Tabla de contenido
1. Método de procesamiento de normalización
(1) método min-max (normalización discreta)
(2) Método de normalización de media cero
(3) Estandarización de la calibración decimal
(1) Método de interpolación de Lagrange
(1) Coeficiente de correlación de Pearson
(2) coeficiente de correlación de Spearman
4. Análisis de componentes principales (PCA)
1. Método de procesamiento de normalización
Los métodos comunes de normalización son:
(1) método min-max (normalización discreta)
Una transformación lineal de los datos originales, asignando los puntos de datos al intervalo [0,1] (predeterminado)
En general, llame a la función min_max_scaler en la biblioteca sklearn para implementar, el código es el siguiente:
from sklearn import preprocessing
import numpy as np
x = np.array(
[[1972, 685, 507, 962, 610, 1434, 1542, 1748, 1247, 1345],
[262, 1398, 1300, 1056, 552, 1306, 788, 1434, 907, 1374],])
# 调用min_max_scaler函数
min_max_scaler = preprocessing.MinMaxScaler()
minmax_x = min_max_scaler.fit_transform(x)(2) Método de normalización de media cero
Transforma la distribución de valores propios a media cero. Este enfoque puede eliminar la diferencia de magnitud entre las diferentes funciones (o muestras) y hacer que la distribución de las funciones sea más cercana entre sí. En algunos modelos (como SVM), puede mejorar en gran medida el efecto de procesamiento y hacer que el modelo sea más preciso. Estable y mejorar la precisión de la predicción.
Código:
import numpy as np
# 零-均值规范化
def ZeroAvg_Normalize(data):
text=(data - data.mean())/data.std()
return text(3) Estandarización de la calibración decimal
La normalización de la escala decimal consiste en normalizar moviendo la posición del punto decimal. La cantidad de lugares que se mueve el punto decimal depende del valor absoluto máximo del valor del atributo A.
El código de implementación es el siguiente:
import numpy as np
# 小数定标规范化
def deci_sca(data):
new_data=data/(10**(np.ceil(np.log10(data.max()))))
return new_data2. Método de interpolación
Interpolar una función continua sobre la base de datos discretos para que esta curva continua pase por todos los puntos de datos discretos dados.
La interpolación es un método importante de aproximación, que se puede utilizar para estimar el valor aproximado de la función en otros puntos a través del valor de la función en un número limitado de puntos.
En la aplicación de imágenes, es para llenar los vacíos causados por la transformación de imágenes.
(1) Método de interpolación de Lagrange
Las funciones de base de nodo se dan en los nodos, y luego se realiza la combinación lineal de las funciones de base, y el coeficiente de combinación es una especie de polinomio de interpolación de los valores de función de nodo.
Se puede realizar llamando al método lagrange en la biblioteca scipy, el código es el siguiente:
'''拉格朗日插值法实现'''
from scipy.interpolate import lagrange
import numpy as np
x_known = np.array([987,1325,1092,475,2911])
y_known = np.array([372,402,1402,1725,1410])
new_data = lagrange(x_known,y_known)(4)
print(new_data)3. Análisis de correlación
(1) Coeficiente de correlación de Pearson
El producto de la covarianza dividida por la desviación estándar, el coeficiente de correlación de Pearson es una correlación lineal, y el coeficiente de correlación de Pearson presenta una relación lineal entre variables continuas normalmente distribuidas.
Se puede realizar llamando al método corr() y definiendo el parámetro como el método pearson.El código es el siguiente:
# pearson相关系数计算
corr_pearson = df.corr(method='pearson')(2) coeficiente de correlación de Spearman
El coeficiente de correlación de Pearson entre variables de rango (orden), el coeficiente de correlación de spearman presenta una correlación no lineal, y el coeficiente de correlación de spearman no requiere normal continuo, pero al menos ordenado.
# spearman相关系数计算
corr_spearman = df.corr(method='spearman')4. Análisis de componentes principales (PCA)
El análisis de componentes principales (PCA) es un método estadístico que convierte un grupo de variables que pueden estar correlacionadas en un grupo de variables linealmente no correlacionadas mediante una transformación ortogonal. El grupo de variables convertidas se denomina componente principal.
En el preprocesamiento de datos, a menudo usamos el método de PCA para reducir la dimensionalidad de los datos y asignar características n-dimensionales a la dimensión K. Esta dimensión k es una nueva característica ortogonal, también conocida como componente principal, que se basa en la característica n-dimensional original Las características k-dimensionales reconstruidas sobre la base de .
Los pasos específicos de implementación son los siguientes:
1) En primer lugar, estandarice los datos para eliminar la influencia de diferentes dimensiones en los datos, y el método de valor extremo se puede usar para la estandarización.
y estandarización de la desviación estándar.
2) Encuentre la matriz de varianza basada en los datos estandarizados.
3) Calcular las raíces características y las variables características de la matriz de covariables, y determinar los componentes principales según las raíces características.
4) Combinar el conocimiento profesional y la información contenida en cada componente principal para dar una explicación adecuada.
Puede llamar directamente al método pca en sklearn, el código es el siguiente:
# 调用sklearn的PCA
from sklearn.decomposition import PCA
import numpy as np
import pandas as pd
df=pd.DataFrame({'能力':[66,65,57,67,61,64,64,63,65,67,62,68,65,62,64],
'品格':[64,63,58,69,61,65,63,63,64,69,63,67,65,63,66],
'担保':[65,63,63,65,62,63,63,63,65,69,65,65,66,64,66],
'资本':[65,65,59,68,62,63,63,63,66,68,64,67,65,62,65],
'环境':[65,64,66,64,63,63,64,63,64,67,64,65,64,66,67]
})
#调用sklearn中的PCA函数对数据进行主成分分析
pca=PCA()
pca.fit(df) # 用训练数据X训练模型
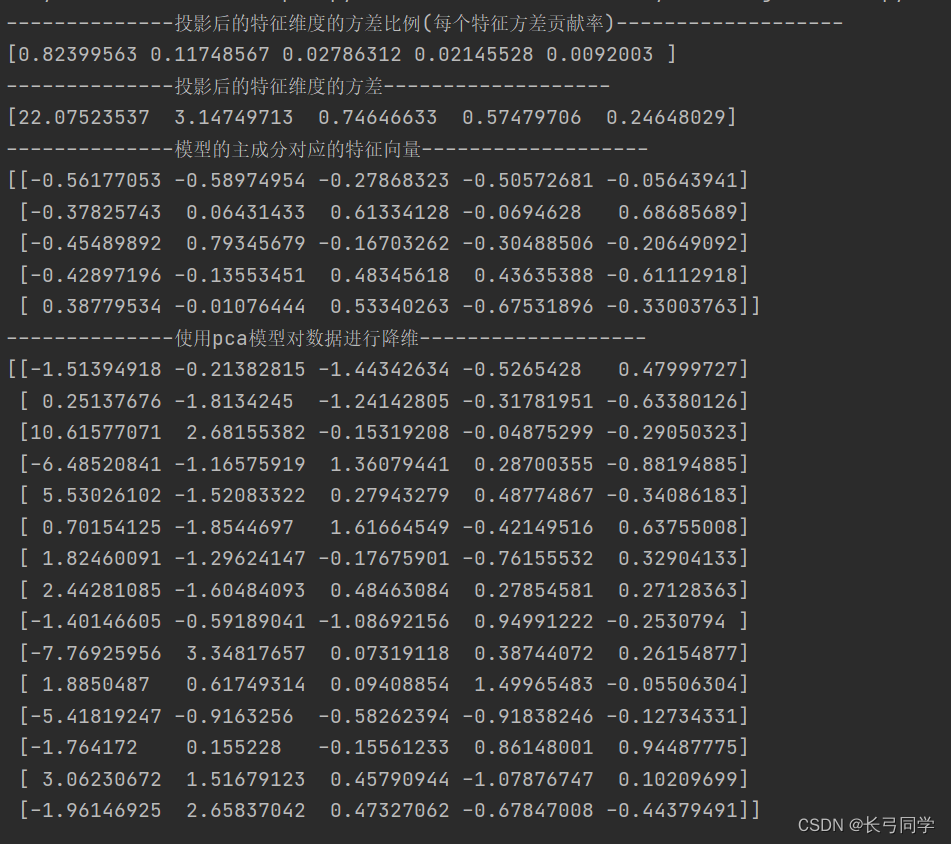
'''投影后的特征维度的方差比例'''
print('--------------投影后的特征维度的方差比例(每个特征方差贡献率)-------------------')
print(pca.explained_variance_ratio_)
'''投影后的特征维度的方差'''
print('--------------投影后的特征维度的方差-------------------')
print(pca.explained_variance_)
print('--------------模型的主成分对应的特征向量-------------------')
print(pca.components_)
print('--------------使用pca模型对数据进行降维-------------------')
print(pca.transform(df))# 对数据进行降维
resultado de la operación: