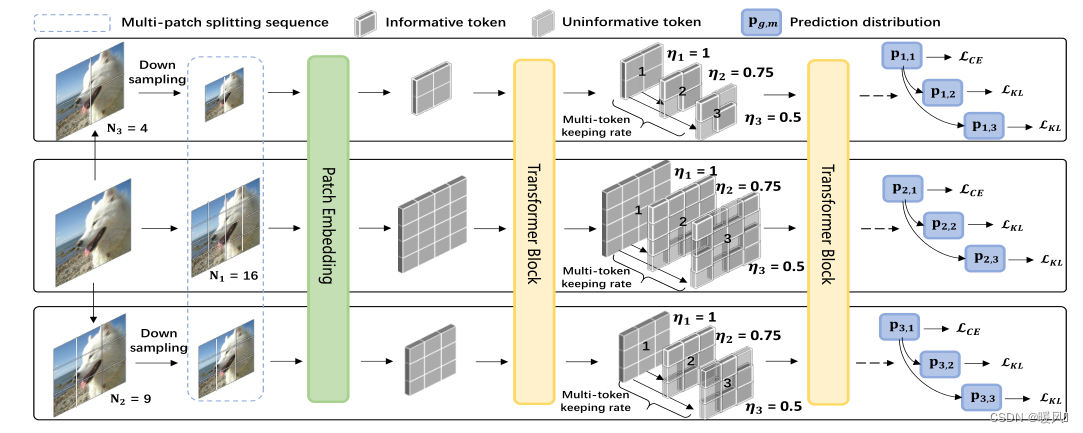
 Este artículo está dirigido principalmente aReducir el consumo computacional de Vision Transformer, se propone un nuevo método. En ViT, sabemos que la cantidad de tokens de Transformador es inversamente proporcional al tamaño del parche, lo que significa que cuanto menor sea el tamaño del parche, mayor será el costo computacional del modelo, y cuanto mayor sea el parche, mayor será la pérdida del modelo. efecto. Esto es contrario a nuestro propósito. El autor de SuperViT mejora el rendimiento desde dos aspectos:
Este artículo está dirigido principalmente aReducir el consumo computacional de Vision Transformer, se propone un nuevo método. En ViT, sabemos que la cantidad de tokens de Transformador es inversamente proporcional al tamaño del parche, lo que significa que cuanto menor sea el tamaño del parche, mayor será el costo computacional del modelo, y cuanto mayor sea el parche, mayor será la pérdida del modelo. efecto. Esto es contrario a nuestro propósito. El autor de SuperViT mejora el rendimiento desde dos aspectos: 多尺度的patch分割y 多种保留率. Minimice la cantidad de cálculo para acelerar el cálculo y mantener un mejor rendimiento del modelo. Básicamente, no hay ningún problema con este método en la clasificación de imágenes, pero en el campo de la superresolución, el descarte de píxeles seguirá afectando seriamente el rendimiento del modelo.
Enlace original: Super Vision Transformer