contenido
1. Procesamiento de observaciones repetidas
2. Procesamiento de valores perdidos
1. ¿Por qué escalar datos de características?
En segundo lugar, el método comúnmente utilizado de escalado de características
Limpieza de datos
1. Procesamiento de observaciones repetidas
import pandas as pd
import numpy as np
data=pd.DataFrame([[8.3,6],[9.3,4],[6,8],[3,1],[3,1]])
# 重复观测的检测
print('数据集中是否存在重复观测:\n',any(data.duplicated()))

# 删除重复项
data.drop_duplicates(inplace = True)
# 重复观测的检测
print('数据集中是否存在重复观测:\n',any(data.duplicated()))
print(data)
2. Procesamiento de valores perdidos
-
Método de eliminación
import pandas as pd
import numpy as np
data=pd.DataFrame([[8.3,6,],[9.3,4,],[6,8,8],[5,6],[3,1,8]],columns=('a','b','c'))
# 缺失观测的检测
print('数据集中是否存在缺失值:\n',any(data.isnull()))
print(data)
# 删除法之变量删除
data.drop(["c"],axis =1 ,inplace=True)
print(data)


# 删除法之记录删除
data=data.dropna(axis=0,how='any')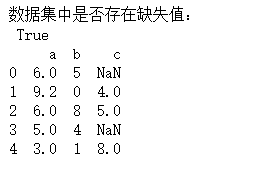

Analizar gramaticalmente:
1, eliminar todas las filas o columnas vacías
data=data.dropna(axis=0,how='all') #行
data=data.dropna(axis=1,how='all') #列
2. Eliminar filas o columnas con valores nulos
data=data.dropna(axis=0,how='any') #行
data=data.dropna(axis=1,how='any') #列
Explicación específica de la función:
Función DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
: eliminar filas o columnas con valores nulos
eje: dimensión, eje = 0 significa fila de índice, eje = 1 significa columna de columnas, el valor predeterminado es 0
cómo: "todos" significa que faltan todos los elementos en esta fila o columna (nan) antes de eliminar esta fila o columna, "cualquiera" significa que mientras falten elementos en esta fila o columna, esta fila o columna se elimina
umbral: elimine solo cuando aparece al menos umbral en una fila o columna.
subconjunto: seleccione columnas con valores faltantes en un subconjunto de ciertas columnas para eliminar, y las columnas o filas con valores faltantes que no están en el subconjunto no se eliminarán (el eje determina si es una fila o una columna)
inplace: seleccione si desea guardar los datos nuevos con valores faltantes como una copia o modificarlos directamente en los datos originales.
-
método de sustitución
# 替换法之前向替换
#data.fillna(method = 'ffill')
# 替换法之后向替换
#data.fillna(method = 'bfill')
#替换法之补平均数
#data['c']=data['c'].fillna(data['c'].mean())
#替换法之补众数
#data['c']=data['c'].fillna(data['c'].mode())
#替换法之补中位数
data['c']=data['c'].fillna(data['c'].median())
print(data) 

-
interpolación
El método de interpolación consiste en utilizar los puntos conocidos para establecer una función de interpolación adecuada, y el valor desconocido se reemplaza aproximadamente por el valor de la función f(xi) obtenido del punto xi correspondiente.
3. Manejo de valores atípicos
4. Procesamiento de codificación de características
5. Creación de características
rasgos podados
1. Eliminar atributos únicos
Los únicos atributos suelen ser algunos atributos de identificación, estos atributos no describen la ley de distribución de la muestra en sí, así que simplemente elimine estos atributos.
vista de datos
- Ver filas y columnas: data.shape
- Ver detalles de datos: data.info(), puede ver si faltan valores
- Ver el análisis estadístico descriptivo de los datos: data.describe(), puede ver datos anormales
- Obtenga 10 filas de datos antes/después: data.head(10), data.tail(10)
- Ver etiquetas de columna: data.columns.tolist()
- Ver índice de fila: data.index
- Ver tipos de datos: data.dtypes
- Ver dimensiones de datos: data.ndim
- Ver valores que no sean index: data.values, que devuelve los datos del DataFrame en forma de un ndarray bidimensional
- Ver la distribución de datos (histograma): seaborn.distplot(data[nombre de columna].dropna())
Escalado de funciones
1. ¿Por qué escalar datos de características?
El rango de valores de una característica varía mucho, lo que afecta a otras características con un rango de valores más pequeño. Luego, de acuerdo con la fórmula de la distancia euclidiana, toda la distancia estará dominada por la característica con un rango de valores más grande.

Para evitar esto, cada característica generalmente se escala, digamos, a [0,1], de modo que cada atributo de característica contribuya aproximadamente en la misma cantidad a la distancia.
Qué hace: asegúrese de que todas estas características estén en un rango similar.
Ventajas: 1. Esto puede ayudar al algoritmo de descenso de gradiente a converger más rápido, 2. Mejorar la precisión del modelo
Desventajas de la solución directa:
1. Cuando el peso correspondiente a la característica x1 es mucho menor que el peso correspondiente a x2, la interpretabilidad del modelo se reduce
2. Cuando el gradiente desciende , la solución final está dominada por una determinada característica, que afectar la precisión del modelo y la velocidad de convergencia
3. La regularización no tratará la importancia de las características de manera desigual (la regularización L1/L2 sin normalización es incorrecta)
¿Qué algoritmos de aprendizaje automático no (necesitan) normalizar?
Los modelos probabilísticos (modelos de árbol) no necesitan normalización porque no les importa el valor de la variable, sino la distribución de la variable y la probabilidad condicional entre las variables, como los árboles de decisión, RF. Y los problemas de optimización como Adaboost, SVM, LR, Knn, KMeans requieren normalización.
En segundo lugar, el método comúnmente utilizado de escalado de características
1. Normalización _
- La normalización del valor, la pérdida de la información de distribución de los datos, la distancia entre los datos no se conserva bien, pero se conserva el peso.
- 1. El uso de datos pequeños/datos fijos 2. Cuando la medición de distancia, el cálculo de covarianza y los datos no se ajustan a la distribución normal no están involucrados 3. Cuando se realiza una evaluación integral de múltiples indicadores.
Reducir un valor al intervalo (0,1) o (-1,1).
Rango [mín., máx.] para una característica X
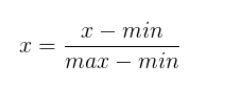
import pandas as pd
import numpy as np
data=pd.DataFrame([[8.3,6],[9.3,4],[6,8],[3,1]])
print(data)
data[0]=(data[0]-data[0].min())/(data[0].max()-data[0].min())
data[1]=(data[1]-data[1].min())/(data[1].max()-data[1].min())
print(data)resultado:

2. Estandarización
- La normalización de la distribución de datos conserva mejor la distribución entre los datos, es decir, se conserva la distancia entre las muestras, pero se pierden los pesos
- 1. En algoritmos de clasificación y agrupamiento se necesita usar distancias para medir similitud 2. Tiene buena robustez y produce datos discretos con un rango de valores o cuando se desconocen los valores máximo y mínimo.
Transforme los datos en una distribución con una media de 0 y una desviación estándar de 1. Recuerde, no tiene que ser normal.

donde μ es la media de todos los datos de la muestra y σ es la desviación estándar de todos los datos de la muestra.
Encuentre la media primero

Luego encuentre la varianza (std)

import numpy as np
from sklearn.preprocessing import StandardScaler
data=np.array([[2,2,3],[1,2,5]])
print(data)
print()
scaler=StandardScaler()
# fit函数就是要计算这两个值
scaler.fit(data)
# 查看均值和方差
print(scaler.mean_)
print(scaler.var_)
# transform函数则是利用这两个值来标准化(转换)
X=scaler.transform(data)
print()
print(X)resultado:

Puede usar la fórmula anterior para verificar
Si la media de los dos conjuntos de datos es 0 y la varianza (σ2) es 1
Semejanzas y sus conexiones.
- La normalización incluye la estandarización en un sentido amplio, y lo anterior es principalmente para distinguir los dos en un sentido estricto. Esencialmente, la extracción de características se realiza para facilitar la comparación de los datos finales. Todos son para reducir el alcance y facilitar el procesamiento posterior de datos.
- Acelera el descenso del gradiente, la función de pérdida converge; Mejora la precisión del modelo; Previene la explosión del gradiente (elimina la gran brecha de salida causada por la gran brecha de entrada, que a su vez hace que el gradiente sea demasiado grande en el proceso) de retropropagación, formando así una explosión de gradiente)