Limpieza de datos: combinación de tablas y agregar marca de tiempo
extraer el nombre del archivo
Leer el nombre del tipo de archivo especificado
nombre de archivo separado
names = os.listdir(path)
for name in names:
index = name.rfind('.')
name = name[:index]
print(name)
flag = name.split('_')
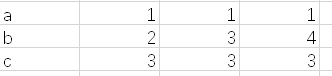
El formulario original se muestra en la figura anterior, sin encabezado.
Agregue columnas a la tabla y escriba la información especificada en las columnas
definir encabezado
fusionar tabla
总程序:
import os
import pandas as pd
path = os.getcwd()
names = os.listdir(path)
for name in names:
index = name.rfind('.')
csv = name[index:]
if(csv =='.csv'): #由于文件夹中有其他文件,进行筛选,否则转化为dataframe时报错
df = pd.read_csv(name,header=None,names=['temp','tempavg','tempmax','tempmin'])# 注意这里增加表头的方式!!
# df.columns=['temp','tempavg','tempmax','tempmin'] #增加表头,否则下一步添加列时不方便
name_new = name[:index]
flag = name_new.split('_')
print(flag)
time = flag[2]
series = flag[1]
df['time'] = time
df['series'] = series
df.to_csv(name,index=False) #保存更改,注意不需要自动添加索引!
for name in names:
index = name.rfind('.')
csv = name[index:]
if(csv =='.csv'): #由于文件夹中有其他文件,进行筛选,否则转化为dataframe时报错
print(csv)
df = pd.read_csv(name)
df.to_csv('allok.csv',encoding="utf_8_sig",header=False,index=False,mode='a+')
df = pd.read_csv('allok.csv',header=None,names=['temp','tempavg','tempmax','tempmin','time','series'])# 定义合并好的表格名字
df.to_csv('allok.csv',index=True)
problema de índice de índice
Los índices para las adiciones predeterminadas no están basados en 1
df.index = np.arange(1, len(df))
Los datos exportados son demasiado largos para convertirlos en notación científica

Debido a que los datos exportados son demasiado largos, se ha convertido en una notación científica, lo que provocó el redondeo al fusionar las tablas más tarde... ¡
Así que agregue df['time'] = str(time)+'\t'

una solución exitosa!
Actualización de la tabla de fusión (expansión y fusión de filas y columnas de funciones)
Estilo de tabla original: (decenas de miles de tablas de este tipo deben fusionarse) 

Después de la fusión, se convierte en una tabla total con valores medios y máximos separados de cada parámetro
path = os.getcwd()
names = os.listdir(path)
i = 0
for name in names:
index = name.rfind('.')
csv = name[index:]
if(csv =='.csv'): #由于文件夹中有其他文件,进行筛选,否则转化为dataframe时报错
df = pd.read_csv(name)
for index,row in df.iterrows():
feature_name = row[0]
feature_avg = feature_name+'_avg'
feature_min = feature_name+'_min'
feature_max = feature_name+'_max'
df[feature_avg] = str(row[1])+'\t'
df[feature_max] = str(row[2])+'\t'
df[feature_min] = str(row[3])+'\t'#防止科学计数
data =df.iloc[:1,4:] #定位表格
if(i == 0):
data.to_csv('gather_operate.csv',encoding="utf_8_sig",header =True,index = False ,mode='a+')
else:
data.to_csv('gather_operate.csv',encoding="utf_8_sig",header =False,index = False ,mode='a+')
i=i+1
Extraiga el nombre del archivo en la tabla y guárdelo en el directorio principal
import os,sys
import xlwt
path = os.getcwd()
dirs = os.listdir(path)
write =xlwt.Workbook()
sheet = write.add_sheet('sheet_name')
i = 0
for file in dirs:
if os.path.splitext(file)[1]=='.csv':
sheet.write(i,0,file)
i+=1
print(i)
write.save('../file_name.xls')
Aparecen caracteres chinos ilegibles cuando los pandas escriben un archivo en formato csv
df.to_csv("cnn_predict_result.csv",encoding="utf_8_sig")
Migrar encabezados de tabla al fusionar tablas en lotes
i = 0
for name in names:
index = name.rfind('.')
csv = name[index:]
if(csv =='.csv'): #由于文件夹中有其他文件,进行筛选,否则转化为dataframe时报错
if(i==0):
print("header")
df = pd.read_csv(name)
df.to_csv('特征值数据汇总.csv',encoding="utf_8_sig",header=True,index=False,mode='a+')#拼接第一个表格时保留表头
else:
print(csv)
df = pd.read_csv(name)
df.to_csv('特征值数据汇总.csv',encoding="utf_8_sig",header=False,index=False,mode='a+')
i=i+1
La cadena de la tabla de salida de Pandas es demasiado larga para cambiarla a notación científica
El método de cambiar directamente el formato de celda en Internet, el archivo se cierra y luego se abre sigue siendo el mismo.
Más tarde, leí un artículo
df['time']=[' %i' % i for i in df[' time']] seleccione Agregar / t a la columna que se va a modificar. Según tengo entendido, debe agregar un carácter. Use
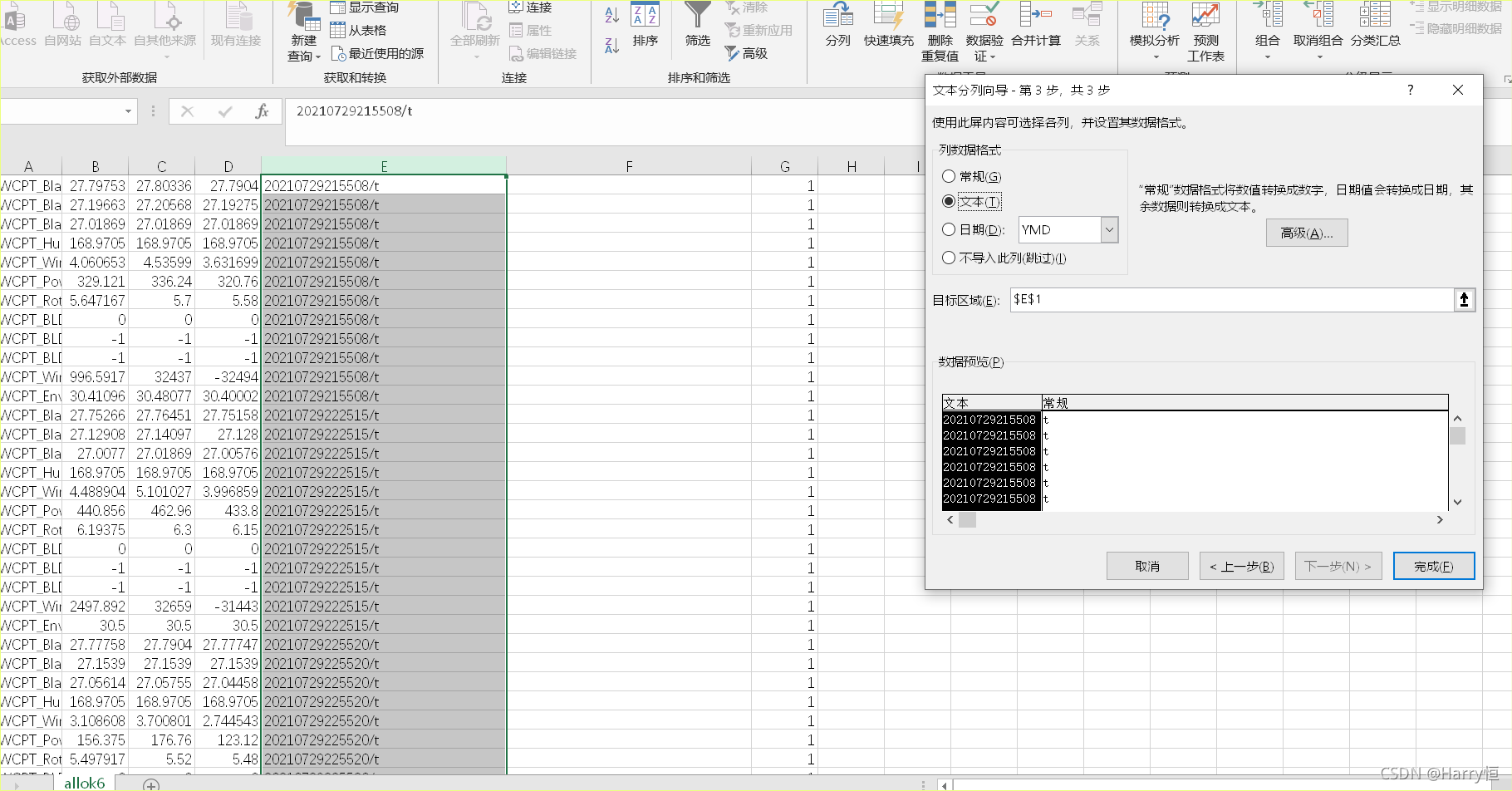
Excel para ordenar