Tabla de contenido
1.1 Introducción a las Redes Neuronales Convolucionales
1.3 Redes Neuronales Convolucionales
1.3.1 El concepto de convolución
1.3.2 Proceso de cálculo de convolución
1.3.5 Cálculo del tamaño de la característica de salida
1.4 Todo el proceso de la red neuronal convolucional
1.5 Reconocimiento de dígitos escritos a mano por la red neuronal convolucional (cnn) de PyTorch
1.1 Introducción a las Redes Neuronales Convolucionales
Las redes neuronales convolucionales (CNN para abreviar) son una estructura de red neuronal muy importante en el aprendizaje profundo. Se utiliza principalmente en el procesamiento de imágenes, procesamiento de video, procesamiento de audio y procesamiento de lenguaje natural.
Ya alrededor de la década de 1980, se propuso el concepto de redes neuronales convolucionales. Pero su verdadero auge es después del siglo 21. Después del siglo 21, con la mejora continua de la teoría del aprendizaje profundo, al mismo tiempo, la mejora del rendimiento del hardware de la computadora y el desarrollo continuo de la potencia informática proporcionan algoritmos de redes neuronales convolucionales. espacio. La mayoría de los famosos AlphaGo y reconocimiento facial en teléfonos móviles utilizan redes neuronales convolucionales. Por lo tanto, se puede decir que las redes neuronales convolucionales juegan un papel fundamental en el campo del aprendizaje profundo actual.
Antes de entender la red neuronal convolucional, debemos saber: qué es una red neuronal (Neural Networks), sobre esto ya lo hemos introducido en la segunda parte de la introducción al aprendizaje profundo. No entraré en detalles aquí. Sobre la base de la comprensión de la red neuronal, exploremos nuevamente: ¿qué es la red neuronal convolucional? ¿Qué significa la palabra "convolución"?
1.2 Red neuronal
1.2.1 Modelo de neuronas
La investigación sobre redes neuronales artificiales (redes neuronales) ha aparecido muy temprano. Hoy en día, "red neuronal" es un campo bastante amplio e interdisciplinario. Varias disciplinas relacionadas tienen varias definiciones de redes neuronales. Una extensa red paralela interconectada compuesta por unidades simples cuya organización puede simular la respuesta interactiva del sistema nervioso biológico a objetos del mundo real". El componente más básico de una
red neuronal es el modelo de neuronas, que es el modelo de neuronas en la definición anterior. "Unidad simple", en la red neuronal biológica, cada neurona está conectada a otras neuronas, cuando está "excitada", enviará sustancias químicas a las neuronas conectadas, cambiando así el potencial en estas neuronas; si un cierto El potencial de una neurona supera un "umbral" (umbral), entonces se activará, es decir, se "excitará", enviando sustancias químicas a otras neuronas. En este modelo, una neurona recibe señales de otras n neuronas. Las señales de entrada transmitidas se transmiten a través de conexiones, y el valor de entrada total recibido por la neurona se comparará con el inter-valor de la neurona, y luego será procesado por la función de activación para generar la salida de la neurona.
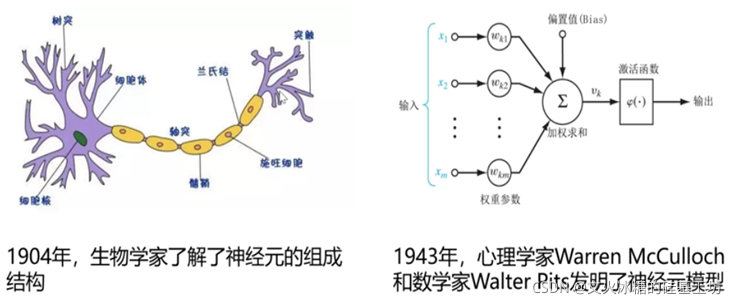
1.2.2 Modelo de red neuronal
Una red neuronal es un modelo operativo que consiste en una gran cantidad de nodos (o neuronas) conectados entre sí. Cada nodo representa una función de salida específica llamada función de activación. Cada conexión entre dos nodos representa un valor ponderado para la señal que pasa por la conexión, llamado peso, que es equivalente a la memoria de la red neuronal artificial. La salida de la red varía según la forma en que se conecta la red, el valor del peso y la función de activación. La red en sí suele ser una aproximación a un cierto algoritmo o función en la naturaleza, o puede ser una expresión de una estrategia lógica.

1.3 Redes Neuronales Convolucionales
1.3.1 El concepto de convolución
La diferencia entre la red neuronal convolucional y la red neuronal ordinaria es que la red neuronal convolucional contiene un extractor de características compuesto por una capa convolucional y una capa de submuestreo (capa de agrupación) . En una capa convolucional de una red neuronal convolucional, una neurona solo está conectada a algunas neuronas en capas vecinas. En una capa convolucional de CNN, por lo general contiene varios mapas de características (featureMap), cada mapa de características está compuesto por algunas neuronas dispuestas en un rectángulo, y las neuronas del mismo mapa de características comparten pesos, y los pesos compartidos aquí son volúmenes . . El kernel de convolución generalmente se inicializa en forma de una matriz decimal aleatoria, y el kernel de convolución aprenderá a obtener pesos razonables durante el proceso de entrenamiento de la red. El beneficio directo de compartir pesos (núcleos de convolución) es reducir las conexiones entre las capas de la red y al mismo tiempo reducir el riesgo de sobreajuste. El submuestreo también se denomina agrupación y, por lo general, tiene dos formas : agrupación media y agrupación máxima . El submuestreo puede verse como un tipo especial de proceso de convolución. La convolución y el submuestreo simplifican enormemente la complejidad del modelo y reducen los parámetros del modelo.
1.3.2 Proceso de cálculo de convolución
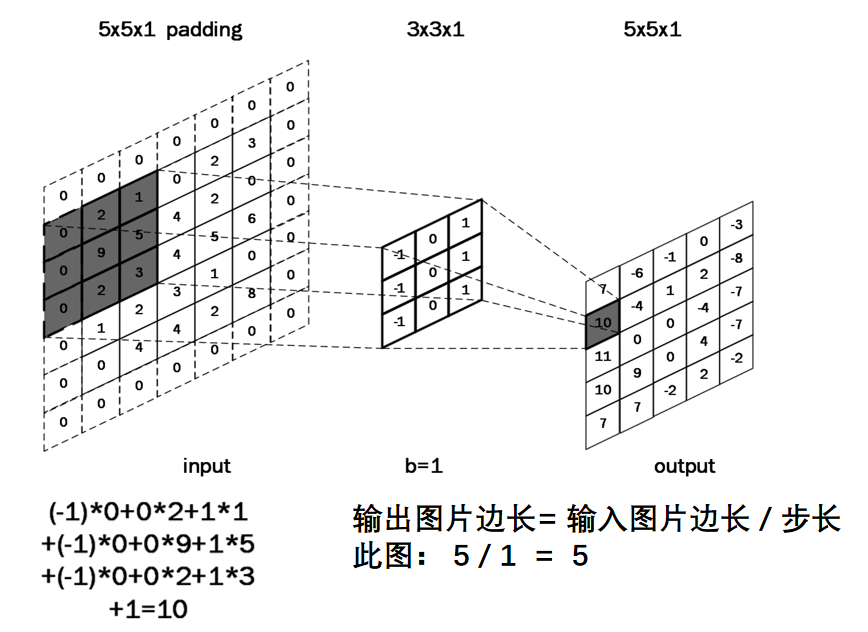
Supongamos que ingresamos una imagen de 5*5*1, y el 3*3*1 en el medio es un núcleo de convolución que definimos (en términos simples, puede considerarse como un operador de matriz), a través de la imagen de entrada original y la convolución. El resultado de la parte verde se puede obtener mediante la operación central ¿Qué tipo de operación? En realidad es muy simple. Miramos la parte oscura en la imagen de la izquierda. El número en el medio es el píxel de la imagen, y el número en la esquina inferior derecha es el número de nuestro kernel de convolución. Simplemente multiplique y agregue el números correspondientes para obtener el resultado. Por ejemplo, '3*0+1*1+2*2+2*2+0*2+0*0+2*0+0*1+0*2=9' en la imagen
El proceso de cálculo es el siguiente:
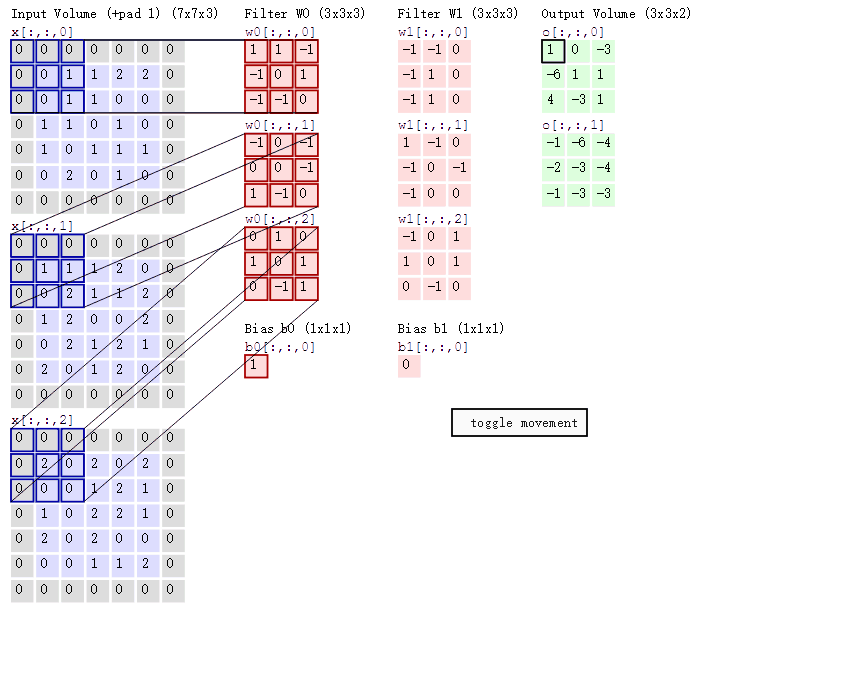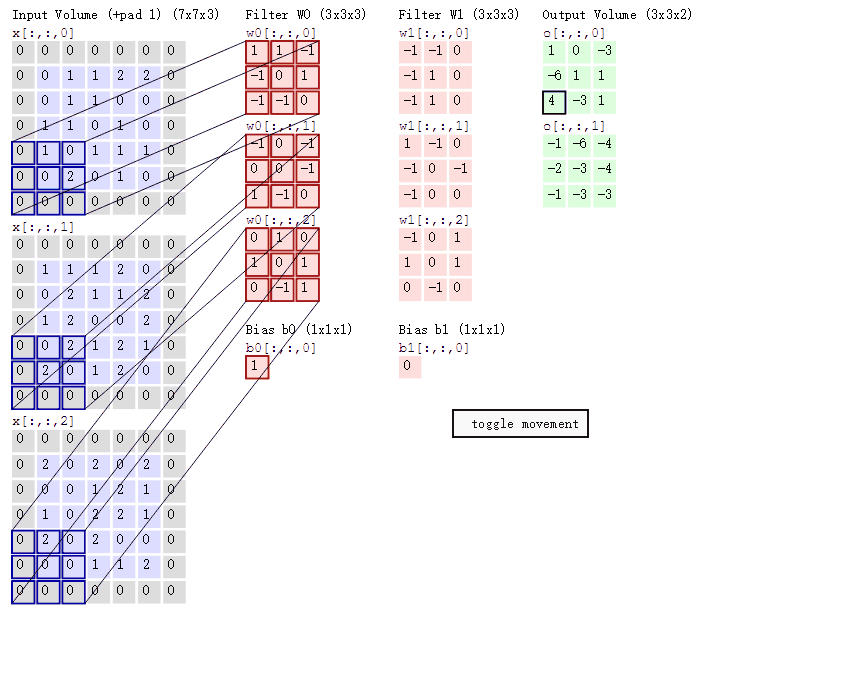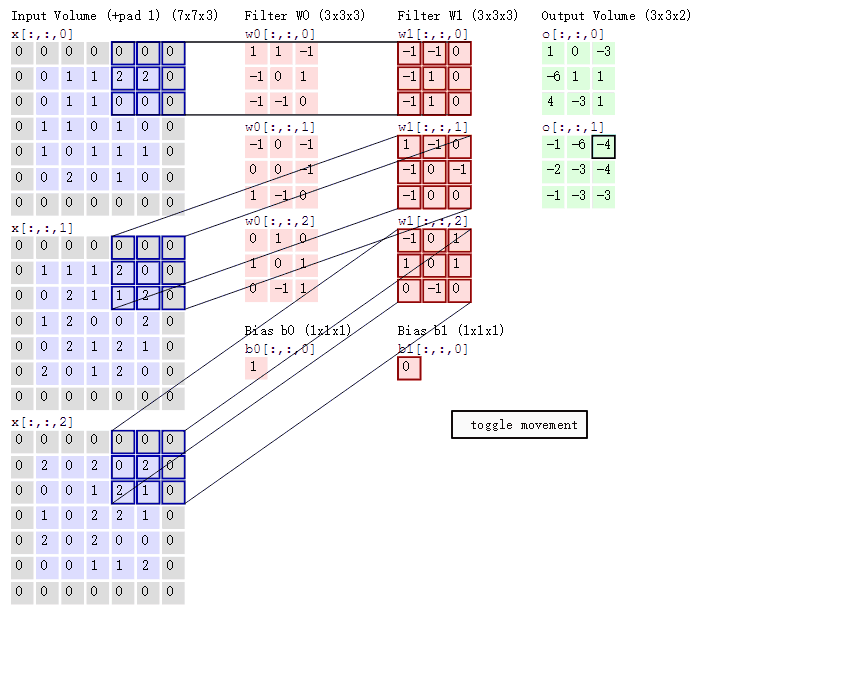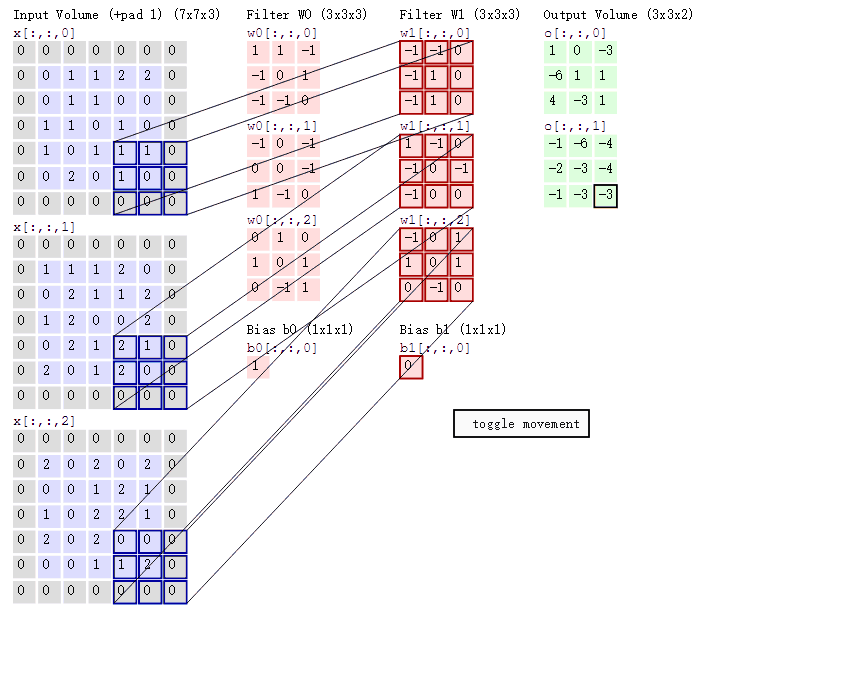
Las tres matrices de entrada en el extremo izquierdo de la figura son nuestra entrada equivalente d=3 cuando hay tres mapas de canales. Cada mapa de canales tiene un núcleo de convolución que pertenece a su propio canal. Podemos ver que solo hay dos salidas (salida) Un mapa de características significa que configuramos la salida d=2, y hay varias capas de núcleos de convolución con varios canales de salida (por ejemplo, hay FilterW0 y FilterW1 en la figura), lo que significa que el número de nuestros núcleos de convolución es el número de entrada d El número multiplicado por el número de salida d (en la figura es 2*3=6), donde el cálculo de cada capa del mapa de canales es el mismo que el cálculo de la capa mencionada anteriormente, y luego agregue el salida de cada salida de canal Ese es el número de salida verde.
1.3.3 Campo receptivo
Campo Receptivo : El tamaño del área de mapeo de cada píxel de cada capa de salida de la red neuronal convolucional sobre la imagen original.
La siguiente figura es un diagrama esquemático del campo receptivo:
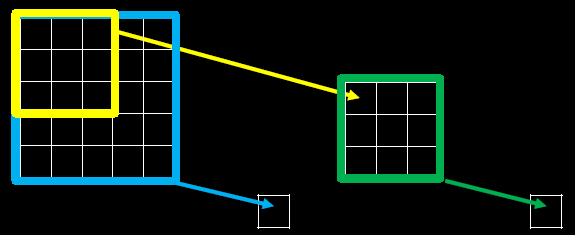
Cuando usamos núcleos de convolución con diferentes tamaños, la mayor diferencia es que el tamaño del campo receptivo es diferente, por lo que a menudo usamos varias capas de núcleos de convolución pequeños para reemplazar una capa de núcleos de convolución grandes y reducir los parámetros manteniendo los campos receptivos. el mismo volumen y cómputo.
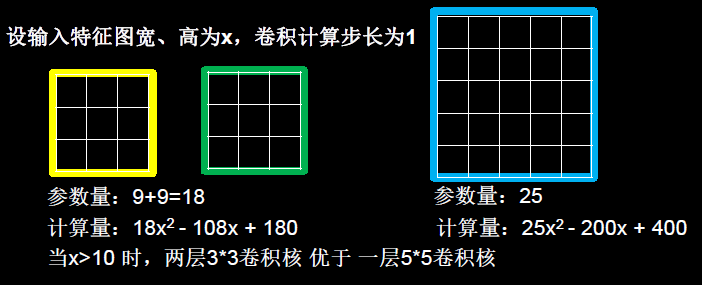
Por ejemplo, es muy común usar 2 capas de núcleos de convolución de 3*3 para reemplazar 1 capa de núcleos de convolución de 5*5, como se muestra en la siguiente figura.
1.3.4 Tamaño de paso
El tamaño de cada movimiento del kernel de convolución.
1.3.5 Cálculo del tamaño de la característica de salida
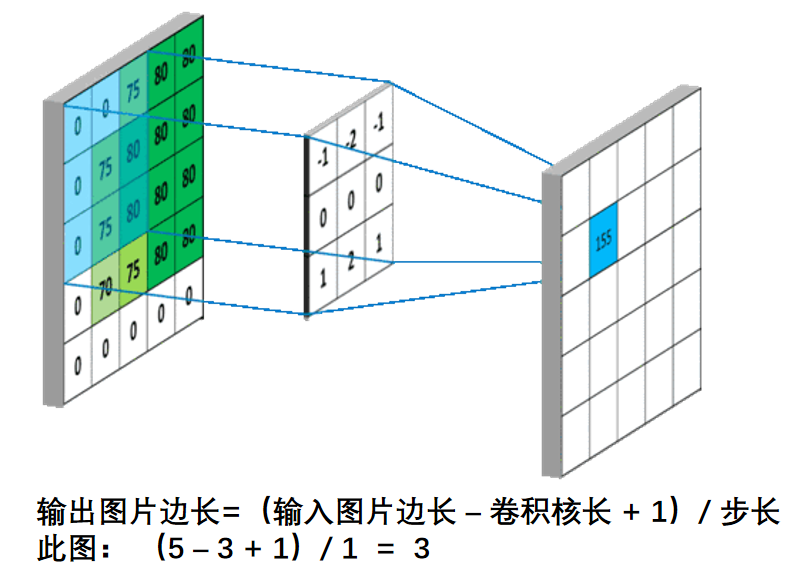
Cálculo del tamaño de la característica de salida : después de comprender todo el proceso de cálculo de convolución en la red neuronal , se puede calcular el tamaño del mapa de características de salida. Como se muestra en la siguiente figura, el tamaño de la característica de salida de una imagen de 5×5 es 3×3 después del cálculo de convolución con un kernel de convolución de tamaño 3×3.
1.3.6 Relleno con ceros
Cuando el tamaño del kernel de convolución es mayor que 1, el tamaño del mapa de características de salida será más pequeño que el tamaño de la imagen de entrada. Después de varias circunvoluciones, el tamaño de la imagen de salida seguirá disminuyendo. Para evitar que el tamaño de la imagen se reduzca después de la convolución, el relleno generalmente se realiza en la periferia de la imagen, como se muestra en la figura a continuación.
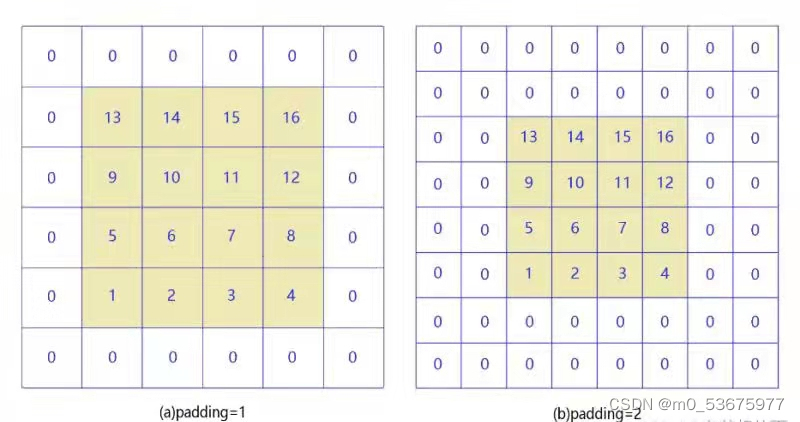
Relleno con todos los ceros (relleno): para mantener el tamaño de la imagen de salida consistente con la imagen de entrada, a menudo se realiza un relleno con todos los ceros alrededor de la imagen de entrada, como se muestra a continuación, si se llena con 0 alrededor de la imagen de entrada de 5 × 5, la salida el tamaño de la función también es de 5 × 5.
Cuando padding=1 y paadding=2, como se muestra en la siguiente figura:
1.3.7 Estandarización
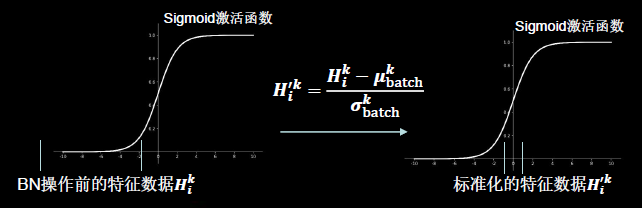
Ajuste los datos a una distribución con una media de 0 y una desviación estándar de 1.
Normalización por lotes : estandarice un pequeño lote de datos (lote).

Batch Normalization ajusta la entrada de cada capa de la red neuronal a una distribución normal estándar con una media de 0 y una varianza de 1. Su propósito es resolver el problema de la desaparición de gradientes en la red neuronal .
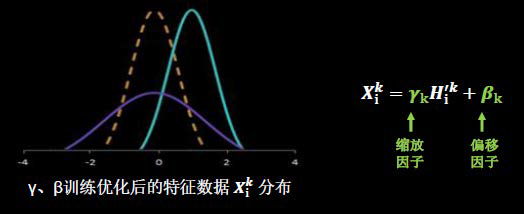
Otro paso importante en la operación de BN es el escalado y el desplazamiento. Vale la pena señalar que tanto el factor de escala γ como el factor de desplazamiento β son parámetros entrenables.
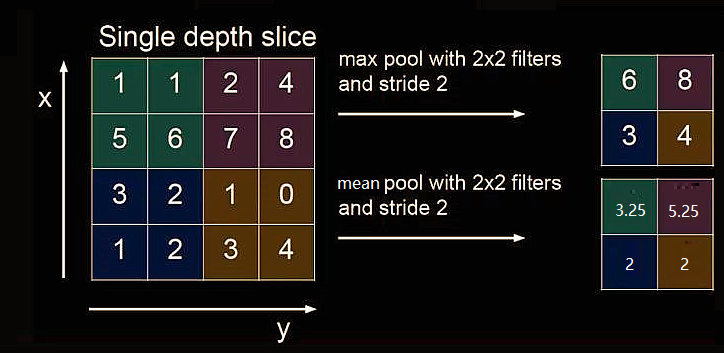
1.3.7 Capa de agrupación
La agrupación se utiliza para reducir la cantidad de datos de características.
La agrupación máxima puede extraer la textura de la imagen, la agrupación media puede conservar las características de fondo
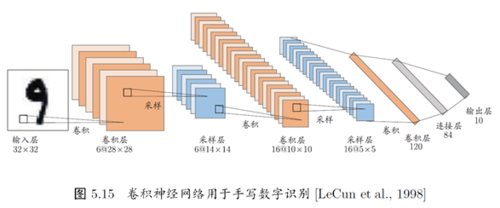
1.4 Todo el proceso de la red neuronal convolucional
1.5 Reconocimiento de dígitos escritos a mano por la red neuronal convolucional (cnn) de PyTorch
El framework utilizado es pytorch.
Conjunto de datos: conjunto de datos MNIST , 60 000 imágenes de entrenamiento, cada tamaño de imagen es 28*28.
Disponible en http://yann.lecun.com/exdb/mnist/
1.5.1 Código
import torch
import torch.nn as nn
import torchvision.datasets as dataset
import torchvision.transforms as transforms
import torch.utils.data as data_utils
#获取数据集
train_data=dataset.MNIST(root="D",
train=True,
transform=transforms.ToTensor(),
download=True
)
test_data=dataset.MNIST(root="D",
train=False,
transform=transforms.ToTensor(),
download=False
)
train_loader=data_utils.DataLoader(dataset=train_data, batch_size=100, shuffle=True)
test_loader=data_utils.DataLoader(dataset=test_data, batch_size=100, shuffle=True)
#创建网络
class Net(torch.nn.Module):
def __init__(self):
super().__init__()
self.conv=nn.Conv2d(1, 32, kernel_size=5, padding=2)
self.bat2d=nn.BatchNorm2d(32)
self.relu=nn.ReLU()
self.pool=nn.MaxPool2d(2)
self.linear=nn.Linear(14 * 14 * 32, 70)
self.tanh=nn.Tanh()
self.linear1=nn.Linear(70,30)
self.linear2=nn.Linear(30, 10)
def forward(self,x):
y=self.conv(x)
y=self.bat2d(y)
y=self.relu(y)
y=self.pool(y)
y=y.view(y.size()[0],-1)
y=self.linear(y)
y=self.tanh(y)
y=self.linear1(y)
y=self.tanh(y)
y=self.linear2(y)
return y
cnn=Net()
cnn=cnn.cuda()
#损失函数
los=torch.nn.CrossEntropyLoss()
#优化函数
optime=torch.optim.Adam(cnn.parameters(), lr=0.01)
#训练模型
for epo in range(10):
for i, (images,lab) in enumerate(train_loader):
images=images.cuda()
lab=lab.cuda()
out = cnn(images)
loss=los(out,lab)
optime.zero_grad()
loss.backward()
optime.step()
print("epo:{},i:{},loss:{}".format(epo+1,i,loss))
#测试模型
loss_test=0
accuracy=0
with torch.no_grad():
for j, (images_test,lab_test) in enumerate(test_loader):
images_test = images_test.cuda()
lab_test=lab_test.cuda()
out1 = cnn(images_test)
loss_test+=los(out1,lab_test)
loss_test=loss_test/(len(test_data)//100)
_,p=out1.max(1)
accuracy += (p==lab_test).sum().item()
accuracy=accuracy/len(test_data)
print("loss_test:{},accuracy:{}".format(loss_test,accuracy))