Antes de aprender sobre redes neuronales profundas, debe comprender los conceptos básicos del entrenamiento de redes neuronales. Incluye: definición de una arquitectura de red neuronal simple, procesamiento de datos, especificación de funciones de pérdida y cómo entrenar el modelo. Para que sea más fácil de aprender, comience con el algoritmo clásico, Redes neuronales lineales, y aprenda los conceptos básicos de las redes neuronales.
Directorio de artículos
1.1 Elementos básicos en regresión lineal
La regresión lineal se basa en varios supuestos simples:
primero, suponga que la relación entre la variable independiente x y la variable dependiente y es lineal , es decir, y se puede expresar como una suma ponderada de los elementos en x, lo que generalmente permite cierto ruido. en las observaciones; en segundo lugar, asumimos que cualquier ruido es relativamente normal, como que el ruido sigue una distribución normal.
Tomemos un modelo muy clásico para estimar los precios de la vivienda en función del tamaño (metros cuadrados) y la antigüedad (años) de la casa.
Primero, debemos prepararnos 训练数据集(training data set) 或训练集(training set), incluido el precio real de la casa, el tamaño y la edad.
Llamamos a la meta que estamos tratando de predecir (como predecir el precio de una casa) como 标签(label)或目标(target). Las variables independientes (área y edad) en las que se basa la predicción se denominan 特征(feature)或协变量(covariate).
1.1.1 Modelo lineal
De acuerdo con nuestra suposición lineal inicial, nuestro objetivo de pronóstico (precio de la vivienda) se puede expresar como una suma ponderada de (área y edad de la vivienda), expresada en una expresión matemática de la siguiente manera:
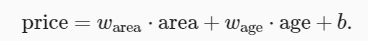
Esta expresión se puede ver como una de las características de entrada
仿射变换(affine transformation). La transformación afín se caracteriza por la suma ponderada de las características线性变换(linear transformation)y el término de sesgo平移(translation).
w área y salario se llaman 权重(weight),Los pesos determinan la influencia de cada característica en nuestro valor previsto.偏置(bias)、偏移量(offset)或截距(intercept)b se llama (Puede ser más familiar expresarlo como una intersección). Se puede ver claramente que b puede representar cuál es el valor predicho cuando todas las características toman 0. Incluso si en realidad no habrá casas con un área de 0 o una antigüedad de exactamente 0 años, todavía necesitamos un término de compensación.Sin el término sesgo, el poder expresivo de nuestro modelo sería limitado。
En el aprendizaje automático, generalmente usamos conjuntos de datos de alta dimensión, y muchas entradas de características
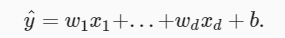
se usan en álgebra lineal. Es más conveniente usar vectores para representarlos. Simplificado en la siguiente forma:

después de expresar este modelo matemático, se puede encontrar que hay dos 模型参数(model parameters)w y b en la expresión. El siguiente paso es determinar estos dos parámetros, e introducimos otros dos conceptos:
损失函数: una medida de la calidad del modelo随机梯度下降: Un método capaz de actualizar el modelo para mejorar la calidad de las predicciones del modelo.
1.1.2 Función de pérdida
La función de pérdida cuantifica la diferencia entre el valor real del objetivo y el valor predicho.
Por lo general, elegimos un número no negativo como pérdida, y cuanto menor sea el valor, menor será la pérdida, y la pérdida para una predicción perfecta es 0.
La función de pérdida más utilizada en problemas de regresión es la función de error al cuadrado. Cuando el valor predicho de la muestra i es y^ (i) y su etiqueta verdadera correspondiente es y (i), el error cuadrático se puede definir como la siguiente fórmula
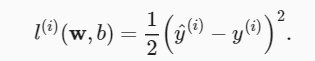
La constante 1/2 no hace una diferencia esencial, pero tiene una forma un poco más simple (ya que el coeficiente constante es 1 cuando tomamos la derivada de la función de pérdida).
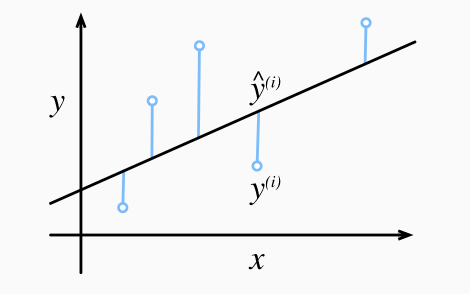
Una diferencia mayor entre el valor estimado y^ (i) y el valor observado y (i) dará como resultado una pérdida mayor debido al término cuadrático en la función de error cuadrático . Para medir la calidad del modelo en todo el conjunto de datos, necesitamos calcular la media (también equivalente a la suma) de la pérdida sobre las n muestras del conjunto de entrenamiento.
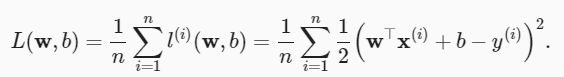
Al entrenar el modelo, queremos encontrar un conjunto de parámetros ( w ∗, b ∗), este conjunto de parámetros minimiza la pérdida total en todas las muestras de entrenamiento.

1.1.3 Descenso de gradiente estocástico
梯度下降(gradient descent), este método puede optimizar casi todos los modelos de aprendizaje profundo. Reduce el error al actualizar continuamente los parámetros en la dirección de la función de pérdida decreciente.
El uso más simple del descenso de gradiente es calcular la derivada de la función de pérdida con respecto a los parámetros del modelo.(También se puede llamar gradiente aquí).
Pero en la práctica, la ejecución puede ser muy lenta: tenemos que recorrer todo el conjunto de datos antes de cada actualización de parámetros. Por lo tanto, generalmente seleccionamos aleatoriamente un pequeño lote de muestras cada vez que se necesita calcular una actualización. Esta variante se denomina 小批量随机梯度下降(minibatch stochastic gradient descent)
pasos del algoritmo:
(1) Inicializar los valores de los parámetros del modelo, como inicialización aleatoria;
(2) Muestra aleatoria lotes pequeños del conjunto de datos Muestras de lotes, calcule la derivada (también llamada gradiente) de la pérdida promedio con respecto a los parámetros del modelo para el mini lote. Finalmente, multiplicamos el gradiente por un número positivo predeterminado η y lo restamos del valor del parámetro actual. Y sigue iterando en este paso.

|B| representa el número de muestras en cada mini-lote, que también se denomina
批量大小(batch size). n学习率(learning rate)representa Los valores para el tamaño del lote y la tasa de aprendizaje generalmente se especifican previamente de forma manual, en lugar del entrenamiento del modelo. Estos parámetros que se pueden ajustar pero no actualizar durante el entrenamiento se denominan超参数(hyperparameter).
调参(hyperparameter tuning)es el proceso de elección de hiperparámetros. Normalmente ajustamos los hiperparámetros en función de los resultados de las iteraciones de entrenamiento, que se evalúan en un conjunto de datos de validación independiente.
Por ejemplo, para w y B en pérdida al cuadrado :
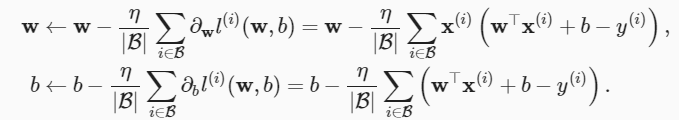
la regresión lineal resulta ser un problema de aprendizaje con solo un mínimo en todo el dominio. Pero para modelos complejos como redes neuronales profundas, el plano de pérdida generalmente contiene múltiples mínimos. Se necesita mucho esfuerzo para encontrar un conjunto de parámetros que minimice la pérdida en el conjunto de entrenamiento. De hecho, lo que es más difícil de hacer es encontrar un conjunto de parámetros que logre una baja pérdida de datos que nunca antes habíamos visto, un desafío conocido como generalización.
1.2 Aceleración de vectorización
De hecho, es simplemente usar la biblioteca de álgebra lineal en lugar del ciclo for para simplificar el proceso de operación. Cronometre el proceso de sumar dos vectores de dos formas para representar la diferencia de eficiencia entre ellos
n = 100000
a = torch.ones(n)
b = torch.ones(n)
Un temporizador de uso común:
class Timer: #@save
"""记录多次运行时间"""
def __init__(self):
self.times = []
self.start()
def start(self):
"""启动计时器"""
self.tik = time.time()
def stop(self):
"""停止计时器并将时间记录在列表中"""
self.times.append(time.time() - self.tik)
return self.times[-1]
def avg(self):
"""返回平均时间"""
return sum(self.times) / len(self.times)
def sum(self):
"""返回时间总和"""
return sum(self.times)
def cumsum(self):
"""返回累计时间"""
return np.array(self.times).cumsum().tolist()
El primero : use un bucle for para realizar la adición de un bit a la vez:
c = torch.zeros(n)
timer = Timer()
for i in range(n):
c[i] = a[i] + b[i]
f'{
timer.stop():.5f} sec'
Duración de la salida:
'0.76498 sec'
Segundo : use el operador + sobrecargado para calcular la suma de los elementos.
timer.start()
d = a + b
f'{
timer.stop():.5f} sec'
Duración de la salida:
'0.00100 sec'
Resulta que el segundo método es mucho más rápido que el primero. La vectorización de código a menudo resulta en aceleraciones de órdenes de magnitud. Además, ponemos más matemáticas en la biblioteca en lugar de tener que escribir tantos cálculos nosotros mismos, lo que reduce la posibilidad de errores.
1.3 Distribución normal y pérdida al cuadrado
La relación entre la distribución normal y la regresión lineal es estrecha. 正态分布(normal distribution), también conocida como 高斯分布(Gaussian distribution)su función de densidad de probabilidad de distribución normal de la siguiente manera:
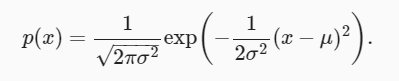
A continuación, definimos una función de Python para calcular la distribución normal.
def normal(x, mu, sigma):
p = 1 / math.sqrt(2 * math.pi * sigma**2)
return p * np.exp(-0.5 / sigma**2 * (x - mu)**2)
Visualizar:
# 再次使用numpy进行可视化
x = np.arange(-7, 7, 0.01)
# 均值和标准差对
params = [(0, 1), (0, 2), (3, 1)]
d2l.plot(x, [normal(x, mu, sigma) for mu, sigma in params], xlabel='x',
ylabel='p(x)', figsize=(4.5, 2.5),
legend=[f'mu {
mu}, sigma {
sigma}' for mu, sigma in params])
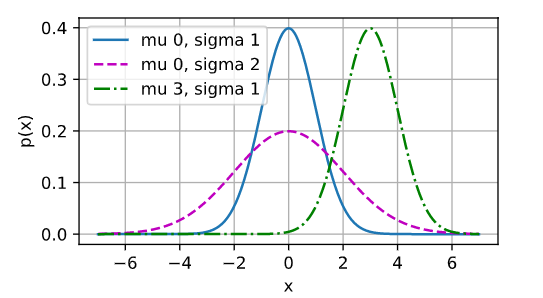
Como se muestra en la figura, es la comprensión de la distribución normal: cambiar la media (mu) producirá un desplazamiento a lo largo del eje x, y aumentar la varianza (sigma) extenderá la distribución y reducirá su pico.
Una de las razones por las que la pérdida cuadrática media se puede utilizar para la regresión lineal es: Suponemos que las observaciones contienen ruido, donde el ruido sigue una distribución normal. La distribución normal del ruido es la siguiente:
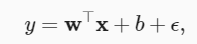
La probabilidad de observar una y particular con una x dada se puede escribir:
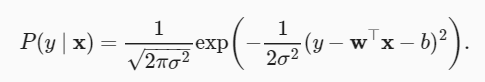
De acuerdo con el método de estimación de máxima verosimilitud, los valores óptimos de los parámetros w y b son las probabilidades que forman la totalidad conjunto de datos El valor más grande
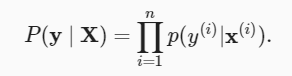
El estimador seleccionado de acuerdo con el método de estimación de máxima verosimilitud se denomina estimador de máxima verosimilitud. Aunque maximizar el producto de muchas funciones exponenciales puede parecer difícil, podemos simplificarlo calculando el logaritmo de maximización de la probabilidad en la teoría de la probabilidad. Por razones históricas, la optimización generalmente significa minimizar en lugar de maximizar. En su lugar, podemos minimizar la log-verosimilitud negativa −logP(y∣X) .
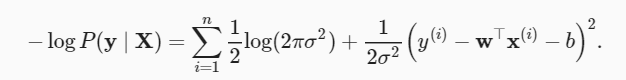
Ahora solo necesitamos asumir que σ es una constante fija e ignorar el primer término porque no depende de w y b. Ahora el segundo término es el mismo que el error cuadrático medio introducido anteriormente, excepto por la constante 1/ σ 2 .
Por lo tanto, bajo el supuesto de ruido gaussiano,Minimizar el error cuadrático medio es equivalente a una estimación de máxima verosimilitud para un modelo lineal。
1.4 De la regresión lineal a las redes profundas
Aunque la red neuronal cubre más y más ricos modelos, todavía podemos describir el modelo lineal de la misma manera que se describe la red neuronal, por lo que al pensar en el modelo lineal como una red neuronal, el diagrama solo muestra el modo de conexión, es decir , solo se muestra cada entrada como conectar a la salida, omitiendo los valores de pesos y sesgos.
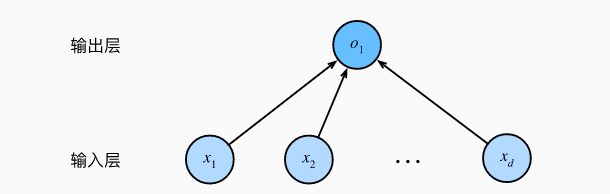
En la figura, las entradas son x 1 ,…,x d , entonces d en la capa de entrada 输入数(或称为特征维度,feature dimensionality). La salida de la red es o 1 , por lo que el número de salidas en la capa de salida es 1. Cabe señalar que los valores de entrada están todos dados y solo hay una neurona computacional.
Dado que el modelo se enfoca en dónde se lleva a cabo el cálculo, generalmente no consideramos la capa de entrada cuando calculamos el número de capas. Entonces, el número de capas en la red neuronal de la figura es 1. Podemos pensar en un modelo de regresión lineal como una red neuronal que consta de una sola neurona artificial, también conocida como red neuronal de una sola capa.
Para la regresión lineal, cada entrada está conectada a cada salida (en este caso, solo hay una salida), y llamamos a esta transformación (la capa de salida en la Figura 3) 全连接层(fully-connected layer)或称为稠密层(dense layer).
1.5 Resumen
- Los elementos clave en un modelo de aprendizaje automático son los datos de entrenamiento, la función de pérdida, el algoritmo de optimización y el propio modelo.
- La vectorización hace que las matemáticas sean más simples y rápidas.
- Minimizar la función objetivo es equivalente a realizar una estimación de máxima verosimilitud.
- Un modelo de regresión lineal también es una red neuronal simple.