Red neuronal convolucional
Las redes neuronales convolucionales se diseñaron originalmente para resolver problemas relacionados con la visión por computadora, pero ahora no solo se utilizan en campos de imagen y video, sino también en el procesamiento de señales de series de tiempo como las señales de audio.
Este artículo se centra principalmente en los principios básicos de las redes neuronales convolucionales y el uso de PyTorch para implementar redes neuronales convolucionales.
1. Contexto de desarrollo
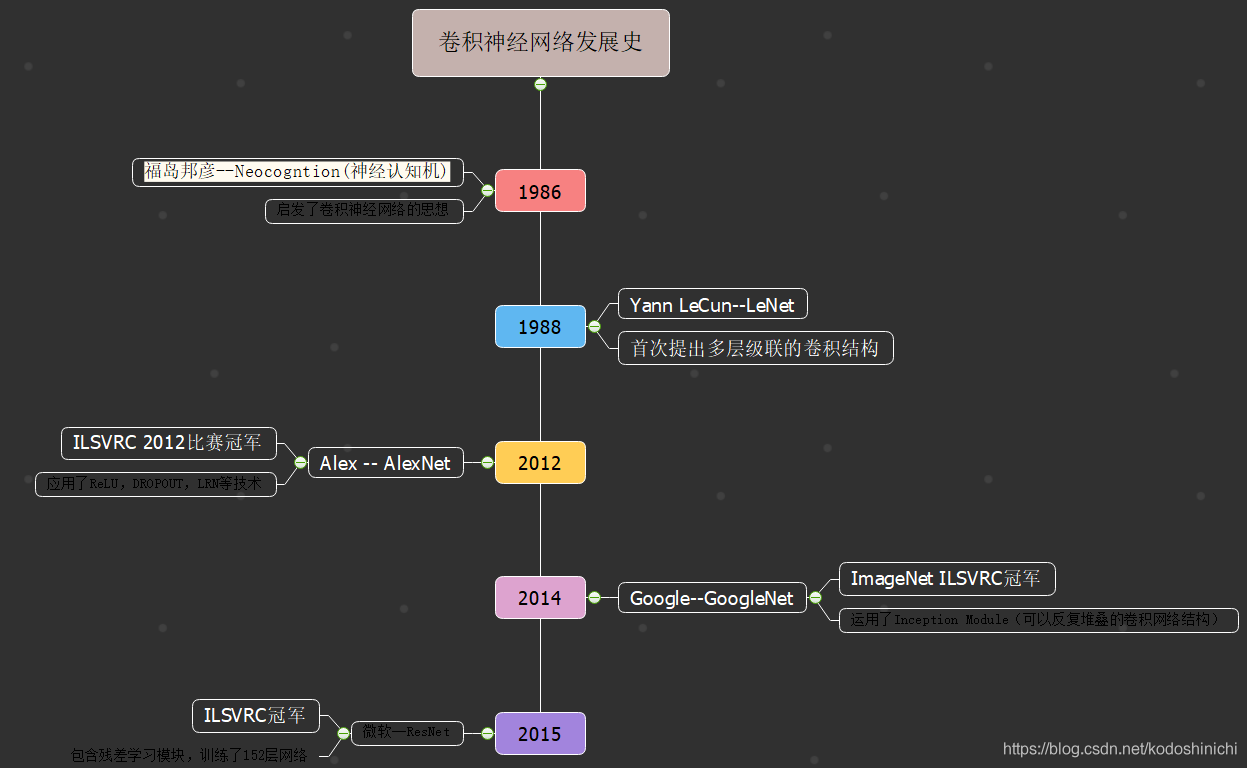
2. Red neuronal convolucional
Debido a que la red neuronal convolucional también se propuso para resolver el problema de la imagen al principio, a menudo usamos el problema de la imagen como ejemplo al explicar su concepto.
(1. Resumen
1. Problemas con las redes completamente conectadas
- Red neuronal completamente conectada: una red neuronal que solo contiene una capa completamente conectada ( todos los nodos en cada dos capas están conectados en pares )
① Gran cantidad de parámetros
Por ejemplo, para una imagen de 200x200 es de entrada, el siguiente número de neuronas en la capa oculta se establece en 10 . 4 meses, toda la estructura de la capa de conexión a la siguiente un total de 200x200x10 . 4 ponderaciones de parámetros.
ps Aquí asumimos: para la entrada de imágenes, se utiliza el procesamiento a nivel de píxeles, es decir, cada unidad de capa de entrada procesa un bloque de píxeles.
② La formación requiere mucho tiempo
Debido a la gran cantidad de parámetros, la eficiencia del entrenamiento es baja cuando se realiza la propagación hacia atrás.
③Ajuste
También es debido a la gran cantidad de parámetros que la cantidad de parámetros es demasiado grande en comparación con los datos etiquetados, lo que puede conducir fácilmente al problema de sobreajuste en el grado de entrenamiento del modelo.
2. Pequeño truco de una red neuronal convolucional
①Conexión local
Cada operación de convolución solo es responsable de procesar una pequeña parte de la imagen y transferir el resultado a la siguiente cuadrícula.
Lo mismo ocurre con una imagen de entrada de 200x200. Bajo conexión local, cada unidad en la capa oculta solo está conectada a la imagen local 4x4 en la imagen. En este momento, el número de parámetros es solo 4x4x10 4 = 1.6x10 5 , que es reducido en comparación con la capa totalmente conectada de 3 órdenes de magnitud.
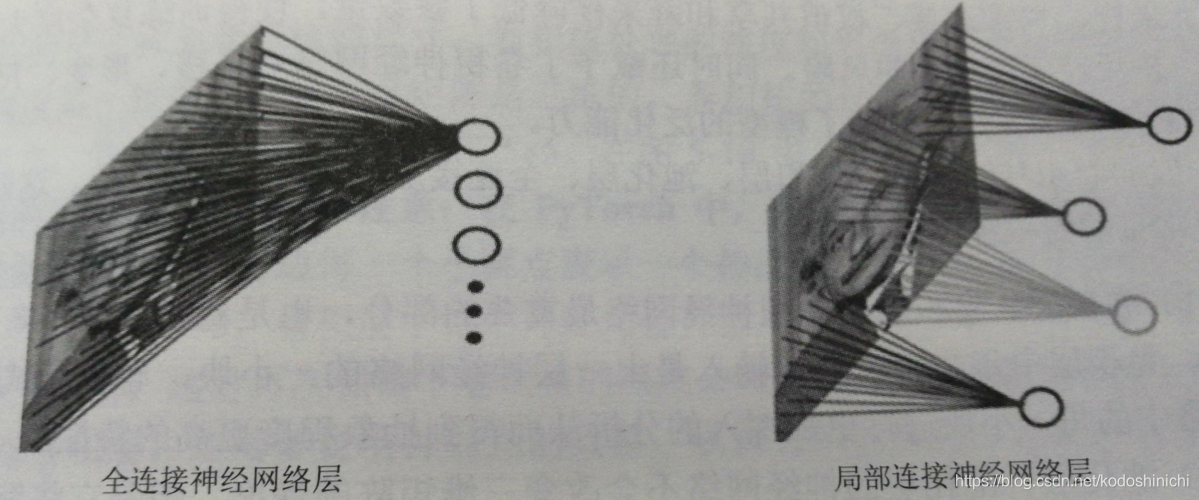
② Peso compartido
- Como comentamos en nuestra conexión local , si hay n neuronas en la capa oculta , y cada neurona solo está conectada a la imagen local mxm de la capa anterior , entonces tendremos n · m 2 parámetros de peso ; bajo la idea de compartir peso , permitimos que cada neurona tenga los mismos parámetros mxm , por lo que no importa cuál sea el número de unidades ocultas n, solo tendremos m 2 parámetros de peso en esta capa .
[Esencia] La
capa de convolución se utiliza para realizar el resultado de la operación de convolución. El núcleo de la operación de convolución es el núcleo de convolución. La función del núcleo de convolución corresponde a la imagen original después de un cierto filtrado para obtener una nueva imagen.
Cada píxel de la nueva imagen se obtiene mediante este núcleo de convolución común. Cada unidad de la capa convolucional se utiliza para almacenar los píxeles de cada nueva imagen, por lo que los parámetros de peso asociados con cada unidad deben ser los mismos.
ps Para obtener conocimientos específicos sobre convolución, consulte la publicación del blog "Wu Enda Deep Learning cnn"
[Kernels y características de
convolución ] Una capa de convolución puede tener varios núcleos de convolución diferentes, y cada capa de convolución es equivalente a extraer una característica de la imagen original sale;
en aplicaciones prácticas, es posible que necesitemos extraer múltiples características, por lo que se puede lograr agregando un kernel de convolución
3. Estructura general de la red neuronal convolucional
- Una red convolucional general consta de una capa convolucional, una capa de agrupación, una capa completamente conectada y una capa Softmax.
[Capa convolucional] La entrada de cada nodo en esta capa es una pequeña parte de la red neuronal de la capa anterior. Ve cada pequeña parte de la red neuronal para un análisis más profundo, obteniendo así un mayor grado de característica de abstracción.
[Capa de agrupación] La red de esta capa no cambiará la profundidad de la matriz tridimensional (por ejemplo, la longitud y el ancho de una imagen RGB reflejan el tamaño de la imagen y la profundidad es de 3 canales), pero sí reducir el tamaño de la matriz. En esencia, esta capa convierte imágenes de mayor resolución en imágenes de menor resolución.
[Capa completamente conectada] Después de múltiples rondas de convolución y agrupación, la red neuronal convolucional conectará de 1 a 2 capas completamente conectadas para entregar el resultado final.
[Capa Softmax] se utiliza para problemas de clasificación, es decir, se seleccionan la función de activación y la función objetivo correspondientes.
La conexión local, el peso compartido y la disminución de resolución de la capa de agrupación reducen la cantidad de parámetros, reducen la complejidad del entrenamiento y reducen el riesgo de sobreajuste; al mismo tiempo, la red neuronal convolucional recibe un cierto grado de resistencia a la traducción, deformación y escala La desnaturalización mejora la capacidad de generalización del modelo.
(2) Capa convolucional
1. Conocimientos básicos
La parte más importante de la estructura de la red neuronal de la capa convolucional es el kernel de convolución (kernel) o también conocido como filtro (filtro). El kernel de convolución transforma una matriz de subnodos en la capa actual de la red neuronal en la siguiente capa de neuronal Red. De una matriz de nodos.

De acuerdo con la figura anterior, cuando usamos redes neuronales convolucionales y operaciones y estructuras de convolución, lo más importante es comprender los parámetros relevantes del kernel de convolución y la configuración relevante de las neuronas.
- El tamaño del kernel de convolución (la longitud y el ancho del kernel de convolución) se especifica manualmente, y el tamaño de la matriz de nodos secundarios de la capa actual de la red neuronal es el tamaño del kernel de convolución.
- La profundidad (de procesamiento) del núcleo de convolución es consistente con la profundidad de la matriz de nodos de la red neuronal de la capa actual.
Cabe señalar que la profundidad del kernel de convolución es a menudo la misma de forma predeterminada.Incluso si la matriz de la capa actual entrante es tridimensional, solo necesitamos especificar manualmente la longitud y el ancho de los dos parámetros.
En términos generales, tomaremos el tamaño del kernel de convolución como 3x3 y 5x5.
En la figura anterior, la matriz correspondiente a la imagen de entrada se muestra a la izquierda, y su tamaño es 3x32x32.
Por lo tanto, si tomamos el tamaño del kernel de convolución como 5x5, entonces El tamaño de cada kernel de convolución debería ser en realidad 3x5x5, y cada neurona en la capa de convolución (la pequeña elipse en el área derecha en la figura de arriba) tendrá el peso del área de 3x5x5 en los datos de entrada, un total de 75 pesos.
ps debe prestar atención al orden de descripción del tamaño de los datos en PyTorch.
- El número de núcleos de convolución, es decir, la profundidad de salida de la capa de convolución, como se muestra en el área derecha de la figura anterior, hay un total de 5 neuronas, correspondientes a 5 núcleos de convolución. El número de núcleos de convolución y el número de filtros utilizados son los mismos.
- La longitud del paso, la longitud del paso deslizante es el número de píxeles que se mueven cada vez durante la operación de convolución.
La operación de convolución deslizante hace que los datos de salida generalmente sean menores.
- El relleno de límites tiene diferentes modos de relleno según sea necesario; cuando todo el relleno es 0, asegúrese de que los datos de entrada tengan el mismo tamaño; si el valor de relleno es mayor que 0, puede garantizar que no se pierda información de límites durante la operación de convolución.
[Fórmula de cálculo de convolución]
El tamaño de salida obtenido después de la operación de convolución se calcula mediante la siguiente fórmula para obtener
W ′ = piso ((W - F + 2 P) / S + 1) W '= piso ((W-F + 2P) / S + 1)W′=f l o o r ( ( W-F+2 P ) / S+1 )
Entre ellos, floor representa la operación de eliminación de números enteros, W representa el tamaño de los datos de entrada, F representa el tamaño del núcleo de convolución en la capa de convolución, S representa el tamaño del paso y P representa el número de rellenos de ceros.
2. Llamadas
en PyTorch Hay un módulo de kernel de convolución especialmente empaquetado en PyTorch. nn.Conv2d()
Su estructura formal de parámetros es la siguiente
nn.Conv2d(in_channels,out_channels,kernel_size,stride = 1,padding = 0,dilation = 1,groups = 1,bias = True)
in_channels: La profundidad del cuerpo de datos de entrada, que está determinada por el tamaño de los datos entrantesout_channels: La profundidad del volumen de datos de salida, generalmente determinada por el número de núcleos seleccionadoskernel_size: El tamaño del kernel de convolución; cuando se usó el kernel de convolución cuadrado, solo se pasó un número; cuando se pasó el kernel de convolución no cuadrado, se pasó una tupla enstride: Longitud del paso deslizante, el valor predeterminado es 1padding: El número de relleno en el límite 0dilation: Ingrese el intervalo de espacio del cuerpo de datosgroups: La profundidad de la relación entre el cuerpo de datos de entrada y el cuerpo de datos de salidabias: Indica el desplazamiento
'''
对PyTorch中的卷积核的调用示例
'''
#方形卷积核,等长的步长
m = nn.Conv2d(16,33,3,stride = 2)
#非方形卷积核,非登场的步长和边界填充
m = nn.Conv2d(16,33,(3,5),stride = (2,1),padding = (4,2))
#非方形卷积核,非登场的步长、边界填充和空间间隔
m = nn.Conv2d(16,33,(3,5),stride = (2,1),padding = (4,2),dilation = (3,1))
#进行卷积运算
input = autograd.Variable(torch.randn(20,16,50,100))
output = m(input)
(3) Capa de agrupación
Por lo general, se inserta una capa de agrupación después de la capa convolucional. Esta capa de red neuronal tiene las siguientes funciones:
- Reducir gradualmente el tamaño del espacio de la red
- Reducir el número de parámetros en la red.
- Reducir el uso de recursos informáticos
- Controle eficazmente el sobreajuste del modelo
En general, existen dos métodos de cálculo para la capa de agrupación, Agrupación máxima y Agrupación media, el primero utiliza el cálculo de [Valor máximo] y el segundo utiliza el cálculo de [valor medio]. El siguiente utiliza Agrupación máxima como ejemplo para analizar.
1. Proceso de cálculo La
capa de agrupación solo realiza un muestreo descendente de las dimensiones de largo y ancho de los datos, y no cambia la profundidad del modelo.
Toma el segmento de profundidad de los datos de entrada como entrada y desliza continuamente la ventana Bajo el principio de cálculo de Max Pooling, el valor máximo en estas ventanas se toma como el resultado de salida.

¿Qué tan efectiva es la capa de agrupación?
- Las características de la imagen tienen invariancia local, es decir, la imagen reducida obtenida después de la reducción de resolución aún no pierde sus características.
En base a esto, la operación de convolución se realiza después de que se reduce la imagen (la llamada operación de convolución consiste en utilizar el núcleo de diseño para extraer las características de la imagen), lo que puede reducir el tiempo de la operación de convolución.
- Usando el esquema de agrupación comúnmente utilizado (el tamaño de la agrupación es 2x2, el tamaño del paso deslizante es 2), el muestreo descendente de la imagen en realidad pierde el 75% de la imagen original, y la mayor parte se selecciona para mantenerla, y el ruido puede también se eliminará.
2. Llamar en PyTorch
Debido a que hay dos esquemas de agrupación diferentes, de manera similar, hay correspondiente
nn.MaxPool2dynn.AvgPool2d
nn.MaxPool2d(kernel_size,stride = None,padding = 0,dilation = 1,
return_indices = False,ceil_mode = False)
- Para los parámetros relacionados, consulte la explicación en la capa convolucional.
return_indices: Si devolver el subíndice del valor máximoceil_model: Use cuadrados en lugar de estructura de capas
Del mismo modo, si el tamaño de agrupación seleccionado es cuadrado, solo necesita pasar un número; de lo contrario, debe pasar una tupla.
3. Red neuronal convolucional clásica
1. LeNet
LeNet se refiere específicamente a LeNet-5, que fue propuesto por el profesor Yann LeCun en el artículo "Aprendizaje basado en gradientes aplicado al reconocimiento de documentos" en 1988. Fue la primera red neuronal convolucional aplicada con éxito a problemas de reconocimiento digital.
El modelo LeNet-5 tiene un total de 7 capas (2 capas convolucionales, 2 capas agrupadas, 2 capas completamente conectadas y una capa de salida)
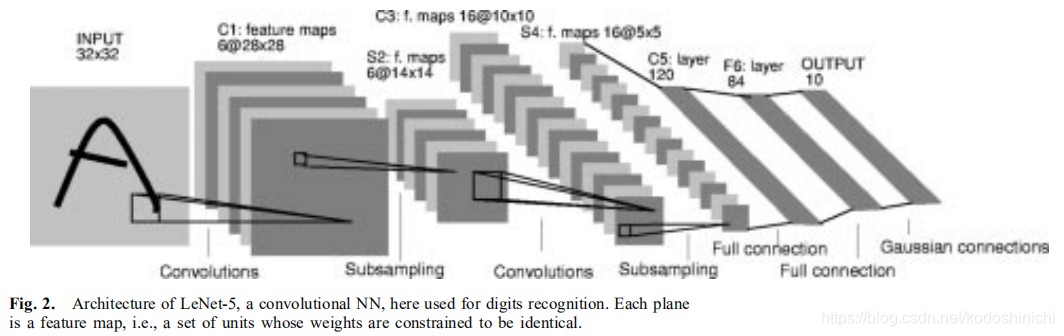
class LeNet(nn.Module):
def __init__(self):
super(LeNet,self).__init__()
self.conv1 = nn.Conv2d(3,6,5)
self.conv2 = nn.Conv2d(6,16,5)
self.fc1 = nn.Linear(16*5*5,120)
self.fc2 = nn.Linear(120,84)
self.fc3 = nn.Linear(84,10)
def forward(self,x):
out = F.relu(self.conv1(x))
out = F.max_pool2d(out,2)
out = F.relu(self.con2(out))
out = F.max_pool2d(out,2)
out = out.view(out.size(0),-1)
out = F.relu(self.fc1(out))
out = F.relu(self.fc2(out))
out = self.fc3(out)
return out
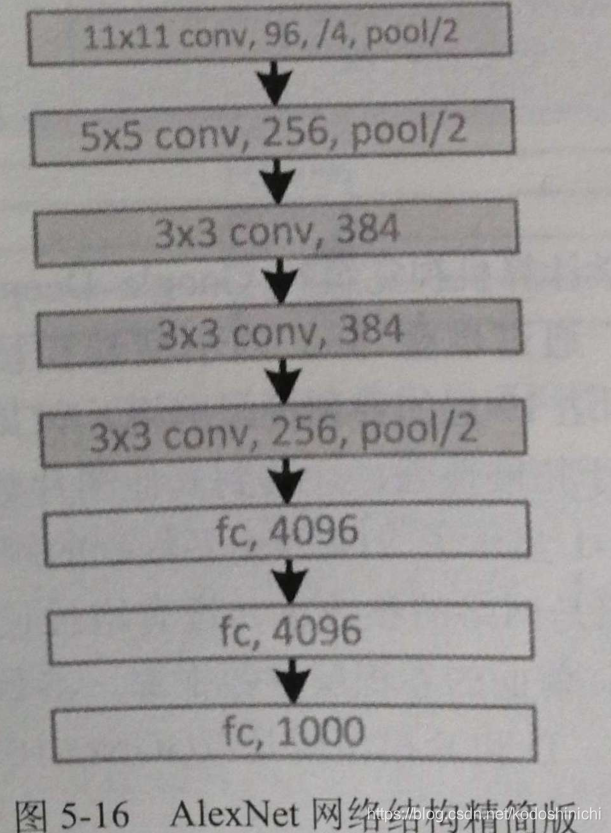
2. AlexNet
Propuesto por el estudiante de Hilton Alex Krizhevsky en 2012; la estructura aplicó con éxito técnicas como Relu, Dropout y LRN.
El diagrama de estructura del modelo AlexNet se muestra a continuación. Debido a las limitaciones de la potencia de cálculo en ese momento, se utilizaron dos GPU para el cálculo en paralelo, por lo que el diagrama de estructura parece un poco complicado.
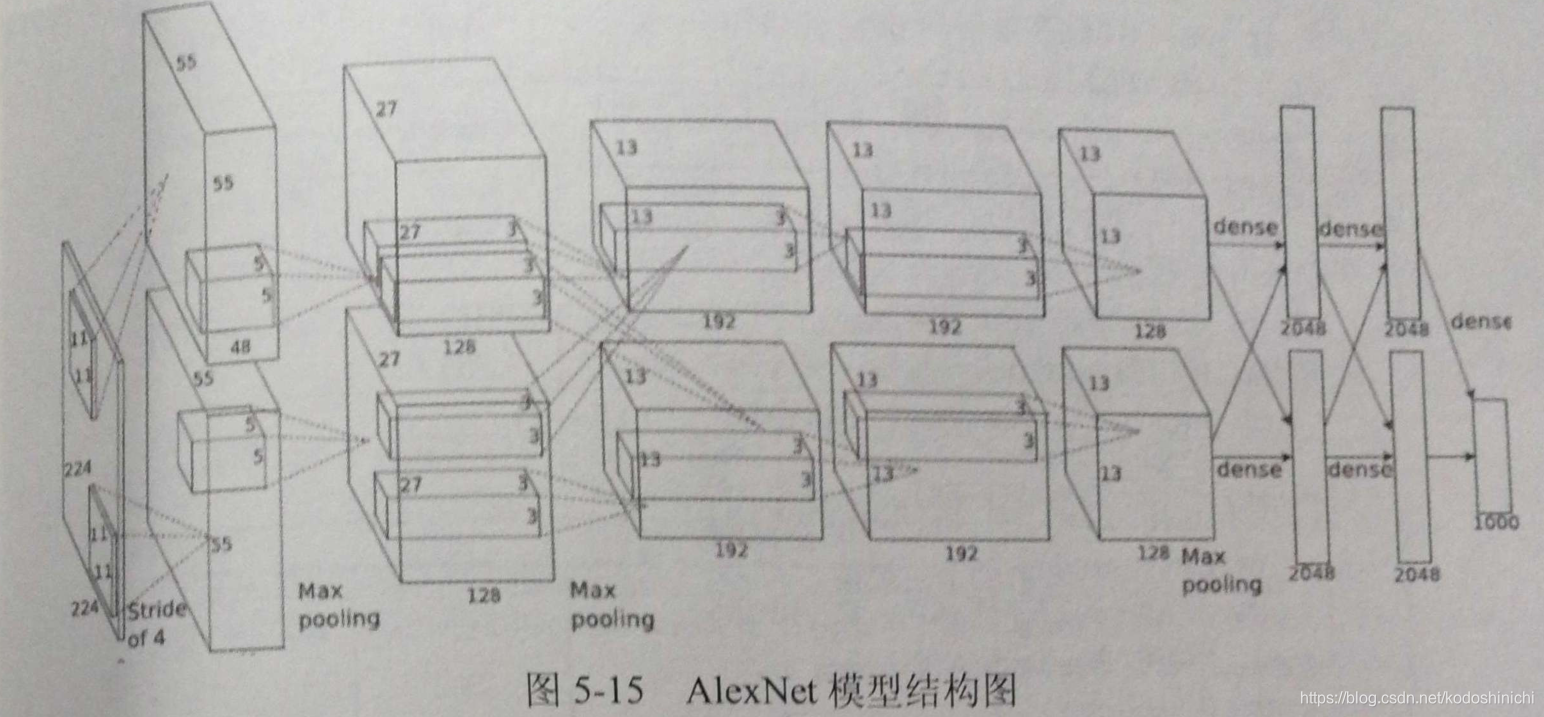
A continuación se muestra el diagrama de estructura del modelo equivalente para un cálculo de una sola GPU
Todo el AlexNet contiene 5 capas convolucionales, 3 capas agrupadas y 3 capas completamente conectadas.
Entre ellos, tanto la capa convolucional como la capa completamente conectada incluyen la capa ReLU, y la capa de abandono también se usa en la capa completamente conectada.
class AlexNet(nn.Module):
def __init__(self,num_classes):
super(AlexNet,self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3,96,kernel_size = 11,stride = 4,padding = 2),
nn.ReLU(inplace = True),
nn.MaxPool2d(kernel_size = 3,stride = 2),
nn.Conv2d(64,256,kernel_size = 5,padding = 2),
nn.ReLU(inplace = True),
nn.MaxPool2d(kernel_size = 3,stride = 2),
nn.Conv2d(192,384,kernel_size = 3,padding = 1),
nn.ReLU(inplace = True),
nn.Conv2d(384,256,kernel_size = 3,padding = 1),
nn.ReLU(inplace = True),
nn.Conv2d(256,256,kernel_size = 3,padding = 1),
nn.ReLU(inplace = True),
nn.MaxPool2d(kernel_size = 3,stride = 2),
)
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256*6*6,4096),
nn.ReLU(inplace = True),
nn.Dropout(),
nn.Linear(4096,4096),
nn.ReLU(inplace = True),
nn.Linear(4096,num_classes)
)
def forward(self,x):
x = self.features(x)
x = x.view(x.size(0),256*6*6)
x = self.classifier(x)
return x