prefacio
yolov5 actualizó v6.2 y agregó un modelo de clasificación, así que quería probar el rendimiento de clasificación de yolov5 por capricho. Esta vez, usé el modelo yolov5s-cls y entrené solo cinco veces para ver cuánta precisión se puede lograr en el conjunto de datos clásico mnist. Al mismo tiempo, en aras de la justicia, solo use instrucciones oficiales para el entrenamiento y envíe la precisión de la prueba en kaggle.
Preparación del conjunto de datos
Si necesita descargar, ingrese el enlace
usted mismo . Aquí solo descargamos test.csv y sample_submission.csv directamente.
Cree un nuevo script py en el mismo directorio e ingrese el siguiente contenido para convertir cada pieza de datos en una imagen de 28x28.
#oom.py
import pandas as pd
import imageio
df = pd.read_csv('test.csv')
for index,row in df.iterrows():
print(index) #打印序号方便看进度
pixels = row.values.reshape((28, 28))
imageio.imwrite('E:/image/'+str(index) + '.png', pixels)
Modifique el directorio de guardado usted mismo. Aquí estoy en la carpeta de imágenes del disco E, y luego ejecútelo directamente con la línea de comando . Si la memoria de la computadora no es suficiente para ejecutarse bajo un ide como vs, puede desbordarse.
Abra el directorio, puede encontrar que se ha convertido en una imagen.
entrenamiento yolov5
Enlace
Primero, debe descargar el último código fuente de yolov5, y luego ir a la página de lanzamiento.Puede ver que hay muchos modelos: aquí, si la tarjeta gráfica de su computadora es basura, refiriéndose a una tarjeta gráfica antigua sin memoria 8g, se recomienda elegir el modelo más pequeño yolov5n-cls, porque mi tarjeta gráfica con memoria de video 8g ejecuta yolov5s-cls y necesita configurar num_workers en 6 para funcionar
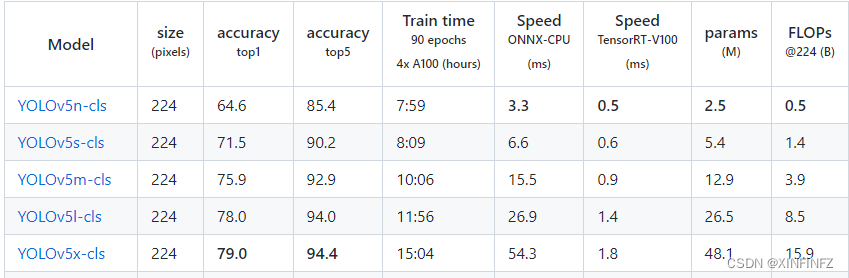
normalmente .
Coloque el modelo en el directorio del código fuente, luego inicie la línea de comando en el directorio actual e ingrese la siguiente capacitación:
python classify/train.py --model yolov5s-cls.pt --data mnist --epochs 5 --img 224 --batch 128
Luego, la nueva versión parece obligarlo a usar el software de la página web de wandb para registrar el proceso de capacitación. Se recomienda registrar uno con anticipación y luego ingresar la clave api que le entregó wandb para activarla durante la capacitación (no puedo pegarla aquí, solo puedo escribirla a mano)
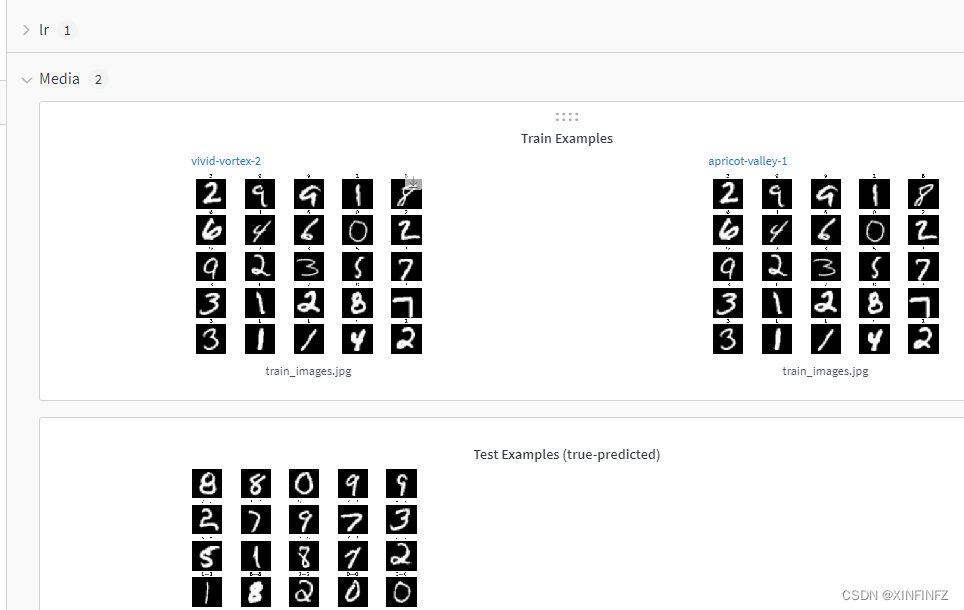
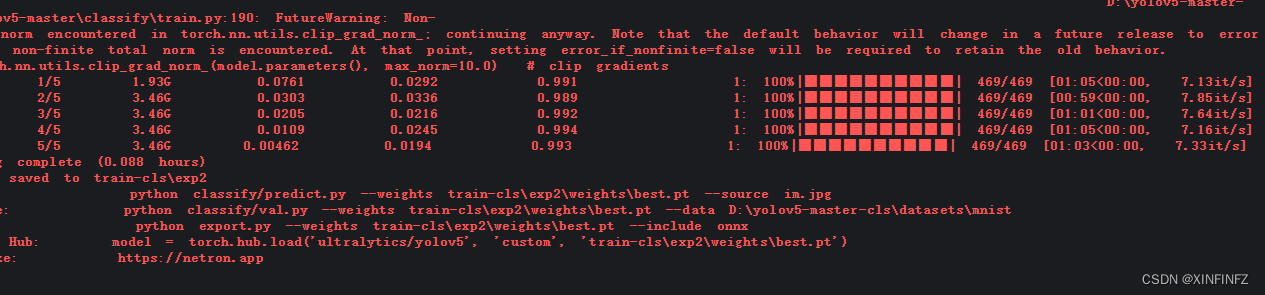
.
Se puede ver que la tasa de precisión del entrenamiento cuatro veces ha llegado a 0,994, y el siguiente paso es predecir y guardar la salida.
Pronóstico Yolov5
Primero vaya al directorio de entrenamiento y saque el mejor modelo (best.pt) y colóquelo en el directorio raíz:
luego coloque la carpeta de imágenes del conjunto de datos previamente preparada en el directorio raíz: coloque
sample_submission.csv en la carpeta classify para facilitar la lectura:
modifique predict.py de la siguiente manera Para verlo más claramente, usé vs para comparar el py original y el modificado (el de la izquierda es el modificado): primero agregue una referencia
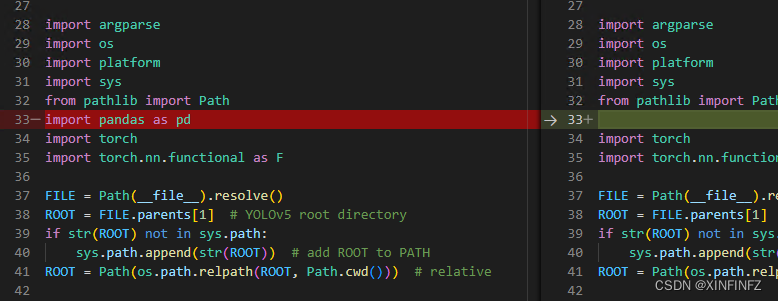
.
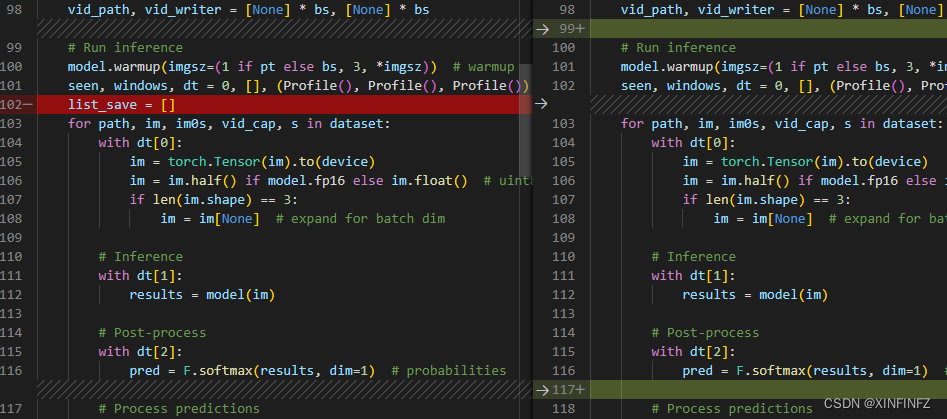
Cree un nuevo list_save para guardar los resultados previstos.
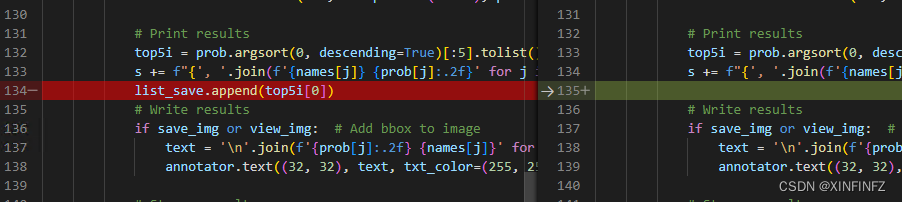
Coloque top5i[0] (su salida oficial es mostrar las cinco categorías principales con la mayor probabilidad, aquí solo tomamos la primera) en list_save.

Lea la etiqueta Label en el archivo sample_submission.csv y sobrescriba el resultado. Cabe señalar aquí que cuando yolov5 lee la ruta del archivo para ordenar, hay cadenas delante de él, es decir, no se ordenará de acuerdo con el orden numérico normal, pero se ordena uno por uno, como 1, 10, 100, por lo que el orden es desordenado y debe procesarse más tarde.
Predigamos primero, ingrese el siguiente comando en la línea de comando y finalmente obtenga el archivo sub.csv.
python classify/predict.py --weights best.pt --source image/ --nosave
–pesos especifica el peso, –la fuente va seguida directamente de una carpeta, debajo están todas las imágenes, –nosave significa no guardar imágenes.
Luego sacamos el archivo sub.csv generado en la carpeta classify y continuamos leyendo y procesando. La idea general es simular la clasificación con str al frente, y luego usar expresiones regulares para sacar los números para cubrir la columna del número de serie en sub.csv, y luego ordenar todo y obtener el resultado correcto:
import re
import pandas as pd
unorder_df = pd.read_csv('sub.csv')
list_a=[]
for i in range(0,28000):
list_a.append('image'+str(i)+'.png')
list_b = sorted(list_a) #模拟yolov5文件路径排序
list_c = []
for i in list_b:
x = re.findall("\d+", i) #只匹配数字
x = int(x[0]) #从str转换为数字
list_c.append(x + 1) #加一是因为序号是从1开始的
unorder_df['ImageId']=list_c
df = unorder_df.sort_values(by=['ImageId']) #根据序号列排序
df.to_csv('sub2.csv',index=None)
subir resultado
Regrese a kaggle y haga clic en enviar predicciones para enviar sub2.csv:


puede ver que la tasa de precisión es muy alta. Por supuesto, este experimento aún no es riguroso, es decir, el conjunto de entrenamiento proporcionado por kaggle no se usa para el entrenamiento, y se usa el conjunto de entrenamiento descargado automáticamente por yolov5. Tal vez el conjunto de entrenamiento y el conjunto de prueba se superponen.