Cómo instalar la antorcha

método de estudio
- 1. Aprenda mientras usa, la antorcha es solo una herramienta, y el proceso de usarla es el proceso de aprendizaje
- 2. Simplemente vaya al caso directamente, ejecute primero y resuelva lo que encuentre
Tarea de clasificación de Mnist:
-
Construcción de redes básicas y métodos de entrenamiento, análisis de funciones comunes
-
módulo torch.nn.function
-
nn.Módulo módulo
Leer el conjunto de datos de Mnist
- se descargará automáticamente
# 查看自己的torch的版本
import torch
print(torch.__version__)
%matplotlib inline
# 前两步,不用管是在网上下载数据,后续的我们都是在本地的数据进行操作
from pathlib import Path
import requests
DATA_PATH = Path("data")
PATH = DATA_PATH / "mnist"
PATH.mkdir(parents=True, exist_ok=True)
URL = "http://deeplearning.net/data/mnist/"
FILENAME = "mnist.pkl.gz"
if not (PATH / FILENAME).exists():
content = requests.get(URL + FILENAME).content
(PATH / FILENAME).open("wb").write(content)
import pickle
import gzip
with gzip.open((PATH / FILENAME).as_posix(), "rb") as f:
((x_train, y_train), (x_valid, y_valid), _) = pickle.load(f, encoding="latin-1")
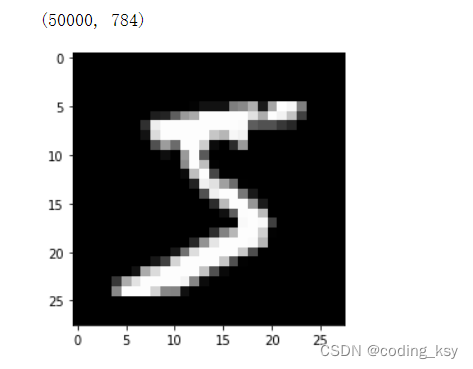
784 es el número de píxeles por muestra en el conjunto de datos mnist
from matplotlib import pyplot
import numpy as np
pyplot.imshow(x_train[0].reshape((28, 28)), cmap="gray")
print(x_train.shape)
La estructura de la red neuronal completamente conectada
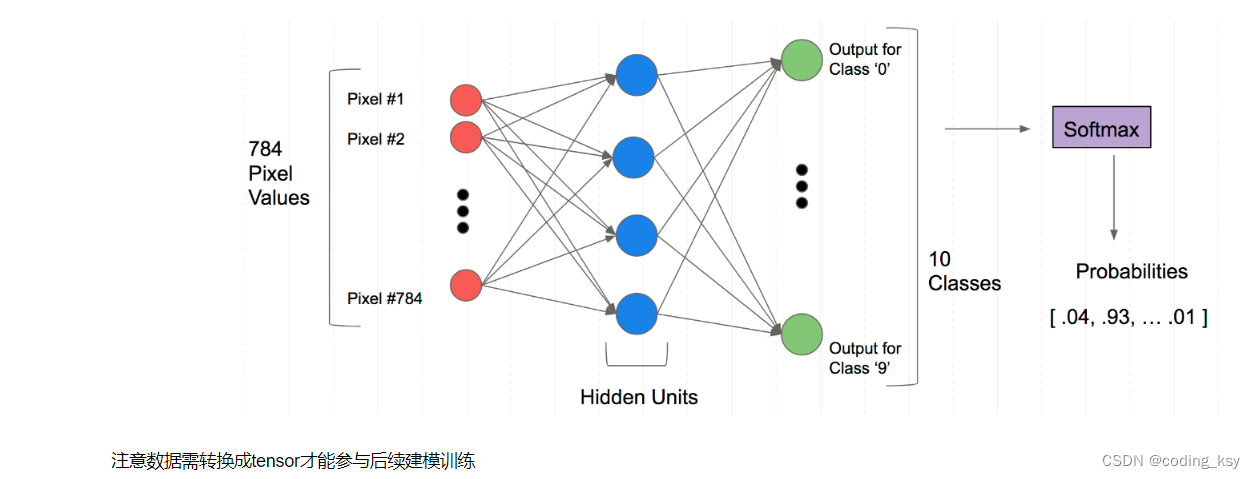 Tenga en cuenta que los datos deben convertirse en tensor para participar en el entrenamiento de modelado posterior
Tenga en cuenta que los datos deben convertirse en tensor para participar en el entrenamiento de modelado posterior
import torch
x_train, y_train, x_valid, y_valid = map(
torch.tensor, (x_train, y_train, x_valid, y_valid)
)
n, c = x_train.shape
x_train, x_train.shape, y_train.min(), y_train.max()
print(x_train, y_train)
print(x_train.shape)
print(y_train.min(), y_train.max())
torch.nn.funcional Muchas capas y funciones se verán aquí
Hay muchas funciones en torch.nn.funcional, que se usarán comúnmente en el futuro. Entonces, ¿cuándo usar nn.Module y cuándo usar nn.funcional? En general, si el modelo tiene parámetros que se pueden aprender, es mejor usar nn.Module, y nn.funcional es relativamente más simple en otros casos.
import torch.nn.functional as F
loss_func = F.cross_entropy
def model(xb):
return xb.mm(weights) + bias
bs = 64
xb = x_train[0:bs] # a mini-batch from x
yb = y_train[0:bs]
weights = torch.randn([784, 10], dtype = torch.float, requires_grad = True)
bs = 64
bias = torch.zeros(10, requires_grad=True)
print(loss_func(model(xb), yb))
Crear un modelo para simplificar más el código.
- Debe heredar nn.Module y llamar al constructor de nn.Module en su constructor
- No es necesario escribir la función de retropropagación, nn.Module puede usar autograd para implementar automáticamente la retropropagación
- Los parámetros que se pueden aprender en el módulo pueden devolver un iterador a través de named_parameters() o parámetros()
from torch import nn
class Mnist_NN(nn.Module):
# 构造函数
def __init__(self):
super().__init__()
self.hidden1 = nn.Linear(784, 128)
self.hidden2 = nn.Linear(128, 256)
self.out = nn.Linear(256, 10)
self.dropout = nn.Dropout(0.5)
#前向传播自己定义,反向传播是自动进行的
def forward(self, x):
x = F.relu(self.hidden1(x))
x = self.dropout(x)
x = F.relu(self.hidden2(x))
x = self.dropout(x)
#x = F.relu(self.hidden3(x))
x = self.out(x)
return x
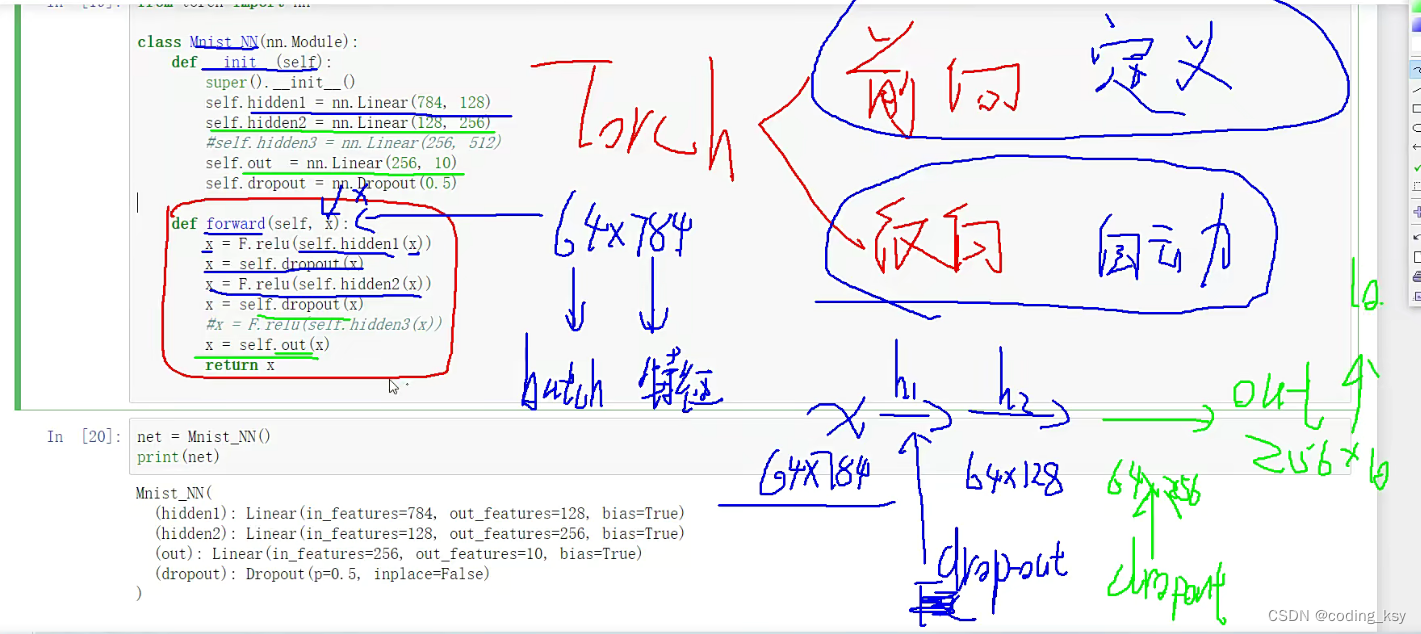
net = Mnist_NN()
print(net)
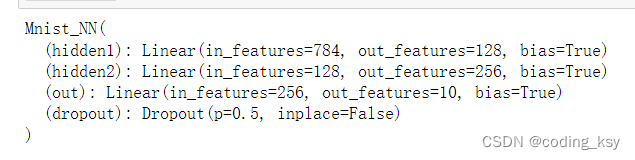
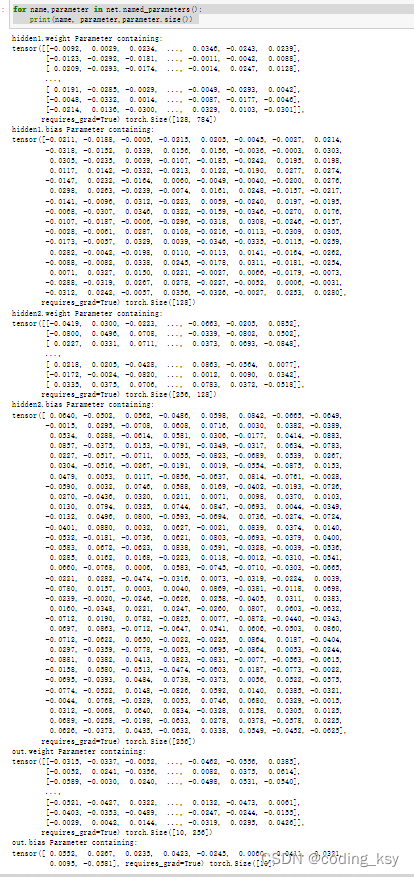
Puede imprimir los pesos y sesgos en los nombres que definimos
for name,parameter in net.named_parameters():
print(name, parameter,parameter.size())
Use TensorDataset y DataLoader para simplificar
from torch.utils.data import TensorDataset
from torch.utils.data import DataLoader
train_ds = TensorDataset(x_train, y_train)
train_dl = DataLoader(train_ds, batch_size=bs, shuffle=True)
valid_ds = TensorDataset(x_valid, y_valid)
valid_dl = DataLoader(valid_ds, batch_size=bs * 2)
def get_data(train_ds, valid_ds, bs):
return (
DataLoader(train_ds, batch_size=bs, shuffle=True),
DataLoader(valid_ds, batch_size=bs * 2),
)
- Generalmente, model.train() se agrega cuando se entrena el modelo, de modo que la normalización por lotes y el abandono se usarán normalmente.
- Al realizar pruebas, generalmente elija model.eval(), de modo que no se utilicen la Normalización por lotes y la Eliminación.
import numpy as np
def fit(steps, model, loss_func, opt, train_dl, valid_dl):
for step in range(steps):
model.train() # 训练的时候需要更新权重参数
for xb, yb in train_dl:
loss_batch(model, loss_func, xb, yb, opt)
model.eval() # 验证的时候不需要更新权重参数
with torch.no_grad():
losses, nums = zip(
*[loss_batch(model, loss_func, xb, yb) for xb, yb in valid_dl]
)
val_loss = np.sum(np.multiply(losses, nums)) / np.sum(nums)
print('当前step:'+str(step), '验证集损失:'+str(val_loss))
uso de zip
a = [1,2,3]
b = [4,5,6]
zipped = zip(a,b)
print(list(zipped))
a2,b2 = zip(*zip(a,b))
print(a2)
print(b2)
from torch import optim
def get_model():
model = Mnist_NN()
return model, optim.SGD(model.parameters(), lr=0.001)
def loss_batch(model, loss_func, xb, yb, opt=None):
loss = loss_func(model(xb), yb)
if opt is not None:
loss.backward()
opt.step()
opt.zero_grad()
return loss.item(), len(xb)
¡Tres líneas lo hacen!
train_dl,valid_dl = get_data(train_ds, valid_ds, bs)
model, opt = get_model()
fit(100, model, loss_func, opt, train_dl, valid_dl)

correct = 0
total = 0
for xb,yb in valid_dl:
outputs = model(xb)
_,predicted = torch.max(outputs.data,1)
total += yb.size(0)
correct += (predicted == yb).sum().item()
print(f"Accuracy of the network the 10000 test imgaes {
100*correct/total}")
![Insertar descripción de la imagen aquí](https://img-blog.csdnimg.cn/89e5e749b680426c9700aac9f93bf76a.png
Aquellos que estén interesados en el período posterior pueden comparar los dos optimizadores de SGD y Adam, cuál es mejor
-SGD 20epoch 85%
-Adam 20epoch 85%