Pregunta de ingreso a la competencia de Kaggle · Use CNN para el reconocimiento de números escritos a mano, la tasa de precisión es 0.98260
Enlace de entrada de Digit Recognizer: https://www.kaggle.com/c/digit-recognizer
Conjunto de datos:
Enlace: https://pan.baidu.com/s/13f3rM_lhNGyu2Rsqbc1AUw
Código de extracción: otoy
copie este contenido y abra Baidu.com Es más conveniente operar en la aplicación de teléfono móvil,

train.csv y test.csv son datos de conjunto de entrenamiento y conjunto de prueba respectivamente.
Sample_submission es el formato de envío oficial
predict.csv es el resultado de la predicción de esta publicación de blog sobre el conjunto de prueba, con una tasa de precisión de 0,98260
1. Carga y preprocesamiento de datos
Leer los archivos csv en el conjunto de entrenamiento y el conjunto de prueba
train_file = pd.read_csv(os.path.join(main_path, "train.csv"))
test_file = pd.read_csv(os.path.join(main_path, "test.csv"))
Dado que el rango de la matriz de texto en el conjunto de datos MNIST es (0-255), aquí realizaremos una estandarización de datos y normalizaremos (0-255) al rango (0-1).
ps: ¿Por qué estandarizar? Puede consultar este blog
# Normalization
train_file_norm = train_file.iloc[:, 1:] / 255.0
test_file_norm = test_file / 255.0
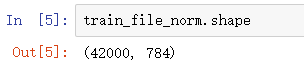
Ver la forma del conjunto de datos en este momento
train_file_norm.shape
También podemos usar matplotlib.pyplot para imprimir el conjunto de datos para visualizar la muestra.
rand_indices = np.random.choice(train_file_norm.shape[0], 64, replace=False)
examples = train_file_norm.iloc[rand_indices, :]
fig, ax_arr = plt.subplots(8, 8, figsize=(6, 5))
fig.subplots_adjust(wspace=.025, hspace=.025)
ax_arr = ax_arr.ravel()
for i, ax in enumerate(ax_arr):
ax.imshow(examples.iloc[i, :].values.reshape(28, 28), cmap="gray")
ax.axis("off")
plt.show()

Necesitamos procesar los datos en una forma de (42000, 32, 32, 3) para facilitar el entrenamiento
Definir parámetros de forma de muestra
num_examples_train = train_file.shape[0]
num_examples_test = test_file.shape[0]
n_h = 32
n_w = 32
n_c = 3
Inicializar el espacio muestral
Train_input_images = np.zeros((num_examples_train, n_h, n_w, n_c))
Test_input_images = np.zeros((num_examples_test, n_h, n_w, n_c))
Cargar datos en el espacio muestral
for example in range(num_examples_train):
Train_input_images[example,:28,:28,0] = train_file.iloc[example, 1:].values.reshape(28,28)
Train_input_images[example,:28,:28,1] = train_file.iloc[example, 1:].values.reshape(28,28)
Train_input_images[example,:28,:28,2] = train_file.iloc[example, 1:].values.reshape(28,28)
for example in range(num_examples_test):
Test_input_images[example,:28,:28,0] = test_file.iloc[example, :].values.reshape(28,28)
Test_input_images[example,:28,:28,1] = test_file.iloc[example, :].values.reshape(28,28)
Test_input_images[example,:28,:28,2] = test_file.iloc[example, :].values.reshape(28,28)
Utilice cv2.resize para hacer zoom
for example in range(num_examples_train):
Train_input_images[example] = cv2.resize(Train_input_images[example], (n_h, n_w))
for example in range(num_examples_test):
Test_input_images[example] = cv2.resize(Test_input_images[example], (n_h, n_w))
Extrae el valor de la etiqueta del conjunto de entrenamiento
Train_labels = np.array(train_file.iloc[:, 0])
Imprima la forma de datos de muestra preprocesados
print("Shape of train input images : ", Train_input_images.shape)
print("Shape of test input images : ", Test_input_images.shape)
print("Shape of train labels : ", Train_labels.shape)

En este punto, ¡nuestro proceso de procesamiento y preprocesamiento de datos ha terminado!
2. Modelo de entrenamiento y predicción de resultados
Antes de presentar el modelo, permítanme presentarles la codificación one-hot. La codificación
one-hot puede convertir datos clasificados en formato binario para el aprendizaje automático. La función de implementación es la siguiente
def one_hot(labels):
onehot_labels = np.zeros(shape=[len(labels), 10])
for i in range(len(labels)):
index = labels[i]
onehot_labels[i][index] = 1
return onehot_labels
Construya un modelo de red CNN
def mnist_cnn(input_shape):
'''
构建一个CNN网络模型
:param input_shape: 指定输入维度
:return:
'''
model = keras.Sequential()
model.add(keras.layers.Conv2D(filters=32, kernel_size=5, strides=(1, 1),
padding='same', activation=tf.nn.relu, input_shape=input_shape))
model.add(keras.layers.MaxPool2D(pool_size=(2, 2), strides=(2, 2), padding='valid'))
model.add(keras.layers.Conv2D(filters=64, kernel_size=3, strides=(1, 1), padding='same', activation=tf.nn.relu))
model.add(keras.layers.MaxPool2D(pool_size=(2, 2), strides=(2, 2), padding='valid'))
model.add(keras.layers.Dropout(0.25))
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(units=128, activation=tf.nn.relu))
model.add(keras.layers.Dropout(0.5))
model.add(keras.layers.Dense(units=10, activation=tf.nn.softmax))
return model
Entrena y guarda el modelo
def trian_model(train_images, train_labels):
# re-scale to 0~1.0之间
print("train_images :{}".format(train_images.shape))
print(train_labels)
train_labels = one_hot(train_labels)
# 建立模型
model = mnist_cnn(input_shape=(32, 32, 3))
model.compile(optimizer=tf.optimizers.Adam(), loss="categorical_crossentropy", metrics=['accuracy'])
model.fit(x=train_images, y=train_labels, epochs=5, batch_size = 256)
model.save('MYCNN2MNIST.h5')
Use el modelo entrenado para predecir la etiqueta del conjunto de prueba, save_path es la ruta donde guardamos el modelo
def pred(save_path,test_images):#载入模型并生成图片
model=keras.models.load_model(save_path)
# 开始预测
predictions = model.predict(test_images)
# print(predictions)
# print(type(predictions))
targetlist = []
targetlist.append(0)
for i in range(len(test_images)):
target = np.argmax(predictions[i])
targetlist.append(target)
print(targetlist)
predictions = pd.DataFrame(targetlist)
predictions.to_csv("predict.csv")
Escribe los resultados de nuestra predicción en un archivo
submission = pd.read_csv('DataSet/sample_submission.csv')
Luego envíe el archivo al servidor y podrá ver su precisión y clasificación.
Ps: Dado que el servidor de kaggle está en el extranjero, debe ** (saber todo)
Enlace de origen: https://pan.baidu.com/s/1HXt24GiUrRZliUXN-0N06g
Código de extracción: pza9
Si tiene alguna pregunta, deje un mensaje en el área de comentarios ~