Segmentación de instancias de video La segmentación de instancias de video, sobre la base de vos, etiqueta cada instancia.
La segmentación de instancias es detección de objetivos + segmentación semántica. El objetivo se detecta en la imagen y luego a cada píxel del objetivo se le asigna una etiqueta de categoría, que puede distinguir diferentes instancias con la misma categoría semántica de primer plano.
Conjunto de datos: Youtube-VIS
Predecesor: segmentación de instancias de video
- Dirección en papel: VIS
- Código de dirección: MaskTrackRCNN
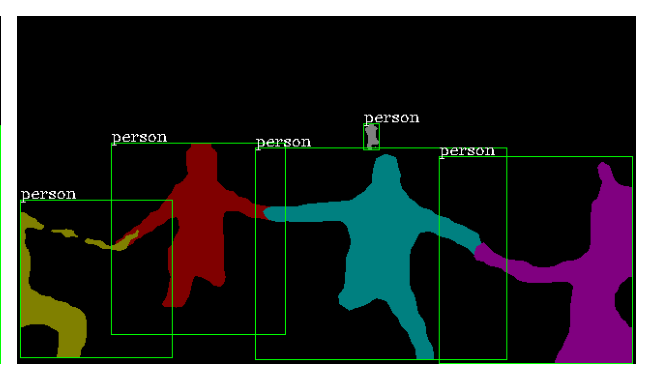
VisTR:Segmentación de instancias de video de extremo a extremo con transformadores
- Dirección en papel: VisTR CVPR2021
- Dirección del código: https://git.io/VisTR
- Enlace de referencia: CVPR 2021 Oral: método de segmentación de instancias de video de extremo a extremo basado en transformadores VisTR
problema resuelto
VIS no solo detecta y segmenta objetos en un solo cuadro de imágenes, sino que también encuentra la relación correspondiente de cada objeto en múltiples cuadros, es decir, los asocia y los rastrea.
- El video en sí mismo son datos a nivel de secuencia y se modela como una tarea de predicción de secuencias. Dada la entrada de varios fotogramas, la salida de la secuencia de máscara de segmentación de varios fotogramas requiere un modelo que pueda procesar varios fotogramas en paralelo .
- Unifique las dos tareas de segmentación y seguimiento de objetivos. La segmentación es el aprendizaje de similitudes de las características de los píxeles, y el seguimiento de objetivos es el aprendizaje de similitudes de las características de las instancias.
Aplicación de transformadores a la segmentación de instancias de video
- sí mismo para secuencia a secuencia
- El transformador es bueno para modelar secuencias largas y se puede usar para establecer dependencias de larga distancia y aprender información de tiempo a través de múltiples marcos.
- La autoatención puede aprender y actualizar funciones en función de la similitud entre pares, y puede aprender mejor la correlación entre marcos
De extremo a extremo, considere las características temporales y espaciales del video como un todo, refiriéndose a DETR
introducir
Tarea: Realice la segmentación de instancias para cada marco y establezca la asociación de datos de instancias en marcos consecutivos al mismo tiempo: seguimiento de seguimiento
Resumen: trata la tarea VIS como un paralelosecuenciaProblemas de decodificación/predicción. Dado un videoclip que consta de múltiples cuadros de imagen como entrada, VisTR genera directamente una secuencia de máscaras para cada instancia en el video. En este documento, la secuencia de salida de cada instancia se denomina secuencia de instancia.
En la imagen a continuación, los marcos se distinguen por la forma, las instancias se distinguen por el color, tres marcos y cuatro instancias
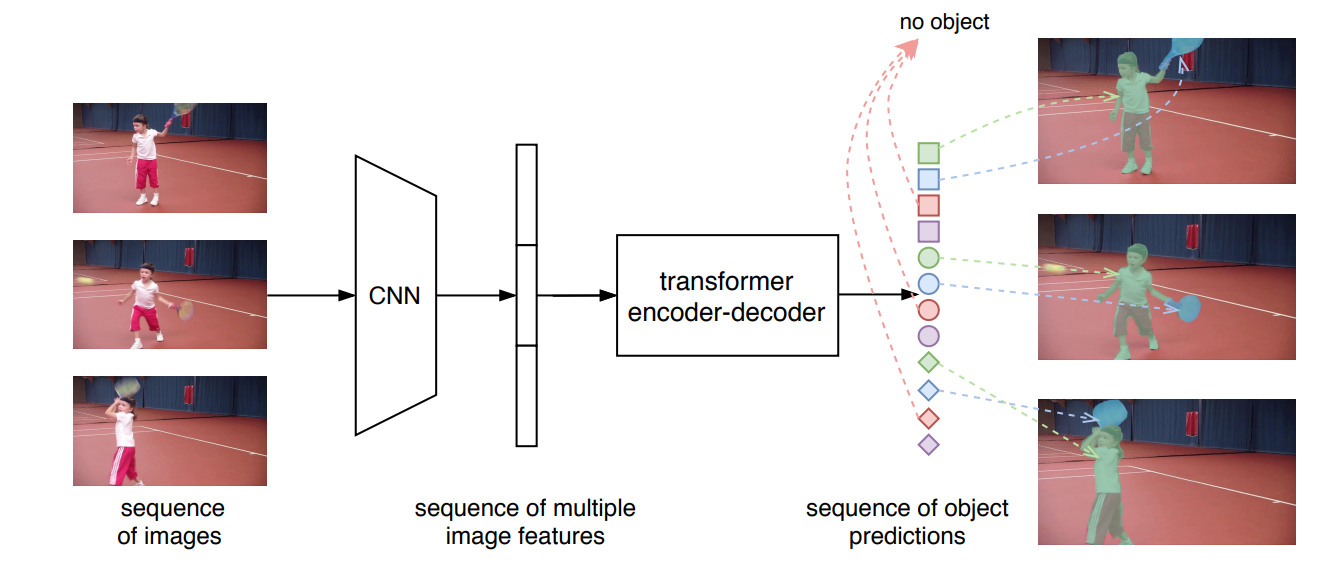
-
En la primera etapa, dada una secuencia de cuadros de video, un módulo CNN estándar extrae las características de un solo cuadro de imagen y luego concatena múltiples características de imagen en orden de cuadro para formar una secuencia de características.
Nota: La selección de la red en la etapa de extracción de características se puede cambiar según el tipo de imagen
-
En la segunda etapa, el transformador toma una secuencia de características a nivel de segmento como entrada y genera una secuencia de predicciones de instancias en secuencia. La secuencia de predicciones sigue el orden de los cuadros de entrada , mientras que las predicciones para cada cuadro también siguen el mismo orden de instancias .
Desafío : modelado como un problema de predicción de secuencias
Aunque en la entrada inicial, la entrada y la salida de múltiples cuadros en la dimensión de secuencia de tiempo están ordenadas, pero para un solo cuadro, la secuencia de instancias no está ordenada en el estado inicial y la asociación de seguimiento de instancias no se puede realizar, por lo que es necesario Es obligatorio hacer que el orden de las instancias de salida de cada cuadro de imagen sea coherente, de modo que siempre que se encuentre la salida de la posición correspondiente, la asociación de la misma instancia se pueda realizar de forma natural.
Cómo mantener el orden de la salida
Estrategia de coincidencia de secuencias de instancias: dimensionamiento de secuencias de características en la misma posición de fuerza
Realice coincidencias de gráficos bipartitos entre las secuencias reales de salida y de tierra y supervise las secuencias como un todo
Cómo obtener la secuencia de máscara para cada instancia de la red del transformador
Módulo de segmentación de secuencias de instancias: obtenga las características de la máscara de cada instancia en varios fotogramas con autoatención y utilice la convolución 3D para segmentar la secuencia de máscaras de cada instancia
Estructura general de VisTR
Una red troncal de CNN para extraer representaciones de características de múltiples cuadros (Aquí se pueden usar diferentes redes de extracción de características de acuerdo con los diferentes requisitos de la escena.)
Un transformador codificador-decodificador para modelar la similitud de las características a nivel de píxel y a nivel de instancia
Un módulo de coincidencia de secuencias de ejemplo
Un módulo de segmentación de secuencias de instancias
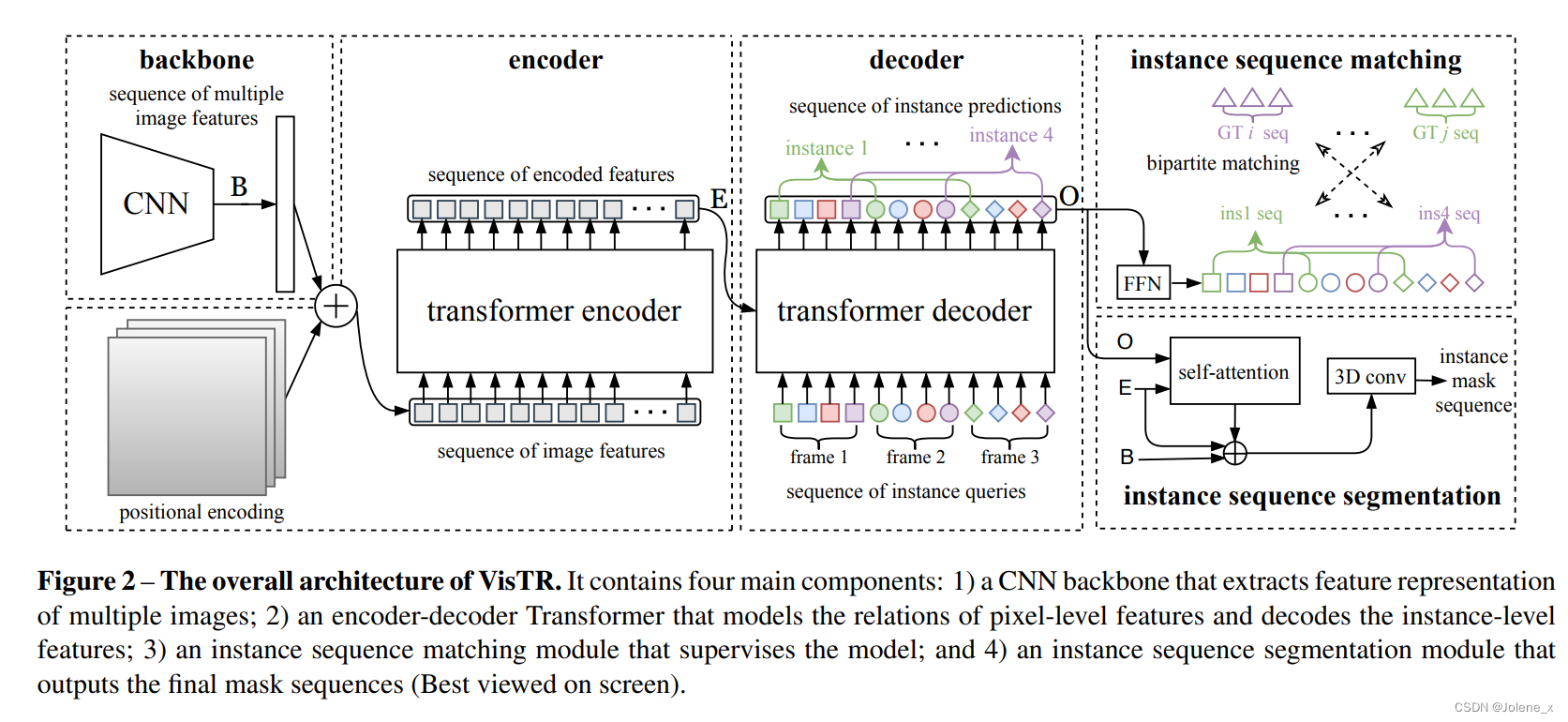
columna vertebral
Entrada inicial: cuadro T * número de canales 3 * H' * W'
Matriz de características de salida (concat cada cuadro): T * C * H * W
codificador de transformador
Aprenda la similitud entre puntos y puntos, y la salida es una secuencia densa de características de píxeles
Primero, las características extraídas por la columna vertebral se reducen en una convolución 1*1: T * C * H * W => T * d * H * W
Aplanamiento: la entrada del transformador debe ser bidimensional, por lo tanto, aplane el espacio (H, W) y el tiempo (T), T * d * H * W => d * (T * H * W)
La comprensión del aplanamiento: d es similar al canal, y T * H * W son todos los píxeles de todos los cuadros T de esta secuencia
Codificación de posiciones en el tiempo y el espacio
Codificación posicional temporal y espacial.
La dimensión del código de posición final es d
El resultado de Transformer es independiente de la secuencia de entrada, y la tarea de segmentación de instancias requiere información de posición precisa, por lo que la característica se complementa con información de codificación de posición fija, que contiene la posición tridimensional (tiempo, espacio - H, W) en el Información del segmento, enviada al codificador junto con la información de características extraída por la red troncal
En el transformador original, la información de posición es unidimensional, por lo que iii es de 1 a d dimensión, entonces2k 2k2 k de 0 a d,wk w_kwkGradualmente de 1 a infinitamente cerca de 0
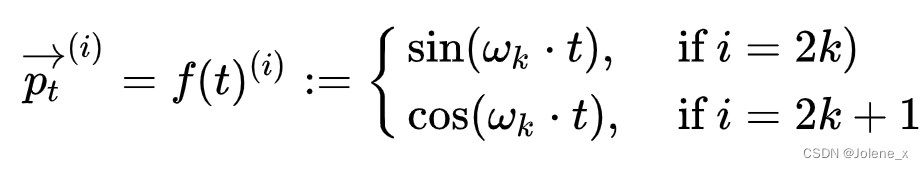
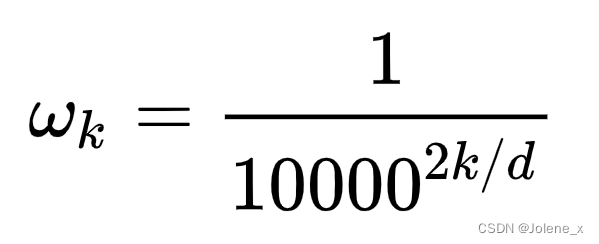
Entonces el vector en la posición t final también es de dimensión d:
pt = [ sin ( w 1 . t ) cos ( w 1 . t ) sin ( w 2 . t ) cos ( w 2 . t ) sin ( wd / 2 . t ) cos ( wd / 2 . t ) ] d p_t = \left[ \begin{matrix} sin(w_1 .t)\\ cos(w_1 .t)\\ sin(w_2 .t)\\ cos(w_2 .t) \\ \\ \\ sin(w_{d/2}.t)\\ cos(w_{d/2}.t)\\ \end{matriz} \right] _dpagt=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡pecado _ _ _ _1. t )c o s ( w1. t )pecado _ _ _ _2. t )c o s ( w2. t )pecado _ _ _ _d / 2. t )c o s ( wd / 2. t )⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤re
En este artículo lo que hay que considerar es la posición de las tres dimensiones, H, W, T, es decir, para un punto de píxel, sus coordenadas tienen tres valores, por lo que para tres dimensiones, independientemente generar d / 3 d/ 3d / vector de posición tridimensional
Para las coordenadas de cada dimensión, utilizando las funciones seno y coseno de forma independiente, se obtiene d/3 d/3vector de d / 3 dimensiones
punto de ventap o s representa las coordenadas (h , w , th, w, th ,w ,t ),iii representa la dimensión, suponiendo que solo mirehhh , seccióniii de 1 ad/3 d/3d / 3 dimensiones, al mismo tiempo para garantizarwk w_kwkEl valor está entre 0 y 1, así que aquí wk w_kwkNo es lo mismo que el transformador original.
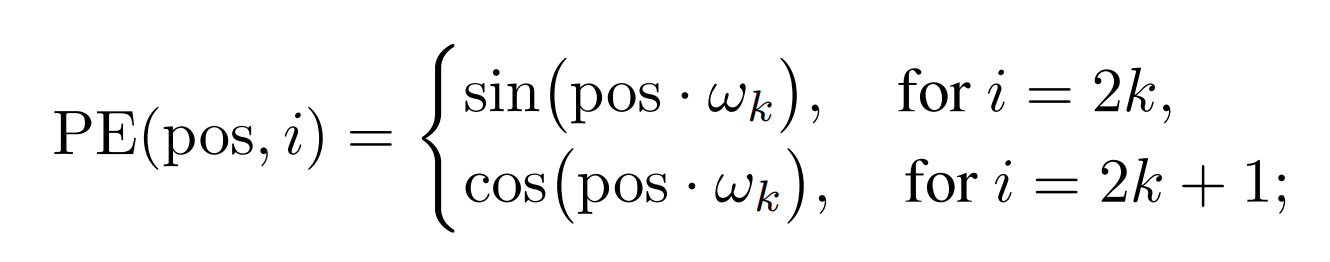
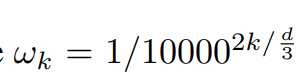
El vector de posición final en la dimensión H se expresa como sigue
PE ( pos ) H = [ sin ( w 1 . t ) cos ( w 1 . t ) sin ( w 2 . t ) cos ( w 2 . t ) sin ( wd / 6 . t ) cos ( wd / 6 . t ) ] d / 3 PE(pos)_H = \left[ \begin{matriz} sin(w_1 .t)\\ cos(w_1 .t)\\ sin(w_2 .t) \\ cos(w_2 .t)\\ \\ \\ sin(w_{d/6}.t)\\ cos(w_{d/6}.t)\\ \\end{matriz} \ derecha] _ {d/3}P E ( p o s )H=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡pecado _ _ _ _1. t )c o s ( w1. t )pecado _ _ _ _2. t )c o s ( w2. t )pecado _ _ _ _d / 6. t )c o s ( wd / 6. t )⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤d / 3
Luego ingrese el código de posición (d * H * W * T) en el codificador junto con las características extraídas por la red troncal
decodificador de transformador
Decodificar la secuencia de características de píxeles densos generados por el codificador en una secuencia de características de instancia dispersa
Para ser visto: Inspirado en DETR, suponiendo que cada marco tiene n instancias, cada marco tiene un número fijo de incrustaciones de entrada que se utilizan para extraer las características de la instancia, consulta de instancia nombrada, luego la consulta de instancia del marco T tiene N = n* t. se puede aprender y tiene las mismas dimensiones que las características de píxeles
consulta de instancia: se utiliza para realizar operaciones de atención con secuencias de características de entrada densas y seleccionar características que pueden representar cada instancia
Entrada: E + consulta de instancia
Salida: la secuencia de predicción O de cada instancia, el proceso posterior considera la secuencia de predicción de todos los cuadros de una sola instancia como un todo, y los genera en el orden de la secuencia de cuadros de video original, que es n * T vectores de instancia
coincidencia de secuencia de instancia
La salida del decodificador es n * T secuencias de predicción, en el orden de los cuadros, pero el orden de n instancias en cada cuadro es incierto
La función de este módulo es mantener la posición relativa sin cambios para la predicción de la misma instancia en diferentes marcos.
Haga coincidir binariamente la secuencia predicha de cada instancia con la secuencia GT de cada instancia en los datos etiquetados y use el método de coincidencia húngaro para encontrar los datos etiquetados más cercanos para cada predicción
Suplemento FFN: De hecho, es el perceptrón multicapa MLP, que es FC+GeLU+FC
En Transformer, a MSA le sigue una FFN (red de avance), que contiene dos capas de FC, la primera FC transforma características de la dimensión D a 4D, la segunda FC restaura características de la dimensión 4D a D y la del medio no lineal. todas las funciones de activación usan GeLU (Unidad lineal de error gaussiano, Unidad lineal de error gaussiano): esto es esencialmente un MLP (el perceptrón multicapa es similar al modelo lineal, la diferencia es que MLP aumenta el número de capas en relación con FC e introduce no -funciones de activación lineal, como FC + GeLU + FC)
Principalmente para mantener la posición relativa de la predicción de la misma instancia en diferentes imágenes
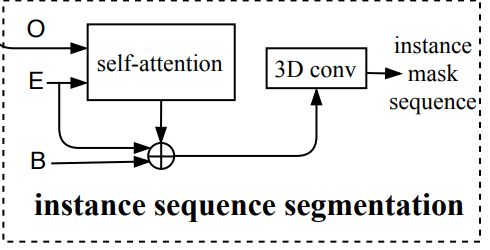
Segmentación de secuencias de instancias
Tarea: Calcular la máscara de cada instancia en el marco correspondiente
O es la salida del decodificador, E es la salida del codificador y B es la función extraída por CNN
La esencia de la segmentación de instancias es el aprendizaje de la similitud de píxeles. Para cada cuadro , primero envíe la imagen de predicción O y la función de codificación E a la autoatención, calcule la similitud y use el resultado como máscara inicial del cuadro de la instancia. , y luego compárelo con el marco. La característica principal inicial y la característica de codificación E se fusionan para obtener la característica de máscara final de la instancia del marco. Con el fin de hacer un mejor uso de la información de tiempo, el concatenamiento de máscara de múltiples cuadros de esta instancia genera una secuencia de máscara, que se envía al módulo de convolución 3D para su segmentación.
Este método fortalece la segmentación de un solo marco al usar las características de la misma instancia de varios marcos para aprovechar la sincronización.
Motivo: cuando el objeto está en estado de desafío, como desenfoque de movimiento, cubierta, etc., puede ayudar a la segmentación al aprender información de otros marcos, es decir, las características de la misma instancia de múltiples marcos pueden ayudar a la red a mejorar. identificar el objeto ejemplo
Suponiendo que la característica de máscara g(i, t) de la instancia i en el cuadro t: 1 * a * H'/4 * W'/4, donde a es el número de canal, concatene las características del cuadro T para obtener la instancia en todos máscara en cuadro 1*a*T*H'/4*W'/4
4 aquí es porque hay 4 instancias en el ejemplo
experimento de ablación
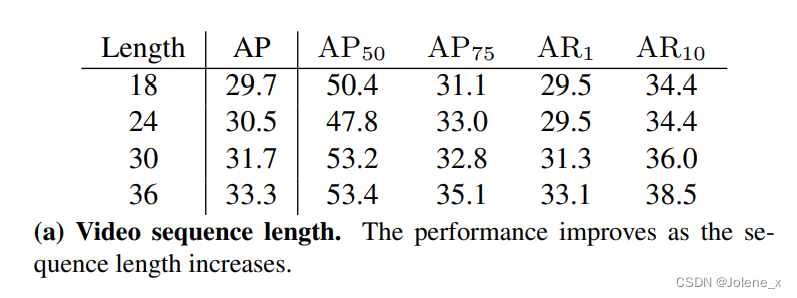
duración de la secuencia de vídeo
De 18 a 36, el efecto mejora y más información sobre el tiempo puede ayudar a mejorar los resultados.
orden de las secuencias de video

código de localización
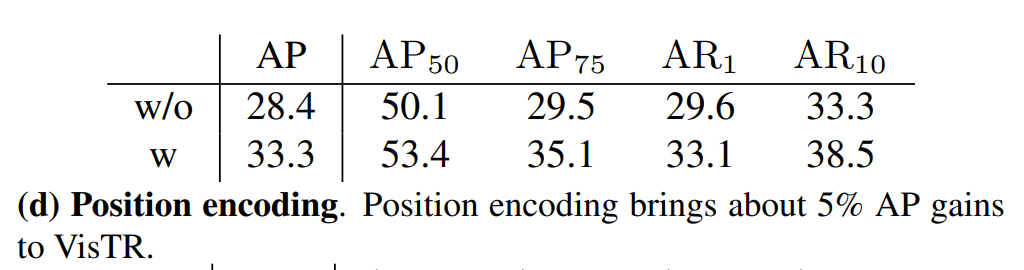
posición relativa en la secuencia de vídeo
El efecto de la primera línea sin codificación de posición es que la correspondencia entre el formato ordenado de la supervisión de secuencia y el orden de entrada y salida del transformador implica parte de la información de posición relativa
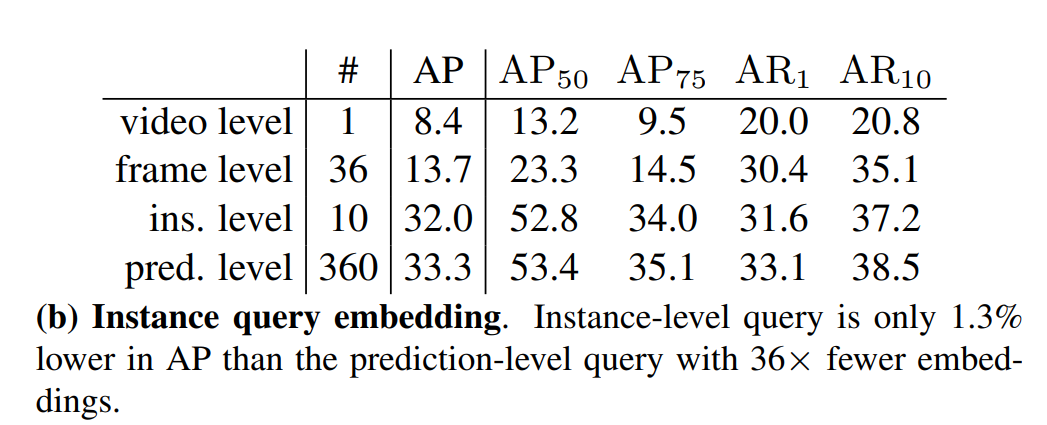
Incrustaciones de consultas de instancias aprendibles
Nivel de predicción predeterminado: una incrustación es responsable de una predicción, un total de n * T
nivel de video: solo una incrustación, reutilizada n * T veces
nivel de cuadro: para cada cuadro, use una incrustación, es decir, T incrustaciones, y para cada incrustación, repita n veces
nivel de instancia: para cada instancia, use una incrustación, es decir, n incrustaciones, repetidas T veces
Las consultas de una instancia se pueden compartir , lo que se puede usar para mejorar la velocidad
Resultados experimentales
Conjunto de datos: YouTube-VIS
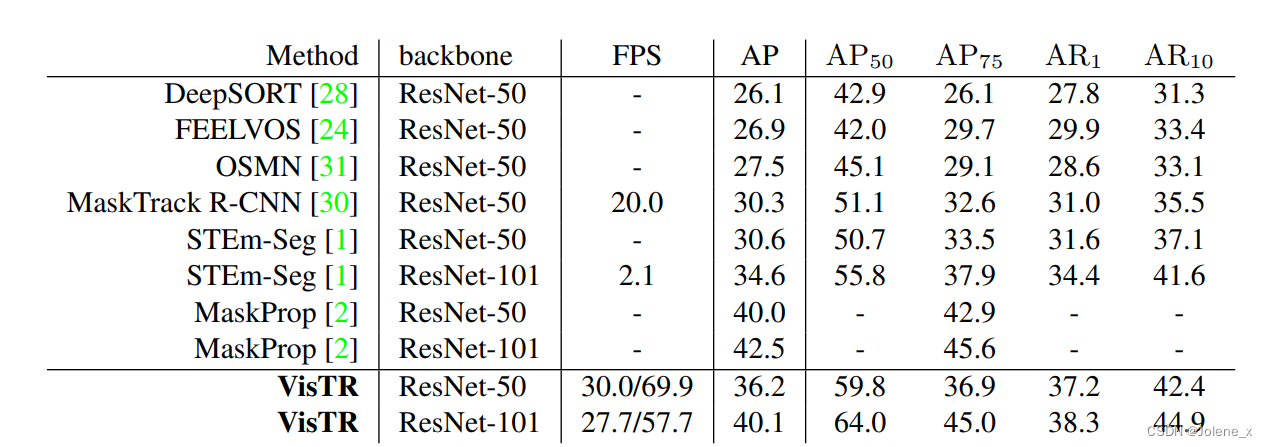
Gran velocidad gracias a: Decodificación en paralelo
Resultados de la visualización: (a) instancias superpuestas, (b) cambios en posiciones relativas entre instancias, © confusión cuando las instancias de la misma categoría están juntas, (d) instancias en varias poses.
