1. ¿Qué es el preprocesamiento de funciones?
El proceso de convertir datos de características en datos de características más adecuados para el modelo de algoritmo a través de algunas funciones de conversión.
Antes del procesamiento, los valores de las características son valores numéricos y, después del procesamiento, se realiza el escalado de las características.
1. Contenidos:
Transformación adimensional de datos numéricos:
normalización y
estandarización
2. API de preprocesamiento de funciones
sklearn.preprocessing
3. ¿Por qué necesitamos normalizar/estandarizar
características? Las unidades o tamaños de las características son muy diferentes, o la variación de una característica es varios órdenes de magnitud mayor que otras características, lo que puede afectar (dominar) fácilmente los resultados objetivo, haciendo algunos algoritmos no pueden aprender a otras características
porque muchas dimensiones de datos son inconsistentes
Se puede ver que el valor del kilometraje es relativamente grande y el consumo de tiempo es relativamente pequeño.
Cuando se utiliza el algoritmo KNN para calcular la fórmula de distancia euclidiana, el resultado final está dominado por el kilometraje y no se pueden aprender otras características
(72993 - 35948 ) ^ 2 + (10,14 - 6,83 ) ^ 2 + (1,03 - 1,21) ^ 2
Necesitamos utilizar algunos métodos de transformación adimensional para convertir datos de diferentes especificaciones en la misma especificación.
4. ¿Cuál es la fórmula de la distancia euclidiana?

5. Procesamiento adimensional.
La razón por la que se requiere el procesamiento adimensional es porque las dimensiones no están unificadas, lo que resulta en valores de kilometraje muy grandes. Para que las características sean igualmente importantes, se requiere normalización/estandarización.
2. Normalización
1. Definición:
asigne los datos entre (el valor predeterminado es [0,1]) transformando los datos originales
2, oficial
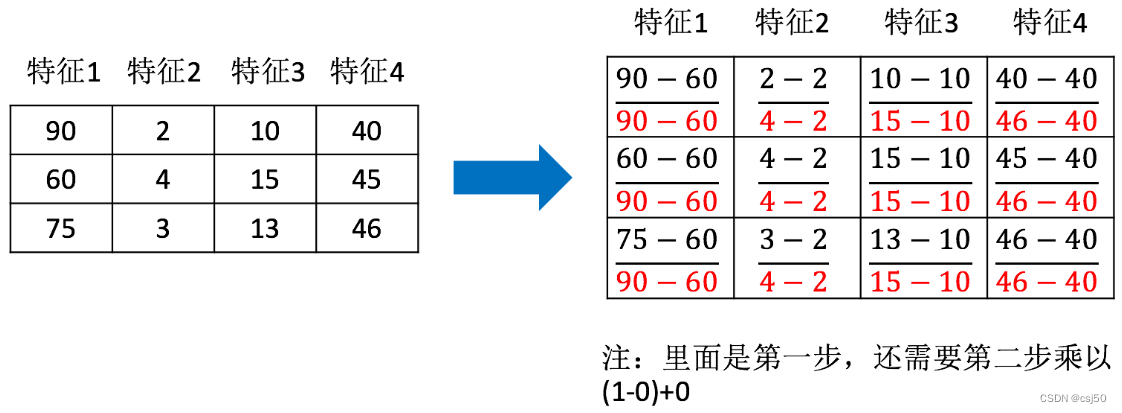
3. API y
sklearn.preprocessing.MinMaxScaler(feature_range=(0, 1)...)
4.
MinMaxScaler.fit_transform
( X
)
5. Normaliza los datos en dating.txt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction import DictVectorizer
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
from sklearn.preprocessing import MinMaxScaler
import jieba
import pandas as pd
def datasets_demo():
"""
sklearn数据集使用
"""
#获取数据集
iris = load_iris()
print("鸢尾花数据集:\n", iris)
print("查看数据集描述:\n", iris["DESCR"])
print("查看特征值的名字:\n", iris.feature_names)
print("查看特征值几行几列:\n", iris.data.shape)
#数据集的划分
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=22)
print("训练集的特征值:\n", x_train, x_train.shape)
return None
def dict_demo():
"""
字典特征抽取
"""
data = [{'city': '北京','temperature':100},{'city': '上海','temperature':60},{'city': '深圳','temperature':30}]
# 1、实例化一个转换器类
transfer = DictVectorizer(sparse=False)
# 2、调用fit_transform()
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new)
print("特征名字:\n", transfer.get_feature_names())
return None
def count_demo():
"""
文本特征抽取
"""
data = ["life is short,i like like python", "life is too long,i dislike python"]
# 1、实例化一个转换器类
transfer = CountVectorizer()
# 2、调用fit_transform()
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new.toarray())
print("特征名字:\n", transfer.get_feature_names())
return None
def count_chinese_demo():
"""
中文文本特征抽取
"""
data = ["我 爱 北京 天安门", "天安门 上 太阳 升"]
# 1、实例化一个转换器类
transfer = CountVectorizer()
# 2、调用fit_transform
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new.toarray());
print("特征名字:\n", transfer.get_feature_names())
return None
def cut_word(text):
"""
进行中文分词
"""
return " ".join(list(jieba.cut(text))) #返回一个分词生成器对象,强转成list,再join转成字符串
def count_chinese_demo2():
"""
中文文本特征抽取,自动分词
"""
# 1、将中文文本进行分词
data = ["今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。",
"我们看到的从很远星系来的光是在几百万年前之前发出的,这样当我们看到宇宙时,我们是在看它的过去。",
"如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。"]
data_new = []
for sent in data:
data_new.append(cut_word(sent))
print(data_new)
# 2、实例化一个转换器类
transfer = CountVectorizer()
# 3、调用fit_transform()
data_final = transfer.fit_transform(data_new)
print("data_final:\n", data_final.toarray())
print("特征名字:\n", transfer.get_feature_names())
return None
def tfidf_demo():
"""
用tf-idf的方法进行文本特征抽取
"""
# 1、将中文文本进行分词
data = ["今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。",
"我们看到的从很远星系来的光是在几百万年前之前发出的,这样当我们看到宇宙时,我们是在看它的过去。",
"如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。"]
data_new = []
for sent in data:
data_new.append(cut_word(sent))
print(data_new)
# 2、实例化一个转换器类
transfer = TfidfVectorizer()
# 3、调用fit_transform()
data_final = transfer.fit_transform(data_new)
print("data_final:\n", data_final.toarray())
print("特征名字:\n", transfer.get_feature_names())
return None
def minmax_demo():
"""
归一化
"""
# 1、获取数据
data = pd.read_csv("dating.txt")
#print("data:\n", data)
data = data.iloc[:, 0:3] #行都要,列取前3列
print("data:\n", data)
# 2、实例化一个转换器
transfer = MinMaxScaler()
# 3、调用fit_transform
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new)
return None
if __name__ == "__main__":
# 代码1:sklearn数据集使用
#datasets_demo()
# 代码2:字典特征抽取
#dict_demo()
# 代码3:文本特征抽取
#count_demo()
# 代码4:中文文本特征抽取
#count_chinese_demo()
# 代码5:中文文本特征抽取,自动分词
#count_chinese_demo2()
# 代码6: 测试jieba库中文分词
#print(cut_word("我爱北京天安门"))
# 代码7:用tf-idf的方法进行文本特征抽取
#tfidf_demo()
# 代码8:归一化
minmax_demo()
resultado de la operación:
data:
milage liters consumtime
0 40920 8.326976 0.953952
1 14488 7.153469 1.673904
2 26052 1.441871 0.805124
3 75136 13.147394 0.428964
4 38344 1.669788 0.134296
.. ... ... ...
984 11145 3.410627 0.631838
985 68846 9.974715 0.669787
986 26575 10.650102 0.866627
987 48111 9.134528 0.728045
988 43757 7.882601 1.332446
[989 rows x 3 columns]
data_new:
[[0.44832535 0.39805139 0.56233353]
[0.15873259 0.34195467 0.98724416]
[0.28542943 0.06892523 0.47449629]
...
[0.29115949 0.50910294 0.51079493]
[0.52711097 0.43665451 0.4290048 ]
[0.47940793 0.3768091 0.78571804]]
3. Estandarización
1. ¿Cuáles son las desventajas de la normalización?
El resultado de la normalización se calcula en función de los valores mínimo y máximo. Si hay muchos valores atípicos en los datos, los valores máximo y mínimo se ven afectados muy fácilmente por los valores atípicos, por lo que este método
es robusto (Robustez) es pobre y solo es adecuado para escenarios tradicionales de datos pequeños y precisos.
2. Definición:
Transforme los datos originales a un rango con una media de 0 y una desviación estándar de 1.
3, oficial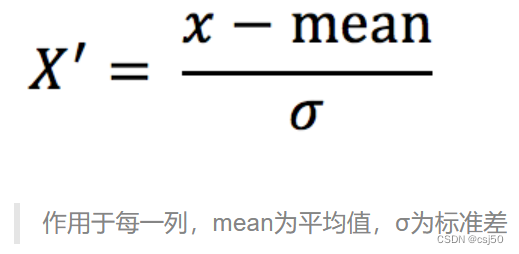
Resta la media de la columna de los datos y divide por la desviación estándar.
4. ¿Qué es la desviación estándar?

5. Después del procesamiento mediante la función API
sklearn.preprocessing.StandardScaler()
, para cada columna, todos los datos se agrupan alrededor de la media de 0 y la desviación estándar de 1.
6. StandardScaler.fit_transform(X)
X: datos en formato de matriz numpy [n_samples, n_features]
Valor de retorno: matriz con la misma forma después de la conversión
7. Estandarice los datos en dating.txt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction import DictVectorizer
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
from sklearn.preprocessing import MinMaxScaler, StandardScaler
import jieba
import pandas as pd
def datasets_demo():
"""
sklearn数据集使用
"""
#获取数据集
iris = load_iris()
print("鸢尾花数据集:\n", iris)
print("查看数据集描述:\n", iris["DESCR"])
print("查看特征值的名字:\n", iris.feature_names)
print("查看特征值几行几列:\n", iris.data.shape)
#数据集的划分
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=22)
print("训练集的特征值:\n", x_train, x_train.shape)
return None
def dict_demo():
"""
字典特征抽取
"""
data = [{'city': '北京','temperature':100},{'city': '上海','temperature':60},{'city': '深圳','temperature':30}]
# 1、实例化一个转换器类
transfer = DictVectorizer(sparse=False)
# 2、调用fit_transform()
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new)
print("特征名字:\n", transfer.get_feature_names())
return None
def count_demo():
"""
文本特征抽取
"""
data = ["life is short,i like like python", "life is too long,i dislike python"]
# 1、实例化一个转换器类
transfer = CountVectorizer()
# 2、调用fit_transform()
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new.toarray())
print("特征名字:\n", transfer.get_feature_names())
return None
def count_chinese_demo():
"""
中文文本特征抽取
"""
data = ["我 爱 北京 天安门", "天安门 上 太阳 升"]
# 1、实例化一个转换器类
transfer = CountVectorizer()
# 2、调用fit_transform
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new.toarray());
print("特征名字:\n", transfer.get_feature_names())
return None
def cut_word(text):
"""
进行中文分词
"""
return " ".join(list(jieba.cut(text))) #返回一个分词生成器对象,强转成list,再join转成字符串
def count_chinese_demo2():
"""
中文文本特征抽取,自动分词
"""
# 1、将中文文本进行分词
data = ["今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。",
"我们看到的从很远星系来的光是在几百万年前之前发出的,这样当我们看到宇宙时,我们是在看它的过去。",
"如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。"]
data_new = []
for sent in data:
data_new.append(cut_word(sent))
print(data_new)
# 2、实例化一个转换器类
transfer = CountVectorizer()
# 3、调用fit_transform()
data_final = transfer.fit_transform(data_new)
print("data_final:\n", data_final.toarray())
print("特征名字:\n", transfer.get_feature_names())
return None
def tfidf_demo():
"""
用tf-idf的方法进行文本特征抽取
"""
# 1、将中文文本进行分词
data = ["今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。",
"我们看到的从很远星系来的光是在几百万年前之前发出的,这样当我们看到宇宙时,我们是在看它的过去。",
"如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。"]
data_new = []
for sent in data:
data_new.append(cut_word(sent))
print(data_new)
# 2、实例化一个转换器类
transfer = TfidfVectorizer()
# 3、调用fit_transform()
data_final = transfer.fit_transform(data_new)
print("data_final:\n", data_final.toarray())
print("特征名字:\n", transfer.get_feature_names())
return None
def minmax_demo():
"""
归一化
"""
# 1、获取数据
data = pd.read_csv("dating.txt")
#print("data:\n", data)
data = data.iloc[:, 0:3] #行都要,列取前3列
print("data:\n", data)
# 2、实例化一个转换器
transfer = MinMaxScaler()
# 3、调用fit_transform
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new)
return None
def stand_demo():
"""
标准化
"""
# 1、获取数据
data = pd.read_csv("dating.txt")
#print("data:\n", data)
data = data.iloc[:, 0:3] #行都要,列取前3列
print("data:\n", data)
# 2、实例化一个转换器
transfer = StandardScaler()
# 3、调用fit_transform
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new)
return None
if __name__ == "__main__":
# 代码1:sklearn数据集使用
#datasets_demo()
# 代码2:字典特征抽取
#dict_demo()
# 代码3:文本特征抽取
#count_demo()
# 代码4:中文文本特征抽取
#count_chinese_demo()
# 代码5:中文文本特征抽取,自动分词
#count_chinese_demo2()
# 代码6: 测试jieba库中文分词
#print(cut_word("我爱北京天安门"))
# 代码7:用tf-idf的方法进行文本特征抽取
#tfidf_demo()
# 代码8:归一化
#minmax_demo()
# 代码9:标准化
stand_demo()
resultado de la operación:
data:
milage liters consumtime
0 40920 8.326976 0.953952
1 14488 7.153469 1.673904
2 26052 1.441871 0.805124
3 75136 13.147394 0.428964
4 38344 1.669788 0.134296
.. ... ... ...
984 11145 3.410627 0.631838
985 68846 9.974715 0.669787
986 26575 10.650102 0.866627
987 48111 9.134528 0.728045
988 43757 7.882601 1.332446
[989 rows x 3 columns]
data_new:
[[ 0.33984938 0.42024644 0.2460588 ]
[-0.86581884 0.14356328 1.69344575]
[-0.338339 -1.2030865 -0.05314407]
...
[-0.31448289 0.96798056 0.07050117]
[ 0.66785937 0.61064669 -0.2081032 ]
[ 0.46925618 0.31547409 1.00698075]]
8. Resumen de estandarización:
es relativamente estable cuando hay suficientes muestras y es adecuado para escenarios modernos y ruidosos de big data.