Decision Tree es un método de aprendizaje supervisado no paramétrico que puede resumir reglas de decisión a partir de una serie de datos con características y etiquetas, y presentar estas reglas en una estructura de dendrograma para resolver problemas de clasificación y regresión. Los algoritmos de árbol de decisión son fáciles de entender, aplicables a diversos datos y funcionan bien para resolver diversos problemas. En particular, varios algoritmos integrados con modelos de árbol como núcleo se utilizan ampliamente en diversas industrias y campos.
Base de clasificación
ganancia de información
En 1948, Shannon propuso el concepto de entropía de la información (Entropía).
Si la clasificación del evento A es (A1,A2,...,An), y la probabilidad de cada parte es (p1,p2,...,pn), entonces la entropía de la información se define como la siguiente fórmula: ( log se basa en 2, lg Base 10)
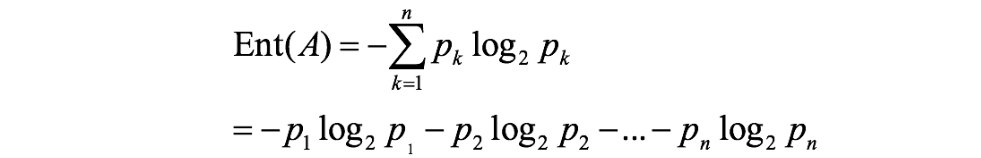 1. Entropía
1. Entropía
Se utiliza para medir el grado de orden de un objeto
Cuanto más ordenado sea el sistema, menor será el valor de entropía; cuanto más caótico o disperso sea el sistema, mayor será el valor de entropía .
2. Entropía de la información
●Descripción de la integridad de la información:
Cuando el estado ordenado del sistema es consistente, el valor de entropía es menor donde los datos están más concentrados y el valor de entropía es mayor donde los datos están más dispersos.
●Descripción del orden de la información:
Cuando la cantidad de datos es consistente, cuanto más ordenado es el sistema, menor es el valor de entropía; cuanto más caótico o disperso es el sistema, mayor es el valor de entropía.
Ganancia de información: la diferencia de entropía antes y después de dividir el conjunto de datos por una determinada característica. La entropía puede representar la incertidumbre de un conjunto de muestras: cuanto mayor es la entropía, mayor es la incertidumbre de la muestra. Por lo tanto , la diferencia en la entropía del conjunto antes y después de la división se puede usar para medir la efectividad del uso de las características actuales para dividir el conjunto de muestra D.
Ganancia de información = entrada (frontal) - entrada (post)
La ganancia de información g(D,A) de la característica A en el conjunto de datos de entrenamiento D, definida como la entropía de información H(D) del conjunto D y la información de D bajo el conjunto dado condiciones de la característica A La diferencia en entropía condicional H(D|A), es decir, la fórmula es:
g ( D , A ) = H ( D ) − H ( D ∣ A ) g(D,A)=H( D)-H(D|A)gramo ( D ,Un )=H ( D )−Explicación detallada de la
fórmula H ( D ∣ A )

: Caso:
como se muestra a la izquierda, la primera columna es el número del foro, la segunda columna es el género, la tercera columna es la actividad y la última columna es si el usuario está perdido. .
Necesitamos resolver un problema: ¿Cuál de las dos características, género y actividad, tiene un mayor impacto en la pérdida de usuarios?
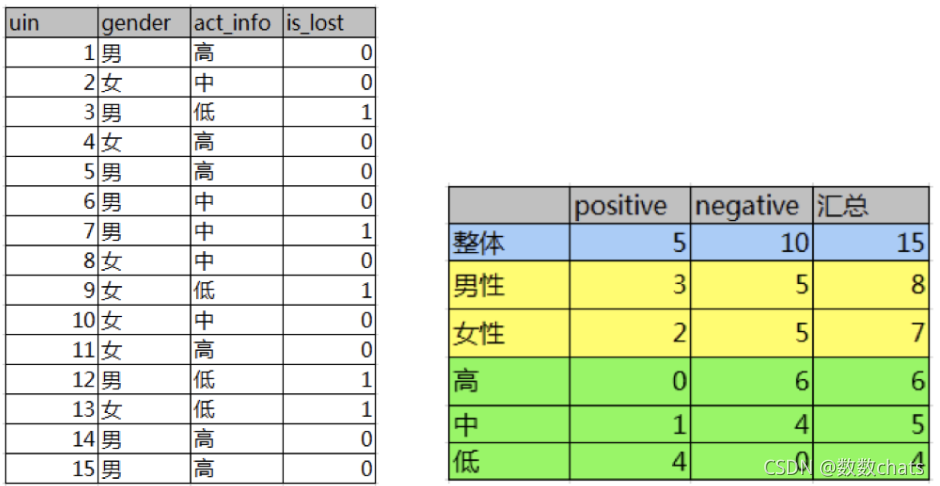
Este problema se puede resolver calculando la ganancia de información. Se cuenta la información en la tabla de la derecha.
Positivo es una muestra positiva (perdida), Negativo es una muestra negativa (no perdida), y los siguientes valores son los correspondientes número de personas bajo diferentes divisiones.
Se pueden obtener tres entropías:
entropía general:
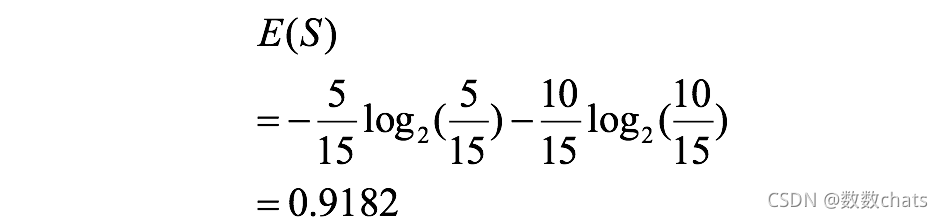
entropía de género:
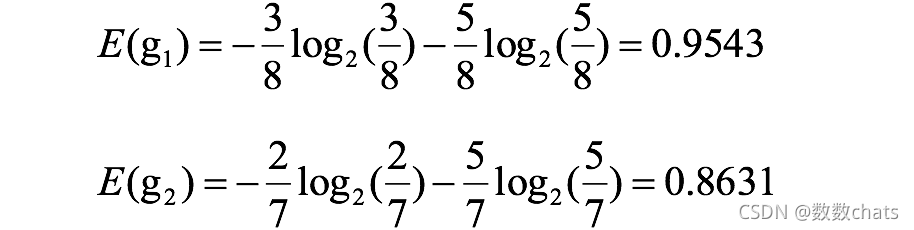
ganancia de información de género:
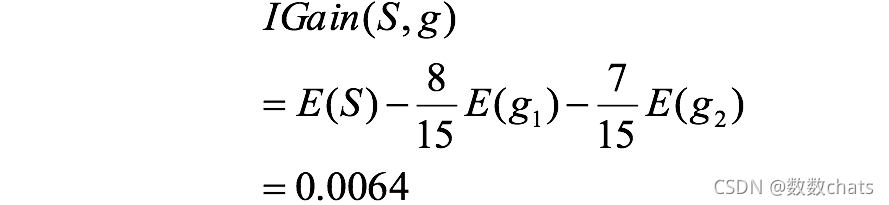
entropía de actividad:
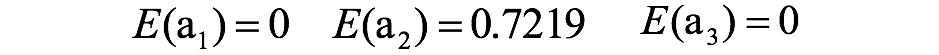
ganancia de información de actividad:
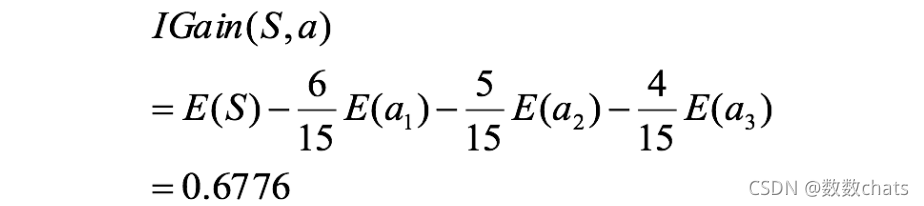 la ganancia de información de la actividad es mayor que la ganancia de información del género, es decir, el impacto de la actividad en la pérdida de usuarios es mayor que el del género grande.
la ganancia de información de la actividad es mayor que la ganancia de información del género, es decir, el impacto de la actividad en la pérdida de usuarios es mayor que el del género grande.
Al realizar la selección de funciones o el análisis de datos, debemos centrarnos en el indicador de actividad.
tasa de ganancia de información
**Relación de ganancia: **La métrica de relación de ganancia se define conjuntamente por la relación de la métrica de ganancia anterior Gain(S,A) y la métrica de información separada SplitInformation (como género, actividad, etc. en el ejemplo anterior).

Caso:
Como se muestra en la siguiente tabla: ¿Qué condiciones se deben cumplir antes de jugar al golf?
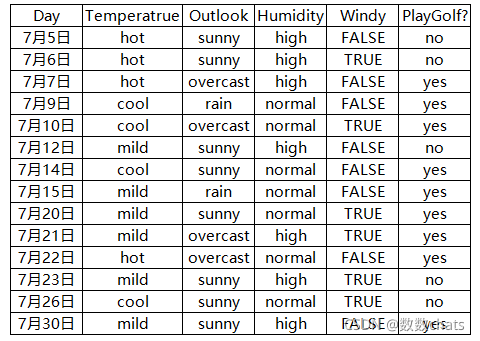
Entropía de información general: H ( Y ) = − 5 14 log 2 ( 5 14 ) − 9 14 log 2 ( 9 14 ) = 0.9403 H(Y)=-\frac{5}{14}\log_2(\frac {5}{14})-\frac{9}{14}\log_2(\frac{9}{14})=0,9403H ( Y )=−1 45iniciar sesión2(1 45)−1 49iniciar sesión2(1 49)=0 . 9 4 0 3
Busque cualquier dato meteorológico, prediga si jugará golf o no, configúrelo como una variable aleatoria Y.
Busque cualquier dato meteorológico. El tiempo (Outlook) es soleado (soleado), nublado (nublado) o lluvioso (lluvia), y configúrelo como una variable aleatoria X.
Cualquier dato meteorológico que llegue es soleado, configúrelo como evento x1;
cualquier dato meteorológico que llegue esté nublado, configúrelo como evento x2;
cualquier dato meteorológico que llegue sea lluvioso, configúrelo como evento x3 ;
el espacio de probabilidad de la variable aleatoria X es:
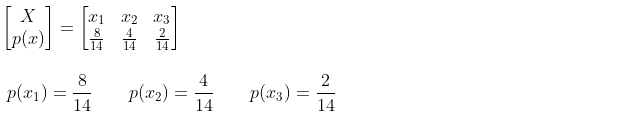
(1) Entropía de condiciones climáticas despejadas: H ( Y ∣ \frac{3}{8}\log_2(\frac{3}{8})-\frac{5}{8}\log_2(\frac{5} {8})=0,9544H ( Y ∣ X=X1)=−83iniciar sesión2(83)−85iniciar sesión2(85)=0 . 9 5 4 4
(2) Entropía de la condición de clima nublado: H ( Y ∣ X = x 2 ) = − 4 4 log 2 ( 4 4 ) − 0 4 log 2 ( 0 4 ) = 0 H(Y| \frac{4}{ 4}\log_2(\frac{4}{4})-\frac{0}{4}\log_2(\frac{0}{4})=0H ( Y ∣ X=X2)=−44iniciar sesión2(44)−40iniciar sesión2(40)=0
(3) Entropía de las condiciones climáticas lluviosas: H ( Y ∣ -\frac{2}{2}\log_2(\frac{2}{2})-\frac{0}{2}\log_2(\frac{0 {2})=0H ( Y ∣ X=X3)=−22iniciar sesión2(22)−20iniciar sesión2(20)=0
(4) Entropía de las condiciones climáticas: H ( Y ∣ X ) = ∑ x ∈ X p ( x ) H ( Y ∣ X ) H(Y|X)=\displaystyle\sum_{x\in (Y|X)H ( Y ∣ X )=x∈X _ _∑p ( x ) H ( Y ∣ X ) = p ( x 1 ) H ( Y ∣ X = x 1 ) + p ( x 2 ) H ( Y ∣ X = x 2 ) + p ( x 3 ) H ( Y ∣ X = x 3 ) = 8 14 × 0.9544 + 4 14 × 0 + 2 14 × 0 = 0.5454 =p(x_1)H(Y|X=x_1)+p(x_2)H(Y|X=x_2)+p (x_3)H(Y|X=x_3)=\frac{8}{14}×0.9544+\frac{4}{14}×0+\frac{2}{14}×0=0.5454=pag ( x1) H ( Y ∣ X=X1)+pag ( x2) H ( Y ∣ X=X2)+pag ( x3) H ( Y ∣ X=X3)=1 48×0 . 9 5 4 4+1 44×0+1 42×0=0 . 5 4 5 4
(5) Ganancia de información meteorológica: g ( Y , X ) = H ( Y ) − H ( Y |gramo ( Y ,X )=H ( Y )−H ( Y ∣ X )=0 . 3 9 4 9
tasa de ganancia de información
(1) Información interna de la fecha del día: I nt I ( D , D ay ) = 14 × ( − 1 14 × log 2 ( 1 14 ) ) = 3.8074 IntI(D,Day)=14×(-\frac{ 1}{14}×\log_2(\frac{1}{14}))=3.8074En t yo ( D , _día ) _ _=1 4×( -1 41×iniciar sesión2(1 41) )=3 . 8 0 7 4
(2) Información interna del clima de Outlook: Int I (D, O outlook) = − 8 14 log 2 ( 8 14 ) − 4 14 log 2 ( 4 14 ) − 2 14 log 2 ( 2 14 ) = 1.3788 IntI(D,Outlook)=-\frac{8}{14}\log_2(\frac{8}{14})-\frac{4}{14}\log_2(\frac{4}{14}) -\frac{2}{14}\log_2(\frac{2}{14})=1,3788En t yo ( D , _mirar hacia afuera ) _ _ _ _=−1 48iniciar sesión2(1 48)−1 44iniciar sesión2(1 44)−1 42iniciar sesión2(1 42)=1 . 3 7 8 8
(3) Tasa de ganancia de información de fecha del día: g ( D ∣ D ay ) = g ( D , D ay ) Int I ( D , D ay ) = 0,9403 3,8074 = 0,247 g(D|Day)=\frac{g (D,Día)}{IntI(D,Día)}=\frac{0.9403}{3.8074}=0.247gramo ( D ∣ D a y )=En t I ( D , Día ) _ _ _g ( D , Día y ) _=3 . 8 0 7 40 . 9 4 0 3=0 . 2 4 7
(4)La perspectiva es la variable dependiente: g ( D ∣ O perspectiva ) = g ( D , O perspectiva ) Int I ( D , O perspectiva ) = 0,3949 1,3788 = 0,2864 g(D|Perspectiva)=\frac{g ( D,Outlook)}{IntI(D,Outlook)}=\frac{0.3949}{1.3788}=0.2864gramo ( D ∣ Afuera mirar ) _ _ _ _ _=In t I ( D , perspectiva ) _ _ _ _ _ _ _g ( D , exterior ) _ _ _ _ _ _=1 . 3 7 8 80 . 3 9 4 9=0 . 2 8 6 4
Valor de Gini e índice de Gini
**Valor de Gini Gini (D): **La probabilidad de que dos muestras se seleccionen aleatoriamente del conjunto de datos D y sus etiquetas de clase sean inconsistentes. Por lo tanto, cuanto menor sea el valor de Gini(D), mayor será la pureza del conjunto de datos D.
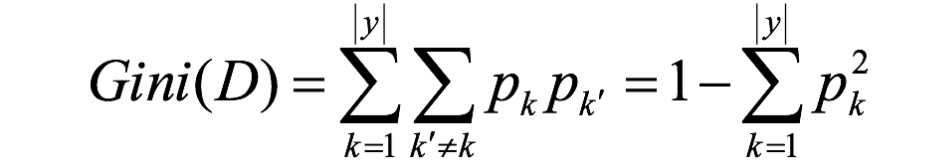
**Gini_index (D): **Generalmente, el atributo que minimiza el coeficiente de Gini después de la división se selecciona como el subatributo óptimo.
Caso
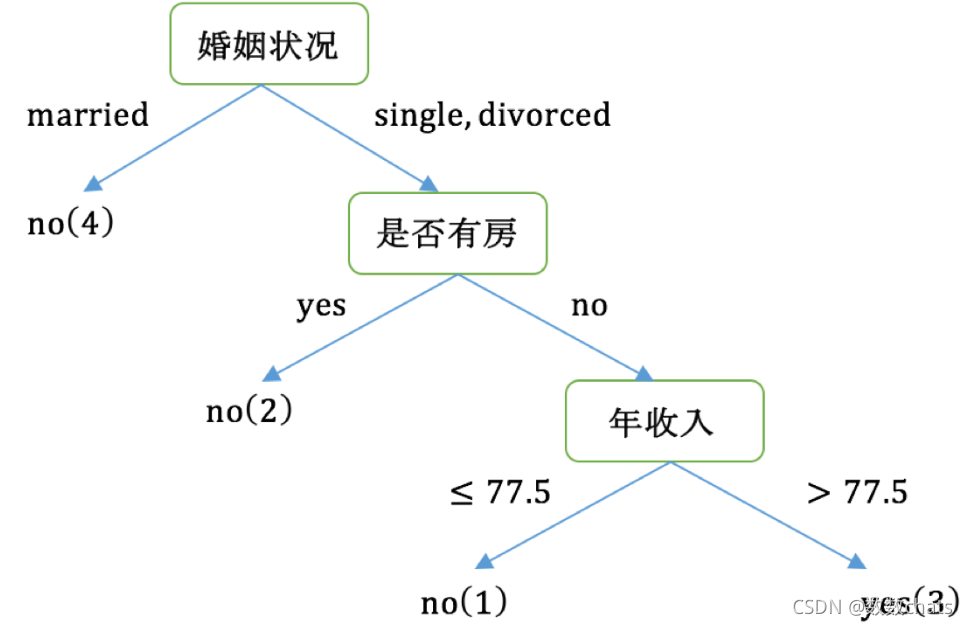
Por favor haga un árbol de decisión basado en la lista siguiente y la base de división del índice de Gini.
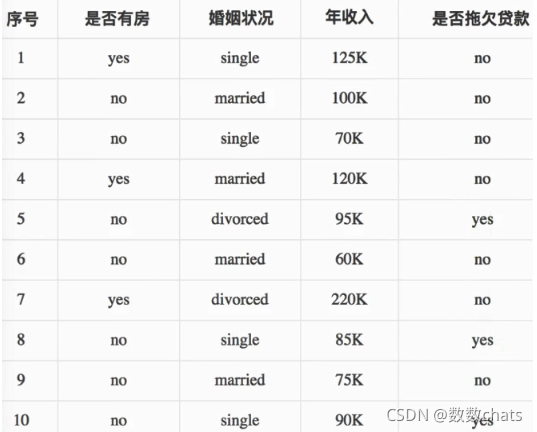
1. Calcule sus ganancias del coeficiente de Gini respectivamente para los atributos de etiqueta que no son de clase del conjunto de datos {si es propietario de una casa, estado civil, ingreso anual} y tome el atributo con el mayor valor de ganancia del coeficiente de Gini como atributo del nodo raíz de el árbol de decisión.
2. El coeficiente de Gini del nodo raíz es:
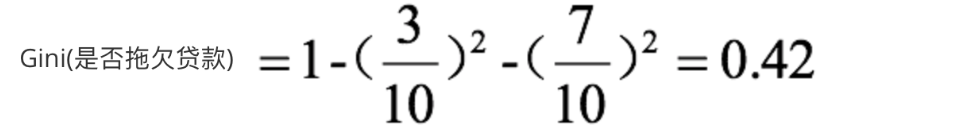
3. Cuando se divide según si hay una casa, el proceso de cálculo de ganancia del coeficiente de Gini es:
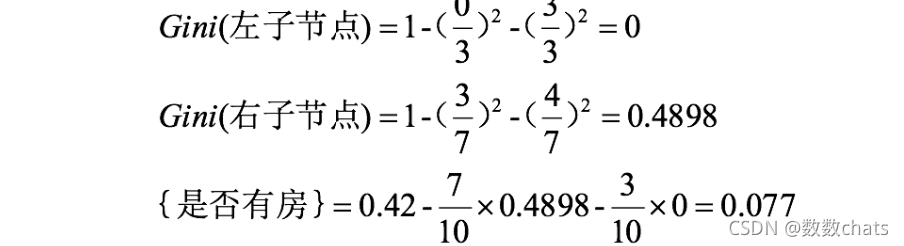
4. Si se divide según el atributo de estado civil, el atributo de estado civil tiene tres valores posibles {casado, soltero, dividido}, calcule respectivamente la ganancia del coeficiente de Gini después de la división.
{casado} | {soltero,divorciado}
{soltero} | {casado,divorciado}
{divorciado} |
{soltero,casado} se agrupa en
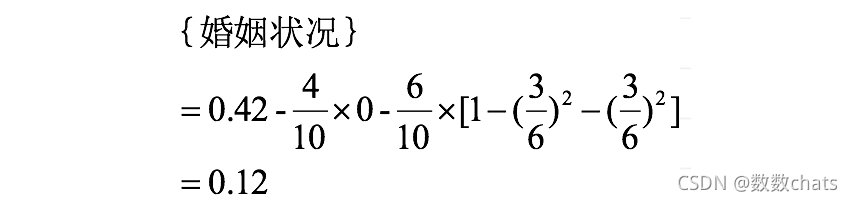 {casado} | Cuando está divorciado}:
{casado} | Cuando está divorciado}:

Cuando la agrupación es {divorciada} | {soltero,casado }:

compare los resultados del cálculo y, al dividir el nodo raíz según el atributo de estado civil, tome el grupo con la mayor ganancia del coeficiente de Gini como resultado de la división, a saber: {casado} | {soltero, divorciado}
5. De la misma manera, se puede obtener el Gini del ingreso anual:
dado que el atributo del ingreso anual es un atributo numérico, primero, los datos deben ordenarse en orden ascendente y luego las muestras se dividen en dos grupos usando el medio valor del valor adyacente como separador de pequeño a grande. Por ejemplo, ante dos valores de renta anual de 60 y 70, calculamos que el valor medio es 65. Utilice el valor medio 65 como punto divisorio para encontrar la ganancia del coeficiente de Gini.
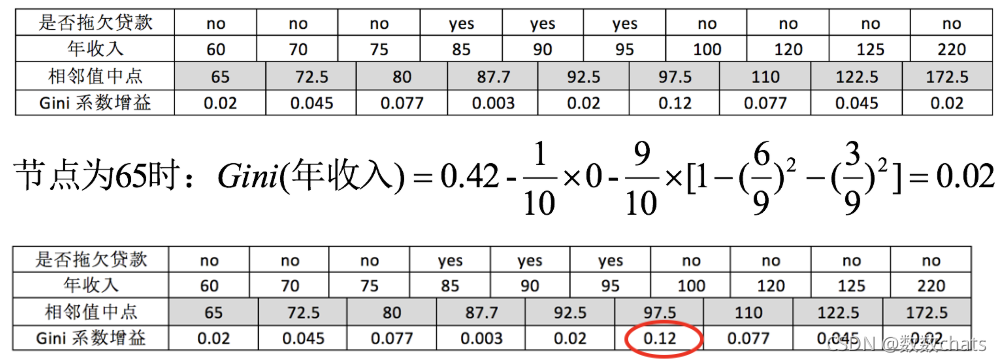
Maximizar la ganancia equivale a minimizar el promedio ponderado de las medidas de impureza (coeficientes de Gini) de los nodos secundarios , y ahora queremos maximizar la ganancia de los coeficientes de Gini. Según los cálculos, hay dos que tienen la mayor ganancia entre los tres atributos que dividen el nodo raíz: el atributo de ingreso anual y el estado civil, sus ganancias son ambos de 0,12. En este momento, el atributo que aparece primero se selecciona como primera división.
6. A continuación, utilice el mismo método para calcular los atributos restantes respectivamente. El coeficiente de Gini del nodo raíz es (en este momento, hay 3 registros para si el préstamo está en mora). 7. Para el atributo de si
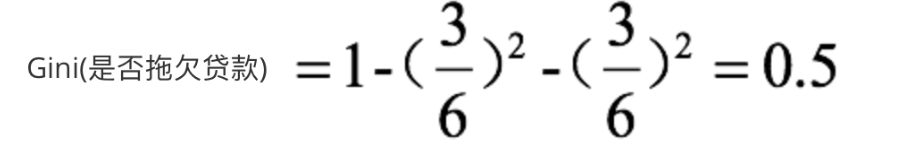
hay una casa, podemos obtener:
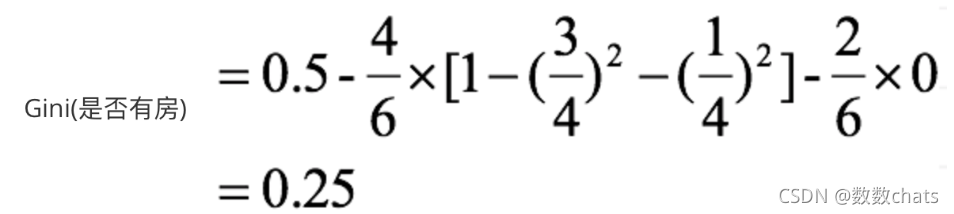
8. Para Los atributos de ingreso anual son:

resumen
1. Ganancia de información
Ganancia de información = entrada (frente) - entrada (posterior)
Nota: Cuanto mayor sea la ganancia de información, le damos prioridad a este atributo para el cálculo. La
ganancia de información primero selecciona el atributo con más categorías para dividir
. 2. La información La tasa de ganancia
mantiene una métrica de información de separación, utilizando esta métrica de información de separación como denominador, límite
3. Ganancia de Gini
● Valor de Gini: se seleccionan dos muestras al azar del conjunto de datos D, menor será la probabilidad del valor de Gini (D)
de la categoría. La etiqueta es inconsistente , el conjunto de datos
cuanto mayor sea la pureza de D.
Índice de Gini:
seleccione el atributo con el coeficiente de Gini más pequeño después de la división como atributo óptimo
Ganancia de Gini:
seleccione el punto con la ganancia de Gini más grande para una división óptima
Los tres algoritmos correspondientes.

algoritmo ID3
Deficiencias existentes (1) El algoritmo ID3 utiliza la ganancia de información como criterio de evaluación
al seleccionar atributos de rama en el nodo raíz y en cada nodo interno . La desventaja de la ganancia de información es que tiende a seleccionar atributos con más valores y, en algunos casos, dichos atributos pueden no proporcionar mucha información valiosa.
(2) El algoritmo ID3 solo puede construir árboles de decisión para conjuntos de datos cuyos atributos de descripción son atributos discretos .
Algoritmo C4.5
Mejoras realizadas (por qué es mejor usar C4.5)
(1) usar la tasa de ganancia de información para seleccionar atributos
(2) puede manejar atributos numéricos continuos
(3) adoptar un método de pospoda
(4) manejar valores faltantes Ventajas y
desventajas de C4.5 Ventajas del algoritmo
:
Las reglas de clasificación generadas son fáciles de entender y tienen alta precisión.
Desventajas:
en el proceso de construcción del árbol, el conjunto de datos debe escanearse y ordenarse varias veces, lo que provoca la ineficiencia del algoritmo.
Además, C4.5 solo es adecuado para conjuntos de datos que pueden residir en la memoria. Cuando el conjunto de entrenamiento es demasiado grande para caber en la memoria, el programa no se puede ejecutar.
Algoritmo de carrito
En comparación con el método de clasificación del algoritmo C4.5, el algoritmo CART utiliza un modelo de árbol binario simplificado y la selección de características utiliza el coeficiente de Gini aproximado para simplificar el cálculo.
C4.5 no es necesariamente un árbol binario, pero CART debe ser un árbol binario.
Al mismo tiempo, ya sea ID3, C4.5 o CART, al realizar la selección de características, se selecciona la característica óptima para tomar decisiones de clasificación, pero la mayoría de las decisiones de clasificación no deben estar determinadas por una determinada característica, sino por una conjunto de características. **El árbol de decisión obtenido con esta decisión es más preciso. Este árbol de decisión se denomina árbol de decisión multivariante. Al seleccionar la característica óptima, el árbol de decisión multivariante no selecciona una característica óptima, sino que selecciona la combinación lineal óptima de características para tomar una decisión. El representante de este algoritmo es OC1, que no se presentará aquí.
Si la muestra cambia aunque sea ligeramente, se producirán cambios drásticos en la estructura del árbol. Esto se puede resolver mediante métodos como el bosque aleatorio en el aprendizaje conjunto.
API del algoritmo del árbol de clasificación
Enlace al sitio web oficial de API
class sklearn.tree.DecisionTreeClassifier(*, criterion='gini', splitter='best', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, class_weight=None, ccp_alpha=0.0)
Parámetros:
✸ Método de cálculo de impureza de criterio
Ingrese "entropía", use entropía de información (Entropía)
para ingresar "gini", use el coeficiente de Gini (Impureza de Gini)
En comparación con el coeficiente de Gini, la entropía de la información es más sensible a la impureza y tiene la penalización más severa por la impureza. Sin embargo, en el uso real, los efectos de la entropía de la información y el coeficiente de Gini son básicamente los mismos . El cálculo de la entropía de la información y el coeficiente bikini es más lento porque el cálculo del coeficiente de Gini no implica logaritmos. Además, debido a que la entropía de la información es más sensible a las impurezas, cuando se utiliza la entropía de la información como indicador, el crecimiento del árbol de decisión será más "fino", por lo que para datos de alta dimensión o datos con mucho ruido, la información la entropía puede sobreajustarse fácilmente y el coeficiente de Gini es En este caso, el efecto suele ser mejor. Cuando el ajuste del modelo es insuficiente, es decir, cuando el modelo funciona mal tanto en el conjunto de entrenamiento como en el conjunto de prueba, se utiliza la entropía de información. Por supuesto, estos no son absolutos.
| parámetro | criterio |
|---|---|
| ¿Cómo afecta al modelo? | Determine el método de cálculo de la impureza para ayudar a encontrar el mejor nodo y la mejor rama. Cuanto menor sea la impureza, mejor se adaptará el árbol de decisión al conjunto de entrenamiento. |
| ¿Cómo elegir los parámetros? | Por lo general, el coeficiente de Gini se usa cuando la dimensión de los datos es muy grande. Cuando el ruido es muy grande, el coeficiente de Gini se usa cuando la dimensión es baja. Cuando los datos son relativamente claros, no hay diferencia entre la entropía de la información y el Gini. coeficiente . Cuando el grado de ajuste del árbol de decisión no sea suficiente, use la entropía de información dos. Pruebe ambos, si no funciona, cambie a otro. |
✸ semilla de números aleatorios de estado_aleatorio y divisor
semilla de números aleatorios de estado_aleatorio, la aleatoriedad será más obvia en dimensiones altas. En datos de dimensiones bajas (como el conjunto de datos de iris), la aleatoriedad difícilmente aparecerá.
El divisor también se usa para controlar las opciones aleatorias en el árbol de decisión. Hay dos valores de entrada. Ingrese "mejor". Aunque el árbol de decisión es aleatorio al bifurcarse, seguirá dando prioridad a características más importantes para la bifurcación (la importancia puede pasar el atributo feature_importances_view), ingrese "aleatorio", el árbol de decisión será más aleatorio al bifurcarse, el árbol será más profundo y más grande porque contiene más información innecesaria y el ajuste del conjunto de entrenamiento se reducirá debido a esta información innecesaria. . . Esta es también una forma de evitar el sobreajuste. Cuando predice que su modelo se sobreajustará, utilice estos dos parámetros para ayudarle a reducir la posibilidad de sobreajuste después de construir el árbol. Por supuesto, una vez que se construye el árbol, seguimos usando parámetros de poda para evitar el sobreajuste.
✸ max_profundidad es la profundidad máxima del árbol de decisión. Todas las ramas que excedan la profundidad establecida serán podadas
. Si el árbol de decisión crece una capa más, la demanda de tamaño de muestra se duplicará, por lo que limitar la profundidad del árbol puede limitar efectivamente el sobreajuste. También es muy práctico en algoritmos de conjuntos. En uso real, se recomienda intentar comenzar desde =3 para ver el efecto de ajuste antes de decidir si aumentar la profundidad de ajuste.
✸ min_samples_leaf & min_samples_split El número mínimo de muestras de nodos hoja y el número mínimo de muestras necesarias para volver a dividir los nodos internos.
min_samples_split Este valor limita las condiciones para continuar la división del subárbol. Si el número de muestras de un nodo es menor que min_samples_split, No seguirá intentando seleccionar las características óptimas para clasificar. El valor predeterminado es 2. Si el tamaño de la muestra no es grande, no es necesario controlar este valor. Si el tamaño de la muestra es de magnitud muy grande, se recomienda aumentar este valor. Un ejemplo de mi proyecto anterior tenía alrededor de 100.000 muestras. Al construir un árbol de decisión, elegí min_samples_split=10. Se puede utilizar como referencia.
El valor min_samples_leaf limita el número mínimo de muestras para los nodos hoja. Si el número de un nodo hoja es menor que el número de muestras, se podará junto con sus nodos hermanos. El valor predeterminado es 1; puede ingresar el número entero del número mínimo de muestras o el número mínimo de muestras como porcentaje del número total de muestras. Si el tamaño de la muestra no es grande, no hay necesidad de preocuparse por este valor. Si el tamaño de la muestra es de magnitud muy grande, se recomienda aumentar este valor. Los 100.000 proyectos de muestra anteriores utilizaron un valor min_samples_leaf de 5 solo como referencia.
✸ max_features y min_impurity_decrease
se usan generalmente con max_ Depth para "refinar" el árbol
max_features limita la cantidad de funciones consideradas al realizar la bifurcación. Las funciones que superen el límite se descartarán. Similar a max_ Depth, max_features es un parámetro de poda que se utiliza para limitar el sobreajuste de datos de alta dimensión, pero su método es más violento: es un parámetro que limita directamente la cantidad de características que se pueden usar y detiene por la fuerza el árbol de decisión. Si no conoce el árbol de decisión, dada la importancia de cada característica en el modelo, establecer este parámetro a la fuerza puede provocar un aprendizaje insuficiente del modelo. Si desea evitar el sobreajuste mediante la reducción de dimensionalidad, se recomienda utilizar PCA, ICA o el algoritmo de reducción de dimensionalidad en el módulo de selección de características.
min_impurity_decrease limita el tamaño de la ganancia de información. No se producirán ramas con una ganancia de información menor que el valor establecido. Esta es una característica actualizada en la versión 0.19, antes de que se usara la versión 0.19 min_impurity_split.
✸ Los atributos del parámetro de peso objetivo class_weight y min_weight_fraction_leaf
son las diversas propiedades del modelo que se pueden llamar y ver después del entrenamiento del modelo. Para los árboles de decisión, lo más importante es feature_importances_, que le permite ver la importancia de cada característica para el modelo. Las interfaces más utilizadas para árboles de decisión son aplicar y predecir. El conjunto de pruebas de entrada en aplicar devuelve el índice del nodo hoja donde se encuentra cada muestra de prueba, y el conjunto de pruebas de entrada en predecir devuelve la etiqueta de cada muestra de prueba.
En todas las interfaces que requieren la entrada de X_train y X_test , la matriz de características de entrada debe ser al menos una matriz bidimensional. sklearn no acepta ninguna matriz unidimensional como entrada como matriz de características . Si sus datos tienen solo una característica, debe usar **reshape(-1,1)** para agregar dimensión a la matriz; si sus datos tienen solo una característica y una muestra, use reshape(1,-1) para Dimensionalidad de sus datos.
Lista de atributos del árbol de clasificación Resumen de

la lista de interfaces del árbol de clasificación : el proceso básico del árbol de decisión, los ocho parámetros del árbol de clasificación, un atributo, cuatro interfaces y el código utilizado para dibujar. Ocho parámetros: criterio, dos parámetros relacionados con la aleatoriedad (random_state, splitter), cinco parámetros de poda (max_ Depth, min_samples_split, min_samples_leaf, max_feature, min_impurity_decrease) un atributo: feature_importances_ cuatro interfaces: ajustar, puntuar, aplicar , predecir

Caso del conjunto de datos de vino tinto
from sklearn import tree
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import graphviz# 需要提前安装graphviz
wine = load_wine()
X_train, X_test, Y_train, Y_test = train_test_split(wine.data,wine.target,test_size=0.3)
clf = tree.DecisionTreeClassifier(criterion="entropy")
clf = clf.fit(X_train, Y_train)
score = clf.score(X_test, Y_test) #返回预测的准确度accuracy
print(score)
print(wine.feature_names)
print(wine.target_names)
feature_name = ['酒精','苹果酸','灰','灰的碱性','镁','总酚','类黄酮','非黄烷类酚类','花青素','颜色强度','色调','od280/od315稀释葡萄酒','脯氨酸']
dot_data = tree.export_graphviz(clf
,feature_names = feature_name # 特征名
,class_names=["琴酒","雪莉","贝尔摩德"] #标签的名称,这里是自定义的
,filled=True # 颜色填充
,rounded=True # 圆角边框
)
graph = graphviz.Source(dot_data)
graph

# random_state & splitter
clf = tree.DecisionTreeClassifier(criterion="entropy"
,random_state=30
,splitter="random"
)
clf = clf.fit(X_train, Y_train)
score = clf.score(X_test, Y_test)
print(score)
#剪枝参数
clf = tree.DecisionTreeClassifier(criterion="entropy"
,random_state=30
,splitter="random"
,max_depth=3
,min_samples_leaf=10 # 将样本数量小于10的叶子节点剪掉
,min_samples_split=10 # 将中间节点样本数量小于10的剪掉
)
clf = clf.fit(X_train, Y_train)
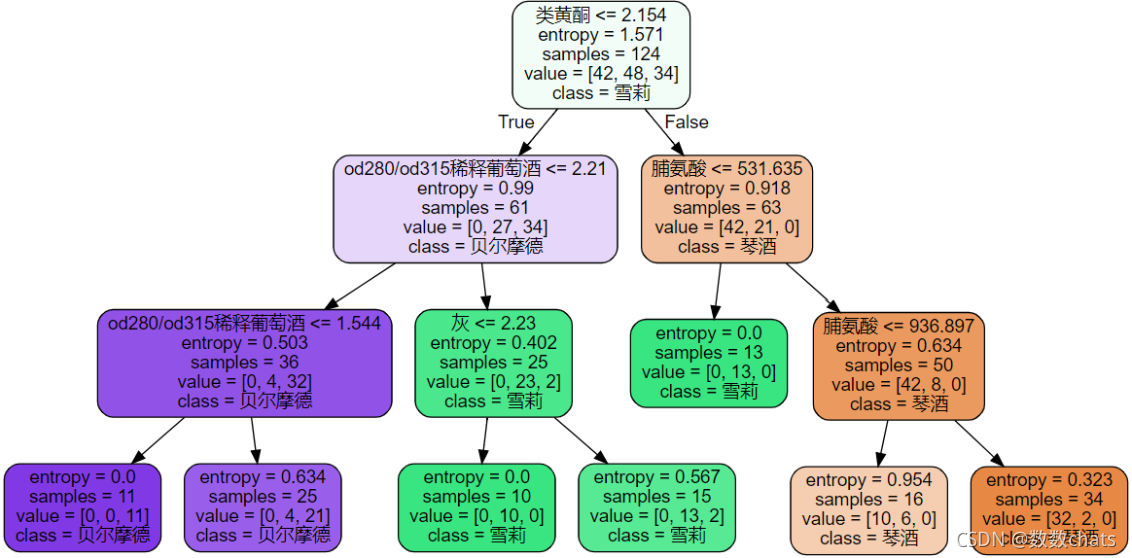
dot_data = tree.export_graphviz(clf
,feature_names = feature_name
,class_names=["琴酒","雪莉","贝尔摩德"]
,filled=True
,rounded=True
)
graph = graphviz.Source(dot_data)
graph
# 确认最优参数,画学习曲线
deths_rt = []
for dep in range(1, 10):
clf = tree.DecisionTreeClassifier(criterion="entropy"
,max_depth = dep
,random_state=30
,splitter="random"
)
clf = clf.fit(X_train, Y_train)
score = clf.score(X_test, Y_test) # 返回准确度
deths_rt.append(score)
plt.plot(range(1, 10), deths_rt)

# 将特征名称与重要性对应
dict(zip(wine.feature_names, clf.feature_importances_))
# 返回样本所在叶子节点的索引
clf.apply(X_test)
API de algoritmo de árbol de regresión
class sklearn.tree.DecisionTreeRegressor(*, criterion='squared_error', splitter='best', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, ccp_alpha=0.0)
En los árboles de regresión, no hay duda de si la distribución de las etiquetas está equilibrada, por lo que no existe ningún parámetro como class_weight.
Descripción del parámetro:
el árbol de regresión es un indicador para medir la calidad de las ramas. Hay tres estándares admitidos:
1) Ingrese "mse" y use el error cuadrático medio (MSE). La diferencia en el error cuadrático medio entre el nodo principal y el nodo de hoja se utilizará como criterio para la selección de características; este método minimiza la pérdida de L2 utilizando el valor medio de los nodos de hoja.
2) Ingrese "friedman_mse" para usar el error cuadrático medio de Feldman. Esta métrica utiliza el error cuadrático medio modificado de Friedman para problemas en sucursales potenciales.
3) Ingrese "mae" para usar el error medio absoluto MAE (error absoluto medio). Este indicador utiliza el valor medio del nodo hoja para minimizar la pérdida L1. El atributo más importante sigue siendo feature_importances_, y la interfaz aún se aplica. encajar,
predecir, puntuar El núcleo.
La puntuación de la interfaz del árbol de regresión devuelve R cuadrado, no MSE.
Pros y contras de los árboles de decisión
Ventajas de los árboles de decisión
-
Fácil de entender y explicar porque los árboles se pueden dibujar y ver.
-
Requiere poca preparación de datos. Muchos otros algoritmos a menudo requieren normalización de datos, creación de variables ficticias y eliminación de valores nulos, etc. Pero tenga en cuenta que el módulo de árbol de decisión en sklearn no admite el manejo de valores faltantes.
-
El costo de usar un árbol (por ejemplo, al predecir datos) es el logaritmo del número de puntos de datos utilizados para entrenar el árbol, lo cual es un costo muy bajo en comparación con otros algoritmos.
-
Capaz de procesar datos tanto numéricos como categóricos, y puede realizar tanto regresión como clasificación. Otras técnicas suelen estar especializadas en analizar conjuntos de datos con un solo tipo de variable.
-
Capaz de manejar problemas de múltiples salidas, es decir, problemas que contienen múltiples etiquetas, tenga en cuenta que se distinguen de los problemas que contienen múltiples clasificaciones de etiquetas en una sola etiqueta.
-
Es un modelo de caja blanca y los resultados son fácilmente interpretables. Si se puede observar una situación determinada en el modelo, las condiciones se pueden explicar fácilmente mediante la lógica booleana. Por el contrario, en los modelos de caja negra (por ejemplo, en redes neuronales artificiales), los resultados pueden ser más difíciles de interpretar.
-
Los modelos se pueden validar mediante pruebas estadísticas, que nos permiten considerar la confiabilidad del modelo.
-
Puede funcionar bien incluso si sus supuestos violan hasta cierto punto el modelo real que generó los datos.
Desventajas de los árboles de decisión
-
Los estudiantes de árboles de decisión pueden crear árboles demasiado complejos que no se generalizan bien con los datos. A esto se le llama sobreajuste. Mecanismos como la poda, establecer el número mínimo de muestras requeridas para un nodo de hoja o establecer la profundidad máxima del árbol son necesarios para evitar este problema, y la integración y el ajuste de estos parámetros pueden resultar oscuros para los principiantes.
-
Los árboles de decisión pueden ser inestables y pequeños cambios en los datos pueden dar lugar a árboles completamente diferentes. Este problema debe resolverse mediante algoritmos conjuntos.
-
El aprendizaje de los árboles de decisión se basa en el algoritmo codicioso, que intenta lograr el óptimo general optimizando el óptimo local (el óptimo de cada nodo), pero este enfoque no puede garantizar que se devolverá el árbol de decisión óptimo global. Este problema también se puede resolver mediante algoritmos de conjunto: en los bosques aleatorios, las características y muestras se muestrean aleatoriamente durante el proceso de ramificación.
-
Algunos conceptos son difíciles de aprender porque los árboles de decisión no los expresan fácilmente, como XOR, paridad o el problema del multiplexor.
-
Si ciertas clases en una etiqueta son dominantes, el aprendiz del árbol de decisión crea árboles que están sesgados hacia las clases dominantes. Por lo tanto, se recomienda equilibrar el conjunto de datos antes de ajustar el árbol de decisión.
práctica
Predicciones de supervivencia de los pasajeros del Titanic
Los marcos de datos del Titanic y del Titanic2 describen el estado de supervivencia de los pasajeros individuales del Titanic. El conjunto de datos utilizado aquí fue iniciado por varios investigadores. Se incluyen listas de pasajeros creadas por muchos investigadores y editadas por Michael A. Findlay. Las características del conjunto de datos que extrajimos son categoría de boleto, supervivencia, clase, edad, inicio de sesión, destino de inicio, habitación, boleto, barco y género.
Datos: http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt
Después de observar los datos, obtenemos:
1. La clase de pasajero se refiere a la clase de pasajero (1, 2, 3), que es representativa de la clase socioeconómica.
2 Faltan los datos de edad.
import pandas as pd
import numpy as np
from sklearn import tree
from sklearn.feature_extraction import DictVectorizer
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier, export_graphviz
# 1、获取数据
titan = pd.read_csv("titanic.csv")
#2、数据基本处理
#2.1 确定特征值,目标值
x = titan[["pclass", "age", "sex"]]
y = titan["survived"]
#2.2 缺失值处理
x['age'].fillna(x['age'].mean(), inplace=True)
#2.3 数据集划分
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=22)
#3.特征工程(字典特征抽取)
# 对于x转换成字典数据x.to_dict(orient="records")
# [{"pclass": "1st", "age": 29.00, "sex": "female"}, {}]
transfer = DictVectorizer(sparse=False)
x_train = transfer.fit_transform(x_train.to_dict(orient="records"))
x_test = transfer.fit_transform(x_test.to_dict(orient="records"))
# 4.机器学习(决策树)
estimator = DecisionTreeClassifier(criterion="entropy", max_depth=5)
estimator.fit(x_train, y_train)
# 5.模型评估
estimator.score(x_test, y_test)
estimator.predict(x_test)