Adaptación de dominio de conjunto abierto con modelos básicos de lenguaje visual Notas de lectura en papel
escribir delante
Es fin de semana otra vez, el tiempo en casa parece pasar volando y puedo volver a la escuela la próxima semana ~
- Dirección del artículo: Adaptación de dominios de conjunto abierto con modelos básicos del lenguaje visual
- Dirección de código: la versión actual aún no proporciona una dirección de código
- Presentación prevista en: CVPR 2024
- Ps: Notas de lectura para una publicación de blog cada semana en 2023. Más información útil en la página de inicio . Bienvenido a seguirme. Espero su participación entre los 5000 fanáticos ~
1. Resumen
La adaptación de dominio no supervisada es útil en la transferencia de conocimientos. Debido a la falta de etiquetas de dominio de destino y la existencia de algunas categorías desconocidas, la adaptación de dominio de conjunto abierto (ODA) es una buena solución. Los métodos ODA existentes tienen como objetivo resolver el problema de la transferencia de distribución de los dominios de origen y de destino, mientras que la mayoría de los métodos ajustan los modelos de dominio de origen entrenados en ImageNet. Los modelos básicos de lenguaje visual (VLFM) recientes, como CLIP, son sólidos para la mayoría de las distribuciones de migración y deberían mejorar intuitivamente el rendimiento de ODA. Por lo tanto, este artículo explora una forma más general de aplicar CLIP a la AOD. La capacidad predictiva del disparo cero se investiga utilizando CLIP y luego se propone una estrategia de optimización de entropía cruzada para ayudar al modelo ODA. El experimento funcionó muy bien.
2. Introducción
Para obtener datos etiquetados a gran escala, la adaptación de dominio no supervisada (UDA) transfiere conocimiento en el dominio de origen etiquetado al dominio de destino no etiquetado. Las técnicas tradicionales de adaptación de dominios suponen que el dominio de origen y el dominio de destino comparten las mismas categorías. Sin embargo, la mayoría de los dominios de destino tienen clases que son desconocidas en el dominio de origen. Esta tarea se denomina adaptación de dominio de conjunto abierto (ODA).
El principal desafío de la AOD es la necesidad de identificar clases desconocidas durante la fase de formación. Los métodos ODA existentes generalmente inicializan los pesos con modelos previamente entrenados en ImageNet y luego los ajustan en el dominio objetivo. Por lo tanto, el rendimiento de estos métodos depende en gran medida de la calidad del modelo previamente entrenado y del grado de cambio de distribución entre los dos dominios.
Los modelos básicos de lenguaje visual (VLFM) previamente entrenados en conjuntos de datos a gran escala, como CLIP, tienen sólidas capacidades de generalización, por lo que este artículo utiliza CLIP para ODA. Primero, investigamos la solidez de CLIP en diferentes conjuntos de datos de AOD y luego nos centramos en la capacidad de disparo cero de CLIP en AOD. Este artículo encontró que cuando la muestra objetivo en el dominio objetivo se considera una muestra conocida, la salida de CLIP tiene una entropía cruzada muy baja, y cuando se considera una muestra desconocida, tiene una entropía cruzada muy alta. Para implementar ODA, los datos del dominio de origen se utilizan para entrenar otro modelo de clasificación de imágenes, llamado modelo ODA. Para las muestras conocidas detectadas en el dominio objetivo, el conocimiento de predicción de CLIP se destilará en el modelo ODA, por lo que el conocimiento de CLIP puede ayudar a adaptarse a las muestras conocidas en el dominio objetivo. Para las muestras desconocidas detectadas en el dominio objetivo, al maximizar la entropía cruzada del modelo ODA, el modelo ODA se entrena para generar predicciones de baja confianza y estas muestras desconocidas se separarán aún más. La estrategia de optimización de entropía cruzada se utiliza para integrar la salida de CLIP para proporcionar características discriminativas ricas para el modelo ODA.
Además, el método de este artículo se puede aplicar a ODA independiente del dominio de origen, es decir, ODA sin origen (SF-ODA), en el que la adaptación de muestras del dominio de destino solo requiere el modelo ODA, sin datos del dominio de origen.
Las contribuciones son las siguientes:
- La investigación encontró el desempeño de la predicción de tiro cero de CLIP en problemas de AOD;
- Se propone una estrategia de optimización de entropía cruzada para la predicción CLIP, mejorando así la capacidad de clasificación del modelo ODA en muestras conocidas y muestras desconocidas;
- El método propuesto no sólo puede resolver la AOD, sino que también puede utilizarse para SF-ODA y funciona bien en varios conjuntos de datos.
La siguiente figura es un diagrama conceptual de estos métodos (Para ser honesto, no entiendo muy bien esta imagen y no fue citada en el artículo.):

3. Trabajo relacionado

3.1 Adaptación al dominio abierto
Las etiquetas del dominio de origen y del dominio de destino se establecen en C s C_s respectivamente.Csy C t C_tCt, C s = C t C_s=C_t en UDA de adaptación de dominio no supervisadoCs=Ct. En la categoría objetivo desconocida, C s C_sCses C t C_tCtUn subconjunto de , por lo que se propuso la AOD para resolver este tipo de problema de desajuste de categorías.
Una forma de resolver ODA es utilizar los pesos de las muestras de los dominios de origen y de destino en una red adaptativa no supervisada y utilizar datos de etiquetas del dominio de origen para minimizar la pérdida de entropía cruzada para entrenar un clasificador uno a uno para cada categoría.
3.2 Adaptación de dominio abierto independiente del dominio de origen
Durante la capacitación, todos los métodos UDA y ODA requieren la participación de muestras del dominio de origen y del dominio de destino. Sin embargo, este método obviamente no es aplicable a escenarios en los que no se pueden proporcionar etiquetas de dominio de origen, o a algunos escenarios de implementación en tiempo real. Por lo tanto, parte de la literatura propone congelar el módulo clasificador del dominio de origen y, en su lugar, aprender módulos extractores de características específicas de tareas, como SHOT, USFDA y OneRing para implementar SF-ODA.
3.3 Modelo Básico Visión-Lenguaje VLFM
Los modelos de preentrenamiento a gran escala utilizan Transformer para abordar tareas de CV y PNL. Uno de los primeros trabajos fue GPT, junto con BERT, IGPT y MAE al mismo tiempo.
Recientemente, una gran cantidad de técnicas de preentrenamiento, incluido el aprendizaje contrastivo, MLM, MRM, etc., han promovido aún más el desarrollo de VLFM. Entre ellos, el modelo CLIP entrenado en pares de imagen y texto a gran escala muestra una gran capacidad de generalización y puede detectar muestras desconocidas.
En ODA y SF-ODA, la práctica común es utilizar pesos previamente entrenados en ImageNet para inicializar el modelo. Debido a que estos métodos se basan principalmente en la calidad de los modelos previamente entrenados, los métodos VLFM como CLIP tienen un gran potencial para mejorar el rendimiento de ODA y SF-ODA, por el contrario, el costo de ajustar el modelo VLFM es muy alto. Por lo tanto, se utiliza la predicción de tiro cero de CLIP y se propone un método ligero para aplicar CLIP a ODA.
4. Método
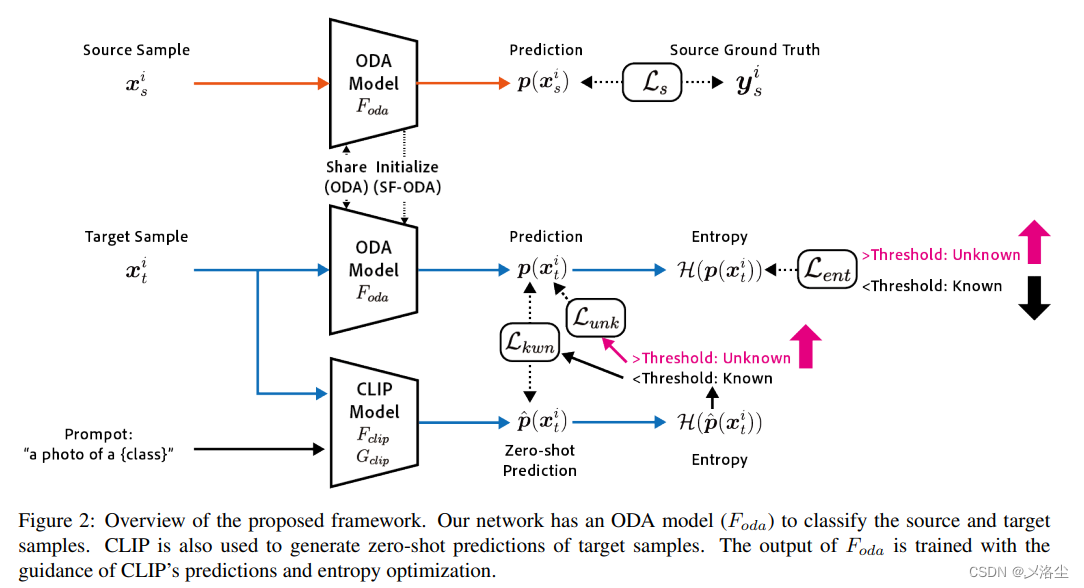
4.1 Planteamiento del problema
Supongamos que la etiqueta del dominio de origen establece {X s, Y s} \{X_s,Y_s\}{
Xs,Ys} , un par imagen-etiqueta del dominio de origen{ xs , ys } \{x_s,y_s\}{
xs,ys} , conjunto de imágenes de destino sin etiquetarX t X_tXtUna imagen de destino sin etiquetar es xt x_tXt,C s C_sCsy C t C_tCtrepresentan la etiqueta del dominio de origen y la imagen de la etiqueta de muestra respectivamente. En ODA, las categorías conocidas son datos del dominio de origen, mientras que algunas categorías desconocidas existen en el dominio de origen y en el dominio de destino sin etiquetas, es decir, C s ∈ C t C_s\in C_tCs∈Ct, expresado como C t ~ = C t \ C s \widetilde{C_{t}}=C_{t}\backslash C_{s}Ct
=Ct\ Cs.
Muestra objetivo dada xt x_tXt, la AOD pretende predecir su etiqueta yt y_tytSi pertenece a la categoría de dominio de origen C s C_sCsUna de las categorías desconocidas C t ~ \widetilde{C_{t}}Ct
una muestra de. En SF-ODA, al entrenarXtCuando no se proporciona su etiqueta, es necesario entrenarlo en { X s , Y s } \{X_s,Y_s\}{
Xs,Ys} implementación del modelo.
El proceso de entrenamiento por lotes mínimo implica dos conjuntos de datos, dondeD s = ( xsi , ysi ) i = 1 N D_{s}=\left(x_{s}^{i},y_{s}^{i }\ derecha)_ {i=1}^{N}Ds=( xsyo,ysyo)yo = 1norteRepresenta el tamaño como NNLos minilotes de N se derivan de muestras del dominio de origen, y D t = ( xti ) i = 1 N D_{t}=\left(x_{t}^{i}\right)_{i=1}^ {N}Dt=( xtyo)yo = 1norteRepresenta el tamaño como NNN minilotes de muestras del dominio objetivo.
4.2 Predicción de tiro cero usando CLIP
CLIP consta de un codificador de imágenes F clip F_{clip}Fc l i py un modelo de lenguaje G clip G_ {clip}GRAMOc l i pCompuesto, que utiliza el mensaje de texto ttLa imagen se clasifica según la similitud entre la incrustación de t y las características de la imagen. Para el mensaje de categoríatk \boldsymbol{t}_ktk, calculando F clip ( xti ) F_{clip}(x_t^i)Fc l i p( xtyo)和G clip ( tk ) G_{clip}(\boldsymbol{t}_k)GRAMOc l i p( tk) Similitud coseno de la salida:
y ^ i = arg max k ∈ C s F clip ( xti ) ⋅ G clip ( tk ) \hat{y}^i=\arg\max_{k\in C_s}F_ { clip}(x_t^i)\cdot G_{clip}(\boldsymbol{t}_k)y^i=arg _k ∈ CsmáximoFc l i p( xtyo)⋅GRAMOc l i p( tk) dondeC s C_sCses la categoría en el dominio de origen, ⋅ \cdot⋅ representa similitud coseno. Para una evaluación de disparo cero en ODA, congele tanto el codificador de imágenes como el modelo de lenguaje, luego envíe un mensaje de texto t \boldsymbol{t}
en cada conjunto de datost se reemplaza por "Una foto de {label}".
En ODA, dado que hay muestras desconocidas en el dominio objetivo, estas muestras se detectan prediciendo la entropía cruzada. Primero, convierta la similitud del coseno en probabilidadp ^ \hat{p}pag^:
p ^ ( k ∣ xti ) = exp ( F clip ( xti ) ⋅ G clip ( tk ) / τ ) ∑ k = 1 K exp ( F clip ( xti ) ⋅ G clip ( tk ) / τ ) \hat {p}(k|x_t^i)=\frac{\exp(F_{clip}(x_t^i)\cdot G_{clip}(t_k)/\tau)}{\sum_{k=1}^K \exp(F_{clip}(x_t^i)\cdot G_{clip}(t_k)/\tau)}pag^( k ∣ xtyo)=∑k = 1kexp ( Fc l i p( xtyo)⋅GRAMOc l i p( tk) / t )exp ( Fc l i p( xtyo)⋅GRAMOc l i p( tk) / t )其中p ^ ( k ∣ xti ) \hat{p}(k|x_t^i)pag^( k ∣ xtyo) representa la muestraxti x_t^iXtyoPertenece a la categoría kkLa probabilidad de k ,τ = 0,01 \tau=0,01t=0,01 controla la concentración de la distribución.
Luego calculap ^ \hat ppag^Entropía cruzada H ( p ^ ) \mathcal{H}(\hat p)H (pag^) , cuando una muestra objetivoxti x_t^iXtyoH ( p ^ ) \mathcal{H } (\hat p)H (pag^) es mayor que un cierto umbralδ {\delta}Cuando δ , es una muestra desconocida (la probabilidad de predicción en todas las categorías conocidas es muy baja). Para otras muestras conocidas con pequeña entropía cruzada, la primera fórmula del artículo predecirá sus categorías.
4.3 Preparación del modelo de AOD
Primero prepare un modelo simple F antiguo F_ {old}Fviejo _ _, para distinguir muestras del dominio de origen, incluido un clasificador y un extractor de características, generando un vector de probabilidad F oda ( xi ) ∈ R ∣ C s ∣ F_{oda}(x^i)\in\mathbb{R}^{| C_s| }Fo d a( xyo )∈R∣C _s∣ . Optimice utilizando pérdida de entropía cruzada anotada y datos de dominio de origen etiquetados:
L s ( D s ) = − 1 N ∑ i = 1 N ∑ k = 1 ∣ C s ∣ ysik log p ( k ∣ xsi ) \mathcal {L} _s(D_s)=-\frac1N\sum_{i=1}^N\sum_{k=1}^{|C_s|}y_s^{ik}\log p(k|x_s^i)ls( Ds)=−norte1yo = 1∑nortek = 1∑∣C _s∣ysiiniciar sesiónpag ( k ∣ xsyo) en el quep ( k ∣ xsi ) p(k|x_s^i)pag ( k ∣ xsyo) es la muestraxsi x_s^iXsyoPredecir para la categoría kkLa probabilidad de k , que esF oda ( xsi ) F_{oda}(x_s^i)Fo d a( xsyo) kth_k salidas,ysik y_s^{ik}ysiIndica si la muestra pertenece a la categoría kkEtiqueta binarizada de k .
4.4 Optimización de entropía cruzada con CLIP
4.4.1 Adaptación de dominios separados cruzados
Para realizar el modelo ODA F oda F_{oda}Fo d aAdáptese al dominio objetivo y aplique pérdida por separación cruzada a la muestra objetivo:
L ent ( D t ) = 1 N ∑ i = 1 NL ~ ent ( D t ) \mathcal{L}_{ent}(D_t)=\ frac1N\sum_{i=1}^N\tilde{\mathcal{L}}_{ent}(D_t)le n t( Dt)=norte1yo = 1∑nortel~e n t( Dt)
L ~ ent ( D t ) = { − ∣ H ( p ) − δ ∣ si ∣ H ( p ) − δ ∣ > m 0 en caso contrario \tilde{\mathcal{L}}_{ent}(D_t)=\ comenzar{casos}-|\mathcal{H}(p)-\delta|&\mathrm{if~}|\mathcal{H}(p)-\delta|>m\\0&\mathrm{de lo contrario}&\ fin {casos}l~e n t( Dt)={
− ∣ H ( pags )−δ ∣0si ∣ H ( p )−δ ∣>metrode lo contrariodonde H ( p ) \mathcal{H}(p)H ( p )为p (xti) p(x_t^i)pag ( xtyo) entropía cruzada,δ \deltaδ representa el umbral,mmm es el límite de separación. δ\deltaδ se establece enlog ( ∣ C s ∣ ) 2 \frac{\log(|C_s|)}22l o g ( ∣ Cs∣ ), porque log ( ∣ C s ∣ ) \log(|C_s|)log g ( ∣ Cs∣ ) esH \mathcal{H}El valor máximo de H. Cuando la entropía cruzada es mayor que el umbral y no está dentro del área límite, es decir,H ( p ) > δ + m ( o H ( p ) − δ > m ) \mathcal{H}(p)>\delta+ m\mathrm{~( o~}\mathcal{H}(p)-\delta>m)H ( pag )>d+m ( o H ( p ) −d>m ) , esta muestra se trata como una muestra desconocida y la entropía cruzada aumenta minimizando la pérdida. Por el contrario, cuandoH ( p ) < δ − m (o H ( p ) − δ < − m ) \mathcal{H}(p)<\delta-m\text{ (o }\mathcal{H}( p) -\delta<-m)H ( pag )<d−metro (o H ( pag )−d<− m ) , la entropía cruzada es lo suficientemente pequeña, esta muestra se considera una muestra conocida y su entropía cruzada disminuirá.
4.4.2 Adaptación de dominio guiada por CLIP
Para mejorar el rendimiento de la AOD, la predicción Zert-shot de CLIP se utiliza además para entrenar a F oda F_{oda}Fo d a, según la predicción de CLIP H ( p ^ ) \mathcal{H}(\hat p)H (pag^) detectó una muestra desconocida. Denote la muestra de posición del objetivo detectada comoD^tunk \hat{D}_{t}^{unk}D^tnk _, en D t D_tDtPor ejemplo, H ( p ^ ) > δ \mathcal{H}(\hat p)>\deltaH (pag^)>δ ; las muestras conocidas restantes sonD ^ tkwn \hat{D}_{t}^{kwn}D^tk w n,si H ( p ^ ) < = δ \mathcal{H}(\hat p)<=\deltaH (pag^)<=δ .
Para la muestra conocida objetivoD ^ tkwn \hat{D}_{t}^{kwn}D^tk w nUtilice directamente la predicción de disparo cero de CLIP como pseudoetiqueta para entrenar F oda F_ {oda}Fo d a:
L kwn ( D ^ tkwn ) = − 1 ∣ D ^ tkwn ∣ ∑ i = 1 ∣ D ^ tkwn ∣ ∑ k = 1 ∣ C s ∣ p ^ ( k ∣ xti ) log p ( k ∣ xti ) \mathcal {L}_{kwn}(\hat{D}_{t}^{kwn})=-\frac1{|\hat{D}_{t}^{kwn}|}\sum_{i=1} ^{|\hat{D}_{t}^{kwn}|}\sum_{k=1}^{|C_{s}|}\hat{p}(k|x_{t}^{i} )\log p(k|x_{t}^{i})lk w n(D^tk w n)=−∣D^tk w n∣1yo = 1∑∣D^tk w n∣k = 1∑∣C _s∣pag^( k ∣ xtyo)iniciar sesiónpag ( k ∣ xtyo)
para la muestra objetivo desconocidaD^tunk \hat{D}_{t}^{unk}D^tnk _, aumentando la entropía cruzada de su salida:
L unk ( D ^ tunk ) = 1 ∣ D ^ tunk ∣ ∑ i = 1 ∣ D ^ tunk ∣ − H ( p ^ ) \mathcal{L}_{unk}(\ sombrero{ D}_t^{unk})=\frac1{|\hat{D}_t^{unk}|}\sum_{i=1}^{|\hat{D}_t^{unk}|}- \mathcal {H}(\sombrero{p})lnk _(D^tnk _)=∣D^tnk _∣1yo = 1∑∣D^tnk _∣− H (pag^)
4.5 Función objetivo general
Resumen: el marco de optimización de entropía cruzada realiza entrenamiento supervisado de muestras de dominio de origen, separación cruzada de muestras de destino y adaptación de dominio guiada por CLIP. El objetivo general de aprendizaje de ODA es: min F oda L total = L s ( D s ) + L
ent ( D t ) + L kwn ( D ^ tkwn ) + L unk ( D ^ tunk ) \operatorname*{min}_{F_{oda}}\mathcal{L}_{total}=\mathcal{ L}_s( D_s)+\mathcal{L}_{ent}(D_t) +\mathcal{L}_{kwn}(\hat{D}_{t}^{kwn})+\mathcal{L} _{unk} (\hat{D}_{t}^{unk})Fo d aminlt o t a l=ls( Ds)+le n t( Dt)+lk w n(D^tk w n)+lnk _(D^tnk _)
para SF-ODA, ya queD s D_sDsy D t D_tDtNo se puede obtener durante el proceso de capacitación, por lo que se utiliza la capacitación previa en el dominio de origen D s D_sDsModelo AOD F oda F_{oda} enFo d aEn su lugar, utilice el método de aprendizaje de clasificador supervisado estándar para entrenar:
min F oda L pretrain = L s ( D s ) \min_{F_{oda}}\mathcal{L}_{pretrain}=\mathcal{L}_{ s}(D_{s})Fo d aminlpre - entrenamiento _ _=ls( Ds) A continuación, entrene más separación transversal yD t D_tDtPredeterminado:
min F orden L total = L ent ( D t ) + L kwn ( D ^ tkwn ) + L unk ( D ^ tunk ) \min_{F_{order}}\mathcal{L}_{total }=\ mathcal{L}_{ent}(D_t)+\mathcal{L}_{kwn}(\hat{D}_t^{kwn})+\mathcal{L}_{unk}(\hat{ D}_t ^{unto})Fo d aminlt o t a l=le n t( Dt)+lk w n(D^tk w n)+lnk _(D^tnk _)
5. Experimentar
5.1 Pasos experimentales
5.1.1 Conjunto de datos

5.1.2 Comparación con otros métodos
Dos líneas de base: predicción de tiro cero de CLIP; etiquetar solo el dominio de origen y modelo entrenado en clases desconocidas detectadas por entropía cruzada. Dos métodos ODA: BAILE, OVA. Dos métodos SF-ODA: SHOT, OneRing.
5.1.3 Anexos de evaluación
Usando la métrica de puntuación H, cuando la clase desconocida se considera una etiqueta unificada, la puntuación de puntuación H se calcula para la clase conocida \mathrm{acc}_{kwn}acck w ny categoría desconocida unificada acunk \mathrm{acc}_{unk}accnk _的调和内合数:
puntuación H = 2 accwn ⋅ accunkacckwn + accunk H_{score}=\frac{2\mathrm{acc}_{kwn}\cdot\mathrm{acc}_{unk}}{\mathrm{acc } _{kwn}+\mathrm{acc}_{unk}}hpuntuación=acck w n+accnk _2 cuentask w n⋅accnk _si y sólo si accckwn \mathrm{acc}_{kwn}acck w n和accunk \mathrm{acc}_{unk}accnk _La puntuación H sólo es grande cuando es muy grande. Los experimentos se realizaron con diferentes semillas aleatorias en todos los experimentos.
5.1.4 Detalles de implementación
ResNet-50 preentrenado en Image-Net como modelo ODA F oda F_{oda}Fo d a, el umbral de entropía cruzada se establece en log ( ∣ C s ∣ ) 2 \frac{\log(|C_s|)}22l o g ( ∣ Cs∣ ), el valor límite de separación m = 0,5 m=0,5metro=0,5。
5.2 Resultados experimentales
Resultados principales

Comparación entre el tiro cero de CLIP y el método propuesto



Resultados detallados para cada conjunto de datos


5.3 Experimento de ablación

6. Limitaciones y trabajo futuro
Vale la pena considerar el ajuste fino de CLIP, pero se debe prestar atención al costo computacional y también al hecho de que el ajuste fino del modelo sobreajustará los datos en el dominio de origen. La introducción de modelos más complejos para las tareas de AOD queda para trabajos futuros.
7. Conclusión
Este artículo propone utilizar CLIP para mejorar el rendimiento de la AOD. Para resolver la transferencia de conocimiento en diferentes categorías, se utiliza la capacidad de predicción de disparo cero del modelo CLIP para mejorar el rendimiento del modelo ODA. Los experimentos muestran que el método es muy eficaz y supera los métodos SOTA actuales de AOD y SF-ODA.
escribe en la parte de atrás
Este artículo todavía parece un poco incomprensible, aunque hay pocas fórmulas, no se proporciona el código, lo cual es un poco lamentable. Lo que es digno de elogio es que el nivel de redacción del artículo es relativamente alto y puede ser entendido por lectores no profesionales. Algunas fallas radican en la falta de fluidez en el resumen, y la Figura 1 del artículo no se cita en el texto original.