1. Antecedentes
La red neuronal convolucional (red neuronal convolucional, también conocida como ConvNet) retiene información espacial y, por lo tanto, puede usarse mejor para la clasificación de imágenes.
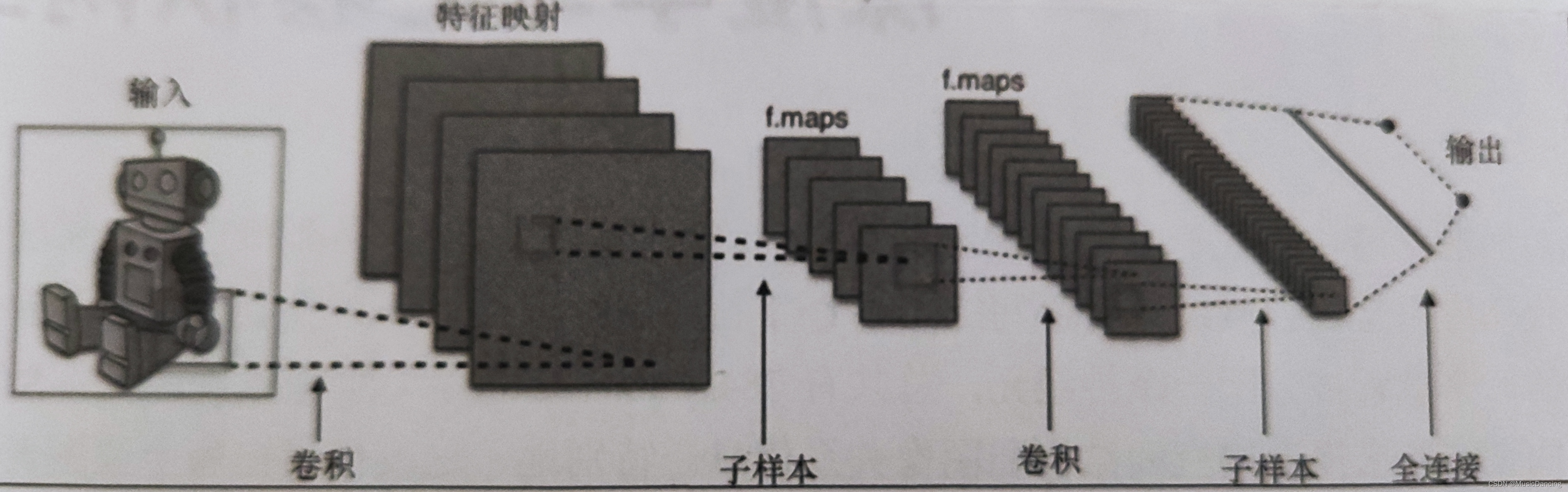
La operación de convolución se basa en campos receptivos locales cuidadosamente seleccionados y comparte pesos en múltiples planos de características ; luego, la capa completamente conectada se basa en un perceptrón multicapa tradicional, utilizando softmax como capa de salida.
Innovaciones en redes convolucionales: retener información espacial, agregar convolución, agrupación y planos de características .
2. Composición de la red
2.1 Campo receptivo local
Convolución: conecte la submatriz de neuronas de entrada adyacentes a una única neurona oculta en la siguiente capa. Esta única neurona oculta representa un campo receptivo local.
Las capas convolucionales pueden representar eficazmente el espacio local reutilizando núcleos de convolución. En DL, se aprenden las matrices del núcleo. Los núcleos de convolución se pueden diseñar para detectar bordes en imágenes.
CNN tiene múltiples filtros apilados para identificar de forma independiente características visuales específicas en diferentes ubicaciones de la imagen . Estas características son muy simples en la capa de red inicial y se vuelven cada vez más complejas a medida que la capa de red se profundiza.
(1) padding = 'mismo': indica que el resultado de la convolución en el límite se conserva, el límite de entrada se rellena con 0 y su salida es del mismo tamaño que la entrada;
(2) padding = 'vaild': significa que solo se convolucionará la parte donde la entrada y el filtro están completamente superpuestos, y la salida será más pequeña que la entrada.
2.2 Pesos y sesgos compartidos
aprobar
2.3 Agrupación
Todas las operaciones de agrupación son operaciones de resumen en una región determinada.
Resuma la salida del plano de características (agregue estas submatrices en un único valor de salida) para describir el significado de la región física asociada.
2.3.1 Agrupación máxima
aprobar
2.3.2 Agrupación promedio
aprobar
3. Solicitud
La convolución unidimensional se utiliza principalmente para procesar datos de sonido y texto en la dimensión temporal;
La convolución bidimensional (alto * ancho) se utiliza principalmente para el procesamiento de datos de imágenes; su matriz bidimensional de salida puede considerarse como una representación de la entrada en un cierto nivel en la dimensión espacial, también llamado mapa de características.
La convolución tridimensional (alto*ancho*tiempo) se utiliza principalmente para el procesamiento de datos de vídeo;
3.1 Conjunto de datos del ministro de predicción de la red LeNet
Características: Deje que las capas inferiores de la red realicen operaciones de convolución y agrupación máxima alternativamente, lo cual es muy resistente a transformaciones geométricas y torsiones simples.
Código:
1. Definición del modelo
from keras.models import Sequential
from keras.layers.convolutional import Conv2D, MaxPooling2D
from keras.layers import Convolution2D
from keras.layers.core import Activation, Flatten, Dense
from keras.datasets import mnist
from keras.utils import np_utils
from keras.optimizers import Adam
import numpy as np
import matplotlib.pyplot as plt
class LeNet:
@staticmethod
def build(input_shape, classes):
model = Sequential()
model.add(Convolution2D(20, kernel_size=5, padding='same', input_shape=input_shape))
# model.add(Conv2D(20, kernel_size=5, padding='same', input_shape=input_shape))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
model.add(Flatten())
model.add(Dense(500))
model.add(Activation('relu'))
model.add(Dense(classes))
model.add(Activation('softmax'))
return model2. Formación y evaluación de modelos
def model_train(X_train, y_train):
OPTIMIZER = Adam()
model = LeNet.build(input_shape=INPUT_SHAPE, classes=NB_CLASSES)
model.compile(loss='categorical_crossentropy', optimizer=OPTIMIZER, metrics=['accuracy'])
history = model.fit(X_train, y_train, batch_size=BATCH_SIZE, epochs=NB_EPOCH, verbose=1, validation_split=VALIDATION_SPLIT)
# plot_picture(history)
return model
def model_evaluate(model, X_test, y_test):
score = model.evaluate(X_test, y_test, verbose=1)
print('Test score: ', score[0])
print('Test acc: ', score[1])3. Carga y preprocesamiento de datos
def load_and_proc_data():
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_test /= 255
print('X_train shape', X_train.shape)
print(X_train.shape[0], 'train samples')
print(X_test.shape[0], 'test samples')
# 将类向量转换成二值类别矩阵
y_train = np_utils.to_categorical(y_train, NB_CLASSES)
y_test = np_utils.to_categorical(y_test, NB_CLASSES)
return X_train, X_test, y_train, y_test4. Función principal
NB_EPOCH = 20
BATCH_SIZE = 128
VALIDATION_SPLIT = 0.2
IMG_ROWS, IMG_COLS = 28, 28
INPUT_SHAPE = (IMG_ROWS, IMG_COLS, 1) # 单通道
NB_CLASSES = 10
if __name__ == '__main__':
X_train, X_test, y_train, y_test = load_and_proc_data()
model = model_train(X_train, y_train)
model_evaluate(model, X_test, y_test)3.2 La red LeNet predice el conjunto de datos de imágenes CIFAR-10
Para más detalles, consulte:
3.3 Red VGG16 y transferencia de aprendizaje
Para más detalles, consulte: