Obtener incrustación del modelo preentrenado
En el campo de la PNL, es muy difícil construir un conjunto de datos etiquetados a gran escala, por lo que solo el corpus actual no puede completar tareas específicas de manera efectiva. Se puede usar el método de transferencia de aprendizaje, es decir, la incrustación de palabras previamente entrenada se usa como el peso del modelo y luego se ajusta sobre esta base.
Nota de antecedentes
Este documento realiza un análisis de sentimiento basado en el conjunto de datos IMDB. Antes de hacer predicciones, es necesario preprocesar el conjunto de datos y convertir las palabras en incrustaciones de palabras. Aquí, el método de transferencia de aprendizaje se usa para mejorar el rendimiento del modelo, y se usa el conjunto de datos de incrustación de palabras precalculados de Wikipedia en inglés en 2014. **El nombre de archivo del conjunto de datos es guante.6B.zip, el tamaño es de 822 MB y contiene vectores de incrustación de 100 dimensiones de 400 000 palabras. ** Importe la palabra incrustada previamente entrenada en la primera capa del modelo, congele esta capa y luego agregue una capa de clasificación para la predicción de clasificación. La dirección de descarga del conjunto de datos de incrustación de palabras de GloVe es https://nlp.stanford.edu/projects/glove/

Descargar el conjunto de datos de IMDB
Descargue el conjunto de datos de IMDB y guárdelo localmente. Descargue el archivo glove.6B.zip aquí y guárdelo en "./aclImdb" después de completarlo.

Lea reseñas de películas y clasifíquelas como 1 o 0 según cuán positivas o negativas sean sus reseñas:
def preprocessing(data_dir):
# 提取数据集中所有的评论文本以及对应的标签,neg表示负面标签,用0表示,pos表示正面标签,用1表示
texts, labels = [], []
train_dir = os.path.join(data_dir, 'train')
for label_type in ['neg', 'pos']:
dir_name = os.path.join(train_dir, label_type)
for fname in os.listdir(dir_name):
if fname[-4:] == '.txt':
f = open(os.path.join(dir_name, fname), encoding='utf-8')
texts.append(f.read())
f.close()
if label_type == 'neg':
labels.append(0)
else:
labels.append(1)
return texts, labels
participio
Usa la función Tokenizer proporcionada por TensorFlow 2.0 para realizar operaciones de segmentación de palabras, de la siguiente manera:
def word_cutting(args, texts, labels):
# 利用Tokenizer函数进行分词操作
tokenizer = Tokenizer(num_words=args.max_words)
tokenizer.fit_on_texts(texts)
sequences = tokenizer.texts_to_sequences(texts)
word_index = tokenizer.word_index
print(f'Found {
len(word_index)} unique tokens.')
data = pad_sequences(sequences, maxlen=args.maxlen)
labels = np.asarray(labels)
print(f'Shape of data tensor: {
data.shape}')
print(f'Shape of label tensor: {
labels.shape}')
return word_index, data, labels
Divida los datos segmentados por palabras en conjunto de entrenamiento y conjunto de prueba:
def data_spliting(data, labels, training_samples, validation_samples):
# 将数据划分为训练集和验证集, 首席按打乱数据,因为一开始数据集是排好序的,负面评论在前,正面评论灾后
indices = np.arange(data.shape[0])
np.random.shuffle(indices)
data = data[indices]
labels = labels[indices]
x_train = data[:training_samples]
y_train = labels[:training_samples]
x_val = data[training_samples:training_samples + validation_samples]
y_val = labels[training_samples:training_samples + validation_samples]
return x_train, y_train, x_val, y_val
Descargar y preprocesar los datos de incrustación de palabras de GloVe
Analice el archivo guante.6B.100d.txt para crear un índice que asigne palabras a sus vectores Aquí, de acuerdo con la descripción anterior, se ha descargado y colocado en el directorio local.
def glove_embedding(glove_dir):
# 对glove.6B文件进行解析,构建一个由单词映射为其向量表示的索引
embeddings_index = {
}
f = open(os.path.join(glove_dir, 'glove.6B.100d.txt'), encoding='utf-8')
for line in f:
values = line.split()
word = values[0]
coefs = np.asarray(values[1:], dtype='float32')
embeddings_index[word] = coefs
f.close()
print(f'Found {
len(embeddings_index)} word vectors.')
# 查看字典的样例
for key, value in embeddings_index.items():
print(key, value)
print(value.shape)
break
return embeddings_index
modelo de construcción
Usando la secuencia de Keras (secuencial) para construir un modelo
def model_building(max_words, embedding_dim, maxlen):
model = Sequential()
model.add(Embedding(max_words, embedding_dim, input_length=maxlen))
model.add(Flatten())
model.add(Dense(32, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.summary()
return model
Entrena el modelo y visualiza los resultados
Al entrenar, distinga entre incrustar y no incrustar:
def training(args):
texts, labels = preprocessing(args.data_dir)
word_index, data, labels = word_cutting(args, texts, labels)
x_train, y_train, x_val, y_val = data_spliting(data, labels, args.training_samples, args.validation_samples)
embeddings_index = glove_embedding(args.embed_dir)
# 在embeddings_index字典的基础上构建一个矩阵,对单词索引中索引为i的单词来说,该矩阵的元素i就是这个单词对应的词向量
embedding_matrix = np.zeros((args.max_words, args.embedding_dim))
for word, i in word_index.items():
embedding_vector = embeddings_index.get(word)
if i < args.max_words:
if embedding_vector is not None:
# 在嵌入索引(embedding_index)找不到的词,其嵌入向量都设为0
embedding_matrix[i] = embedding_vector
model = model_building(args.max_words, args.embedding_dim, args.maxlen)
# 在模型中加载GloVe词嵌入,并冻结Embedding Layer
model.layers[0].set_weights([embedding_matrix])
model.layers[0].trainable = False
# 训练模型
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])
history = model.fit(x_train, y_train, epochs=10, batch_size=32, validation_data=(x_val, y_val))
model.save_weights('./pre_trained_glove_model.h5')
visualizating(history)
# 不使用预训练词嵌入的情况
model = model_building(args.max_words, args.embedding_dim, args.maxlen)
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])
history = model.fit(x_train, y_train, epochs=10, batch_size=32, validation_data=(x_val, y_val))
visualizating(history)
El código de visualización es el siguiente:
def visualizating(history):
# 可视化,并查看验证集的准确率acc
acc, val_acc = history.history['acc'], history.history['val_acc']
loss, val_loss = history.history['loss'], history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.figure()
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.show()
Resultados comparativos
1) Cargue la incrustación de la palabra GloVe en el modelo y congele la capa de incrustación:
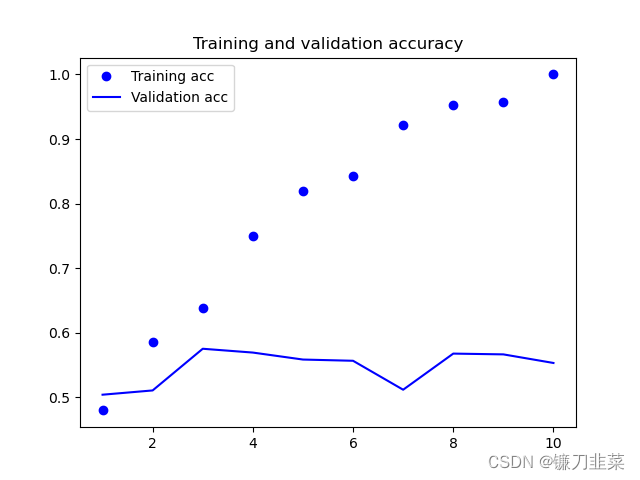
se puede ver que la precisión del entrenamiento y la precisión de la verificación son bastante diferentes, pero aquí se utilizan menos datos de entrenamiento. La precisión de verificación es cercana al 60%.
2) El caso de no usar incrustaciones de palabras previamente entrenadas
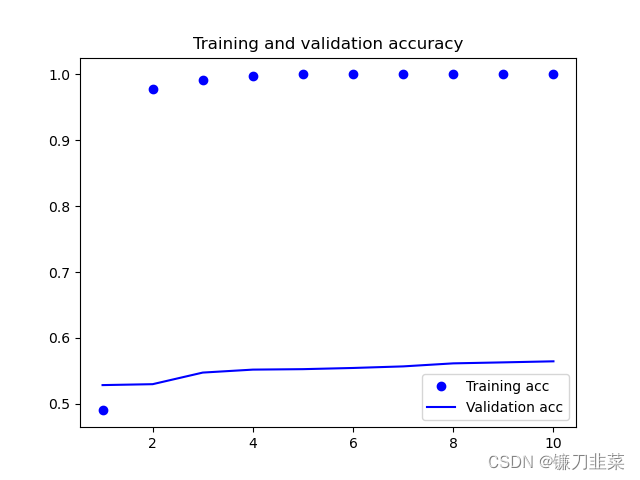
Obviamente, la tasa de precisión de verificación sin usar el modelo preentrenado es solo del 55%. Por lo tanto, se puede concluir preliminarmente que el rendimiento del modelo que utiliza la incrustación de palabras previamente entrenada es mejor que el del modelo no utilizado.
otro codigo
import argparse
import os
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, Flatten, Dense
def main():
parser = argparse.ArgumentParser(description='IMDB Emotional Analysis')
parser.add_argument('--data_dir', type=str, default='./aclImdb', help='the dir path of IMDB dataset')
parser.add_argument('--embed_dir', type=str, default='./glove.6B/', help='the dir path of embeddings')
parser.add_argument('--maxlen', type=int, default=100, help='Keep comments for only the first 100 words')
parser.add_argument('--training_samples', type=int, default=500, help='Train on 200 samples')
parser.add_argument('--validation_samples', type=int, default=10000, help='Verify 10,000 samples')
parser.add_argument('--max_words', type=int, default=10000, help='Consider the most common 10000 words')
parser.add_argument('--embedding_dim', type=int, default=100, help='the dim of word vector')
args = parser.parse_args()
training(args)
if __name__ == '__main__':
main()