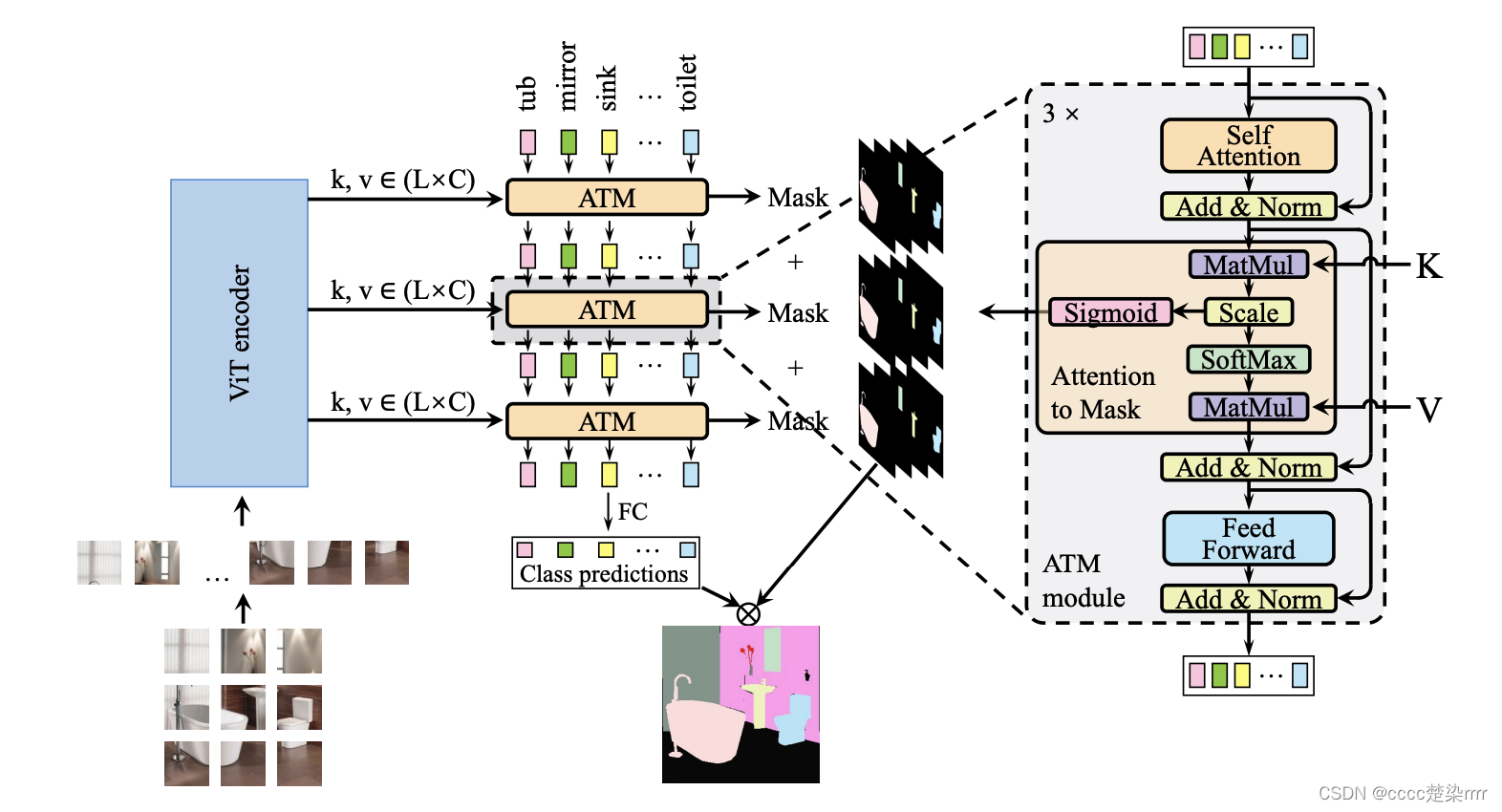
Quiere aprender del código fuente del modelo oficial de SegViT e implementarlo en su propio archivo de código local.
1. Configuración del entorno
El sitio web oficial requiere la instalación de mmcv-full=1.4.4 y mmsegmentation=0.24.0.
Recuerde desinstalar las versiones originales de mmcv y mmsegmentation antes de hacerlo.
pip uninstall mmcv
pip uninstall mmcv-full
pip uninstall mmsegmentation
Instalar mmcv
Entre ellos, mmcv incluye dos versiones: una es la versión completa de mmcv (originalmente llamada mmcv-full) y la otra es la versión simplificada de mmcv-lite (originalmente llamada mmcv), cuyo nombre cambió después de la versión 2.0.0. Para diferencias específicas, consulte el manual del sitio web oficial de mmcv , y el blog
para instalar mmcv-full (es decir, la versión completa de mmcv) consulte principalmente el manual del sitio web oficial de mmcv.
Si desea instalar mmcv>=2.0.0, puede instalarlo directamente de acuerdo con el manual del sitio web oficial sin entrar en detalles.
Si desea instalar una versión histórica, por ejemplo, instalé mmcv-full==1.4.4, puede consultar mis registros.
Antes de instalar mmcv, primero debe conocer sus versiones correspondientes de pytorch y cuda.
Ver la versión de pytorch:
python -c 'import torch;print(torch.__version__)'
Si se genera la información de la versión, se ha instalado pytorch.
Verifique la versión de cuda:
tenga cuidado de verificar la versión de cuda correspondiente a pytorch en su entorno.
Por ejemplo,
esta es la versión de cuda que solía verificar usando el comando nvidia-smi:

Este es el comando que utilicé para verificar la versión de cuda correspondiente a pytorch:
python -c 'import torch;print(torch.version.cuda)'
También se puede escribir como:
Blog de referencia: https://blog.csdn.net/qq_49821869/article/details/127700187
python
>>>import torch
>>>torch.version.cuda

Aquí mi versión de pytorch debería ser 1.11.0 y la versión de cuda correspondiente es 11.3
Blog de referencia: https://blog.csdn.net/qq_41661809/article/details/125345690
Entonces, ingresé el comando:
pip install mmcv-full==1.4.4 -f https://download.openmmlab.com/mmcv/dist/cu113/torch1.11.0/index.html
No tuvo éxito, así que visité este sitio web para comprobarlo y descubrí que la versión más baja que podía usar era 1.4.7,
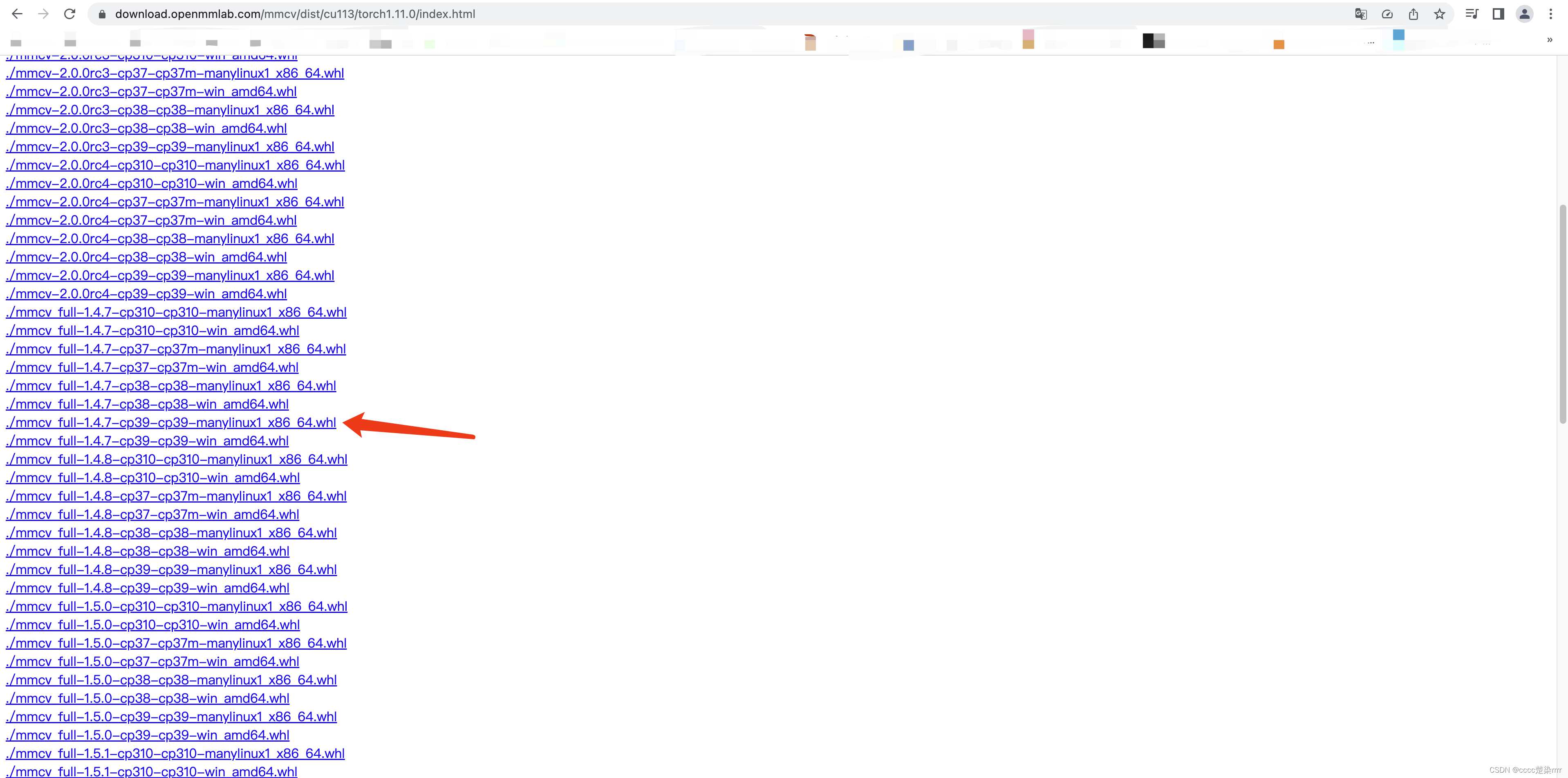
así que cambié el comando a:
pip install mmcv-full==1.4.7 -f https://download.openmmlab.com/mmcv/dist/cu113/torch1.11.0/index.html
Instalación completa de mmcv completada
Instalar segmentación mm
Originalmente instalé mmsegmentation de acuerdo con las instrucciones del sitio web oficial
, pero requería mmcv>=2.0.0 y la versión instalada era mmsegmentation==1.0.0, lo que entraba en conflicto con mis requisitos.
Tenga en cuenta que la segmentación mm debe coincidir con la versión mmcv:
Blog de referencia: https://blog.csdn.net/CharilePuth/article/details/122909620
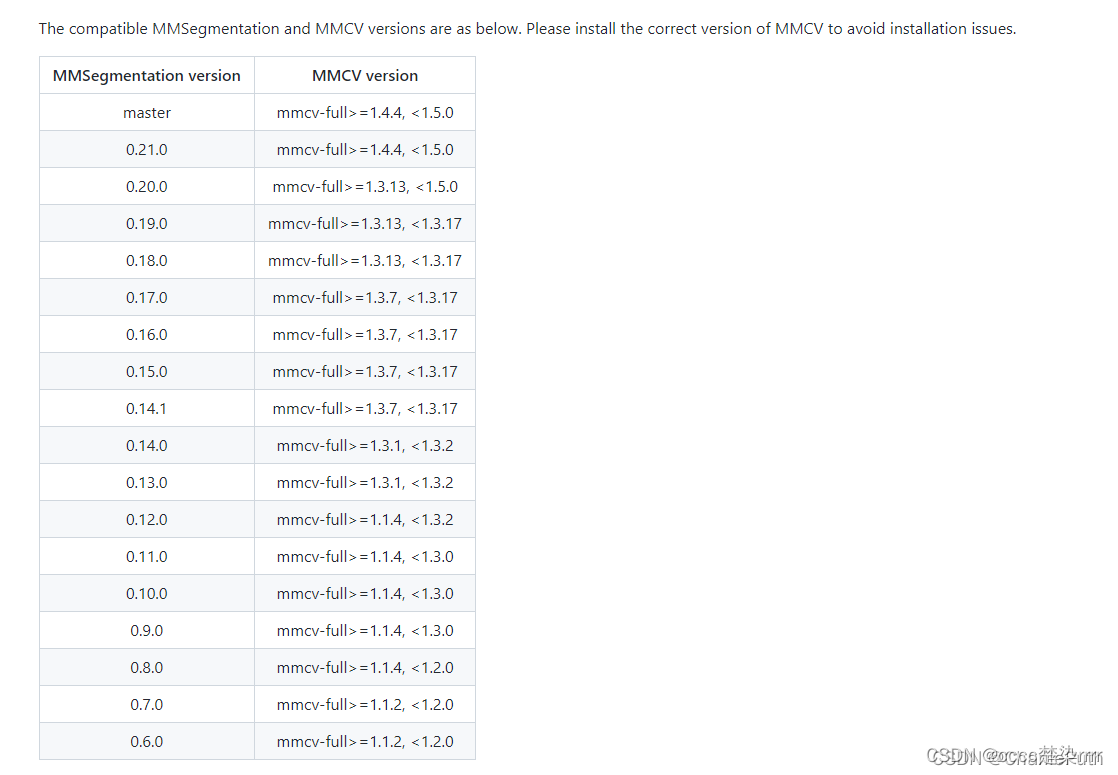
Entonces yo directamente:
pip install mmsegmentation==0.24.0
Instalación exitosa.
"El paquete de instalación de tuberías es tan fácil como beber agua", dijo una vez un gran jefe.
2. ¡Código!
Buscar archivo de configuración del modelo
Vaya al sitio web oficial y busque el archivo de configuración correspondiente al modelo en Capacitación: En Aspectos destacados, aprendí que
uno de los aspectos más destacados de este artículo es la estructura de contracción, que puede reducir los costos de cálculo, así que a continuación elegiré la estructura de contracción:

Dado que el tamaño de la imagen que quiero ejecutar es 512, encontré el modelo correspondiente del conjunto de datos COCO con el mismo 512*512 en los Resultados de este código:

Regrese a la carpeta de configuración para encontrar el modelo de red correspondiente a este conjunto de datos:
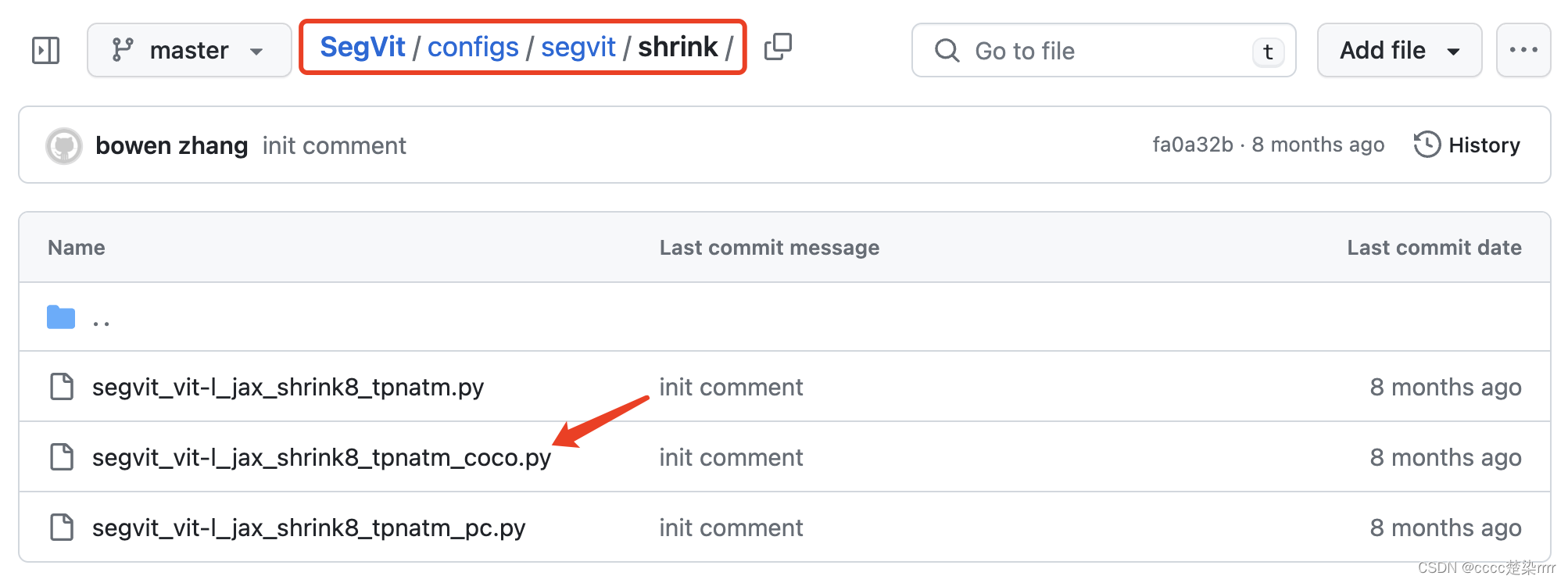
observe el código y aprenda que la columna vertebral utilizada es vit_shrink y el cabezal de decodificación es TPNATMHead:
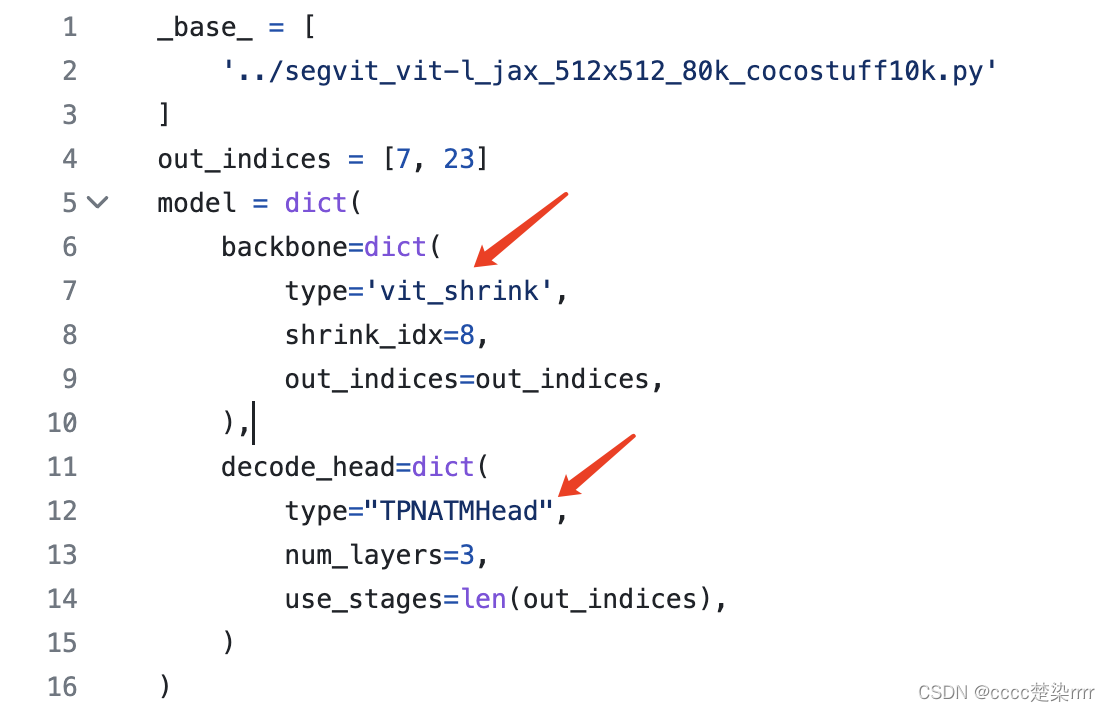
preste atención a la configuración de los parámetros y también al archivo de configuración. de __base__, cuyos parámetros se declaran en el modelo cuando lo ingresa.
Buscar código de modelo
Ingrese a la carpeta principal y busque la red vit_shrink:
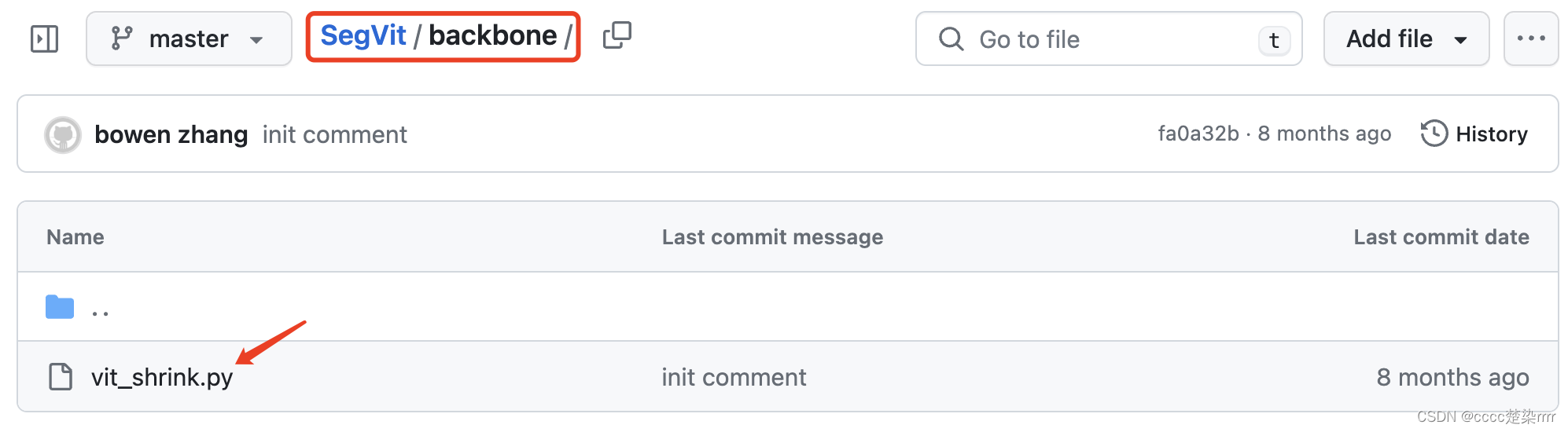
cópiela y péguela en su propio archivo py.
Busque el código del encabezado de decodificación en la carpeta decode_heads:
cópielo y péguelo en su propio archivo py.
parcheando el código
- Complemente el
archivo de la biblioteca con lo que falta en el archivo de la biblioteca. Por ejemplo, si necesita hacer referencia al contenido de los otros dos códigos de decodificador en el código de decodificador tpn_atm_head, ingrese directamente los códigos de los otros dos decodificadores con Ctrl C+V y deja los módulos que necesitas usar, solo baja:
- Verifique la entrada y salida de la
columna vertebral de entrada y salida:
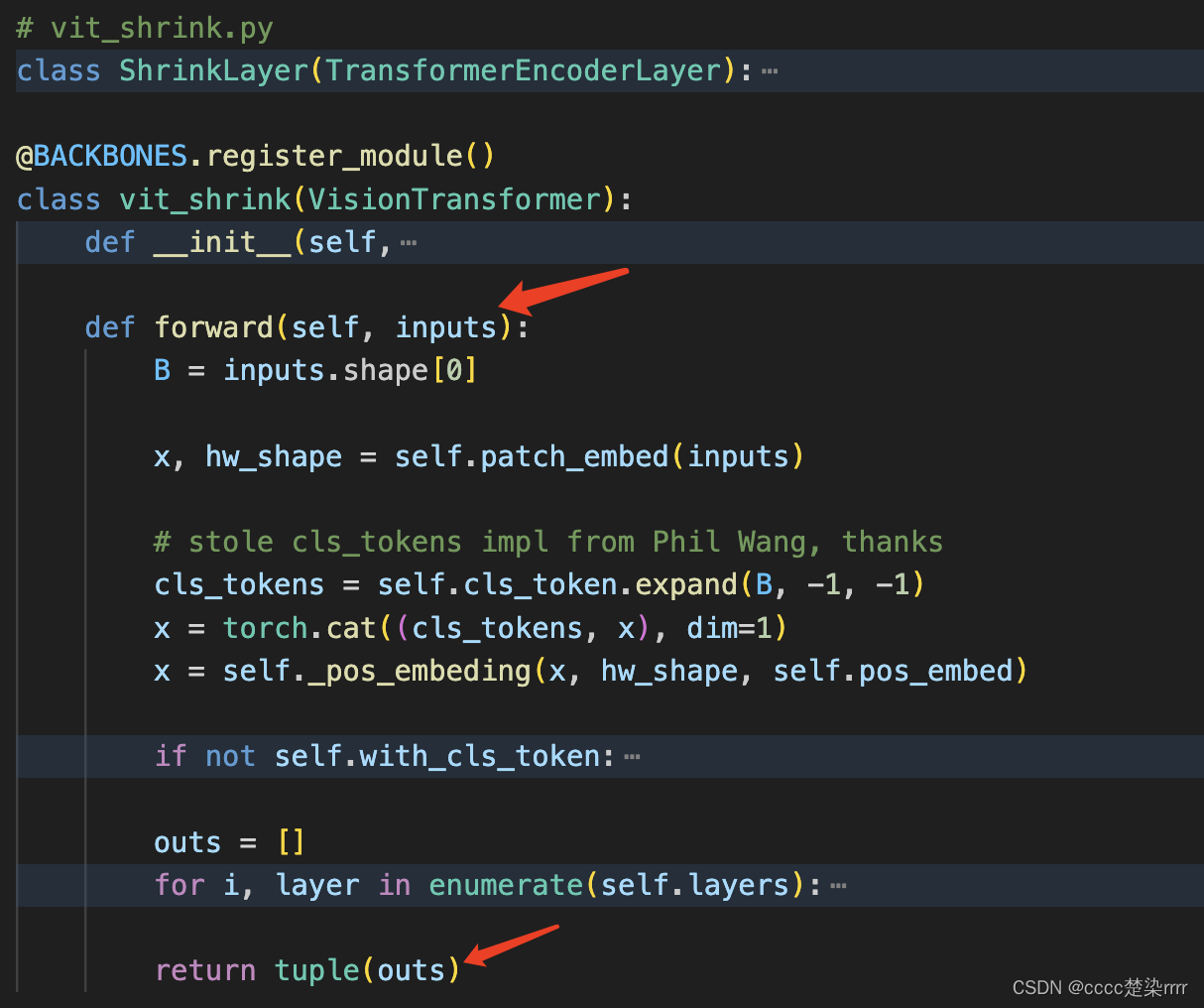
La entrada y salida de la parte del decodificador son como se muestra en la figura:
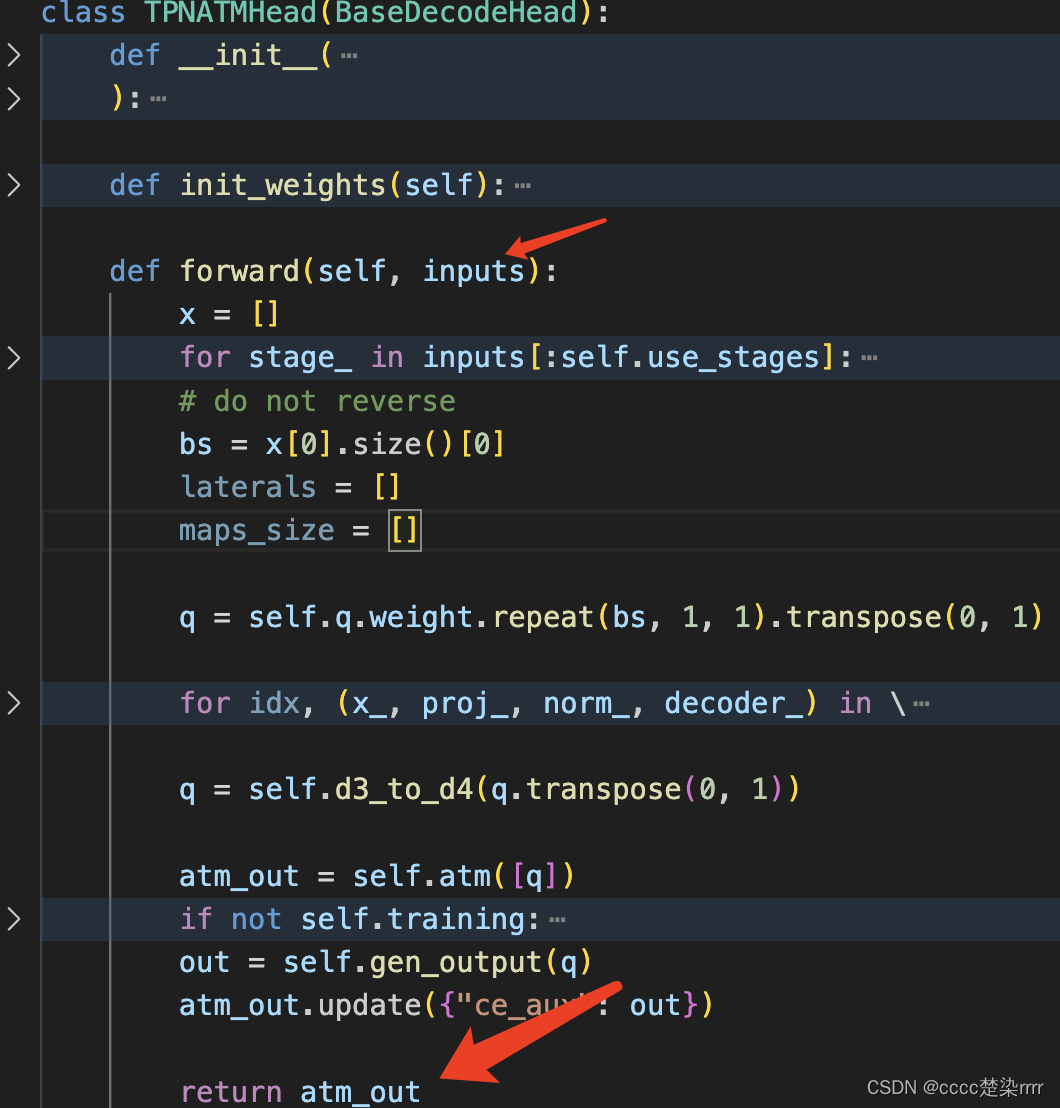
Escriba un SegViT para probar la entrada y la salida. Consulte el archivo de configuración para declarar la configuración correspondiente con anticipación. :
class SegViT(nn.Module):
def __init__(self, num_class):
super(SegViT, self).__init__()
out_indices = [7,23]
in_channels = 1024
img_size = 512
# checkpoint = './pretrained/vit_large_p16_384_20220308-d4efb41d.pth'
checkpoint = 'https://download.openmmlab.com/mmsegmentation/v0.5/pretrain/segmenter/vit_large_p16_384_20220308-d4efb41d.pth'
# self.backbone = get_vit_shrink()
self.backbone = vit_shrink(
img_size=(img_size,img_size),embed_dims=in_channels,num_layers=24,drop_path_rate=0.3,num_heads=16,out_indices=out_indices)
self.decoder = TPNATMHead(
img_size=img_size,in_channels=in_channels,channels=in_channels,embed_dims=in_channels//2,num_heads=16,num_classes=num_class,num_layers=3, use_stages=len(out_indices))
def forward(self, _x):
x = self.backbone(_x)
out = self.decoder(x)
# if self.training:
# return out['pred'], out['ce_aux']
# else:
# return out
return out
Ejecutar tipo de salida
if __name__ == "__main__":
x = torch.randn(4, 3, 512, 512)
net = SegViT(6)
# flops, params = profile(net, (x,))
# print('flops: %.2f G, params: %.2f M' % (flops / 1000000000.0, params / 1000000.0))
# res, aux = net(x)
res = net(x)
print(res)
Luego se encuentra que la salida es del tipo diccionario, la predicción es el valor correspondiente al nombre de la clave pred, el valor es del tipo tensor, el tamaño de la forma es (4,6,512,512) y la salida es correcta.
A continuación necesitamos encontrar la salida de la rama auxiliar.
Se encuentra al frente del encabezado del decodificador:

elimine los comentarios para obtener la salida de la rama auxiliar (la salida de la rama auxiliar se agregará a atm_out en forma de elementos de diccionario, puede depurarlo), recuerde agregar los comentarios de la función de inicialización correspondiente Elimine también:
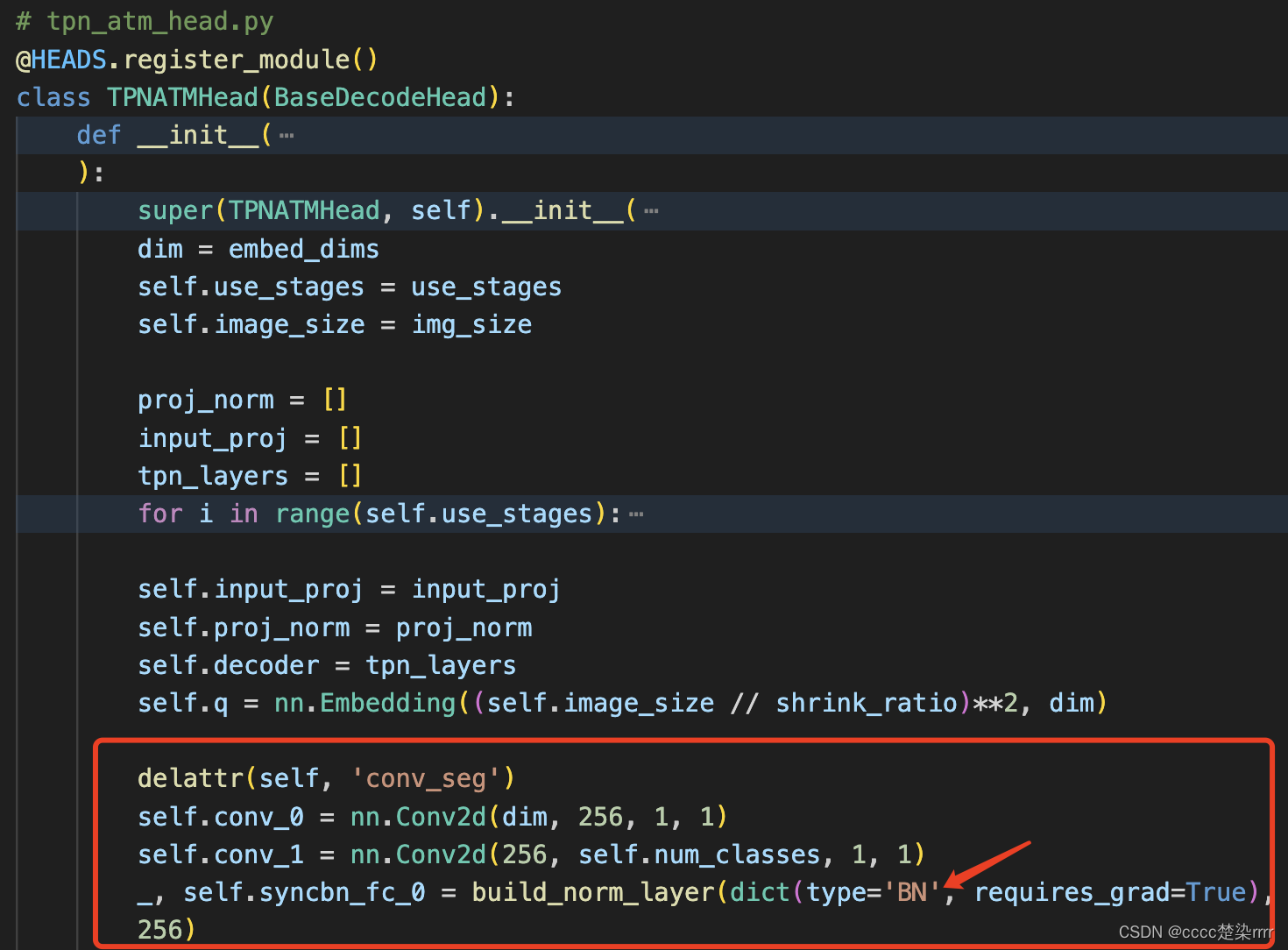
Entre ellos, como estoy ejecutando con una sola tarjeta, cambié SyncBN a BN; de lo contrario, se informará un error.
Además, el resultado de la fase de capacitación y la fase de prueba es diferente, y se puede depurar y verificar:
def forward(self, _x):
x = self.backbone(_x)
out = self.decoder(x)
if self.training:
return out['pred'], out['ce_aux']
else:
return out
- Cargue el archivo de peso.
Tenga en cuenta que el archivo de peso se puede descargar con antelación.
def get_vit_shrink(pretrained=True, img_size=512, in_channels=1024, out_indices=[7,23]):
model = vit_shrink(
img_size=(img_size,img_size),embed_dims=in_channels,num_layers=24,drop_path_rate=0.3,num_heads=16,out_indices=out_indices)
if pretrained:
checkpoint = '权重文件所在路径'
# if 'state_dict' in checkpoint: state_dict = checkpoint['state_dict']
# else: state_dict = checkpoint
model.load_state_dict(checkpoint, strict=False)
return model
El modelo final es:
class SegViT(nn.Module):
def __init__(self, num_class):
super(SegViT, self).__init__()
out_indices = [7,23]
in_channels = 1024
img_size = 512
# checkpoint = './pretrained/vit_large_p16_384_20220308-d4efb41d.pth'
# checkpoint = 'https://download.openmmlab.com/mmsegmentation/v0.5/pretrain/segmenter/vit_large_p16_384_20220308-d4efb41d.pth'
self.backbone = get_vit_shrink()
self.decoder = TPNATMHead(
img_size=img_size,in_channels=in_channels,channels=in_channels,embed_dims=in_channels//2,num_heads=16,num_classes=num_class,num_layers=3, use_stages=len(out_indices))
def forward(self, _x):
x = self.backbone(_x)
out = self.decoder(x)
if self.training:
return out['pred'], out['ce_aux']
else:
return out
- Verifique la entrada y salida final
.
3. Ejecute el modelo
En su propio marco, configure los parámetros y luego ejecútelo.
Finalizar.