En los últimos años, hemos sido testigos de muchos cambios en el campo del aprendizaje automático y la informática. La aplicación de la inteligencia artificial también es cada vez más extensa y acelera su integración en el día a día de las personas. Como núcleo de la tecnología, el aprendizaje automático también se desarrolla y evoluciona continuamente, desempeñando un papel cada vez más importante en más campos. **¿Qué nuevas tendencias de evolución y direcciones de desarrollo tendrá el aprendizaje automático? **¿Cómo debemos planificar con anticipación y mantenernos al día con los cambios de vanguardia de esta popular tecnología?
| La comunidad de desarrolladores de tecnología en la nube de Amazon proporciona a los desarrolladores recursos de tecnología de desarrollo global. Hay documentos técnicos, casos de desarrollo, columnas técnicas, videos de capacitación, actividades y concursos, etc. Ayude a los desarrolladores chinos a conectarse con las tecnologías, ideas y proyectos más vanguardistas del mundo, y recomiende desarrolladores o tecnologías chinos sobresalientes a la comunidad global de la nube. Si aún no ha prestado atención / favorito, no se apresure cuando vea esto, ¡ haga clic aquí para convertirlo en su tesoro técnico! |
La serie de artículos "Machine Learning Insights" interpretará y analizará las cuatro posibles tendencias de evolución del aprendizaje automático en la práctica en función del estado de desarrollo actual del aprendizaje automático, incluido el aprendizaje automático multimodal, la capacitación distribuida, el razonamiento sin servidor y JAX es un nuevo emergente . marco de aprendizaje profundo.
¿Qué es el aprendizaje automático en datos multimodales?
Los sonidos que escucha la gente, la comida que ven y los olores que huelen son todos información modal, y vivimos en un entorno donde la información multimodal se mezcla entre sí.
Para que la inteligencia artificial comprenda mejor el mundo, las personas deben darle a la inteligencia artificial la capacidad de aprender a comprender y razonar sobre la información multimodal. El aprendizaje automático de datos multimodales se refiere al proceso de establecer modelos para permitir que las máquinas aprendan información modal variada de múltiples modalidades, y para realizar el intercambio de información y la conversión de cada modal.
Las aplicaciones multimodales tienen una amplia gama, que abarca no solo los altavoces de inteligencia artificial, los sistemas de recomendación de productos de comercio electrónico, el reconocimiento de imágenes y otros escenarios de la vida, sino también algunos campos industriales, como la navegación y la conducción automática, la investigación de patologías fisiológicas, la vigilancia medioambiental y la previsión meteorológica. etc., también puede admitir la comunicación entre humanos virtuales y humanos en la futura escena de Metaverse, etc.
Evolución en el campo del aprendizaje multimodal
Con la creciente popularidad del aprendizaje automático de datos multimodales, la investigación sobre el aprendizaje automático de datos multimodales ha dado paso a muchos avances innovadores, especialmente los siguientes tres avances importantes:
-
ZSL:Zero-Shot Learning (Universidad de Tübingen, 2009)
-
CLIP: Pre-entrenamiento en Pares Texto-Imagen Contrastivos (OpenAI, 2021)
-
ZESREC: Sistema de recomendación basado en Zero-Shot (Amazon, 2021)
Aprendizaje de tiro cero (ZSL)
Aprenda algunos atributos a través de las imágenes del conjunto de entrenamiento, combine estos atributos para obtener características de fusión y haga coincidir las imágenes del conjunto de prueba que no se superponen con las imágenes del conjunto de entrenamiento para juzgar su categoría.Este proceso es Zero-Shot Learning (ZSL), es decir , Las características de las imágenes vistas se utilizan para juzgar las categorías de imágenes que no se han visto.
Comencemos con una analogía con el proceso de razonamiento general de los humanos:
Supongamos que Xiao Ming y su padre fueron al zoológico a jugar juntos. Primero, vio un caballo, por lo que su padre le dijo a Xiao Ming que el caballo tenía esta forma; después de eso, volvió a ver un tigre y su padre le dijo a Xiao Ming: "Mira, este animal con rayas en el cuerpo es un tigre". Finalmente, lo llevó a verlo de nuevo. Levantó al panda y le dijo: “Mira, este panda es blanco y negro”.
Luego, mi padre organizó una tarea para Xiao Ming, pidiéndole que encontrara un animal que nunca antes había visto en el zoológico, llamó cebra y le contó a Xiao Ming sobre la cebra: "La cebra tiene el contorno de un caballo, y su cuerpo es como un tigre, tiene rayas y es blanco y negro como un panda". Finalmente, Xiao Ming encontró una cebra en el zoológico de acuerdo con las indicaciones de su padre.
El ejemplo anterior contiene un proceso de razonamiento humano, que consiste en utilizar conocimientos pasados (descripciones de caballos, tigres y pandas) para inferir la forma específica de un nuevo objeto (cebra) en la mente , de modo que se pueda identificar el nuevo objeto.
Por ejemplo, en la figura a continuación, algunos atributos (como caballo, rayas y blanco y negro) se aprenden de las imágenes del conjunto de entrenamiento (Datos de clases vistas), y luego estos atributos se combinan para obtener características de fusión. características de cebra del conjunto de prueba Finalmente, el resultado predicho es Zebra:

Fuente de la imagen: Documento " Aprender a detectar clases de objetos invisibles mediante la transferencia de atributos entre clases (Universidad de Tübingen, 2009) "
El aprendizaje Zero-Shot incluye un proceso de razonamiento, que es cómo usar el conocimiento pasado para inferir la forma específica de un nuevo objeto en la mente, a fin de identificar el nuevo objeto.
Hoy en día, aunque el aprendizaje profundo y el aprendizaje supervisado pueden dar resultados sorprendentes en muchas tareas, este método de aprendizaje también tiene las siguientes desventajas:
- Se requieren suficientes datos de muestra y la carga de trabajo de etiquetado de muestras es enorme
- Los resultados de la clasificación dependen de las muestras de entrenamiento y no pueden razonar e identificar nuevas categorías.
Obviamente, esto es difícil de satisfacer la última imaginación de los seres humanos sobre la inteligencia artificial. Y Zero-Shot Learning espera simular la capacidad de los seres humanos para identificar nuevas categorías a través del razonamiento, de modo que las computadoras tengan la capacidad de identificar cosas nuevas y luego realizar una inteligencia real.
CLIP: Pre-entrenamiento en Pares Texto-Imagen Contrastivos
Antes de 2021, muchos métodos de formación previa en el campo del procesamiento del lenguaje natural (PNL) han tenido éxito. Por ejemplo, GPT-3 175B recolectó casi 500 millones de tokens de Internet para capacitación previa y logró un rendimiento SOTA (State-of-the-Art) y Zero-Shot Learning en muchas tareas posteriores. Esto muestra que el aprendizaje a partir de datos masivos de Internet (a escala web) puede superar los conjuntos de datos de NLP de alta calidad etiquetados por humanos.
Sin embargo, el modelo de pre-entrenamiento en el campo de Computer Vision (CV) todavía se entrena principalmente en base a datos de ImageNet etiquetados manualmente. Debido a la enorme carga de trabajo del etiquetado manual, muchos científicos comenzaron a imaginar cómo construir una forma más eficiente y conveniente de entrenar modelos de representación visual.
En el documento " Aprendizaje de modelos visuales transferibles a partir de la supervisión del lenguaje natural " publicado en 2021 , se presentó con gran detalle el modelo CLIP (entrenamiento previo de imagen y lenguaje contrastivo) y se presentó en detalle cómo entrenar modelos visuales transferibles a través de señales de supervisión de procesamiento de lenguaje natural. .modelo.
¿Cómo lidiar con la señal supervisora de la PNL en el papel?
El documento presenta principalmente las siguientes tres partes:
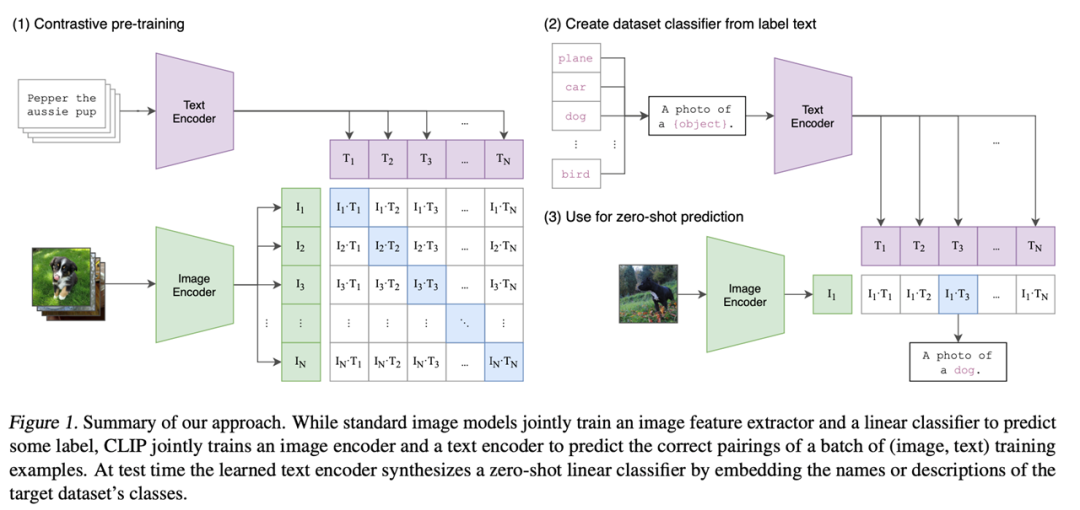
Imagen del papel
Parte 1: Pre-entrenamiento contrastivo.
Durante el proceso de entrenamiento, se utilizan dos codificadores: un codificador de texto y un codificador de imagen para completar el emparejamiento de las entradas del modelo para formar N conjuntos de características de imagen y texto. Los grupos de funciones en la diagonal azul en la matriz anterior se usan como muestras positivas, y los otros grupos de funciones blancas se usan como muestras negativas. CLIP realizará un aprendizaje comparativo basado en estas funciones sin ningún tipo de etiquetado manual.
Cabe señalar que este tipo de aprendizaje contrastivo no supervisado requiere mucho entrenamiento de datos. En el conjunto de datos del documento, hay 400 millones de pares de pares de texto e imágenes, lo que garantiza la calidad de los resultados de salida.
Parte II: Implementación de la Clasificación Zero-Shot con CLIP.
En las tareas posteriores, CLIP evita el uso de encabezados de clasificación especiales para permitir la transferencia de conjuntos de datos sin ningún ajuste fino. En el documento, se diseña un método muy ingenioso, Plantilla de solicitud, que utiliza lenguaje natural para trasplantar ingeniosamente la tarea de clasificación al método de capacitación existente.
Parte III: Inferencia Zero-Shot.
Al ingresar la imagen de muestra en el codificador de imágenes para obtener las características de la imagen, luego use las características de esta imagen para calcular la similitud con todas las características del texto, seleccione la oración correspondiente a la característica del texto con la mayor similitud para completar la clasificación tarea, y finalmente formar la imagen de resultado.
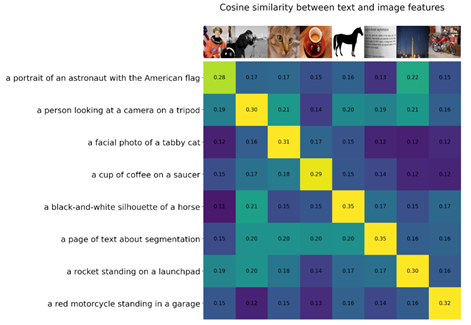
A través del cálculo, podemos ver que el modelo entrenado en base a CLIP es muy efectivo:

Imagen del papel
Este experimento se volvió a examinar en el conjunto de datos de ImageNet para producir varias versiones variantes.
La tasa de precisión del modelo ResNet 101 capacitado en el conjunto de datos de ImageNet es del 76,2 %, y la tasa de precisión del modelo VIT-Large capacitado con CLIP también es del 76,2 %. Sin embargo, cuando cambiamos a otros conjuntos de datos y volvemos a entrenar estrictamente de acuerdo con el encabezado de clasificación de 1000 categorías, la precisión del modelo obtenido cae rápidamente. Especialmente cuando se usan las dos últimas filas de muestras (boceto o muestras contradictorias) en la figura anterior, la precisión es solo del 25,2 % y el 2,7 %, que son básicamente conjeturas aleatorias, y el efecto de transferencia es terrible. En comparación con el modelo entrenado por CLIP, la tasa de precisión es básicamente en línea.
Esto se muestra desde un lado: debido a la combinación con el procesamiento del lenguaje natural, las características visuales aprendidas por CLIP tienen una fuerte conexión con un objeto que describimos en lenguaje.
Ejemplo de código: ejecución de un modelo CLIP en Amazon SageMaker
Este ejemplo muestra cómo descargar y ejecutar un modelo CLIP, calcular la similitud entre imágenes arbitrarias y entradas de texto, y realizar la clasificación de imágenes ZSL.
- Descargue y ejecute el modelo CLIP, y podemos obtener el modelo que necesitamos después de ingresarlo;
import clip
clip.available_models()model, preprocess = clip.load("ViT-B/32")
model.cuda().eval()
input_resolution = model.visual.input_resolution
context_length = model.context_length
vocab_size = model.vocab_size
Fuente de la imagen: conjunto de datos de ImageNet
- Calcule la similitud: calcule la similitud del coseno normalizando las características y calculando el producto punto para cada par.
Fuente de la imagen: conjunto de datos CIFAR100
- Clasificación de imágenes ZSL: clasifica las imágenes utilizando la similitud del coseno (multiplicada por 100) como el logaritmo de la operación softmax.
from torchvision.datasets import CIFAR100
cifar100 = CIFAR100(os.path.expanduser("~/.cache"), transform=preprocess, download=True)
text_descriptions = [f"This is a photo of a {label}" for label in cifar100.classes]
text_tokens = clip.tokenize(text_descriptions).cuda()
with torch.no_grad():
text_features = model.encode_text(text_tokens).float()
text_features /= text_features.norm(dim=-1, keepdim=True)
text_probs = (100.0 * image_features @ text_features.T).softmax(dim=-1)
top_probs, top_labels = text_probs.cpu().topk(5, dim=-1)El resultado final de realizar la clasificación de imágenes ZSL se muestra aquí: los resultados coincidentes del modelo CLIP ViT-B/32 con las etiquetas de clasificación del conjunto de imágenes CIFAR100 en un conjunto de imágenes que el modelo nunca ha visto (aquí el conjunto de imágenes CIFAR100) .
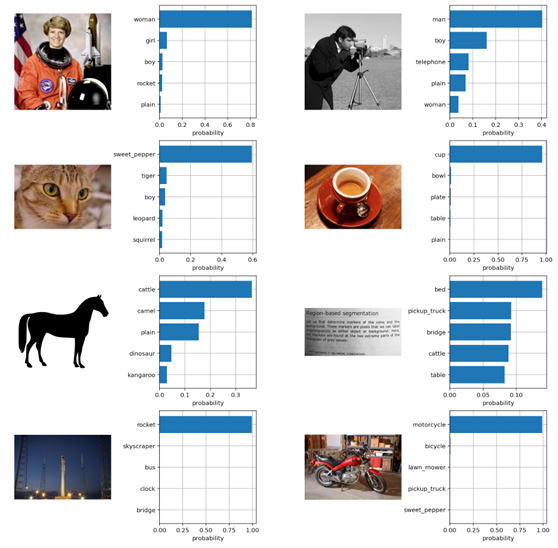
Fuente de la imagen: conjunto de datos CIFAR100
Todo el proceso no necesita ajustes posteriores, ni capacitación en el conjunto de datos, ni evaluación directa en el punto de referencia.
Para obtener el código completo del documento CLIP, consulte: GitHub - openai/CLIP: CLIP (Entrenamiento previo de imagen de lenguaje contrastivo), Prediga el fragmento de texto más relevante dada una imagen
ZESREC: Sistema de recomendación basado en Zero-Shot
Además, en el aprendizaje automático de datos multimodales, además de CLIP, también tenemos otras exploraciones, como AI Labs de Amazon Cloud Technology.
En el documento " Sistemas de recomendación Zero-Shot ", se comparte la idea básica, es decir, la información de descripción del producto entrenada por BERT se usa para reemplazar la incrustación de identificación del producto como entrada del producto, la capa superior conecta mlp a 300 dim, y luego conecta hmn para aprender características de secuencia.
Para la recomendación de productos y usuarios que no han aparecido, resuelve muy bien el problema de arranque en frío recomendado, e incluso tiene un buen rendimiento en Zero-Shot entre conjuntos de datos, lo que es adecuado para el omnicanal (Omni-Channel) de nueva venta al por menor, y ampliar y aumentar la dimensión de entrada, como video y mapa de productos, etc.
Caso de arquitectura: entrenamiento de modelos en datos multimodales
La arquitectura de implementación de referencia de la tubería de datos multimodal en el campo de las ciencias de la vida se presenta en la siguiente figura.
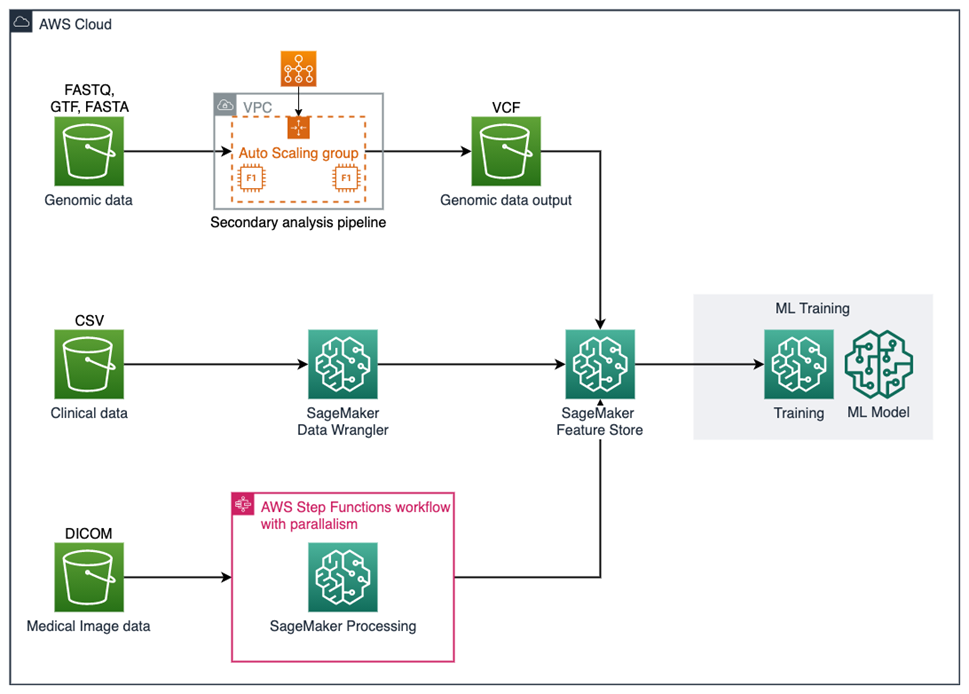
Fuente de la imagen: Blog oficial " Entrenamiento de modelos de aprendizaje automático con datos de salud multimodales en Amazon SageMaker "
La arquitectura procesará datos de datos genómicos, datos clínicos e imágenes médicas, y cargará las capacidades de procesamiento para cada modalidad en la tienda de características de Amazon SageMaker .
Este ejemplo muestra cómo agrupar características de diferentes modalidades y entrenar un modelo predictivo que supera a los modelos entrenados en una o ambas modalidades de datos.
Continuaremos presentando la capacitación distribuida, el razonamiento sin servidor y la tendencia de evolución del marco JAX en artículos posteriores. Continúe prestando atención a la cuenta oficial de WeChat de Build On Cloud.
Con la creciente importancia del aprendizaje automático y el enriquecimiento continuo de la investigación tecnológica relacionada, se cree que la tecnología en torno al aprendizaje automático mejorará gradualmente en el futuro, y esto potenciará y promoverá la inteligencia artificial y otros campos técnicos para marcar el comienzo de un desarrollo más amplio. espacio, beneficiar a la humanidad.

Autor Huang Haowen
Evangelista desarrollador sénior de Amazon Cloud Technology, centrado en AI/ML, ciencia de datos, etc. Con más de 20 años de rica experiencia en diseño de arquitectura, tecnología y gestión empresarial en las industrias de telecomunicaciones, Internet móvil y computación en la nube, ha trabajado en Microsoft, Sun Microsystems, China Telecom y otras empresas, centrándose en proporcionar a clientes corporativos como juegos, comercio electrónico, medios y publicidad Servicios de consultoría de soluciones como AI/ML, análisis de datos y transformación digital empresarial.
Fuente del artículo: https://dev.amazoncloud.cn/column/article/63e32a58e5e05b6ff897ca0c?sc_medium=regulartraffic&sc_campaign=crossplatform&sc_channel=CSDN