Reconocimiento de dígitos escritos a mano
Requisitos de la tarea
Puede reconocer imágenes de dígitos escritos a mano del 0 al 9. Específicamente, la imagen en escala de grises de los dígitos escritos a mano (28 píxeles x 28 píxeles) se divide en 10 categorías (0-9). Es necesario utilizar el marco PaddlePaddle para implementar el modelo.
Conjunto de datos y entorno
- Fuente del conjunto de datos: MNIST , un conjunto de datos clásico en el campo ML , que contiene 60.000 imágenes de entrenamiento y 10.000 imágenes de prueba.
- Descripción de los datos: los datos se dividen en imágenes y etiquetas. La imagen es una matriz de 28 * 28 píxeles y la etiqueta tiene 10 números del 0 al 9
- Entorno operativo: PaddlePaddle2.0 + cuda11.1 + pycharm
Consejos: La nueva versión de PaddlePaddle2.0 se envía, la API de alto nivel recién agregada simplifica el proceso de construcción del modelo y es conveniente para una práctica práctica rápida.
Proceso de construcción de modelos
A continuación, realizamos principalmente experimentos en torno a este proceso, como se muestra en la figura:
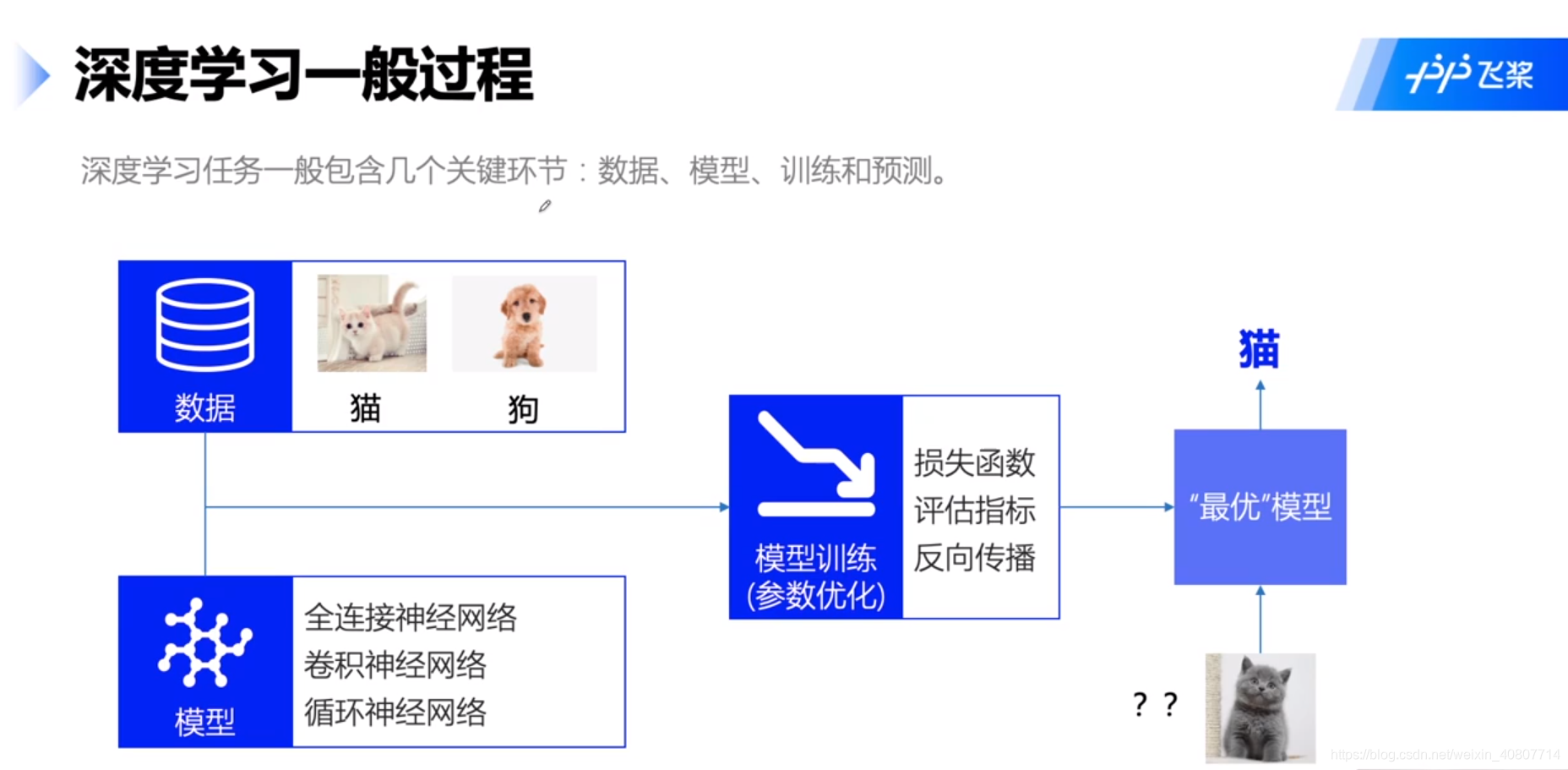
además, en el entrenamiento del modelo, realizamos principalmente las tareas que se muestran en la siguiente figura:
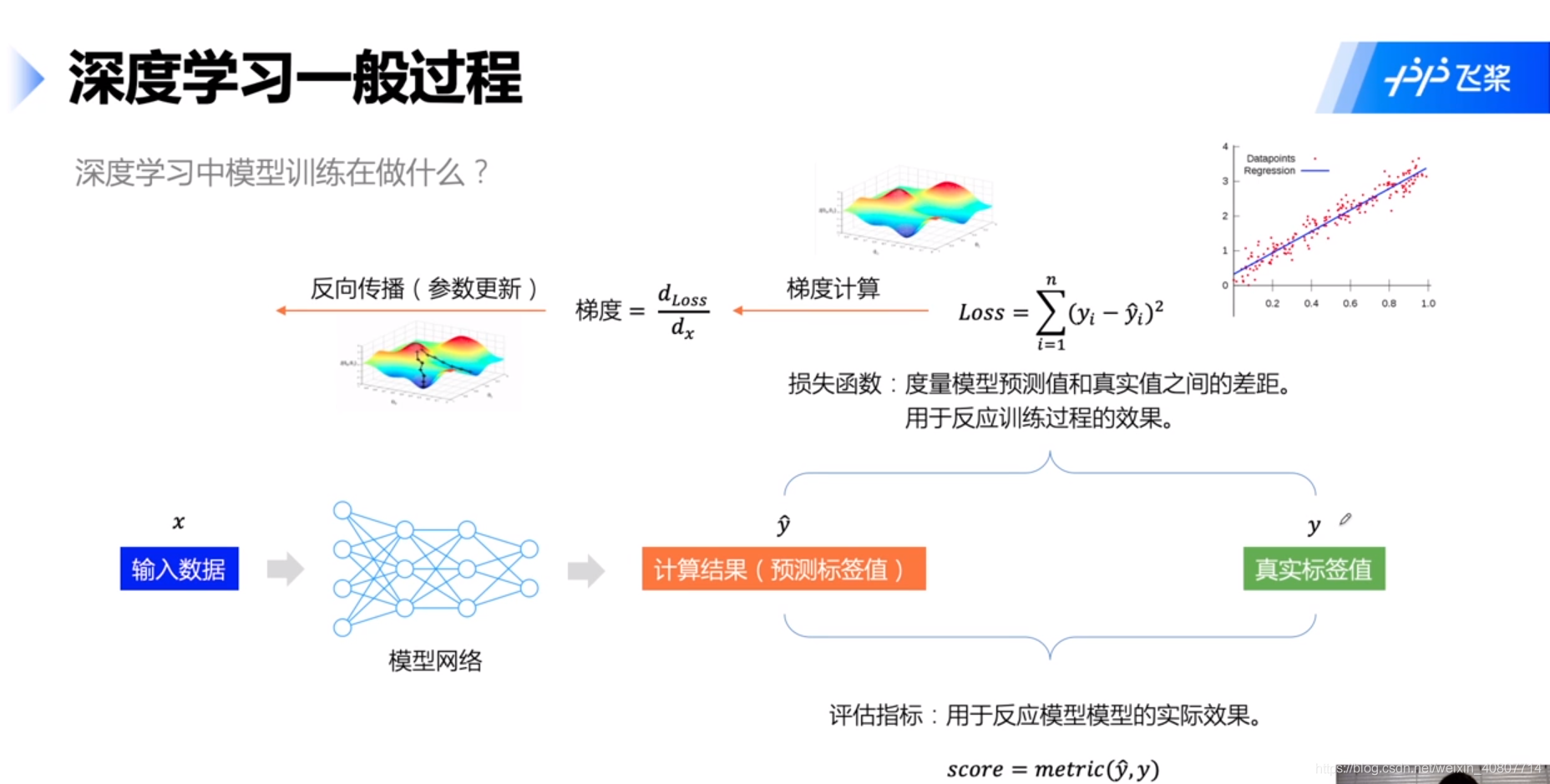
Consejos : El marco general del proceso aquí (por qué deberíamos seguir este proceso) puede referirse a la explicación de la regresión ( Pokémon) del maestro Li Hongyi , sobre la red neuronal BP (especialmente la retropropagación y la regla de derivación de la cadena). el libro de la sandía (resumen) y el libro de las flores (detallado). Además, la optimización del gradiente también puede referirse al método de aprendizaje estadístico de Li Hang y la parte decente del gradiente de Li Hongyi . Escribiré un resumen más adelante y no lo ampliaré aquí. Por favor perdóname ~
Preprocesamiento de datos
La paleta voladora tiene un conjunto de datos MNIST incorporado, simplemente llámelo. Defina el conjunto de entrenamiento train_datasety el conjunto de prueba del conjunto de datos test_dataset. Luego use la Normalizeinterfaz para normalizar la imagen.
import paddle
import numpy as np
import matplotlib.pyplot as plt
import paddle.vision.transforms as T
# 数据的加载和预处理
transform = T.Normalize(mean=[127.5], std=[127.5])
# 训练数据集
train_dataset = paddle.vision.datasets.MNIST(mode='train', transform=transform)
# 评估数据集
eval_dataset = paddle.vision.datasets.MNIST(mode='test', transform=transform)
print('训练集样本量: {},验证集样本量: {}'.format(len(train_dataset), len(eval_dataset)))
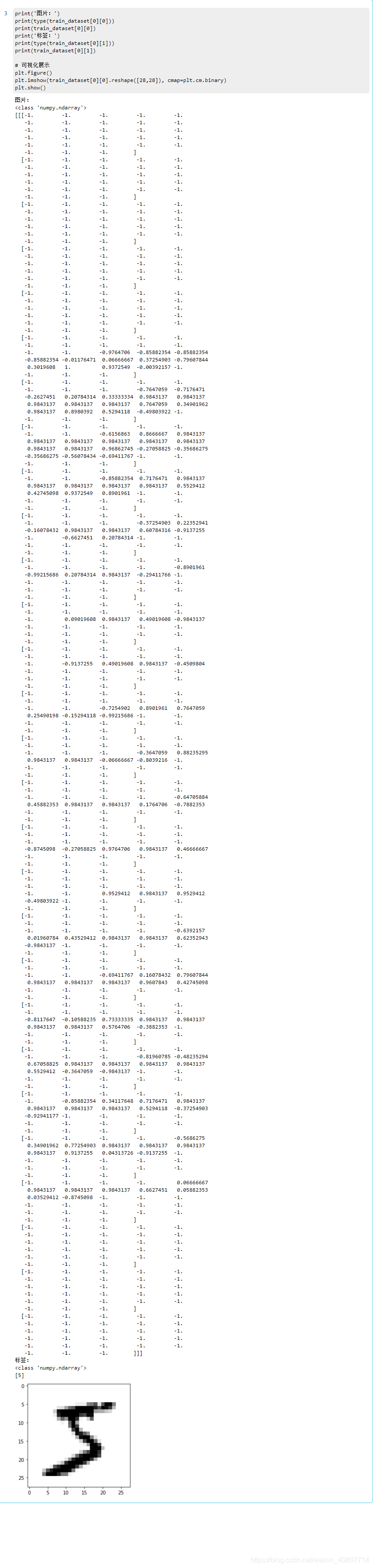
¿Por qué necesitamos normalizarnos? Aquí hay una imagen preprocesada para ilustración.
print('图片:')
print(type(train_dataset[0][0]))
print(train_dataset[0][0])
print('标签:')
print(type(train_dataset[0][1]))
print(train_dataset[0][1])
# 可视化展示
plt.figure()
plt.imshow(train_dataset[0][0].reshape([28,28]), cmap=plt.cm.binary)
plt.show()
Como se muestra en la figura, el rango del valor de la matriz de píxeles después de la normalización ya no es 0 ~ 255, sino que se comprime a -1 ~ 1. Evidentemente conviene realizar los cálculos más tarde. Para el método de normalización, usamos una media uniforme y una desviación estándar para calcular cada canal de la imagen.
Entonces, ¿prestar atención Normalizea lo que se puede hacer con la interfaz?
class paddle.vision.Normalize(mean=0.0, std=1.0, data_format='CHW', to_rgb=False, keys=None)
Acabamos de mencionar el método de procesamiento de la normalización de imágenes, y en esta interfaz, el proceso de cálculo es el siguiente:
salida [canal] = (entrada [canal] - media [canal]) / estándar [canal] salida [canal] = ( input [channel] -mean [channel]) / std [channel]o u t p u t [ c h a n n e l ]=( i n p u t [ c h a n n e l ]-m e a n [ c h a n n e l ] ) / s t d [ c h a n n e l ]
Definición de los parámetros relacionados utilizados esta vez:
- media: la media normalizada para cada canal
- std: la desviación estándar utilizada para la normalización de cada canal
- data_format (str, opcional): El formato de los datos, debe ser 'HWC' o 'CHW'. Valor predeterminado: 'CHW'
Este método devuelve la imagen normalizada, el tipo de retorno es numpy ndarray(objeto de matriz n-dimensional numpy).
Modelo de redes
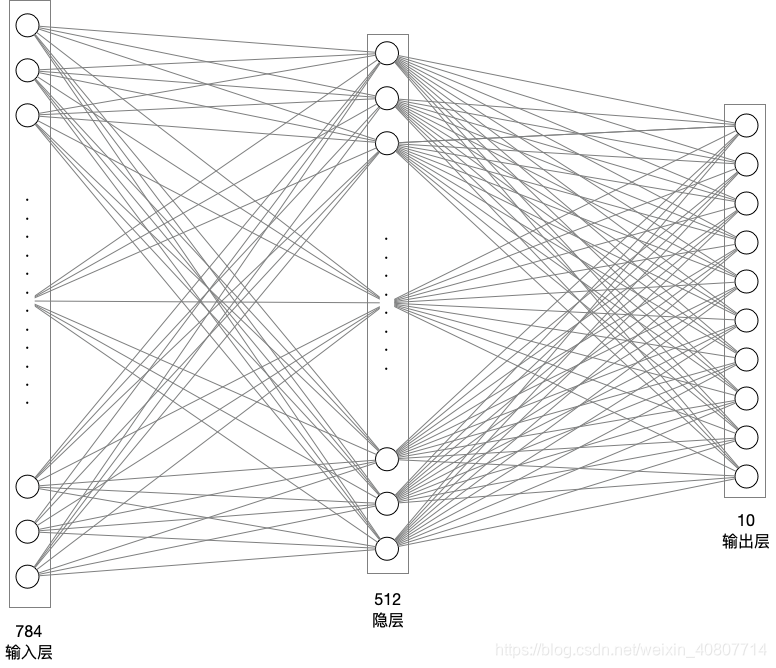
Ahora comience a diseñar la red neuronal, utilizando una red completamente conectada de una sola capa oculta. Capa de entrada de neuronas 784 (28 píxeles * 28 píxeles), capa oculta 512 neuronas (se puede personalizar a voluntad), capa de salida 10 neuronas (obviamente, esta es una tarea de clasificación múltiple, dividida en números 0-9).
El código de construcción modelo es el siguiente:
# 模型网络结构搭建
network = paddle.nn.Sequential(
paddle.nn.Flatten(), # 拉平,将 (28, 28) => (784)
paddle.nn.Linear(784, 512), # 隐层:线性变换层
paddle.nn.ReLU(), # 激活函数
paddle.nn.Linear(512, 10) # 输出层
)
# 模型封装
model = paddle.Model(network)
# 模型可视化
model.summary((1, 28, 28))
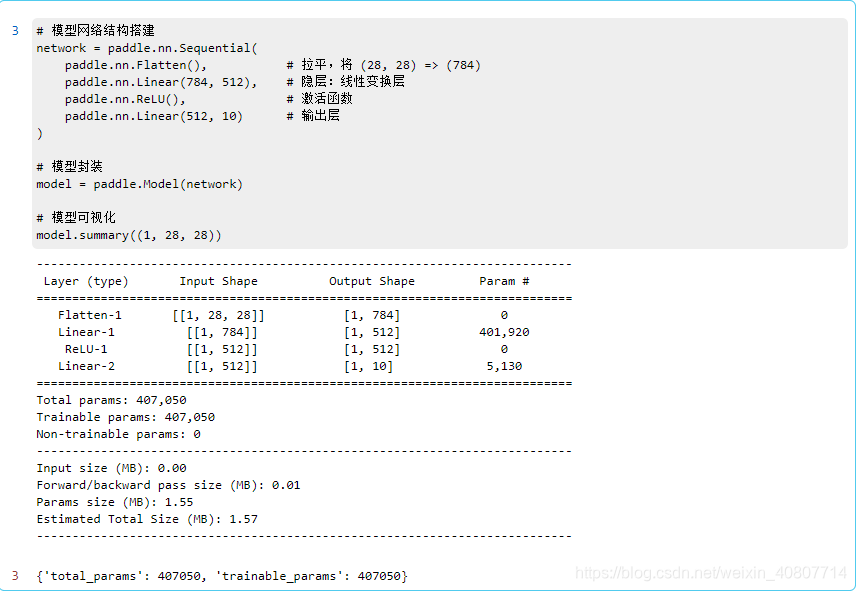
Aquí Sequentialdefinimos la red neuronal. Nota: La Sequentialinterfaz es el contenedor secuencial proporcionado por paddlepaddle . entre ellos,
1.
FlattenInterfaz, aplanar un tensor de dimensión continua en un tensor unidimensional. En resumen, se trata de aplanar los 28 * 28 píxeles.
2.LinearInterfaz, establezca la capa oculta y la capa de salida en capa de transformación lineal. Es decir:
O ut = XW + b Out = XW + bO u t=X W+b
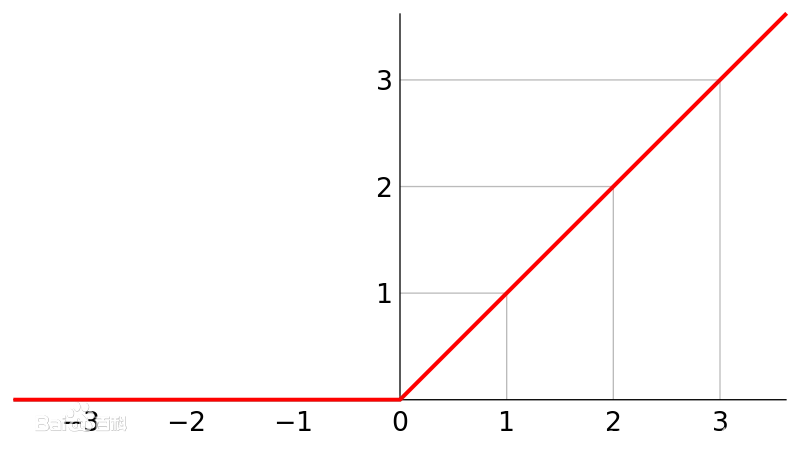
3.ReLUInterfaz, use la función de activación relu para procesar el resultado de la transformación lineal de la neurona y luego, como valor de salida,envíela salida a la siguiente capa
ReLU (x) = max (0, x) ReLU (x) = max (0, X)R y L U ( x )=m una x ( 0 ,x )
Después de eso, el modelo se encapsula y visualiza para confirmar el éxito de la construcción del modelo.
Modelo de entrenamiento
Ahora comience a configurar la función de pérdida, el optimizador y los indicadores de evaluación. Aquí utilizamos el método de descenso de gradiente para optimizar los parámetros de la red neuronal. Entre ellos, utilizamos el optimizador Adam para ajustar dinámicamente la tasa de aprendizaje de cada parámetro. Paddlepaddle también proporciona la interfaz correspondiente . Se recomienda ver el documento de interfaz. Papel del algoritmo de Adam.
Luego comience a entrenar el modelo.
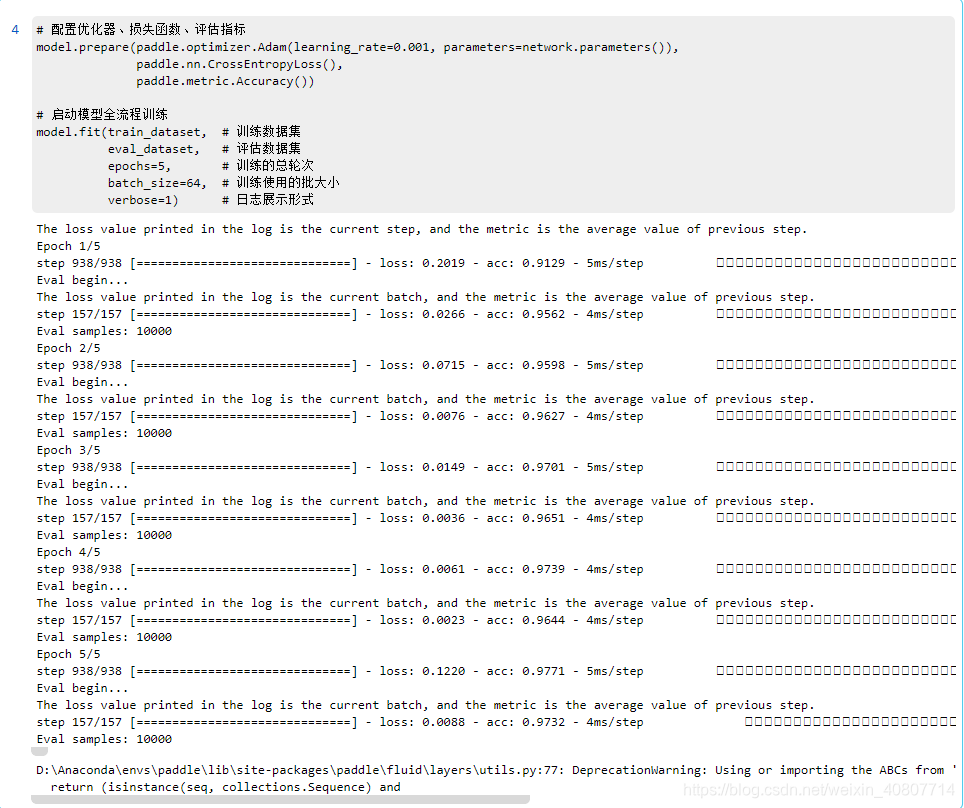
# 配置优化器、损失函数、评估指标
model.prepare(paddle.optimizer.Adam(learning_rate=0.001, parameters=network.parameters()),
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy())
# 启动模型全流程训练
model.fit(train_dataset, # 训练数据集
eval_dataset, # 评估数据集
epochs=5, # 训练的总轮次
batch_size=64, # 训练使用的批大小
verbose=1) # 日志展示形式
Modelo de evaluación
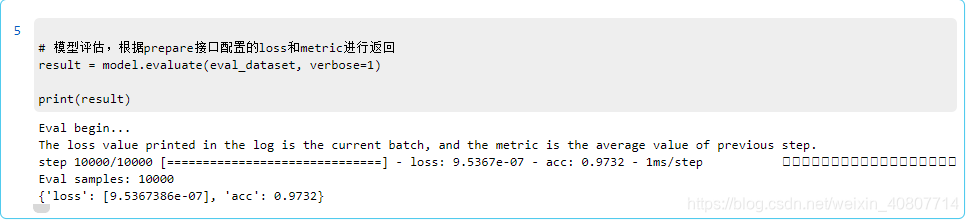
Evalúe el modelo para obtener la precisión (exactitud).
# 模型评估,根据prepare接口配置的loss和metric进行返回
result = model.evaluate(eval_dataset, verbose=1)
print(result)
Predicción del modelo
Predicción por lotes
Úselo predictpara la predicción por lotes.
Extraída de documentos oficiales , la API de alto nivel proporciona una predictinterfaz para facilitar a los usuarios la predicción y verificación del modelo entrenado. Solo necesita colocar los datos que deben predecirse y probarse en la interfaz para el cálculo basado en el modelo entrenado, y la interfaz pasará el modelo Se devuelve el resultado de la predicción calculada.
El formato de retorno es una lista, el número de elementos corresponde al número de salida del modelo:
- El modelo es una única salida:
[(numpy_ndarray_1, numpy_ndarray_2, …, numpy_ndarray_n)]- El modelo es de salida múltiple:
[(numpy_ndarray_1, numpy_ndarray_2, …, numpy_ndarray_n), (numpy_ndarray_1, numpy_ndarray_2, …, numpy_ndarray_n), …]- Nota: Son
numpy_ndarray_nlos datos predichos obtenidos después de que el modelo calcula los datos originales correspondientes, y el número corresponde al número del conjunto de datos predichos.
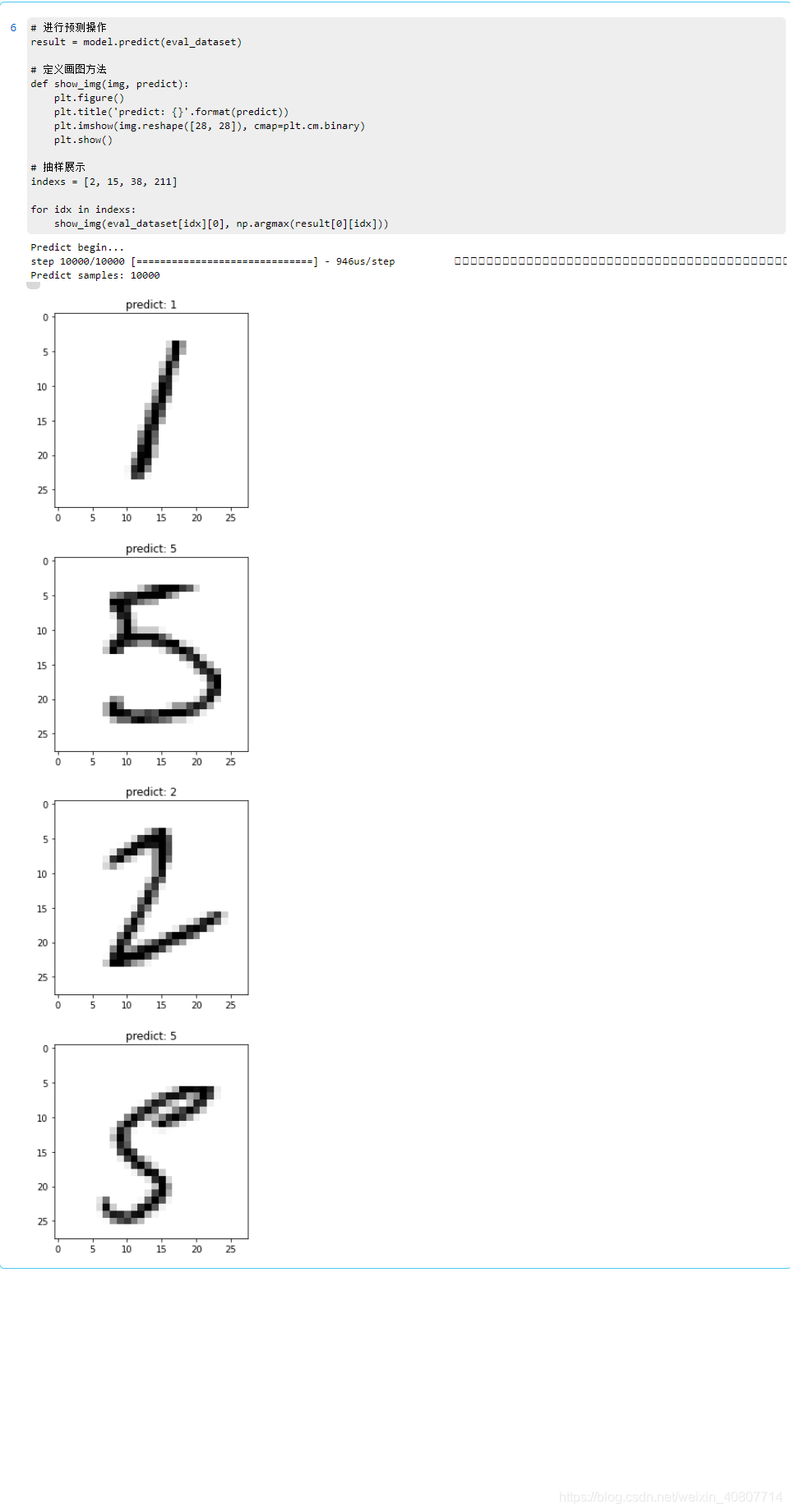
# 进行预测操作
result = model.predict(eval_dataset)
# 定义画图方法
def show_img(img, predict):
plt.figure()
plt.title('predict: {}'.format(predict))
plt.imshow(img.reshape([28, 28]), cmap=plt.cm.binary)
plt.show()
# 抽样展示
indexs = [2, 15, 38, 211]
for idx in indexs:
show_img(eval_dataset[idx][0], np.argmax(result[0][idx]))
Predicción de una sola imagen
Utilice model.predict_batch para predecir una única o una pequeña cantidad de varias imágenes.
# 读取单张图片
image = eval_dataset[501][0]
# 单张图片预测
result = model.predict_batch([image])
# 可视化结果
show_img(image, np.argmax(result))

desplegar
Guardar el modelo
# 保存用于后续继续调优训练的模型
model.save('finetuning/mnist')

Continuar afinando el entrenamiento
from paddle.static import InputSpec
# 模型封装,为了后面保存预测模型,这里传入了inputs参数
model_2 = paddle.Model(network, inputs=[InputSpec(shape=[-1, 28, 28], dtype='float32', name='image')])
# 加载之前保存的阶段训练模型
model_2.load('finetuning/mnist')
# 模型配置
model_2.prepare(paddle.optimizer.Adam(learning_rate=0.001, parameters=network.parameters()),
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy())
# 模型全流程训练
model_2.fit(train_dataset,
eval_dataset,
epochs=2,
batch_size=64,
verbose=1)

Guarde el modelo de predicción
# 保存用于后续推理部署的模型
model_2.save('infer/mnist', training=False)