Tensorflow2 implementa el reconocimiento de dígitos escritos a mano
0. Introducción al conjunto de datos MNIST
El conjunto de datos MNIST proviene del Instituto Nacional de Estándares y Tecnología (NIST). El conjunto de capacitación consta de números escritos a mano por 250 personas diferentes, el 50% de las cuales son estudiantes de secundaria y el 50% del personal de la Oficina del Censo. El conjunto de prueba también tiene la misma proporción de datos de dígitos escritos a mano.
El conjunto de datos MNIST está disponible en MNIST y consta de cuatro partes:
- Imágenes del conjunto de entrenamiento: train-images-idx3-ubyte.gz
(47 MB descomprimidos, contiene 60.000 muestras) - Etiquetas del conjunto de entrenamiento: train-labels-idx1-ubyte.gz
(60 KB después de la descompresión, contiene 60.000 etiquetas) - Imágenes del conjunto de prueba: t10k-images-idx3-ubyte.gz
(7,8 MB después de la descompresión, contiene 10.000 muestras) - Etiquetas del conjunto de prueba: t10k-labels-idx1-ubyte.gz
(10 KB después de la descompresión, contiene 10 000 etiquetas)
Las imágenes del conjunto de entrenamiento y del conjunto de prueba aquí son imágenes en escala de grises de 28 × 28 y cada píxel tiene un valor en [0, 255].
El valor en el conjunto de etiquetas es un valor en [0, 9], que marca el número escrito a mano de la imagen de posición correspondiente.
ejemplo: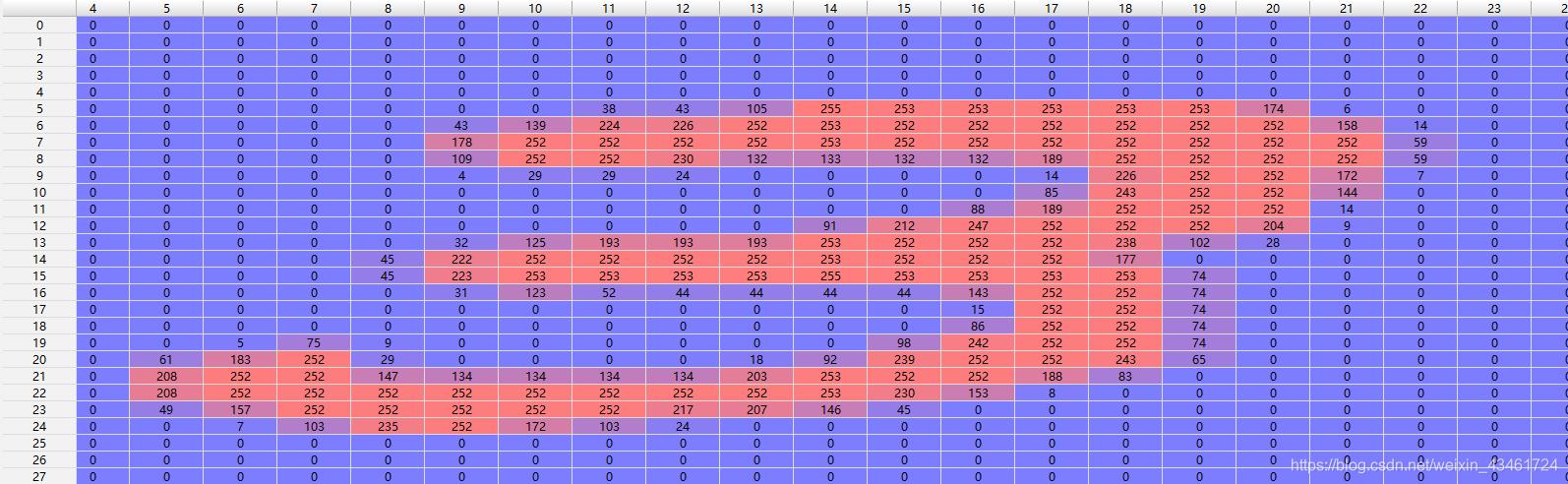
1. Detalles del código
import tensorflow as tf
Introducir el módulo tensorflow con tf como alias
batch_size = 128
le_r = 0.2
Definir un tamaño de lote y una tasa de aprendizaje
mnist = tf.keras.datasets.mnist
(ti, tl), (vi, vl) = mnist.load_data()
print('datasets:', ti.shape, tl.shape, vi.shape, vl.shape)
Utilice la función incorporada de tensorflow para importar el conjunto de datos MNIST
Y genere las dimensiones de los datos:
conjuntos de datos: (60000, 28, 28) (60000,)
(10000, 28, 28) (10000,)
def fun(a, b):
a = tf.cast(a, dtype=tf.float32)
b = tf.cast(b, dtype=tf.int64)
return tf.reshape(a, [-1, 28*28])/255.0, tf.one_hot(b, depth=10)
ti, tl = fun(ti, tl)
vi, _ = fun(vi, vl)
Dado que las dimensiones de vi y ti son [-1, 28, 28], esperamos aplanar cada muestra [28, 28] en [784] para facilitar la entrada a la red, por lo que aquí se define una función denominada fun, respectivamente. Realice el preprocesamiento de datos en ti, tl y vi (no es necesario procesar vl). La entrada simplemente se normaliza, es decir, se divide por 255,0 (valor máximo - valor mínimo en los datos). Y se realiza una codificación one-hot en las etiquetas.
Después del preprocesamiento, las dimensiones de ti y vi son [60000, 784] y [10000, 784] respectivamente.
ejemplo:
Después de la normalización
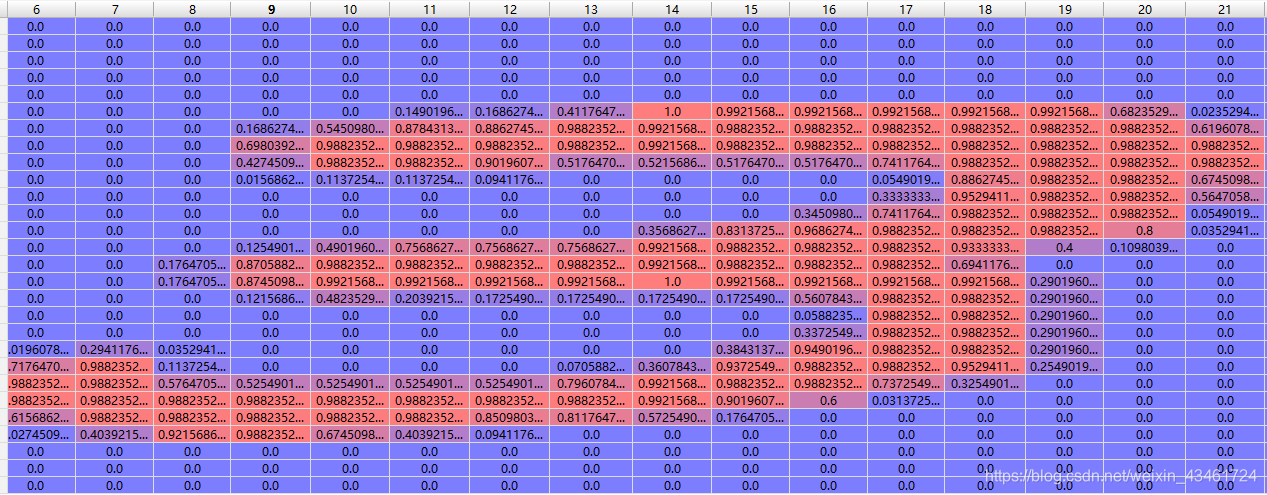
Su etiqueta correspondiente 3 se expandirá a [0, 0, 0, 1, 0, 0, 0, 0, 0]
Acerca de la expansión del preprocesamiento de datos:
d1 = tf.data.Dataset.from_tensor_slices((ti, tl)) # ti tl 自动转换为tensor
d1 = d1.shuffle(10000).batch(batch_size)
Llame a la función tf.data.Dataset.from_tensor_slices() para construir una porción de (ti, tl): shuffle() puede mezclar los datos.batch(batch_size) puede dividir los datos en varios grupos de datos del tamaño de un lote y devolver un Iterable Objeto utilizado para iterar a través de grupos de datos individuales.
w1 = tf.random.normal([784, 512])
b1 = tf.zeros([512], dtype=tf.float32)
w2 = tf.random.normal([512, 10])
b2 = tf.zeros([10], dtype=tf.float32)
Construya la matriz de peso w y su desplazamiento b de la primera y segunda capa, inicialice b en una matriz 0; inicialice w de acuerdo con una distribución normal.
Aquí, dado que la dimensión ti de entrada se ha procesado a [-1, 784],]', nuestra entrada es de 784 nodos y la capa oculta intermedia es de 512 nodos. Dado que es un problema de clasificación de 10 clases, la salida es 10 nodos, que representan números del 0 al 9, cuanto mayor sea la salida del nodo, más probable es que represente este número.
Respecto a la expansión de inicialización de peso:
-
Una descripción general de la inicialización de pesos en redes neuronales: desde lo básico hasta Kaiming
Luego, itere el conjunto de datos para la optimización del descenso de gradiente y genere la precisión de la red en el conjunto de verificación en un período fijo.
for epoch in range(10):
print('the {0} epoch began'.format(epoch))
d2 = iter(d1)
for steps, (x, y) in enumerate(d2):
with tf.GradientTape() as tape:
tape.watch([w1, b1, w2, b2]) # 可以去掉tf.variable()包装
h1 = x@w1 + b1
a1 = tf.nn.sigmoid(h1)
out1 = a1 @ w2 + b2
loss = tf.reduce_mean(tf.losses.categorical_crossentropy(y, out1, from_logits=True))
if steps % 100 == 0:
print(steps, 'finished')
grads = tape.gradient(loss, [w1, b1, w2, b2])
w1 = w1 - le_r*grads[0]
b1 = b1 - le_r*grads[1]
w2 = w2 - le_r*grads[2]
b2 = b2 - le_r*grads[3]
c1 = tf.nn.sigmoid(vi @ w1 + b1)
c2 = tf.nn.softmax(c1 @ w2 + b2, axis=1)
out2 = tf.cast(tf.argmax(c2, axis=1), dtype=tf.int64)
acc = tf.reduce_sum(tf.cast(tf.equal(out2, vl), tf.float32))/vl.shape[0]
print('the {0} epoch finished and the acc ={1}'.format(epoch+1, acc))
Visto por separado:
for epoch in range(10):
print('the {0} epoch began'.format(epoch))
d2 = iter(d1)
for steps, (x, y) in enumerate(d2):
La primera es ejecutar un total de 10 épocas, es decir, 10 bucles grandes. Cada bucle grande primero inicializa d2 como el iterador de d1 y luego itera d1 a través del bucle for. Las dimensiones de d1, x e y excepto el Los últimos son [128, 784], [128, 10].
with tf.GradientTape() as tape:
tape.watch([w1, b1, w2, b2]) # 可以去掉tf.variable()包装
h1 = x@w1 + b1
a1 = tf.nn.sigmoid(h1) # [TensorShape([128, 500])
out1 = a1 @ w2 + b2
loss = tf.reduce_mean(tf.losses.categorical_crossentropy(y, out1, from_logits=True))
@ significa multiplicación de matrices
Aquí se utiliza la poderosa diferenciación automática de Tensorflow: tape.watch ([w1, b1, w2, b2]) significa registrar la información de gradiente de w1, b1, w2, b2, de modo que no sea necesario empaquetar un paquete para w1, b1. , w2, b2.Capa tf.Variable().
a1 es la salida final de la capa oculta de h2 después de ser procesada por la función de activación sigmoide().
Finalmente, defina la función de pérdida. El valor de esta función representa el grado de desviación entre nuestra salida final de [-1, 10] y la etiqueta [-1, 10]. Aquí se puede utilizar el error cuadrático medio, pero el efecto es mejor utilizar la función de entropía cruzada como función de pérdida. La función de entropía cruzada puede reflejar con mayor precisión la brecha entre dos distribuciones de probabilidad.
Aquí, debido a que no hemos realizado el procesamiento softmax en la salida para que se ajuste a las características de la distribución de probabilidad (la suma es 1), configuramos from_logits en True, lo que volverá a llamar a softmax_cross_entropy_with_logits_v2() para ayudarnos a realizar softmax. procesamiento dentro de la función.
Aquí hay una demostración de la derivación automática de tensorflow. También puede encontrar la derivada de segundo orden mediante anidamiento.
With tf.GradientTape() as tape:
Build computation graph
loss=fθ(x)
[w_grad] = tape.gradient(loss,[w])
if steps % 100 == 0:
print(steps, 'finished')
grads = tape.gradient(loss, [w1, b1, w2, b2])
w1 = w1 - le_r*grads[0]
b1 = b1 - le_r*grads[1]
w2 = w2 - le_r*grads[2]
b2 = b2 - le_r*grads[3]
grads = tape.gradient(loss, [w1, b1, w2, b2]) saca la matriz derivada parcial de w1, b1, w2, b2 para perder (función de pérdida) (grads = [dw1, db1, dw2, db2] )
Las líneas 4, 5, 6 y 7 actualizan los parámetros en la dirección de reducción del gradiente.
Cada vez que se ejecutan 100 lotes (se realizan 100 descensos de gradiente), se genera un mensaje de finalización.
c1 = tf.nn.sigmoid(vi @ w1 + b1)
c2 = tf.nn.softmax(c1 @ w2 + b2, axis=1)
out2 = tf.cast(tf.argmax(c2, axis=1), dtype=tf.int64)
acc = tf.reduce_sum(tf.cast(tf.equal(out2, vl), tf.float32))/vl.shape[0]
print('the {0} epoch finished and the acc ={1}'.format(epoch+1, acc))
En este momento, se ha completado 1 época y c1 y c2 son el proceso de propagación hacia adelante del conjunto de verificación. En este momento, la dimensión c2 es [10000, 10], es decir, cada fila es la salida de una imagen de muestra del conjunto de verificación después del procesamiento de la red. No es necesario realizar procesamiento softmax en ella. Solo necesitamos sacar el nodo inferior del nodo con el valor de salida más grande entre los 10 nodos. Puede conocer el valor predicho de esta imagen de muestra utilizando el estándar.
La función tf.argmax() se utiliza aquí para obtener el subíndice del elemento más grande en cada fila. La dimensión out2 procesada es [10000,], que corresponde a los valores predichos de 10000 imágenes del conjunto de verificación.
Luego compare out2 con el conjunto de etiquetas vl, convierta los valores verdadero y falso a 1 o 0, resúmalo para obtener el número de imágenes predichas correctamente y luego divida por vl.shape [0], que es 10000. , para obtener el número previsto. La tasa de precisión ha aumentado.

Después de ejecutarlo, puede ver que la precisión de esta red para predecir dígitos escritos a mano es de aproximadamente el 91%. Si utiliza una red convolucional, puede lograr una mayor precisión.
2. Descripción general del código
import tensorflow as tf
batch_size = 128
le_r = 0.2
def fun(a, b):
a = tf.cast(a, dtype=tf.float32)
b = tf.cast(b, dtype=tf.int64)
return tf.reshape(a, [-1, 28*28])/255.0, tf.one_hot(b, depth=10)
mnist = tf.keras.datasets.mnist
(ti, tl), (vi, vl) = mnist.load_data()
print('datasets:', ti.shape, tl.shape, vi.shape, vl.shape)
ti, tl = fun(ti, tl)
vi, _ = fun(vi, vl)
d1 = tf.data.Dataset.from_tensor_slices((ti, tl)) # ti tl 自动转换为tensor
d1 = d1.shuffle(10000).batch(batch_size)
w1 = tf.random.normal([784, 512])
b1 = tf.zeros([512], dtype=tf.float32)
w2 = tf.random.normal([512, 10])
b2 = tf.zeros([10], dtype=tf.float32)
for epoch in range(10):
print('the {0} epoch began'.format(epoch))
d2 = iter(d1)
for steps, (x, y) in enumerate(d2):
with tf.GradientTape() as tape:
tape.watch([w1, b1, w2, b2]) # 可以去掉tf.variable()包装
h1 = x@w1 + b1
a1 = tf.nn.sigmoid(h1)
out1 = a1 @ w2 + b2
loss = tf.reduce_mean(tf.losses.categorical_crossentropy(y, out1, from_logits=True))
if steps % 100 == 0:
print(steps, 'finished')
grads = tape.gradient(loss, [w1, b1, w2, b2])
w1 = w1 - le_r*grads[0]
b1 = b1 - le_r*grads[1]
w2 = w2 - le_r*grads[2]
b2 = b2 - le_r*grads[3]
c1 = tf.nn.sigmoid(vi @ w1 + b1)
c2 = tf.nn.softmax(c1 @ w2 + b2, axis=1)
out2 = tf.cast(tf.argmax(c2, axis=1), dtype=tf.int64)
acc = tf.reduce_sum(tf.cast(tf.equal(out2, vl), tf.float32))/vl.shape[0]
print('the {0} epoch finished and the acc ={1}'.format(epoch+1, acc))