Uso de Keras para entrenar una red Lenet para el reconocimiento de dígitos escritos a mano
Este blog describirá cómo entrenar una red Lenet usando Keras para el reconocimiento de dígitos escritos a mano.
- La arquitectura LeNet es un trabajo pionero en el aprendizaje profundo que demuestra cómo entrenar una red neuronal para reconocer objetos en una imagen de forma integral (es decir, sin tener que realizar la extracción de características, la red puede aprender patrones de la imagen misma). Introducido por primera vez por LeCun et al. En su artículo de 1998, se aplicó el aprendizaje basado en gradientes al reconocimiento de documentos. Como sugiere el nombre del artículo, la motivación del autor para implementar LeNet es principalmente para el reconocimiento óptico de caracteres (OCR).
- Aunque innovador, LeNet todavía se considera una red "superficial" según los estándares actuales. Con solo cuatro capas entrenables (dos capas CONV y dos capas FC), la profundidad de LeNet eclipsa la de las arquitecturas de vanguardia actuales como VGG (16 y 19 capas) y ResNet (100 capas).
- La arquitectura de LeNet es simple y pequeña (en términos de huella de memoria), lo que la hace ideal para aprender los conceptos básicos de las CNN.
Este blog primero revisará la arquitectura de LeNet y luego implementará la red usando Keras. Finalmente, LeNet para el reconocimiento de dígitos escritos a mano se evaluará en el conjunto de datos MNIST.
1. Representación
Después de 20 y 10 épocas de entrenamiento, se informan errores y la CPU se atasca directamente al 100 %. 8 épocas ajustadas, éxito...
2022-07-04 22:34:57.847384: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'cudart64_110.dll'; dlerror: cudart64_110.dll not found
2022-07-04 22:34:57.848391: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.
[INFO] accessing MNIST...
[INFO] compiling model...
D:\python374\lib\site-packages\keras\optimizer_v2\optimizer_v2.py:356: UserWarning: The `lr` argument is deprecated, use `learning_rate` instead.
"The `lr` argument is deprecated, use `learning_rate` instead.")
2022-07-04 22:35:35.461843: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'nvcuda.dll'; dlerror: nvcuda.dll not found
2022-07-04 22:35:35.462571: W tensorflow/stream_executor/cuda/cuda_driver.cc:269] failed call to cuInit: UNKNOWN ERROR (303)
2022-07-04 22:35:35.467148: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:169] retrieving CUDA diagnostic information for host: WIN10-20180515Z
2022-07-04 22:35:35.467837: I tensorflow/stream_executor/cuda/cuda_diagnostics.cc:176] hostname: WIN10-20180515Z
2022-07-04 22:35:35.468665: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX AVX2
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
[INFO] training network...
2022-07-04 22:35:38.528379: I tensorflow/compiler/mlir/mlir_graph_optimization_pass.cc:185] None of the MLIR Optimization Passes are enabled (registered 2)
Epoch 1/8
1/469 [..............................] - ETA: 4:54 - loss: 2.3132 - accuracy: 0.1250
2/469 [..............................] - ETA: 27s - loss: 2.3172 - accuracy: 0.1211
3/469 [..............................] - ETA: 27s - loss: 2.3099 - accuracy: 0.1354
4/469 [..............................] - ETA: 26s - loss: 2.3119 - accuracy: 0.1387
5/469 [..............................] - ETA: 27s - loss: 2.3136 - accuracy: 0.1375
6/469 [..............................] - ETA: 27s - loss: 2.3145 - accuracy: 0.1289
7/469 [..............................] - ETA: 27s - loss: 2.3133 - accuracy: 0.1306
8/469 [..............................] - ETA: 27s - loss: 2.3121 - accuracy: 0.1348
...
...
...
467/469 [============================>.] - ETA: 0s - loss: 1.0499 - accuracy: 0.7285
468/469 [============================>.] - ETA: 0s - loss: 1.0482 - accuracy: 0.7290
469/469 [==============================] - 28s 58ms/step - loss: 1.0469 - accuracy: 0.7293 - val_loss: 0.2980 - val_accuracy: 0.9138
Epoch 2/8
...
...
...
Epoch 8/8
...
...
...
468/469 [============================>.] - ETA: 0s - loss: 0.0795 - accuracy: 0.9769
469/469 [==============================] - 26s 55ms/step - loss: 0.0795 - accuracy: 0.9769 - val_loss: 0.0639 - val_accuracy: 0.9791
[INFO] evaluating network...
precision recall f1-score support
0 0.98 0.99 0.98 980
1 0.99 0.99 0.99 1135
2 0.98 0.98 0.98 1032
3 0.99 0.97 0.98 1010
4 0.98 0.98 0.98 982
5 0.98 0.98 0.98 892
6 0.98 0.98 0.98 958
7 0.98 0.97 0.98 1028
8 0.96 0.98 0.97 974
9 0.97 0.96 0.97 1009
accuracy 0.98 10000
macro avg 0.98 0.98 0.98 10000
weighted avg 0.98 0.98 0.98 10000
Como puede ver, LeNet logra una precisión de clasificación del 98 %, lo que representa una gran mejora con respecto al 92 % cuando se utiliza una red neuronal de avance estándar.
La pérdida y la precisión a lo largo del tiempo se representan de la siguiente manera:
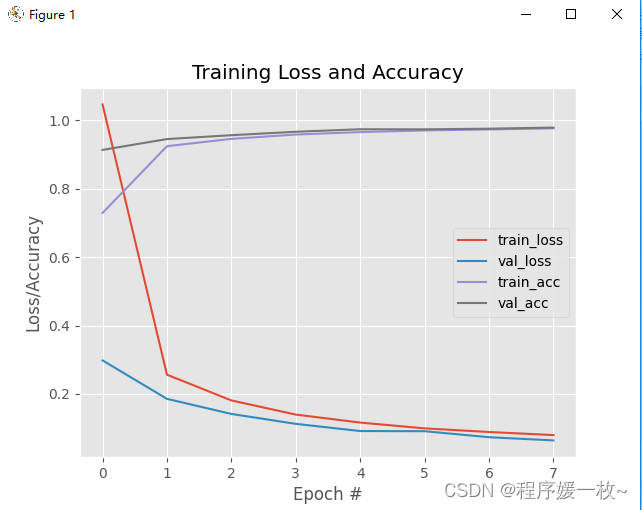
Se puede ver que la red funciona bastante bien. Se ha alcanzado una precisión de clasificación de ≈96% después de 5 épocas. A medida que la tasa de aprendizaje permanece constante y no decae, la pérdida de datos de capacitación y validación continúa disminuyendo con solo unos pequeños "picos". Después de 8 épocas, la precisión en el conjunto de prueba alcanzó el 98 %.
La pérdida y la precisión del entrenamiento y la validación se mimetizan (casi) por completo, sin signos de sobreajuste. A menudo es difícil obtener un gráfico de entrenamiento con un comportamiento tan bueno que indique que la red está aprendiendo los patrones subyacentes sin sobreajustarse.
El conjunto de datos del MNIST está muy preprocesado y no es representativo de los problemas de clasificación de imágenes que se encontrarían en el mundo real. Los investigadores tienden a usar el conjunto de datos MNIST como punto de referencia para evaluar nuevos algoritmos de clasificación. Si su método no logra lograr una precisión de clasificación >95 %, hay una falla en (1) la lógica del algoritmo o (2) la implementación en sí.
2. Principio
pip install opencv-contrib-python
-
La arquitectura LeNet es una excelente red del "mundo real". La red es pequeña, fácil de entender y lo suficientemente grande como para proporcionar resultados interesantes.
-
La arquitectura LeNet consta de dos series de conjuntos de capas CONV=>TANH=>POOL, seguidas de capas completamente conectadas y salidas softmax.
-
La combinación de LeNet+MNIST puede ejecutarse fácilmente en la CPU, lo que facilita que los principiantes den sus primeros pasos en el aprendizaje profundo y CNN. (LeNet+MNIST es el equivalente de "Hello, World" del aprendizaje profundo aplicado a la clasificación de imágenes).
-
La arquitectura de LeNet consta de las siguientes capas, utilizando el modo CONV=>ACT=>POOL y el tipo de capa de red neuronal convolucional (CNN):
ENTRADA => CONV => TANH => POOL => CONV => TANH => POOL => FC => TANH => FC
-
La arquitectura LeNet utiliza una función de activación tanh en lugar de la ReLU más popular. En 1998, ReLU no se usaba en el aprendizaje profundo; es más común usar tanh o sigmoid como función de activación.
La Tabla 1 resume los parámetros de la arquitectura LeNet. La capa de entrada toma una imagen de entrada con 28 filas y 28 columnas y usa un solo canal (escala de grises) para representar la profundidad (es decir, las dimensiones de la imagen en el conjunto de datos MNIST). Luego aprenda 20 filtros, cada filtro es 5×5. La capa CONV es seguida por la activación de ReLU seguida por la agrupación máxima de tamaño 2×2 y zancada 2×2.
El siguiente bloque de la arquitectura sigue el mismo patrón, esta vez aprendiendo 50 filtros de 5×5. Es común aumentar el número de capas CONV en la profundidad de la red a medida que disminuye la dimensión de entrada espacial real.
Luego hay dos capas FC. El primer FC contiene 500 nodos ocultos seguidos de activaciones de ReLU. La última capa FC controla el número de etiquetas de clase de salida (0-9; una para cada uno de los diez dígitos posibles). Finalmente aplique la activación softmax para obtener probabilidades de clase.
3. Código fuente
# 使用LeNet进行手写数字识别
# USAGE
# python lenet_mnist.py
# 1. 从磁盘加载MNIST数据集
# 2. 实例化LeNet架构
# 3. 训练LeNet模型
# 4. 评估网络性能
# 在绝大多数机器学习情况下,几乎所有的示例都遵循这种通用的导入模式:
# 将要训练的网络架构、用于训练网络的优化器(SGD)、用于构造给定数据集的训练和测试分割的(一组)便利函数、一个用于计算分类报告的函数,以便评估分类器的性能;
# 以及一些额外的类,以方便执行某些任务(例如预处理图像)。
# 导入必要的包
from pyimagesearch.nn.conv.lenet import LeNet
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.datasets import mnist
from sklearn.preprocessing import LabelBinarizer
from sklearn.metrics import classification_report
from tensorflow.keras import backend as K
import matplotlib.pyplot as plt
import numpy as np
import os
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"] = "-1"
# MNIST数据集已经过预处理(11MB第一次会自动下载)
# load_data()会从Keras数据集存储库下载MNIST数据集。MNIST数据集被序列化为单个11MB文件,
# 注意:每个MNIST样本内部数据由28×28灰度图像的784-d矢量(即原始像素强度)表示。因此需要根据“通道优先”还是“通道最后”排序来重塑数据矩阵:
print("[INFO] accessing MNIST...")
((trainData, trainLabels), (testData, testLabels)) = mnist.load_data()
# 如果是通道优先,则转换为样本数*深度*高度*宽度
if K.image_data_format() == "channels_first":
trainData = trainData.reshape((trainData.shape[0], 1, 28, 28))
testData = testData.reshape((testData.shape[0], 1, 28, 28))
# 如果是通道最后,则转换矩阵为:num_samples x rows x columns x depth
else:
trainData = trainData.reshape((trainData.shape[0], 28, 28, 1))
testData = testData.reshape((testData.shape[0], 28, 28, 1))
# 将图像像素强度缩放到[0,1]范围
trainData = trainData.astype("float32") / 255.0
testData = testData.astype("float32") / 255.0
# 转换类标签编码为一个热向量,而不是单个整数值。如3,转换为热编码:[0, 0, 0, 1, 0, 0, 0, 0, 0, 0]
# 注意:向量中的所有项都是零,数字0是第一个索引,因此为什么三是第四个索引
le = LabelBinarizer()
trainLabels = le.fit_transform(trainLabels)
testLabels = le.transform(testLabels)
# 初始化优化器和模型
# 以0.01的学习率初始化SGD优化器
# 实例化LeNet,表明数据集中的所有输入图像都将是28像素宽、28像素高,深度为1。假设MNIST数据集中有十个类(每个数字一个,0−8) 因此将标签类型设置为10
# 使用交叉熵损失作为损失函数来编译模型
print("[INFO] compiling model...")
opt = SGD(lr=0.01)
model = LeNet.build(width=28, height=28, depth=1, classes=10)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
# 训练网络
# 使用128个小批量在MNIST上训练LeNet总共10个纪元
print("[INFO] training network...")
H = model.fit(trainData, trainLabels,
validation_data=(testData, testLabels), batch_size=128,
epochs=8, verbose=1)
# 评估网络的性能,并绘制随时间变化的损失和准确性图表
# 调用model.predict() 对于testX中的每个样本,构造128个批量,然后通过网络进行分类。对所有测试数据点进行分类后,返回预测变量。
# 预测变量实际上是一个NumPy数组,形状为(len(testX),10),这意味着现在有10个概率与testX中每个数据点的每个类标签相关。
# classification_report中的argmax(axis=1)查找概率最大的标签索引(即最终输出分类)。给定网络的最终分类,可以将预测的类标签与实际的标签值进行比较。
print("[INFO] evaluating network...")
predictions = model.predict(testData, batch_size=128)
print(classification_report(testLabels.argmax(axis=1),
predictions.argmax(axis=1),
target_names=[str(x) for x in le.classes_]))
# 绘制训练/验证的损失/准确度图表
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0, 8), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, 8), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, 8), H.history["accuracy"], label="train_acc")
plt.plot(np.arange(0, 8), H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend()
plt.show()