Principios básicos del transformador visual.
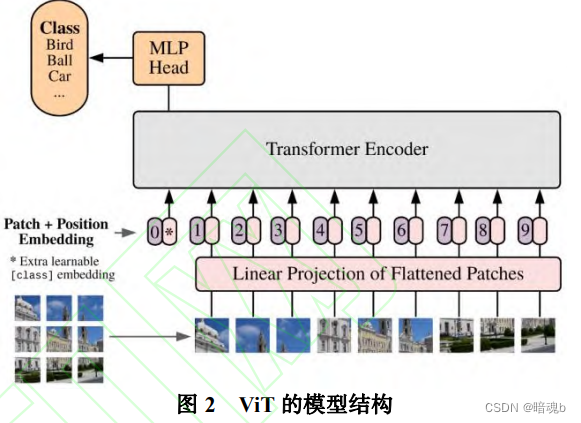
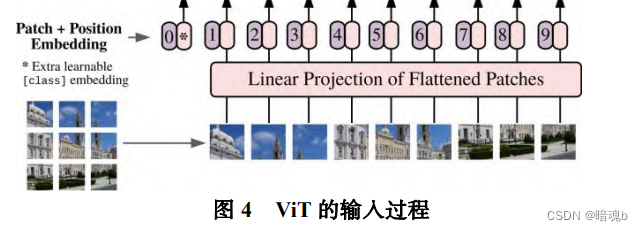
En el proceso de procesamiento de imágenes, ViT primero divide la imagen de entrada en bloques, realiza codificación lineal y mapeo en ellos, y luego los organiza en una pila de vectores como entrada del codificador. En la tarea de clasificación, se agrega un vector que se puede aprender a este vector unidimensional El vector de incrustación se utiliza como una representación del resultado de la predicción de categoría para la clasificación, y el resultado finalmente se genera a través de una capa completamente conectada.
mecanismo de atención
El mecanismo de atención permite que la red se centre más en la información relevante de la entrada, reduciendo así la atención a la información irrelevante.
pasos de cálculo:
- Divida la entrada _ _ _ _ _ _ v t
q i = a i W q k i =a i W k v i =a i W v
donde q i representa el vector de consulta, que se comparará con cada k i
más adelante. k i representa el vector consultado, que será posteriormente Para cada coincidencia de q i , v i representa el vector de información extraído de a i - Calcula la similitud entre q i y k i para obtener el peso.
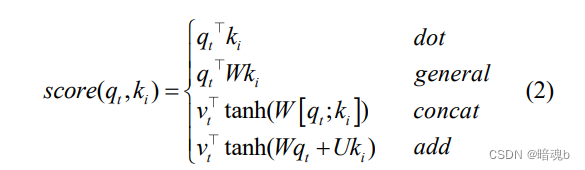
- Normalice los pesos de similitud. La función softmax se utiliza a menudo para normalizar la matriz de similitud en una matriz de ponderación de atención.
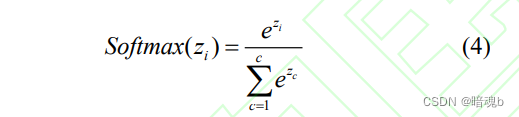
La función softMax se puede utilizar para convertir valores de salida de varias clases en una distribución de probabilidad que oscila entre [0,1] y 1. - La atención se obtiene sumando los vectores de información según el peso:
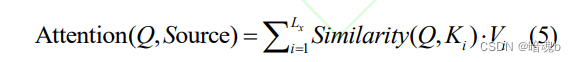
donde L x representa la longitud de la secuencia de entrada, Similitud representa el cálculo de similitud, Q, K y V representan el vector de consulta, el vector consultado y el vector de información respectivamente.
Serialización de imágenes y codificación posicional.
La entrada de Transfomer es una secuencia, para poder procesar la imagen es necesario convertir la imagen bidimensional en una secuencia unidimensional.
Módulo transformador
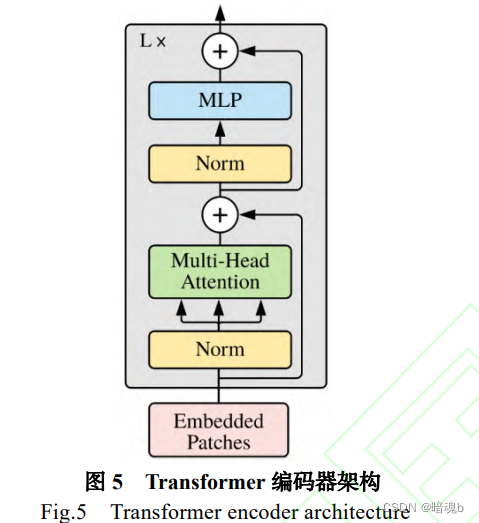
El módulo Transfomer se basa en la arquitectura de codificador y decodificador, y el codificador y decodificador se componen de múltiples capas. El codificador es responsable de extraer características y el decodificador es responsable de convertir las características extraídas en resultados. El codificador consta de una capa de atención y una capa completamente conectada.
Ventajas y desventajas de Visual Transformer
ventaja
- Fuerte capacidad de fusión multimodal
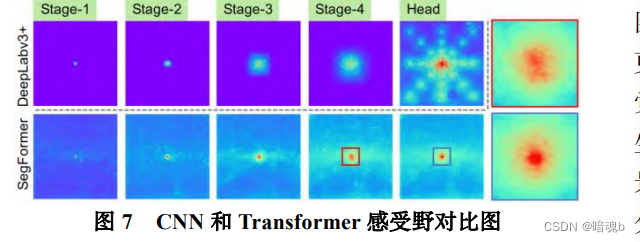
- Campo receptivo más amplio
defecto
- VIT tiene una gran cantidad de cálculos, parámetros y complejidad de algoritmos.
- Alta demanda de datos

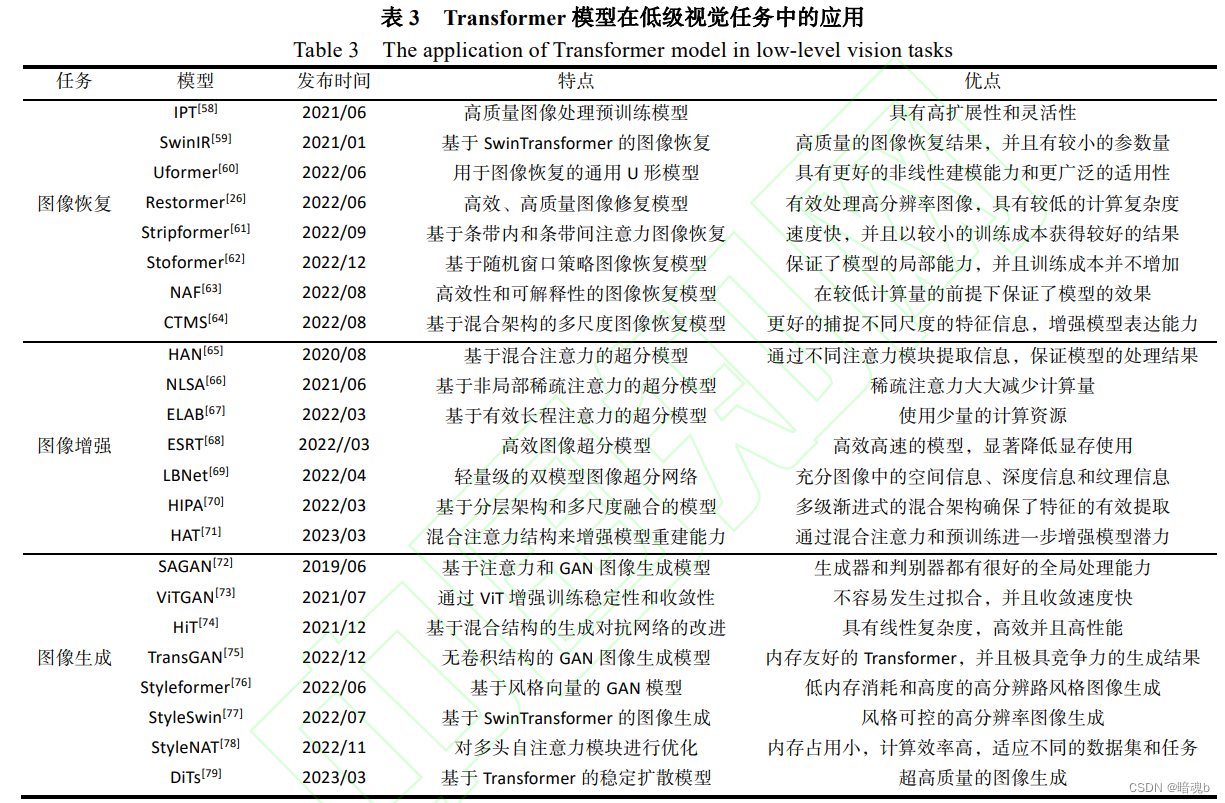
Aplicación de Transformer en tareas de visión de bajo nivel.
Conjuntos de datos de uso común para tareas de visión de bajo nivel.