Sobre el Autor
Yiwen, analista de datos de Ctrip, se centra en el crecimiento de usuarios, la inferencia causal, la ciencia de datos y otros campos.
1. Antecedentes
Es muy importante inferir científicamente el efecto de una determinada estrategia de producto en los indicadores observados, lo que puede ayudar a los productos y operaciones a obtener el valor de la estrategia con mayor precisión, para realizar iteraciones y ajustes posteriores en la dirección.
En el marco de la inferencia causal, el estándar de oro para la evaluación de efectos debe ser el "experimento AB", porque la desviación del experimento se considera completamente aleatoria y uniforme. Sobre esta base, una determinada intervención puede reflejarse comparando las diferencias en indicadores entre el grupo experimental y el grupo de control El valor incremental aportado. Sin embargo, en muchos escenarios, nos resulta difícil realizar experimentos AB estrictos, como precios de hoteles, distribución de recompensas en efectivo, etc., y no es adecuado mostrar contenido diferente a diferentes grupos de personas. Para estos problemas, adoptaremos el método de inferencia causal para evaluar el efecto de la estrategia.
Este artículo presenta principalmente el principio del modelo BSTS y la implementación del código del modelo por CausalImpact, con el objetivo de estimar el valor del efecto causal de manera más precisa y científica cuando se enfrentan algunos datos con características periódicas específicas. A continuación, primero se explicará brevemente el principio del modelo, luego se utilizarán datos simulados para demostrar la lógica del código y, finalmente, se practicará en escenarios comerciales específicos.
2. Métodos existentes y problemas potenciales
Cuando la mayoría de las operaciones y productos evalúan los efectos de algunas estrategias completamente lanzadas, la forma más común es observar la diferencia en los efectos antes y después del lanzamiento. Pero el mayor problema de este método es su premisa: se supone que la función en línea es la única variable que afecta el efecto (es decir, no hay otras variables que intervengan y confundan), pero esta suposición a menudo es difícil de realizar en la realidad. .
Así que intentamos utilizar más métodos de inferencia causal, como PSM (Propensity Score Matching), para encontrar un grupo de personas que tengan características muy similares a los usuarios del grupo experimental entre todos los usuarios del grupo no experimental, y comparar los datos de sus indicadores. (como la tasa de realización de pedidos, los ingresos por pedidos, etc.) se comparan con los usuarios del grupo experimental para reflejar el impacto de la intervención. Sin embargo, este método se basa más en las características del usuario seleccionado y el efecto de coincidencia final.
Otro ejemplo es SCM (método de control sintético), que utiliza algunas áreas ininterrumpidas para sintetizar un "área virtual similar" para hacer una comparación general con las "áreas con estrategias en línea". Pero esto también requiere una suposición clave: es posible encontrar áreas con tendencias a largo plazo altamente sincronizadas para comparar, y esta condición a menudo es difícil de lograr.
Además, sobre la base del SCM tradicional, intentamos utilizar un método similar al aprendizaje en conjunto, utilizando múltiples grupos de control sin intervención como valores de entrada y luego combinándolos con las fluctuaciones de series temporales a largo plazo del propio grupo experimental para ajustarlo a un modelo virtual sin intervención. grupo de control, reduciendo así la hipótesis fuerte de que " el grupo de control y el grupo experimental están altamente sincronizados" a una hipótesis débil . El modelo BSTS presentado en este artículo es un modelo de datos que se utiliza para describir una determinada "fluctuación de series de tiempo a largo plazo", y CausalImpact se utiliza para estimar el valor del efecto causal de dichos datos. A continuación presentaremos estas dos herramientas en detalle.
3. Introducción del modelo
El modelo BSTS (Bayesian Structured Time Series) se denomina “Bayesian Structured Time Series”, como su propio nombre indica, sus principales características se reflejan en:
Adecuado para datos de series temporales con características estructurales.
Utilice ideas bayesianas para estimar parámetros
Los datos de series de tiempo estructurados no son infrecuentes en la vida diaria, especialmente en industrias OTA como Ctrip. La situación de los pedidos en la plataforma en realidad tiene un cierto patrón de tiempo. Por ejemplo, los fines de semana y días festivos son los períodos pico de pedidos, a mitad de semana es el pico plano. plazo para pedidos, etc. Por otro lado, el pensamiento bayesiano se refiere a tener algún "conocimiento innato" de los parámetros a estimar antes de obtener los datos de la muestra) y luego, en base a este conocimiento, combinarlos con los datos de la muestra para obtener la distribución posterior (como se muestra a continuación). mostrar)
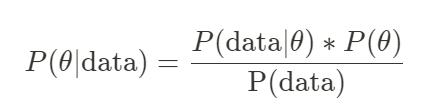
Por lo tanto, el modelo BSTS realiza principalmente ajuste y predicción del modelo en datos de series de tiempo estructurados, y en el proceso de ajuste se utilizan ideas previas bayesianas. La ventaja es que puede proporcionar el intervalo de confianza del valor predicho, haciendo que los resultados de la predicción sean más científicos y creíbles. Estas ideas se presentarán una por una a continuación.
3.1 Modelo de espacio de estados
Los datos de series de tiempo estructurados significan que detrás de ciertos datos de observación, en realidad hay diferentes estados que cambian con el tiempo. Existe una relación correspondiente entre el valor de observación y el valor de estado, y también existe una relación de conversión entre los estados en diferentes momentos. Generalmente utilizamos el siguiente modelo de espacio de estados para describir estas dos lógicas de mapeo:

(1) se llama ecuación de observación, que refleja la relación entre el valor observado y el estado oculto detrás de él; (2) se llama ecuación de estado, que refleja la transición entre estados a lo largo del tiempo. ; 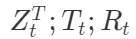 Todas ellas son "matrices de mapeo de relaciones" entre diferentes variables;
Todas ellas son "matrices de mapeo de relaciones" entre diferentes variables; 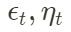 son ruido que es independiente de otras variables y obedece a una distribución normal. La denominada "estructuración" de datos incluye principalmente:
son ruido que es independiente de otras variables y obedece a una distribución normal. La denominada "estructuración" de datos incluye principalmente:
Tendencia local lineal: monotonicidad (aumento o caída monótona) dentro de un cierto período de tiempo
Estacionalidad: un cambio de duración fija, similar a los cambios de temperatura a lo largo del año.
Cíclico: cambios similares a la estacionalidad pero con fluctuación temporal y frecuencia variables.
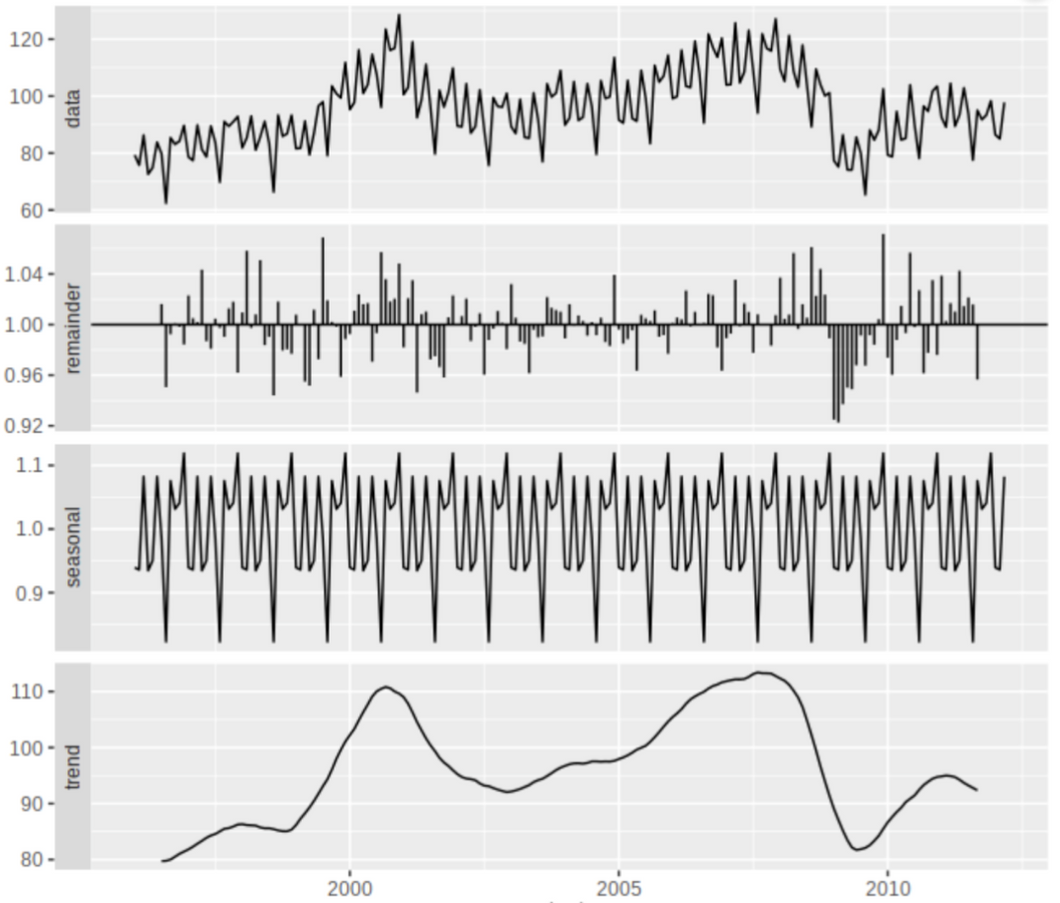
Figura 3-1: Datos de observación y sus elementos estructurales. La primera imagen refleja la fluctuación de los datos originales; la segunda imagen refleja los factores estacionales; y la tercera imagen refleja la tendencia local.
Si desea agregar la covariable X a la relación de mapeo, puede expandir (1) para:
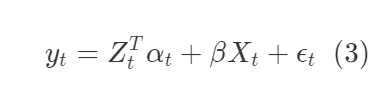
que 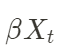 representa la relación entre la covariable Los parámetros de las tres ecuaciones anteriores se estimarán más adelante.
representa la relación entre la covariable Los parámetros de las tres ecuaciones anteriores se estimarán más adelante.
3.2 Bayesiano y MCMC (método de Markov Monte Carlo)
Se supone que la secuencia de estados en cada momento en la ecuación de estado (2) 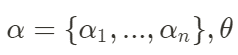 representa todos los parámetros del modelo. Ahora queremos estimar θ. Los pasos principales son los siguientes:
representa todos los parámetros del modelo. Ahora queremos estimar θ. Los pasos principales son los siguientes:
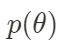 Establecer la distribución previa y la distribución del estado inicial para θ
Establecer la distribución previa y la distribución del estado inicial para θ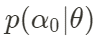
Construir una cadena de Markov y obtenerla mediante el método MCMC

La distribución posterior de parámetros se calcula mediante la fórmula bayesiana.
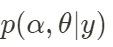
La siguiente es una breve descripción de los métodos utilizados en cada paso:
1) Estimación bayesiana : una característica importante del modelo BSTS es el uso de la estimación bayesiana en la estimación de parámetros, es decir, la distribución previa de los parámetros se proporciona antes de la estimación y luego la distribución posterior de los parámetros se proporciona en función de la muestra. datos. . Los diferentes tipos de parámetros generalmente tienen algunas distribuciones previas de uso común. Por ejemplo, la media generalmente usa la distribución normal, la 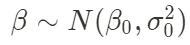 varianza usa la distribución gamma inversa,
varianza usa la distribución gamma inversa, 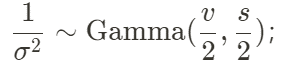 la matriz de covarianza puede usar la distribución IW, etc. Vale la pena señalar que la configuración de la distribución previa afectará la convergencia MCMC posterior y la precisión de la distribución posterior hasta cierto punto, por lo que la distribución previa no se puede establecer de manera demasiado arbitraria y debe derivarse tanto como sea posible en función de la realidad real. datos Elija la distribución previa más adecuada o compare los valores de la distribución posterior y la función de probabilidad bajo cada distribución previa.
la matriz de covarianza puede usar la distribución IW, etc. Vale la pena señalar que la configuración de la distribución previa afectará la convergencia MCMC posterior y la precisión de la distribución posterior hasta cierto punto, por lo que la distribución previa no se puede establecer de manera demasiado arbitraria y debe derivarse tanto como sea posible en función de la realidad real. datos Elija la distribución previa más adecuada o compare los valores de la distribución posterior y la función de probabilidad bajo cada distribución previa.
2) Método MCMC : intentamos construir una cadena de Markov (una secuencia especial en la que el valor de estado en el momento actual solo está relacionado con el valor de estado en el momento anterior, y la secuencia final convergerá a una distribución estable) para que su distribución final La distribución convergente en estado estacionario es la distribución posterior de los parámetros. Podemos realizar este proceso a través del muestreo de Gibbs: después de establecer la distribución previa, comenzando desde el estado inicial 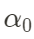 , arregle α y muestree θ cada vez; luego arregle θ y muestree α, actualice gradualmente los dos conjuntos de parámetros una y otra vez, y finalmente forme una línea que obedece a las propiedades de Markov. La distribución de enlaces
, arregle α y muestree θ cada vez; luego arregle θ y muestree α, actualice gradualmente los dos conjuntos de parámetros una y otra vez, y finalmente forme una línea que obedece a las propiedades de Markov. La distribución de enlaces 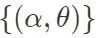 cuya convergencia en estado estacionario puede demostrarse es
cuya convergencia en estado estacionario puede demostrarse es 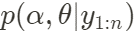 donde
donde 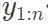 representa todos los datos de observación.
representa todos los datos de observación.
3) Estimación del valor de predicción :  después de obtenerlo, tomamos una muestra de (α, θ) de la distribución y luego lo sustituimos en la ecuación del espacio de estados (1) para predecir y, y obtenemos, donde representa el valor predicho de y después del punto de tiempo n
después de obtenerlo, tomamos una muestra de (α, θ) de la distribución y luego lo sustituimos en la ecuación del espacio de estados (1) para predecir y, y obtenemos, donde representa el valor predicho de y después del punto de tiempo n 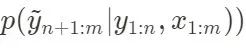 .
.  .
.
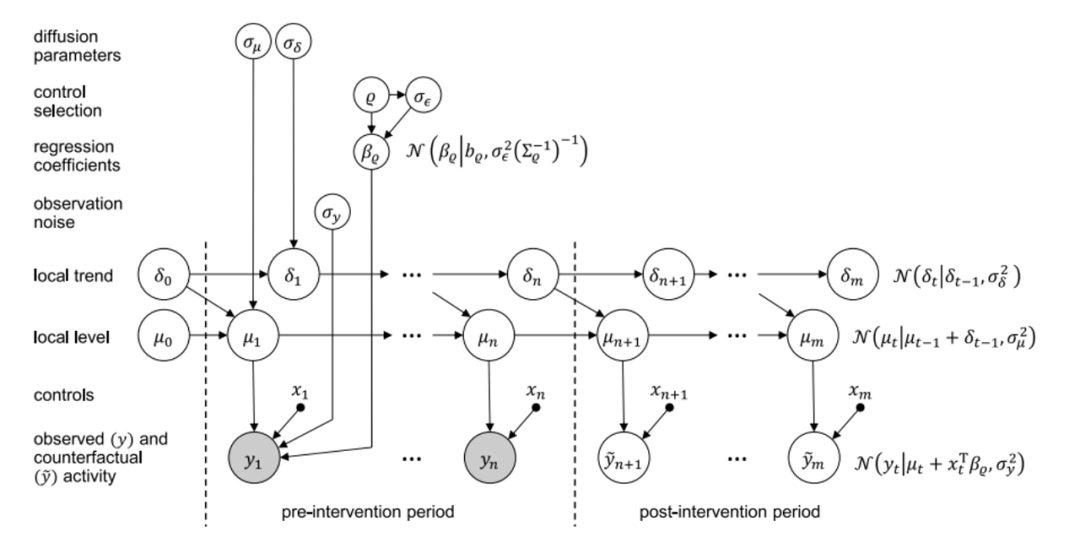 Figura 3-2: Muestra ciertos datos de series de tiempo estructurados y el proceso de cada transición de estado detrás de ellos. El estado α incluye tendencia local:
Figura 3-2: Muestra ciertos datos de series de tiempo estructurados y el proceso de cada transición de estado detrás de ellos. El estado α incluye tendencia local: 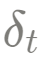 (tendencia local); nivel local:
(tendencia local); nivel local: 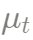 (valor medio de la tendencia local) y covariable x,
(valor medio de la tendencia local) y covariable x, 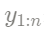 que representa todos los datos observados;
que representa todos los datos observados; 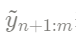 representa los datos pronosticados obtenidos según el modelo estatal.
representa los datos pronosticados obtenidos según el modelo estatal. 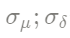 Estos parámetros, representados
Estos parámetros, representados 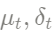 respectivamente por la desviación estándar, son estimados por MCMC.
respectivamente por la desviación estándar, son estimados por MCMC.
4. Aplicación del modelo e implementación del código.
Arriba hemos dado una breve derivación teórica y resultados del modelo BSTS y el método MCMC. El propósito principal es predecir el valor de observación y. A continuación presentaremos cómo aplicar el modelo BSTS en escenarios de inferencia causal.
Al evaluar el efecto de la política, lo que queremos principalmente es el "valor contrafáctico" del objeto de observación, como por ejemplo "¿Cuál sería la situación de navegación del usuario si este anuncio no se publicara?" En comparación con el método tradicional PSM o SCM, BSTS es mejor que el método tradicional PSM o SCM. Puede evaluar el efecto de los datos de series de tiempo y, al mismo tiempo, utiliza la estimación bayesiana para generar la predicción del valor contrafactual y y proporciona el intervalo de confianza del valor predicho. , que puede reducir la volatilidad de la predicción del valor contrafactual hasta cierto punto y mejorar la evaluación del efecto, precisión y estabilidad.
En aplicaciones prácticas, el modelo BSTS se puede implementar a través del paquete CausalImpact de código abierto de Google, que se puede llamar tanto en Python como en R. Para una implementación detallada del código, consulte las referencias [7][8].
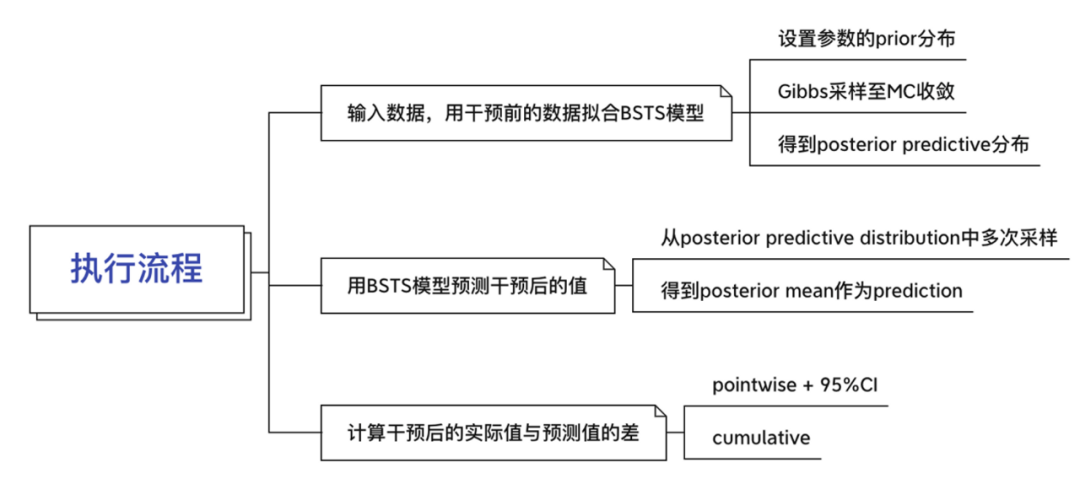
Figura 4-1: Muestra los tres pasos al ejecutar el código: entrenar el modelo BSTS; predecir valores contrafactuales; y calcular el valor del efecto causal, incluidas estimaciones puntuales e intervalos de confianza del valor del efecto.
4.1 Implementación del código
Los comandos específicos del código se muestran a continuación a través de datos simulados.
import tensorflow as tf
import tensorflow_probability as tfp
from causalimpact import CausalImpact
# 模型初始化 - 自定义时间序列数据:
def plot_time_series_components(ci):
component_dists = tfp.sts.decompose_by_component(ci.model, ci.observed_time_series, ci.model_samples)
num_components = len(component_dists)
mu, sig = ci.mu_sig if ci.mu_sig is not None else 0.0, 1.0
for i, (component, component_dist) in enumerate(component_dists.items()):
component_mean = component_dist.mean().numpy()
component_stddev = component_dist.stddev().numpy()
# 自定义观测方程以及真实值y:
def plot_forecast_components(ci):
component_forecasts = tfp.sts.decompose_forecast_by_component(ci.model, ci.posterior_dist, ci.model_samples)
num_components = len(component_forecasts)
mu, sig = ci.mu_sig if ci.mu_sig is not None else 0.0, 1.0
for i, (component, component_dist) in enumerate(component_forecasts.items()):
component_mean = component_dist.mean().numpy()
component_stddev = component_dist.stddev().numpy()
# 生成模拟数据,包括一个实验组数据(有干预)以及两条对照组数据(无干预)
observed_stddev, observed_initial = (tf.convert_to_tensor(value=1, dtype=tf.float32),tf.convert_to_tensor(value=0., dtype=tf.float32))
level_scale_prior = tfd.LogNormal(loc=tf.math.log(0.05 * observed_stddev), scale=1, name='level_scale_prior') # 设置先验分布
initial_state_prior = tfd.MultivariateNormalDiag(loc=observed_initial[..., tf.newaxis], scale_diag=(tf.abs(observed_initial) + observed_stddev)[..., tf.newaxis], name='initial_level_prior') # 设置先验分布
ll_ssm = tfp.sts.LocalLevelStateSpaceModel(100, initial_state_prior=initial_state_prior, level_scale=level_scale_prior.sample()) #训练时序模型
ll_ssm_sample = np.squeeze(ll_ssm.sample().numpy())
# 整合数据
x0 = 100 * np.random.rand(100) # 对照组1
x1 = 90 * np.random.rand(100) # 对照组2
y = 1.2 * x0 + 0.9 * x1 + ll_ssm_sample #生成真实值y
y[70:] += 10 #设置干预点
data = pd.DataFrame({'x0': x0, 'x1': x1, 'y': y}, columns=['y', 'x0', 'x1'])
Figura 4-2: Mostrando datos simulados. La línea de puntos representa el momento en que ocurrió la intervención, la línea azul representa los datos de observación que recibieron la intervención; la línea amarilla y la línea verde representan los datos de control de los dos grupos que no recibieron la intervención.
# 调用模型:
pre_period = [0, 69] #设置干预前的时间窗口
post_period = [70, 99] #干预后的窗口
ci = CausalImpact(data, pre_period, post_period) #调用CausalImpact
# 对于causalImpact的使用我们核心需要填写三个参数:观测数据data、干预前的时间窗口、干预后的时间窗口。
# 输出结果:
ci.plot()
ci.summary()图4-3:展示CausalImpact输出的结果图,图1表示真实值与模型拟合值的曲线;图2表示每个时刻真实值与预测值的差异;图3表示真实值与预测值的累计差值。表3-1:展示CausalImpact输出的结果表格,量化效应值effect的估计及其置信区间,反映效应值是否具有显著性。107.71表示干预之后实际值的平均;96.25表示干预之后预测值的平均,3.28表示估计的标准差,[89.77,102.64]表示反事实估计的置信区间。11.46表示实际值与预测值的差距,[5.07,17.94]表示差值的置信区间,由于差距的置信区间在0的右侧,表示干预有显著的提升作用。
Figura 4-3: Muestra el gráfico de resultados generado por CausalImpact. La Figura 1 muestra la curva entre el valor real y el valor de ajuste del modelo, la Figura 2 muestra la diferencia entre el valor real y el valor predicho en cada momento y la parte sombreada en naranja. muestra el intervalo de confianza; la Figura 3 muestra el valor real La diferencia acumulada entre el valor y el valor predicho.
 Tabla 3-1: Muestra la tabla de resultados generada por CausalImpact, cuantificando la estimación del valor del efecto y su intervalo de confianza, reflejando si el valor del efecto es significativo. 107,71 representa el promedio de los valores reales después de la intervención; 96,25 representa el promedio de los valores predichos después de la intervención, 3,28 representa la desviación estándar estimada y [89,77,102,64] representa el intervalo de confianza de la estimación contrafactual. 11.46 representa la diferencia entre el valor real y el valor predicho, y [5.07, 17.94] representa el intervalo de confianza de la diferencia. Dado que el intervalo de confianza de la brecha está en el lado derecho de 0, significa que la intervención tiene un impacto significativo. efecto de mejora.
Tabla 3-1: Muestra la tabla de resultados generada por CausalImpact, cuantificando la estimación del valor del efecto y su intervalo de confianza, reflejando si el valor del efecto es significativo. 107,71 representa el promedio de los valores reales después de la intervención; 96,25 representa el promedio de los valores predichos después de la intervención, 3,28 representa la desviación estándar estimada y [89,77,102,64] representa el intervalo de confianza de la estimación contrafactual. 11.46 representa la diferencia entre el valor real y el valor predicho, y [5.07, 17.94] representa el intervalo de confianza de la diferencia. Dado que el intervalo de confianza de la brecha está en el lado derecho de 0, significa que la intervención tiene un impacto significativo. efecto de mejora.
4.2 Verificación del modelo
Para obtener los resultados del ajuste del modelo, debemos realizar una "verificación AA" similar al experimento AB. Generalmente, puede utilizar la segunda imagen en los resultados ilustrados para observar si el intervalo de confianza de la diferencia entre el valor verdadero y el valor predicho antes de la intervención contiene 0. Si contiene 0, significa que la prueba pasó y el modelo El efecto de ajuste es bueno. En la figura anterior, todos los intervalos de confianza contienen 0, lo que indica que el modelo está disponible.
4.3 Ajuste del modelo
Parámetros del proceso : podemos usar la descomposición en Tensorflow para ver varios elementos estructurales en el modelo de series de tiempo, incluida la periodicidad/estacionalidad, etc.
seasonal_decompose(data)
La Figura 4-4 muestra los elementos de estado detrás de los datos generados. La primera imagen refleja la tendencia de los datos originales; la segunda imagen refleja el factor de tendencia local; y la tercera imagen refleja el factor estacional. Se puede observar que los datos tienen una estructura estacional y una tendencia ascendente monótona.
Parámetros personalizados : Podemos personalizar la distribución previa de parámetros; el número de iteraciones; la duración de la ventana de tiempo periódica, etc. Los ajustes de parámetros a menudo tienen un impacto en la salida del resultado. Por ejemplo, seleccionar correctamente la distribución previa hará que los resultados sean más precisos; más iteraciones pueden garantizar que MCMC converja de manera más estable (pero también puede llevar a un tiempo de ejecución del modelo más largo), etc. El más importante de ellos es el establecimiento de la duración de la ventana de tiempo , que debe reflejar correctamente la periodicidad de los datos de observación. Si los datos de la dimensión anual se basan en semanas, establezca nestons=52; si los datos de la dimensión diaria se basan en horas, establezca nestons=24, etc.
CausalImpact(..., model.args = list(niter = 20000, nseasons = 24))
La Figura 4-5 muestra el significado de cada parámetro en el paquete CausalImpact y su valor predeterminado.
Modelo de tiempo personalizado : el paquete causalImpact utiliza el modelo BSTS para el entrenamiento de forma predeterminada. También podemos cambiar a otros modelos de tiempo, pero la premisa es que los datos deben estar estandarizados . (La normalización no es necesariamente necesaria si se utiliza el BSTS predeterminado)
from causalimpact.misc import standardize
normed_data, _ = standardize(data.astype(np.float32)) #标准化数据
obs_data = normed_data.iloc[:70, 0]
# 使用tfp中的其他模型来训练时序数据
linear_level = tfp.sts.LocalLinearTrend(observed_time_series=obs_data)
linear_reg = tfp.sts.LinearRegression(design_matrix=normed_data.iloc[:, 1:].values.reshape(-1, normed_data.shape[1] -1))
model = tfp.sts.Sum([linear_level, linear_reg], observed_time_series=obs_data)
# 将自义定时序模型代入CausalImpact包中
ci = CausalImpact(data, pre_period, post_period, model=model)5. Práctica de escenarios empresariales
El marketing de usuarios es una forma importante de promover la retención y la conversión. Entre ellos, llegar a los usuarios con mensajes es un método central, especialmente presionando a los usuarios durante el período pico de compra de boletos durante las vacaciones. Los métodos incluyen push en el sitio y suscripción a miniprogramas en WeChat. Mensajes del ecosistema, cuentas públicas o microambientes corporativos, etc. El propósito incluye, entre otros, recordar a los usuarios que compren boletos, promover funciones de la marca, emitir cupones para atraer a los usuarios a realizar conversiones, etc. Después de las vacaciones, esperamos evaluar la efectividad de este alcance de marketing.
Este es un escenario típico que no es adecuado para los experimentos AB. En primer lugar, debido a que los días festivos son períodos de mayor tráfico, si el 50% de los usuarios están estrictamente reservados y no se alcanzan, se puede perder un lote de usuarios potenciales convertidos; si el grupo de control en su lugar, se reserva un número muy pequeño de personas, como el grupo de control: grupo experimental = 1: 9, tendrá un impacto en la naturaleza científica de las comparaciones de conversión posteriores. En segundo lugar, las estrategias de push durante las vacaciones suelen ser muy refinadas, con un total de decenas de mensajes, lo que nos resulta difícil garantizar la "pureza" de los usuarios en el grupo de control y los usuarios pueden verse cruzados.
Debido a varios problemas, nos resulta difícil evaluar el efecto de conversión del método AB tradicional. Por lo tanto, consideramos utilizar la inferencia causal para resolver este problema. Las opciones generales y los posibles problemas son los siguientes:
Si usa PSM, necesita encontrar usuarios en el mercado que sean similares al grupo de inserción pero que no hayan sido incluidos como grupo de control. Sin embargo, generalmente existe una estrategia de encubrimiento al presionar durante las vacaciones, que cubre casi a más del 95% de los usuarios de la plataforma, es difícil encontrar personas que cumplan con las condiciones pero que no hayan sido presionadas para comparar.
Si utilizamos SCM, nos resulta más difícil encontrar un grupo de control adecuado para sintetizar. Por ejemplo, al evaluar el efecto de impulso de la BU de vacaciones, es poco probable que utilicemos varias líneas de producción, como trenes, boletos de avión, hoteles, etc., para sintetizar una "BU de vacaciones virtual", porque las necesidades de los usuarios de cada línea de producción son diferentes. Utilizar un grupo de control virtual sintetizado de este tipo para comparar tasas de conversión de pedidos de vacaciones no es lo suficientemente científico.
Lo mismo ocurre con DID: nos resulta difícil encontrar un grupo de control que satisfaga el supuesto de tendencia paralela y tenga escenarios comerciales similares para comparar antes y después del impulso.
En resumen, incluso si algunos métodos tradicionales de inferencia causal son técnicamente viables, todavía carecen de explicación empresarial. Además, ninguno de los tres métodos anteriores tiene en cuenta la "periodicidad temporal" del comportamiento de compra de billetes de los usuarios. Por lo tanto, incluso si se sintetiza el grupo de control, es posible que no pueda coincidir con las verdaderas características estructurales del grupo experimental, lo que conducirá a un cálculo sesgado del valor del efecto. Así que primero consideramos verificar la periodicidad de los datos de compra de boletos de los usuarios; después de localizar el patrón periódico, intentamos usar el modelo BSTS combinado con CausalImpact para predecir valores contrafactuales. A continuación, elegimos el escenario de impulso de marketing de billetes de tren del Dragon Boat Festival 2022 para practicar.

La Figura 5-1 muestra diferentes estrategias de promoción para llegar a los usuarios durante el Dragon Boat Festival.
5.1 Selección de datos
Usamos la hora como ventana de período y a través de una simple imagen podemos ver que el número de pedidos de billetes de tren en el mercado sí muestra una cierta tendencia fija a lo largo del tiempo.
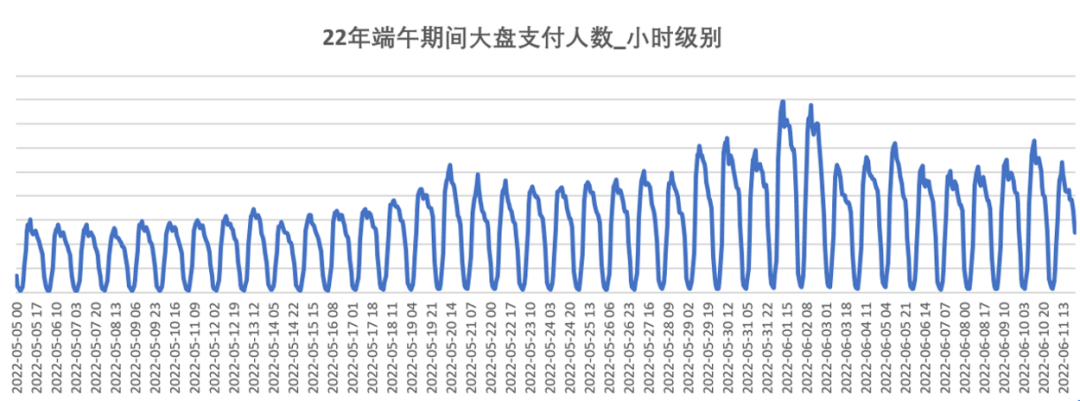
La Figura 5-2 muestra el número de pagadores de boletos de tren por hora durante el período seleccionado del Dragon Boat Festival (10 días antes y después del Dragon Boat Festival).
Teniendo en cuenta el crecimiento natural del tráfico del Dragon Boat Festival como feriado en sí, el aumento en el número de pagadores no puede atribuirse completamente al impulso. Por lo tanto, al entrenar el modelo de series de tiempo, todos los datos del Dragon Boat Festival del 19 al 21 años (10 años antes y después del Dragon Boat Festival). días), ingrese el modelo BSTS para entrenamiento para obtener el estado estructural único dentro de la ventana del Dragon Boat Festival, y luego use este modelo estructurado para sustituir 22 años de Dragon Boat Festival. Datos del festival para predecir la cantidad de conversiones después del impulso del Dragon Boat Festival en 2022.
Finalmente, la diferencia entre el número real de personas convertidas y el número previsto de personas se utiliza para reflejar el efecto de este impulso de marketing.
5.2 Implementación del código R
# 选取19-22年每年的端午窗口,按照小时划分,共960个数据点
y_hour=c(x1,x2,x3,x4)
x_time_hour=c(1:960)
data_hour <- cbind(y_hour, x_time_hour)
pre.period <- c(1, 808) # 2022年的推送发生在第808个时间点,故以此为干预节点。
post.period <- c(809, 960)
# nseasons=24, 迭代次数2000,fit the model
impact_hour <- CausalImpact(data_hour, pre.period, post.period, model.args = list(niter = 20000, nseasons = 24))
summary(impact_hour)
plot(impact_hour)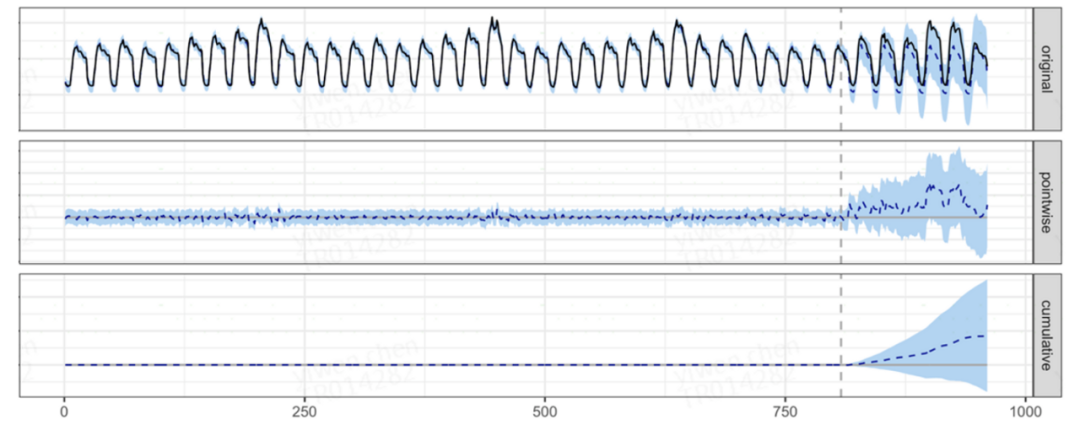
La Figura 5-3 muestra el gráfico de resultados devuelto mediante CausalImpact. La primera imagen muestra el número real de pagadores y el número previsto de pagadores; la segunda imagen muestra la diferencia entre el valor real y el valor previsto y el intervalo de confianza; la tercera imagen muestra la diferencia acumulada y el intervalo de confianza.
La imagen muestra que el modelo puede pasar la verificación AA y el modelo es válido. Después del punto de intervención, el valor real mejora en comparación con el valor previsto, pero el intervalo de confianza de la mejora contiene 0, por lo que no alcanza un nivel significativo. Muestra que la estrategia de marketing del Dragon Boat Festival 2022 tiene un cierto efecto en el número de conversiones, pero el efecto no es significativo.
6. Ventajas y desventajas de los métodos.
En comparación con los métodos tradicionales de inferencia causal, el modelo BSTS tiene dos ventajas principales:
Ser capaz de identificar las características estructurales detrás de los datos y hacer mejores predicciones;
La idea de estimación bayesiana se utiliza para obtener la distribución posterior de los parámetros y se puede dar el intervalo de confianza al calcular el valor del efecto. Pero el punto (2) es un "arma de doble filo" para el modelo BSTS: si la distribución previa no se establece bien, afectará la velocidad y dirección de convergencia de MCMC e incluso la distribución posterior final. Por tanto, la selección de la distribución previa debe ser cautelosa.
7. Expansión del método
El modelo de series de tiempo estructurado presentado en este artículo divide las características periódicas de los datos en elementos de tendencia, elementos estacionales, elementos periódicos, etc., y cada elemento se explora uno por uno. Además, podemos dividir la serie temporal según la duración de la periodicidad y dividirla en elementos de período largo (usando una ventana deslizante grande), elementos de período corto (usando una ventana deslizante pequeña), elementos estacionales, etc. La ventaja de esto es evitar que las condiciones periódicas dentro de algunas ventanas pequeñas se suavicen con información de períodos largos y puede reflejar mejor las características periódicas de los datos en diversos grados. La ecuación específica se puede dividir en la siguiente forma:
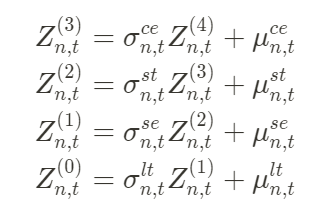
que  representa los valores de estado en diferentes puntos de tiempo; los 4 módulos representan ítems de período largo/ítems de período corto/ítems estacionales/ítems de correlación serial (con covariable X) respectivamente; cada módulo estructural tiene una media y una desviación estándar.
representa los valores de estado en diferentes puntos de tiempo; los 4 módulos representan ítems de período largo/ítems de período corto/ítems estacionales/ítems de correlación serial (con covariable X) respectivamente; cada módulo estructural tiene una media y una desviación estándar.
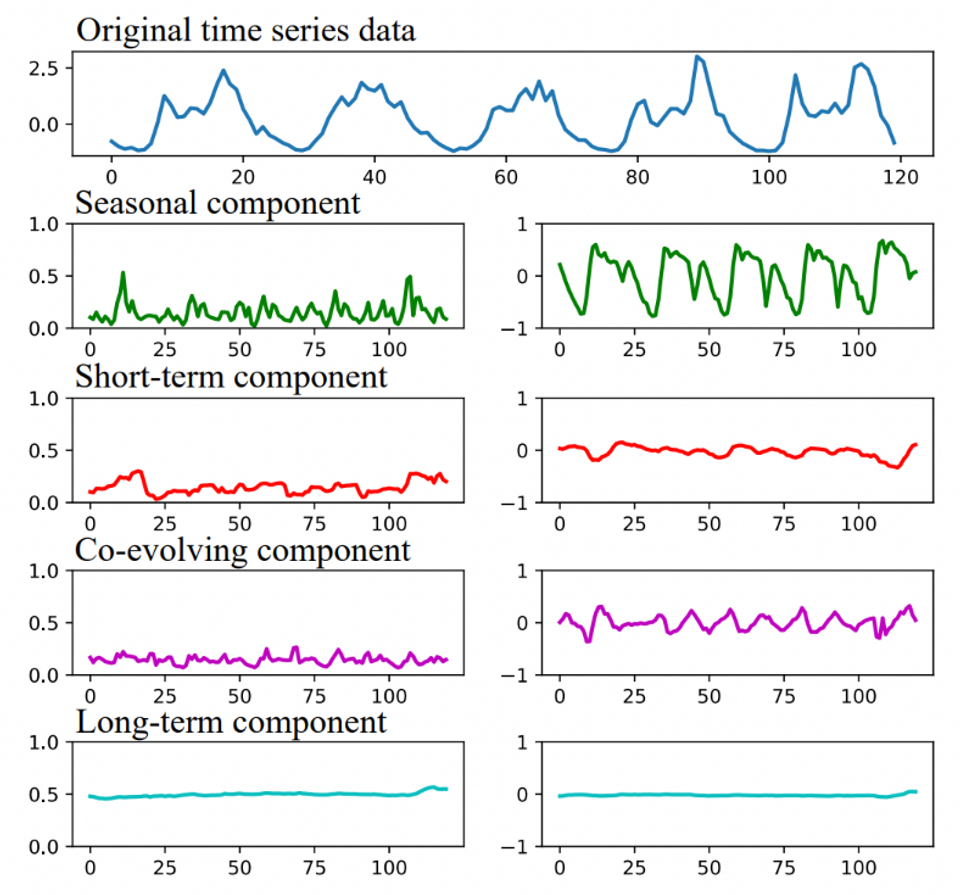
La Figura 7-1 muestra los cuatro módulos detrás de una determinada serie de tiempo: de arriba a abajo: situación de los datos originales; factores estacionales; ítems de período corto; ítems de correlación; y ítems de período largo. Las fluctuaciones de los datos son más obvias en el período corto, y menos obvias en el período largo, por lo que es necesario tener en cuenta la estructura de los datos en el período corto para evitar que los datos del período largo la suavicen.
A continuación, los cuatro módulos anteriores se predicen por separado. Para períodos largos y estacionales, dado que no cambian mucho en un período corto de tiempo, μ y σ en las ecuaciones correspondientes se pueden usar directamente para la predicción; para términos de períodos cortos y términos de correlación, se pueden usar otros métodos de aprendizaje automático para la predicción. . Después de obtener los resultados de predicción de cada módulo, las características de cada módulo se combinan para obtener el resultado de predicción general. La referencia [4] ofrece métodos de predicción más específicos y resultados de comparación con los métodos tradicionales.

La Figura 7-2 muestra diferentes métodos de pronóstico para períodos largos y cortos: los artículos de período largo y los artículos estacionales se pueden expresar directamente como μ para la predicción; los artículos de período corto y relacionados con covariables se predicen utilizando un modelo de aprendizaje automático personalizado.
Después de obtener el modelo de predicción de series de tiempo de acuerdo con el método anterior, lo sustituimos en el código CausalImpact y ajustamos el modelo de parámetros a un modelo de series de tiempo personalizado.
8. Resumen
Este artículo presenta el método de inferencia causal para evaluar el efecto de una determinada política en datos de series de tiempo, utiliza el modelo de espacio de estados de BSTS para predecir valores contrafactuales y lo implementa a través del código de CausalImpact.
A diferencia del marco de otros métodos de inferencia causal, el método de este artículo realiza una estimación bayesiana de todos los hiperparámetros y luego realiza un muestreo MC en la distribución posterior para obtener valores predichos contrafactuales. La principal ventaja es que puede tener en cuenta todos los grupos de control. en la mayor medida Además de las características estructurales del propio grupo experimental, se dan estimaciones de los valores predichos contrafactuales y los intervalos de confianza para medir la importancia del valor del efecto.
Al mismo tiempo, el método presentado en este artículo se centra principalmente en datos de series de tiempo estructurados, utilizando el modelo BSTS para identificar los valores de estado detrás de los datos de observación y la transformación entre cada estado, y luego eliminar tantos problemas como sea posible. causado por estados ocultos al realizar predicciones contrafactuales.Influencia.
Cabe señalar que antes de utilizar el modelo BSTS, es necesario verificar si los datos realmente tienen características periódicas y cuáles son los elementos estructurales (si es un período largo o corto, etc.), y luego seleccionar un modelo de serie de tiempo apropiado. para el entrenamiento; al mismo tiempo, para los parámetros a priori, la configuración de distribución también debe establecerse cuidadosamente para que la estimación del efecto final sea lo más científicamente estable posible.
[Lectura recomendada]
Ahorro del 60% del tiempo de desarrollo, la implementación del sistema de almacenamiento de datos integrado fuera de línea en Ctrip Travel
Acelere 10 veces +, la plataforma indicadora StarRocks está implementada en los boletos de tren Ctrip
Construcción y aplicación del linaje de datos Ctrip.
La evolución de la gobernanza del sistema de registro Ctrip

Cuenta pública “Tecnología Ctrip”
Compartir, comunicar, crecer