I. Resumen
La mayor diferencia entre la arquitectura Transformer y las tradicionales CNN y RNN es que solo se basa en el mecanismo de autoatención sin operaciones de convolución/bucle. En comparación con RNN, no necesita realizar operaciones de temporización y se puede paralelizar mejor ; en comparación con CNN, puede enfocar toda la imagen a la vez y no se limita al tamaño del campo receptivo.
2. Arquitectura modelo
1. Módulos funcionales
La estructura del módulo de función se muestra en la siguiente figura:

Entradas : entrada del codificador
Salidas : Entrada del decodificador ( se utiliza como entrada la salida del decodificador en el momento anterior )
Codificación posicional :
Bloque transformador (codificador): consta de una capa de atención de varios cabezales con conexiones residuales y una red de transferencia directa con conexiones residuales . La salida del codificador se utiliza como entrada del decodificador.

Bloque transformador (decodificador): en comparación con el codificador, hay un mecanismo de atención de múltiples cabezales enmascarados (enmascarar la atención de múltiples cabezales).

2. Estructura de la red
①Codificador _
Se apilan 6 bloques de transformadores , y cada bloque tiene dos Sublyaer (subcapas) ( mecanismo de autoatención de múltiples cabezales (mecanismo de autoatención de múltiples cabezales) + MLP (perceptrón de múltiples capas)), y finalmente pasa a través de una normalización de capa .
Su fórmula se puede expresar como: <con conexión residual>
Layer Norm es similar a Batch Nrom, ambos son algoritmos de promedio. La diferencia es que Batch Nrom es para encontrar el valor medio en un lote (columna), mientras que Layer Norm es para encontrar el valor medio en una muestra (fila ) .
②Decodificador _
Se apilan 6 bloques de transformadores , y hay tres Sublyaer (subcapas) en cada bloque, y se realizará una autorregresión en el decodificador (la entrada en el momento actual es la salida en el momento anterior). Para garantizar que la salida posterior no se vea en el tiempo t, se agrega un mecanismo de enmascaramiento al primer bloque de atención de múltiples cabezales para protección.
③Mecanismo de atención
Función de atención ( una función que mapea consultas y algunos pares clave-valor en una salida , y el peso de cada valor se obtiene de la similitud entre su clave correspondiente y la consulta consulta )
Su fórmula se puede escribir como:
Las longitudes de la consulta y la clave son iguales , y la longitud del valor es igual
; el producto interno de cada conjunto de consulta y clave se usa como la similitud (cuanto mayor es el valor, mayor es la similitud - función cos); después de obtener el resultado, dividir por (es decir, la longitud del vector), finalmente obtener el peso con un softmax.
Después de obtener el peso, se multiplica por vuale para obtener el resultado.
En la operación real, tanto la consulta como la clave se pueden escribir como una matriz, y el método que se muestra en la figura a continuación se usa para el cálculo.

Mecanismo de enmascaramiento : Para la entrada del tiempo k , en el cálculo sólo se debe ver el valor
hasta el momento
, pero de hecho, el cálculo de atención
operará con todos los k. Introduzca sólidamente un mecanismo de enmascaramiento, el método específico es: reemplace
el valor calculado con un número negativo grande , que se convertirá en 0 después de softmax.
Mecanismo de cabezales múltiples : proyecte toda la consulta, la clave y el valor en dimensiones bajas (h veces, h = 8 en el texto original) y luego realice h veces de funciones de atención ; combine los resultados de cada función y luego proyéctelos volver a las dimensiones altas para obtener el resultado. Como se muestra abajo:
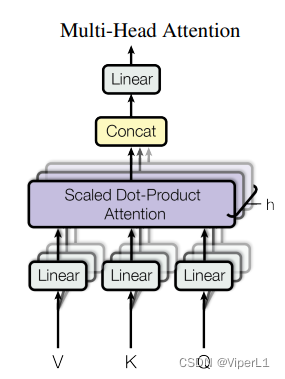
El lineal en la figura se usa para proyección de baja dimensión; la atención de producto de punto escalado es el mecanismo de atención. concat es responsable de combinar los resultados.
Su fórmula es:
dónde
三、VIT(Transformador de visión)
Existe otra dificultad al aplicar Transformer al procesamiento de imágenes: si usa directamente los píxeles de la imagen como secuencia de entrada, se enfrentará al problema de que la secuencia de entrada es demasiado larga. La red VIT soluciona este problema dividiendo la imagen en pequeños parches .
VIT divide el tamaño de 16x16 en un parche.Tomando como ejemplo la entrada de imagen estándar de 224x224, se convierte en 196 parches después del parche, lo que reduce considerablemente el tamaño de la secuencia de entrada.

1. Estructura del modelo
Primero, divida la imagen en varios parches; coloque estos parches en la capa de proyección lineal (Proyección lineal de parches aplanados, es decir, una capa completamente conectada) y luego agregue información de codificación de posición a cada parche (para evitar que la imagen el orden se invierta) Fusionado en un token (añadido directamente en lugar de fusionado). Luego envíe este token al codificador del transformador. Al mismo tiempo, el jefe del token debe colocar el token cls (información de clasificación) para indicar la categoría a la que pertenece; el cls finalmente generado por el mecanismo de autoatención es la información de clasificación.

2. Codificador de transformador
