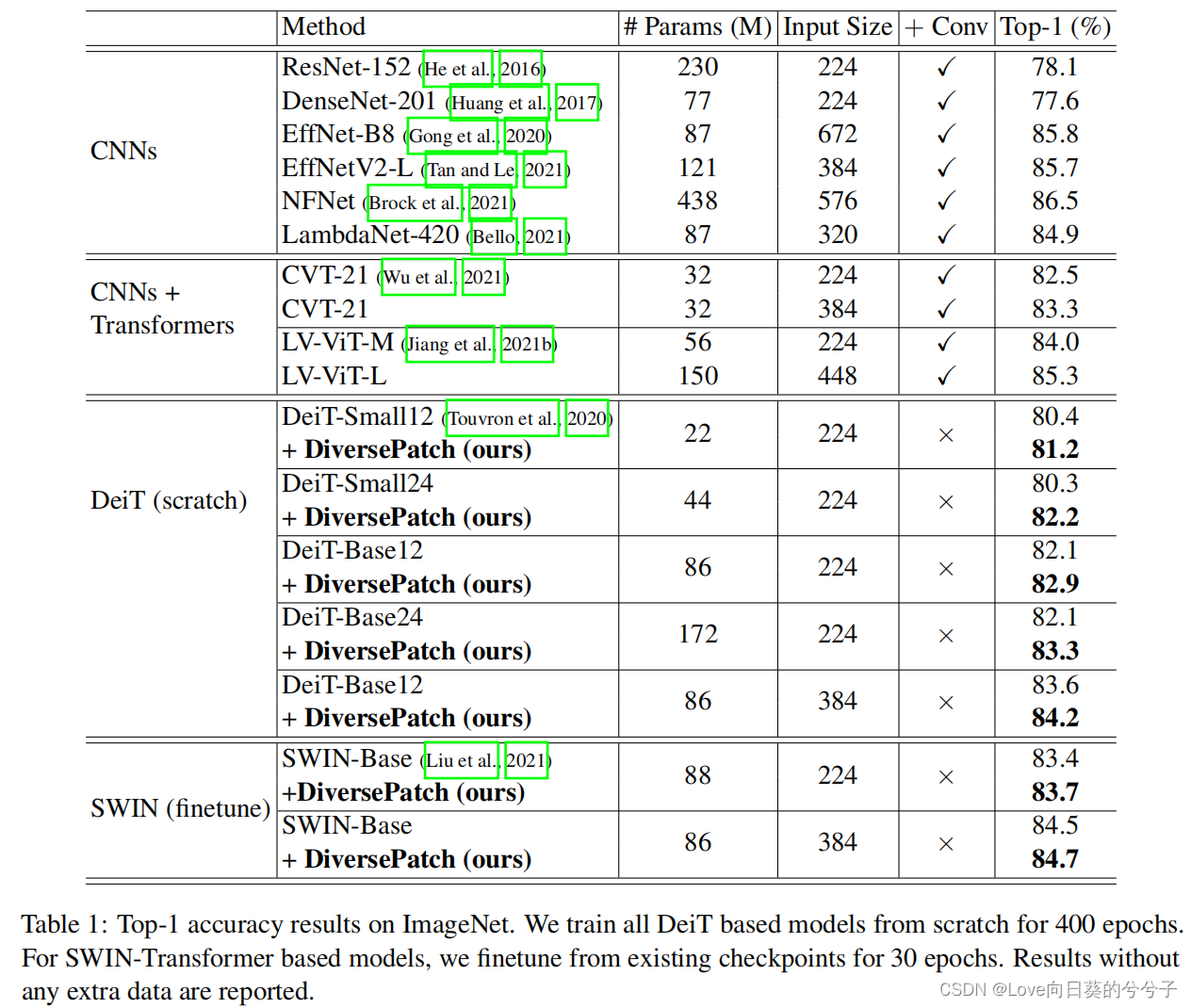
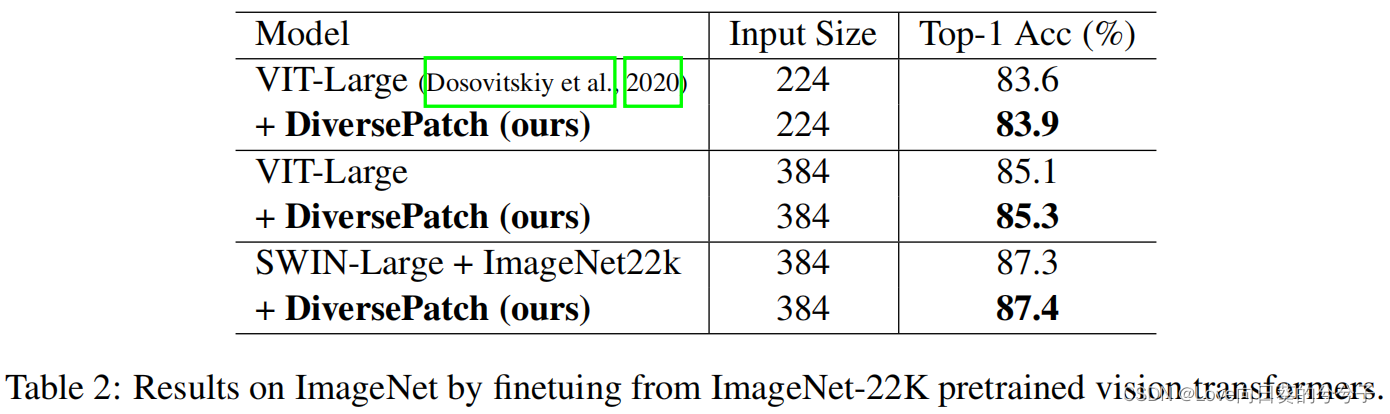
2) Biblioteca ImageNet-22K
- Transferir resultados de aprendizaje para segmentación semántica
1) Biblioteca ADE20K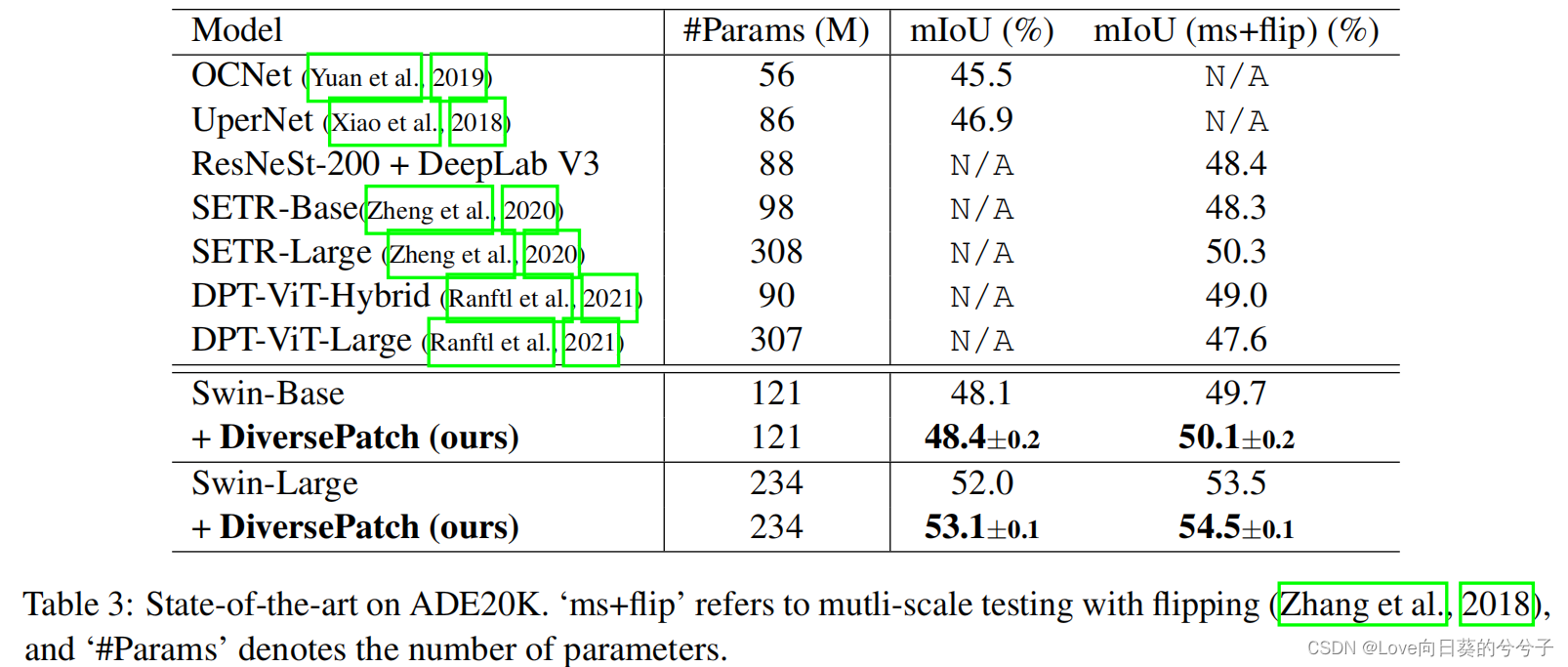
2) Biblioteca de paisajes urbanos
- Comparación de similitud de coseno absoluto de parche promedio (biblioteca ImageNet)
- Experimento de ablación
1) Eficacia de la estrategia de regularización
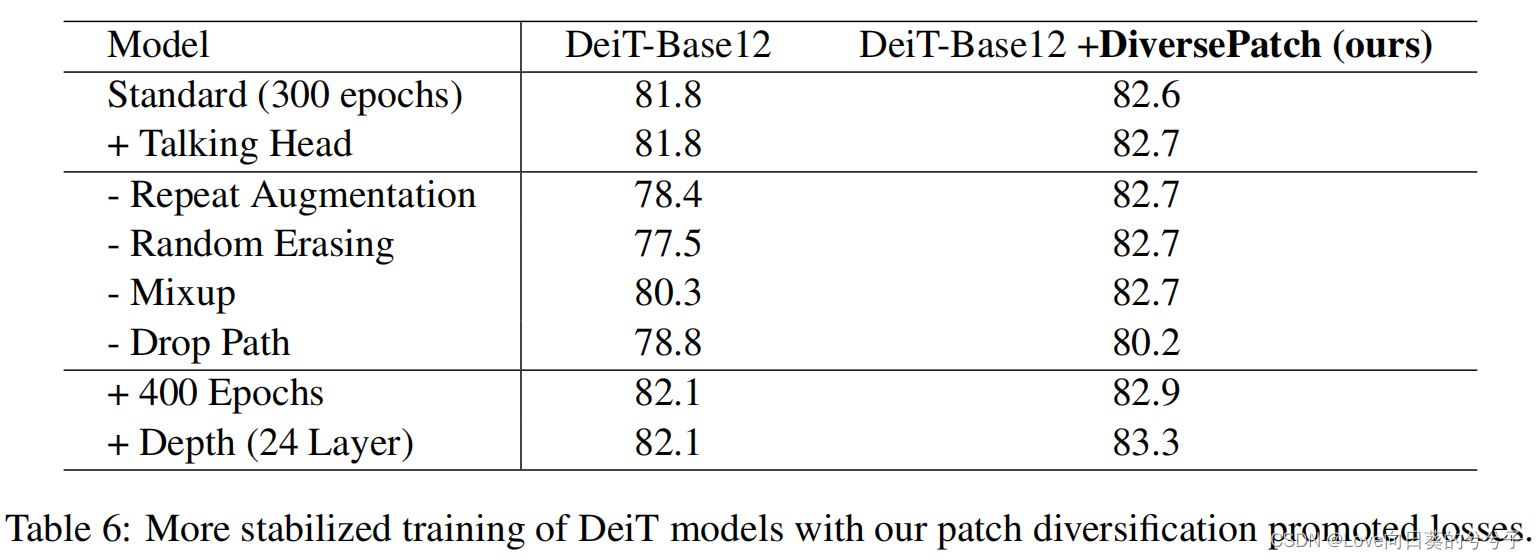
2) Estabilidad de la formación
4. Conclusión
1) El núcleo de este artículo es promover la diversidad de parches al entrenar la imagen Transformer, mejorando así la capacidad de aprendizaje del modelo. Este propósito se logra principalmente proponiendo tres pérdidas.
2) La experiencia del artículo muestra que al diversificar la representación del parche sin cambiar la estructura del modelo Transformer, es posible entrenar modelos más grandes y profundos y obtener un mejor rendimiento en las tareas de clasificación de imágenes.
3) El artículo solo realiza experimentos en tareas supervisadas.