Directorio de artículos
Descripción general
La red neuronal recurrente (RNN) es una estructura de red neuronal con conexiones recurrentes y se usa ampliamente en el procesamiento del lenguaje natural, el reconocimiento de voz, el análisis de datos de series temporales y otras tareas. En comparación con las redes neuronales tradicionales, la característica principal de RNN es que puede procesar datos de secuencia y capturar información de tiempo en la secuencia.
La unidad básica de RNN es una unidad recurrente, que recibe una entrada y un estado oculto del paso de tiempo anterior, y genera el estado oculto del paso de tiempo actual. En el RNN tradicional, la unidad recurrente suele utilizar funciones de activación como tanh o ReLU.
Red neuronal recurrente básica
principio
La estructura básica de la red neuronal recurrente consta de una capa de entrada, una capa oculta y una capa de salida.
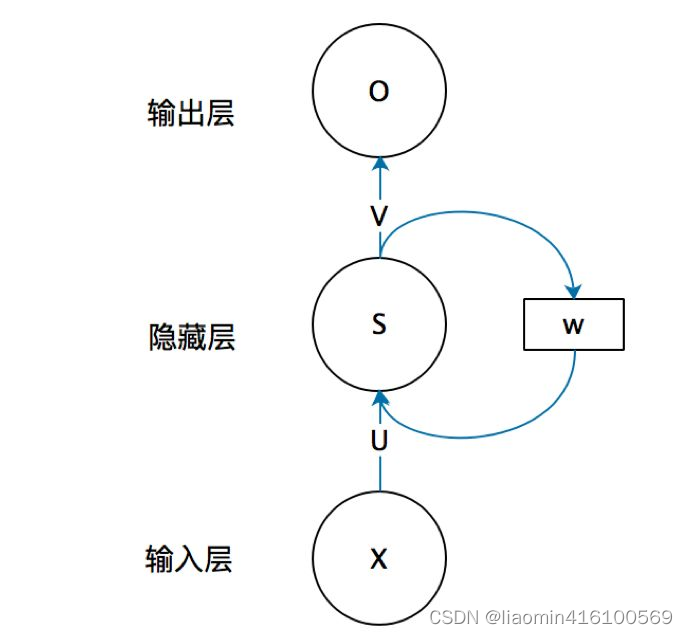
xxx es el vector de entrada,ooo es el vector de salida,sss representa el valor de la capa oculta;UUU es la matriz de peso desde la capa de entrada hasta la capa oculta,VVV es la matriz de peso desde la capa oculta hasta la capa de salida. El valor s de la capa oculta de la red neuronal recurrente no depende solo de la entrada actualxxx , también depende del valor de la última capa ocultasss . La matriz de peso W es el último valor de la capa oculta como peso de esta entrada.
Expanda la estructura básica de RNN en la figura anterior en la dimensión de tiempo (RNN es una estructura de cadena, cada segmento de tiempo usa los mismos parámetros, t representa el tiempo t): ahora se verá mucho más claro. Esta red recibe en el tiempo t para

ingresarxt x_tXtDespués de eso, el valor de la capa oculta es st s_tst, el valor de salida es ot o_toht. El punto clave es st s_tstEl valor de x_t depende no sólo de xtXt, también depende de st − 1 s_{t−1}st - 1。
公式1:st = f ( U ∗ xt + W ∗ st − 1 + B 1 ) s_t=f(U∗x_t+W∗s_{t−1}+B1)st=f ( U∗Xt+W.∗st - 1+B 1 )
Fórmula 2:ot = g ( V ∗ st + B 2 ) o_t=g(V∗s_t+B2)oht=gramo ( V∗st+B2 ) _
- La ecuación 1 es la fórmula de cálculo de la capa oculta, que es una capa recurrente. U es la matriz de peso de la entrada x, W es el último valor de capa oculta S t − 1 S_{t−1}St - 1Esta vez, como matriz de peso de entrada, f es la función de activación.
- La ecuación 2 es la fórmula de cálculo de la capa de salida, V es la matriz de peso de la capa de salida, g es la función de activación y B1 y B2 son sesgos que se supone que son 0.
La capa oculta tiene dos entradas, la primera es U y xt x_tXtEl producto de los vectores, el segundo es el estado st − 1 s_t−1 generado por la capa oculta anteriorst−El producto de 1 y W. Igual a st − 1 s_t−1calculado en el momento anteriorst−1 debe almacenarse en caché, ingrese xt x_testa vezXtCalculen juntos y generen el ot o_t final juntosoht。
Si colocamos repetidamente la Ecuación 1 en la Ecuación 2, obtendremos:
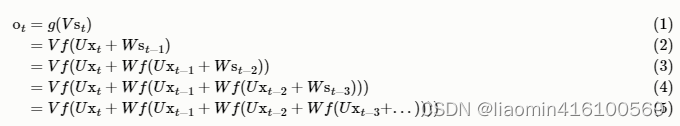
Como se puede ver en lo anterior, el valor de salida ot de la red neuronal recurrente se ve afectado por los valores de entrada anteriores,,,,,,,, xt x_tXt、xt − 1 x_{t−1}Xt - 1、xt − 2 x_{t−2}Xt - 2、xt − 3 x_{t−3}Xt - 3,... influencia, razón por la cual la red neuronal recurrente puede esperar cualquier número de valores de entrada. En realidad, esto no es bueno, porque si el valor anterior no tiene relación con el valor posterior y la red neuronal recurrente aún considera el valor anterior, afectará el juicio del valor posterior.
Lo anterior es el proceso de propagación hacia adelante de todo el NN unidireccional de una sola capa.
Para comprender el formato de entrada x entrada más rápido, usemos Word Embedding en nlp para explicarlo.
Incrustación de palabras
Primero, necesitamos codificar el texto de entrada x en un lenguaje que la computadora pueda leer. Al codificar, esperamos mantener líneas similares entre palabras y oraciones. La representación vectorial de palabras es la base del aprendizaje automático y el aprendizaje profundo.
Una idea básica de la incrustación de palabras es que asignamos una palabra a un punto en el espacio semántico y asignamos una palabra a un espacio denso de baja dimensión. Este mapeo hace que las palabras que son semánticamente similares tengan una distancia más cercana en el espacio semántico. Cerca, si la relación entre dos palabras no es muy cercana, entonces los vectores estarán relativamente lejos en el espacio semántico.
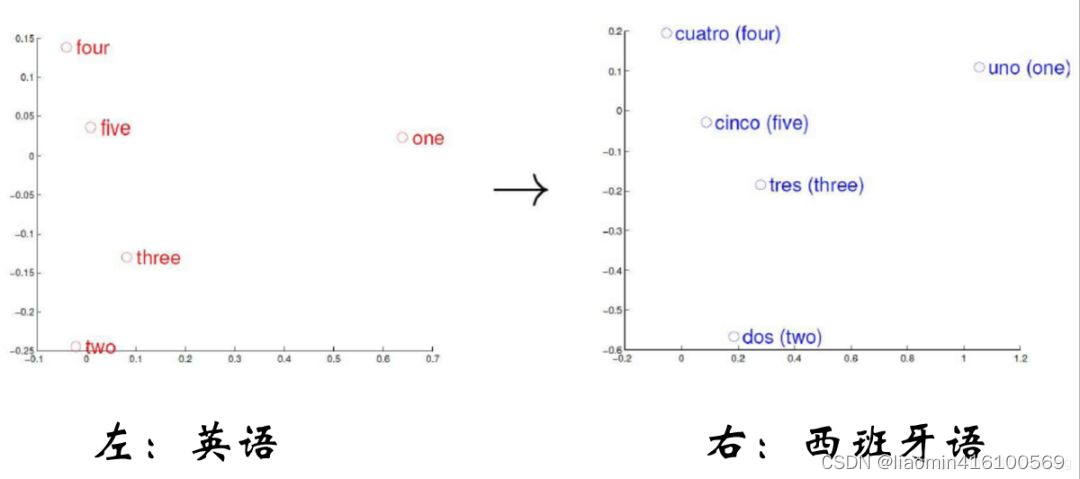
Como se muestra en la figura anterior, el inglés y el español están asignados al espacio semántico. Los números con la misma semántica tienen la misma posición de distribución en el espacio semántico. Repasemos brevemente la
incrustación de palabras. Para nlp, lo que ingresamos son símbolos discretos. Para neural redes, digamos, se trata de vectores o matrices. Entonces, en el primer paso, necesitamos codificar una palabra en un vector. El más simple es el método de representación one-hot. Como se muestra en la siguiente figura:

código Python (one-hot), como
import numpy as np
word_array = ['apple', 'kiwi', 'mango']
word_dict = {'apple': 0, 'banana': 1, 'orange': 2, 'grape': 3, 'melon': 4, 'peach': 5, 'pear': 6, 'kiwi': 7, 'plum': 8, 'mango': 9}
# 创建一个全为0的矩阵
one_hot_matrix = np.zeros((len(word_array), len(word_dict)))
# 对每个单词进行one-hot编码
for i, word in enumerate(word_array):
word_index = word_dict[word]
one_hot_matrix[i, word_index] = 1
print(one_hot_matrix)
Producción:
[[1. 0. 0. 0. 0. 0. 0. 0. 0. 0.] #这就是apple的one-hot编码
[0. 0. 0. 0. 0. 0. 0. 1. 0. 0.] #这就是kiwi的one-hot编码
[0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]] #这就是mango的one-hot编码
Las filas representan cada palabra, las columnas representan el corpus y cada columna corresponde a una palabra del corpus, que es la columna de características.
Aunque la codificación one-hot es un método de representación de características simple y efectivo, también tiene algunas desventajas:
-
Representación de alta dimensión: cuando se utiliza codificación one-hot, cada característica necesita crear un vector disperso grande con dimensiones iguales a la cantidad de valores únicos de la característica. Esto da como resultado datos de entrada de alta dimensión, lo que aumenta la sobrecarga computacional y de almacenamiento. Especialmente cuando se trata de problemas con una gran cantidad de funciones discretas, lo que da como resultado un espacio de funciones muy grande.
-
Independencia de dimensión: la codificación one-hot representa cada característica como una característica binaria independiente, sin tener en cuenta la correlación y la relación semántica entre características. Esto puede dificultar que el modelo capture las interacciones y correlaciones entre características, afectando así el rendimiento del modelo.
-
No se pueden manejar características desconocidas: la codificación one-hot requiere que los valores únicos de la característica aparezcan en el conjunto de entrenamiento; de lo contrario, se producirán problemas. Si se encuentran valores de características que no aparecen en el conjunto de entrenamiento en el conjunto de prueba o en la aplicación real, no se puede realizar la codificación one-hot, lo que puede hacer que el modelo no pueda manejar estas características desconocidas.
-
Escasez de características: dado que el vector de características de la codificación one-hot es escaso, la mayoría de los elementos son 0, lo que provocará una mayor escasez de datos, lo que puede causar algunos problemas para algunos algoritmos (como los modelos lineales).
En resumen, aunque la codificación one-hot es un método de representación de características simple y efectivo en algunos casos, también tiene algunas deficiencias, especialmente cuando se trata de características discretas de alta dimensión, considerando la relación entre características y tratando con valores de características desconocidos. puede encontrar problemas.
Hay dos razones principales para usar nn.Embedding en lugar de codificación one-hot:
-
Flexibilidad de dimensionalidad: cuando se utiliza codificación one-hot, cada característica necesita crear un vector disperso grande con dimensiones iguales a la cantidad de valores únicos de la característica. Esto da como resultado una entrada de alta dimensión, lo que aumenta la sobrecarga computacional y de almacenamiento. El uso de la incrustación puede mapear características discretas en representaciones vectoriales continuas de baja dimensión, lo que reduce los costos de almacenamiento e informática.
-
Relaciones semánticas y similitudes: los vectores de incrustación pueden capturar las relaciones semánticas y las similitudes entre características. Por ejemplo, en tareas de procesamiento de lenguaje natural, el uso de vectores de incrustación puede asignar palabras a representaciones vectoriales continuas, de modo que las palabras con significados semánticos similares estén más cerca en el espacio de incrustación. Estas características pueden ayudar al modelo a comprender y aprender mejor la relación entre las características y mejorar el rendimiento del modelo.
Por lo tanto, usar nn.Embedding en lugar de codificación one-hot puede mejorar la eficiencia y el rendimiento del modelo, especialmente cuando se trata de características discretas de alta dimensión.
Bien, veamos un ejemplo simple para impulsar el efecto de los dos parámetros de nn.embedding.
Supongamos que tenemos una tarea de clasificación de oraciones, nuestra entrada es una oración y cada palabra es una característica. Tenemos 5 palabras diferentes, a saber ["yo", "amor", "profundo", "aprendizaje", "!"].
Podemos usar nn.embedding para asignar estas palabras a vectores de incrustación (una posición en el sistema de coordenadas que apunta a la palabra). Supongamos que incorporamos cada palabra como un vector tridimensional. Aquí, num_embeddings es 5, lo que significa que tenemos 5 palabras diferentes; embedding_dim es 3, lo que significa que cada palabra está incrustada como un vector tridimensional.
Podemos usar la siguiente tabla para representar el vector de incrustación de cada palabra:
| palabra | vector de incrustación |
|---|---|
| "I" | [0,1, 0,2, 0,3] |
| "amar" | [0,4, 0,5, 0,6] |
| "profundo" | [0,7, 0,8, 0,9] |
| "aprendiendo" | [0,2, 0,3, 0,4] |
| “¡!” | [0,5, 0,6, 0,7] |
Con nn.embedding, podemos convertir cada palabra de la oración en el vector de incrustación correspondiente. Por ejemplo, la frase "¡Me encanta el aprendizaje profundo!" se puede convertir en la siguiente secuencia de vectores integrados:
[[0,1, 0,2, 0,3], [0,4, 0,5, 0,6], [0,7, 0,8, 0,9], [0,2, 0,3, 0,4], [0,5, 0,6, 0,7]]
De esta manera, podemos convertir características de palabras discretas en vectores de incrustación continuos para usar en modelos de aprendizaje profundo.
El siguiente es el uso de pytorch ( comenzando con python )
# 创建词汇表
vocab = {"I": 0, "love": 1, "deep": 2, "learning": 3, "!": 4}
strings=["I", "love", "deep", "learning", "!" ]
# 将字符串序列转换为整数索引序列
input = t.LongTensor([vocab[word] for word in strings])
#注意第一个参数是词汇表的个数,并不是输入单词的长度,你在这里就算填100也不影响最终的输出维度,这个输入值影响的是算出来的行向量值
#nn.Embedding模块会随机初始化嵌入矩阵。在深度学习中,模型参数通常会使用随机初始化的方法来开始训练,以便模型能够在训练过程中学习到合适的参数值。
#在nn.Embedding中,嵌入矩阵的每个元素都会被随机初始化为一个小的随机值,这些值将作为模型在训练过程中学习的可训练参数,可以使用manual_seed固定。
t.manual_seed(1234)
embedding=nn.Embedding(len(vocab),3)
print(embedding(input))
Los resultados de salida son:
tensor([[-0.1117, -0.4966, 0.1631],
[-0.8817, 0.0539, 0.6684], [ -0.0597, -0.4675
, -0.2153],
[ 0.8840, -0.7584, -0.3689],
[- 0,3424, -1,4020, 0,3206]], grad_fn=)
Tenga en cuenta que el primer parámetro de incrustación no es la longitud de los caracteres de entrada, sino la longitud del vocabulario. Por ejemplo, hay un vocabulario
{"I": 0, "love": 1, "deep": 2, " aprendizaje": 3, "!": 4}, y la entrada de entrada puede ser: me encanta. En este momento, se debe pasar 5 en lugar de 2, porque la predicción de la última capa oculta requiere una conexión completa para predecir el palabra de entrada actual para todas las palabras del vocabulario completo. La probabilidad.
pytorch rnn
El siguiente es el ejemplo más simple del uso de rnn en pytorch para familiarizarse con pytorch rnn.
Tenga en cuenta que rnn de pytorch no maneja la lógica desde la capa oculta a la capa de salida. Solo se centra en los resultados de salida de la capa oculta. Si Si necesita convertir la capa oculta en la salida del resultado, puede agregar una capa completamente conectada. No nos centraremos en esta parte aquí.
#%%
import torch
import torch.nn as nn
# 定义输入数据
input_size = 10 # 输入特征的维度
sequence_length = 5 # 时间步个数
batch_size = 3 # 批次大小
# 创建随机输入数据
#输入数据的维度为(sequence_length, batch_size, input_size),表示有sequence_length个时间步,
#每个时间步有batch_size个样本,每个样本的特征维度为input_size。
input_data = torch.randn(sequence_length, batch_size, input_size)
print("输入数据",input_data)
# 定义RNN模型
# 定义RNN模型时,我们指定了输入特征的维度input_size、隐藏层的维度hidden_size、隐藏层的层数num_layers等参数。
# batch_first=False表示输入数据的维度中批次大小是否在第一个维度,我们在第二个维度上。
rnn = nn.RNN(input_size, hidden_size=20, num_layers=1, batch_first=False)
"""
在前向传播过程中,我们将输入数据传递给RNN模型,并得到输出张量output和最后一个时间步的隐藏状态hidden。
输出张量的大小为(sequence_length, batch_size, hidden_size),表示每个时间步的隐藏层输出。
最后一个时间步的隐藏状态的大小为(num_layers, batch_size, hidden_size)。
"""
# 前向传播,第二个参数h0未传递,默认为0
output, hidden = rnn(input_data)
print("最后一个隐藏层",hidden.shape)
print("输出所有隐藏层",output.shape)
# 打印每个隐藏层的权重和偏置项
# weight_ih表示输入到隐藏层的权重,weight_hh表示隐藏层到隐藏层的权重,注意这里使出是转置的结果。
# bias_ih表示输入到隐藏层的偏置,bias_hh表示隐藏层到隐藏层的偏置。
for name, param in rnn.named_parameters():
if 'weight' in name or 'bias' in name:
print(name, param.data)
producción
最后一个隐藏层 torch.Size([1, 3, 20])
输出所有隐藏层 torch.Size([5, 3, 20])
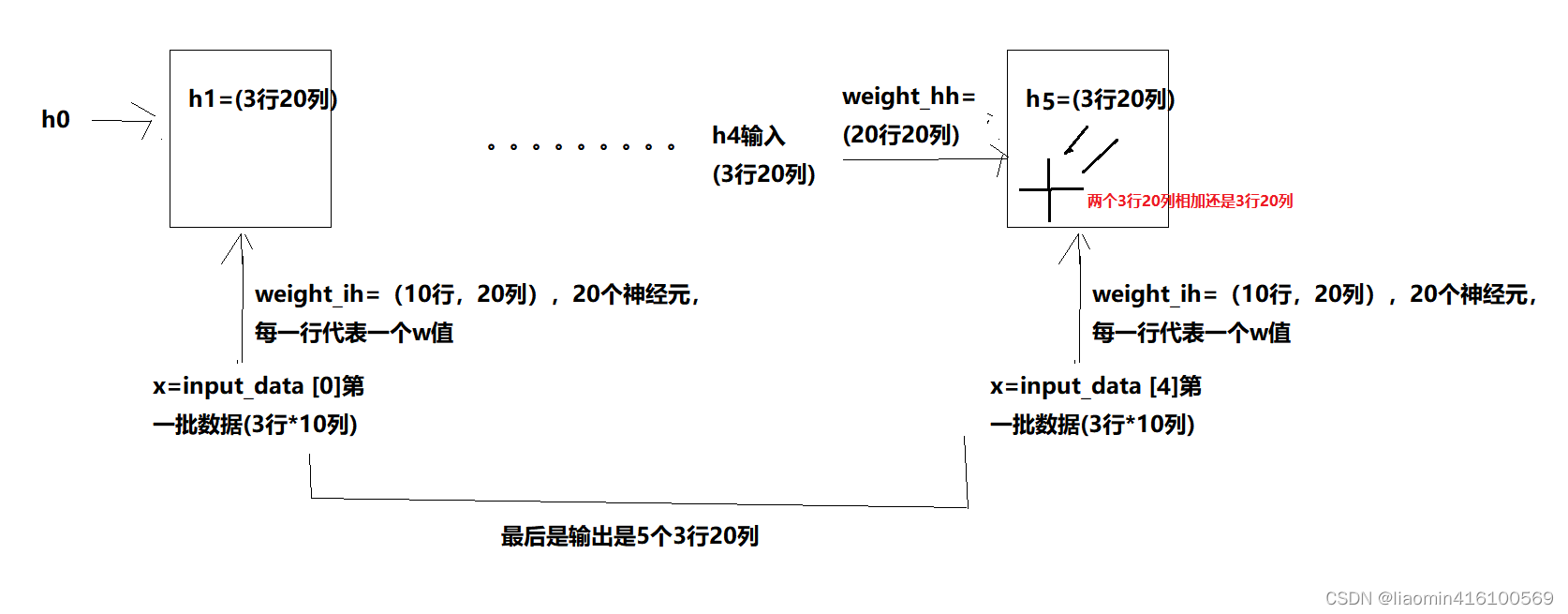
¿Por qué los pesos son 10 filas y 20 columnas? El principio de la red neuronal convolucional de parámetros:
la longitud de la fila más externa de los datos determina el número de series de tiempo de propagación directa.
Este tamaño de entrada es la dimensión de los datos de entrada. Por ejemplo, después de convertir una palabra a one-hot, la columna es la longitud de la característica del diccionario.
Este tamaño oculto es el número de neuronas de la capa oculta, que es el número de características de entrada. hasta la capa oculta final.
En num_layer se apilan capas ocultas de varias capas.
estructuras comunes
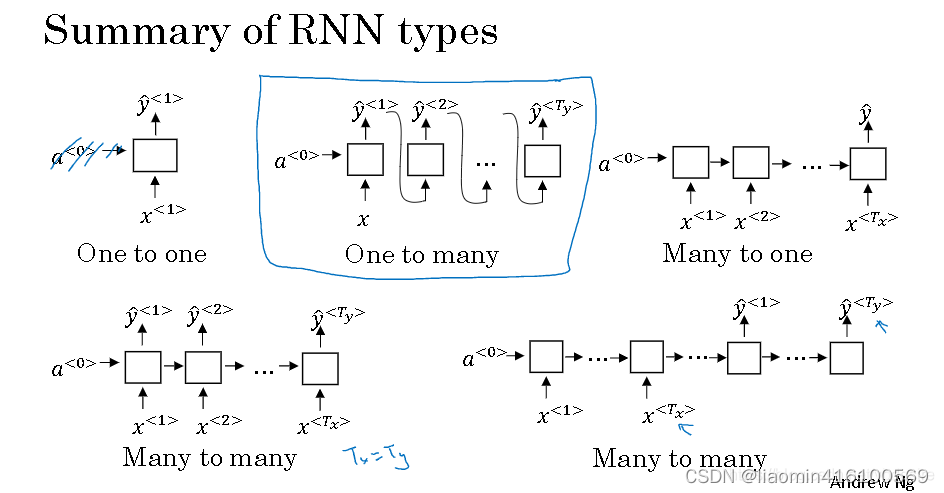
Los tipos de resultados comúnmente utilizados de RNN (red neuronal recurrente) incluyen entrada única, salida única, entrada única, salida múltiple, entrada múltiple, salida múltiple y entrada múltiple y salida única. A continuación explicaré cada tipo de resultado en detalle y cómo se pueden utilizar.
-
Entrada única y salida única (SISO): este es el tipo de resultado RNN más común. La entrada es una secuencia y la salida es un valor predicho único. Por ejemplo, dado un fragmento de texto, predice la siguiente palabra; dado un período de datos de secuencia, predice el valor del siguiente paso de tiempo. Este tipo de resultado es adecuado para muchas tareas de predicción de secuencias, como modelos de lenguaje, predicción de series temporales, etc.
Por ejemplo, supongamos que queremos predecir el precio de una casa, podemos utilizar múltiples características, como el área de la casa, el número de dormitorios, el número de baños, etc. De esta manera, podemos combinar estas características en un vector de características como entrada del modelo, y la salida del modelo es el precio de la vivienda previsto. Por lo tanto, la regresión lineal se puede utilizar para resolver el problema de múltiples características en una sola salida, por lo que se denomina modelo de entrada única y salida única. -
Entrada única y salida múltiple (SIMO): en este tipo de resultado, la entrada es una secuencia pero la salida son múltiples valores predichos. Por ejemplo, dado un fragmento de texto, predice la siguiente palabra y la etiqueta de parte del discurso de la palabra al mismo tiempo; dado un fragmento de señal de audio, predice la emoción del habla y la identidad del hablante al mismo tiempo. Este tipo de resultado es adecuado para situaciones en las que es necesario predecir varias tareas relacionadas simultáneamente.
-
Múltiples entradas y múltiples salidas (MIMO): en este tipo de resultado, hay múltiples secuencias de entrada y múltiples secuencias de salida. Por ejemplo, en una tarea de traducción automática, la entrada es una secuencia de oraciones en el idioma de origen y la salida es una secuencia de oraciones en el idioma de destino; en un sistema de diálogo, la entrada es una secuencia de preguntas del usuario. y el resultado es una secuencia de respuestas del sistema. Este tipo de resultado es adecuado para tareas que necesitan procesar múltiples secuencias de entrada y salida. Mimo tiene dos tipos: números de entrada y salida iguales y desiguales.
-
Entrada múltiple, salida única (MISO): en este tipo de resultado, hay múltiples secuencias de entrada pero solo una salida. Por ejemplo, en la tarea de generación de descripción de imágenes, la entrada es una secuencia de imágenes y la salida es una descripción de la imagen; en la conducción autónoma, la entrada es una secuencia de datos de múltiples sensores y la salida es un comando de control del vehículo. Este tipo de resultado es adecuado para tareas que requieren asignar múltiples secuencias de entrada a una única secuencia de salida.
La regresión lineal es un modelo simple de aprendizaje automático cuya entrada puede ser varias características pero tiene una sola salida. "Entrada única y salida única" aquí significa que la entrada del modelo es un vector (una combinación de múltiples características) y la salida es un escalar (un valor predicho). En la regresión lineal, obtenemos un valor predicho combinando linealmente características de entrada. Entonces, aunque la entrada puede ser de varios elementos, la salida es solo uno.
red neuronal recurrente bidireccional
El RNN ordinario solo puede predecir la salida del momento siguiente en función de la información de tiempo del momento anterior, pero en algunos problemas, la salida del momento actual no solo está relacionada con el estado anterior, sino también con el estado futuro.
Por ejemplo, predecir una palabra que falta en una oración no solo debe juzgarse en función del texto anterior, sino que también debe considerarse el contenido detrás de ella para emitir un juicio verdaderamente basado en el contexto.
BRNN se compone de dos RNN superpuestos uno encima del otro y la salida está determinada por los estados de los dos RNN.
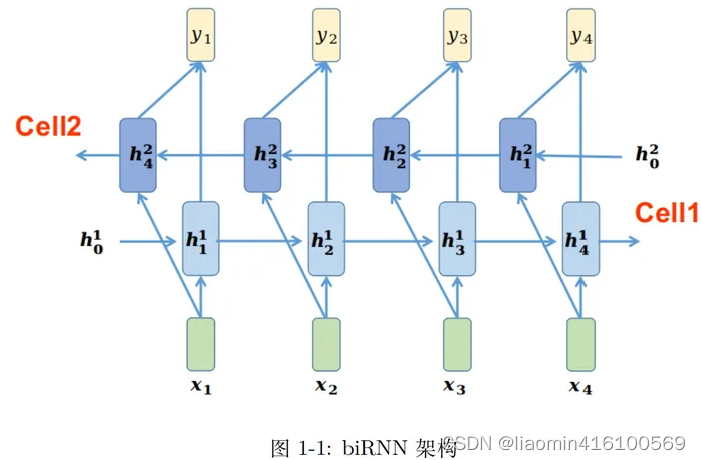
Primero, centrémonos en los símbolos de las imágenes y las fórmulas para consultarlos fácilmente cuando sea necesario:
- ht 1 h_t^1ht1Representa la memoria (información) obtenida de izquierda a derecha en la Celda1 en el momento t;
- W 1, U 1 W ^ 1, U ^ 1W.1 ,Ud.1 representa los parámetros que se pueden aprender de la Celda1 en la figura, W es el parámetro de la capa oculta y U es el parámetro de la capa de entrada;
- f 1 f_1F1Representa la función de activación de Cell1;
- ht 2 h_t ^ 2ht2Representa la memoria obtenida de derecha a izquierda en la Celda2 en el momento t;
- W2W^2W.2 ,U2 U^2Ud.2 representa los parámetros que se pueden aprender de Cell2 en la figura;
- f 2 f_2F2Representa la función de activación de Cell2;
- V.V.V es el parámetro de la capa de salida, que puede entenderse como MLP;
- f 3 f_3F3es la función de activación de la capa de salida;
- yt y_tytes el valor de salida en el momento t;
En la Figura 1-1, para la entrada xt x_t en el momento tXt, se puede combinar con la memoria ht − 1 1 h^1_{t-1} de izquierda a derechaht - 11, obtiene la memoria ht 1 h^1_t en el momento actualht1: De manera similar, la memoria ht − 1 2 h^2_{t−1}
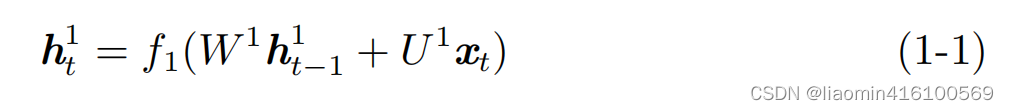
también se puede combinar de derecha a izquierda.ht - 12, obtiene la memoria ht 2 h^2_t en el momento actualht2:
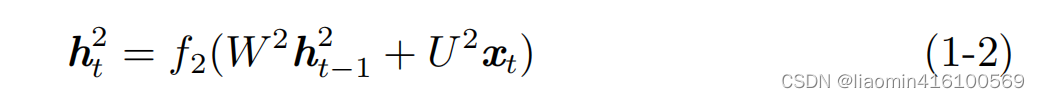
Entonces ht 1 h^1_tht1y ht 2 h ^ 2_tht2La cabeza y la cola se conectan en cascada a través de la red de capa de salida VV.V obtiene la salidayt y_tyt:

De esta forma, para cualquier momento t, se puede ver la memoria obtenida desde diferentes direcciones, lo que facilita la optimización del modelo y acelera la velocidad de convergencia del modelo.
pytorch rnn
El siguiente es el ejemplo más simple de implementación de un RNN bidireccional usando el módulo nn.RNN en PyTorch:
import torch
import torch.nn as nn
# 定义输入数据
input_size = 10 # 输入特征的维度
sequence_length = 5 # 时间步个数
batch_size = 3 # 批次大小
# 创建随机输入数据
input_data = torch.randn(sequence_length, batch_size, input_size)
# 定义双向RNN模型
rnn = nn.RNN(input_size, hidden_size=20, num_layers=1, batch_first=False, bidirectional=True)
# 前向传播
output, hidden = rnn(input_data)
# 输出结果
print("输出张量大小:", output.size())
print("最后一个时间步的隐藏状态大小:", hidden.size())
producción
输出张量大小: torch.Size([5, 3, 40])
最后一个时间步的隐藏状态大小: torch.Size([2, 3, 20])
En este ejemplo, las dimensiones de los datos de entrada son las mismas que en el ejemplo anterior.
Al definir un modelo RNN bidireccional, configuramos bidireccional = Verdadero en los parámetros del modelo RNN, lo que indica que queremos construir un modelo RNN bidireccional.
Durante la propagación directa, pasamos los datos de entrada al modelo RNN bidireccional y obtenemos la salida del tensor de salida y el estado oculto del último paso de tiempo. El tamaño del tensor de salida es (longitud_secuencia, tamaño_lote, tamaño_oculto num_direcciones), donde num_direcciones es 2, lo que indica direcciones hacia adelante y hacia atrás. El tamaño del estado oculto en el último paso es (núm_capas núm_direcciones, tamaño_lote, tamaño_oculto).
RNN bidireccional puede utilizar información pasada y futura al mismo tiempo y puede capturar mejor características en datos de series temporales. Puede ajustar el tamaño de los datos de entrada, los parámetros del modelo RNN, etc. según sea necesario para realizar experimentos.
La salida de un RNN bidireccional suele ser una combinación de estados ocultos hacia adelante y hacia atrás, que se almacenan en una matriz. Específicamente, si usa el módulo nn.RNN en PyTorch para implementar un RNN bidireccional, la forma del tensor de salida será (longitud_secuencia, tamaño_lote, tamaño_oculto * 2), donde tamaño_oculto * 2 representa la suma de los tamaños de avance y estados ocultos inversos. Este tensor de salida contiene información sobre los estados ocultos hacia adelante y hacia atrás en cada paso de tiempo y se puede utilizar en tareas posteriores.
El tamaño final de la capa oculta del rnn bidireccional es (2, tamaño_lote, tamaño_oculto)
RNN profundo (RNN multicapa)
El RNN que presentamos anteriormente es la transformación de datos en la dimensión temporal. No importa cuán larga sea la dimensión de tiempo, solo hay un módulo RNN, es decir, solo hay un conjunto de parámetros para aprender (W, U), que pertenece a un RNN de una sola capa. Deep RNN también se llama RNN multicapa y, como sugiere el nombre, se compone de múltiples cascadas de RNN, que transforman los datos de entrada en la dimensión espacial. Como se muestra en la figura, esta es la arquitectura RNN de capa L. Cada capa es un RNN independiente y hay L RNN en total.
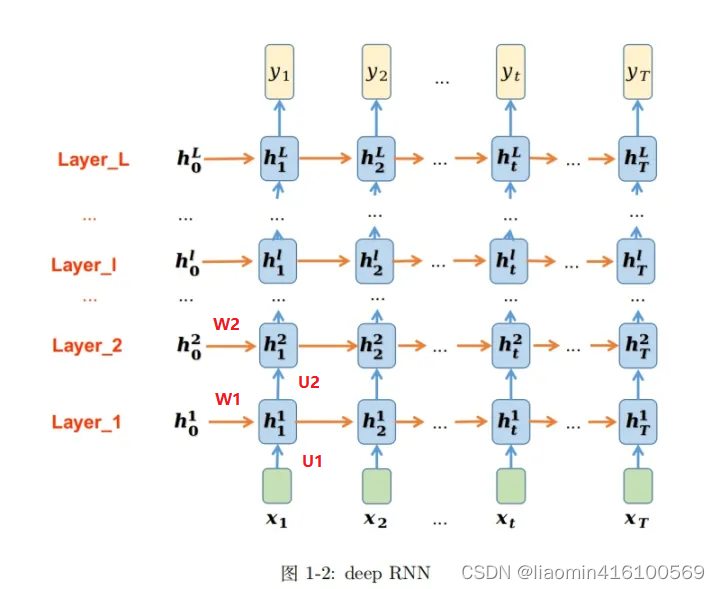
En la dirección horizontal de cada capa, solo hay un conjunto de parámetros que se pueden aprender, como el llParámetros de la capa l W l U l W^lU^lW.yo _yo . La dirección horizontal es que los datos se transforman a lo largo de la dimensión del tiempo. El mecanismo de transformación es consistente con el mecanismo de un solo RNN. Para más detalles, consulte el artículo anterior. En la dirección vertical en cada momento t, hay L conjuntos de parámetros que se pueden aprender (W i, U i W^i,U^iW.yo ,Ud.yo ) yo = 1, 2,…, L. en elllLos datos de entrada de Cell en el momento t de la capa l provienen de dos direcciones: una es la salidahtl − 1 h^{l−1}_thtl - 1:
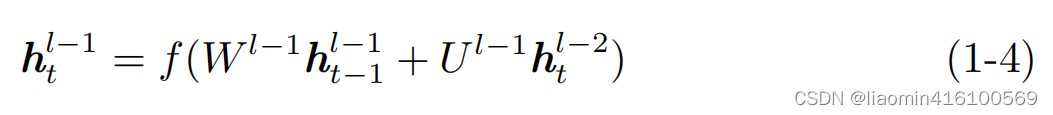
Uno es del lll capa,t − 1 t − 1t−Datos de la memoria en 1 momentoht − 1 lh^l_{t−1}ht - 1yo:
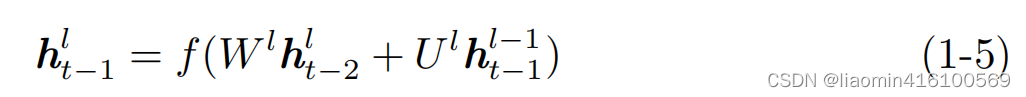
Entonces la salida de Cell htlh^l_thtyo:
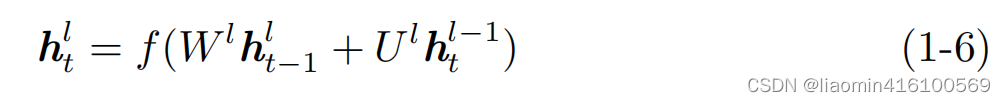
Esencialmente, Deep RNN modifica la entrada en el momento actual en la salida de la capa superior en función de un único RNN. De esta forma, RNN completa la transformación de datos espaciales. Una mención adicional: cada capa de DeepRNN también puede ser un RNN bidireccional.
pytorch rnn
El siguiente es el ejemplo más simple del uso del módulo nn.RNN para implementar un RNN multicapa:
import torch
import torch.nn as nn
# 定义输入数据和参数
input_size = 5
hidden_size = 10
num_layers = 2
batch_size = 3
sequence_length = 4
# 创建输入张量
input_tensor = torch.randn(sequence_length, batch_size, input_size)
# 创建多层RNN模型
rnn = nn.RNN(input_size, hidden_size, num_layers)
# 前向传播
output, hidden = rnn(input_tensor)
# 打印输出张量和隐藏状态的大小
print("Output shape:", output.shape)
print("Hidden state shape:", hidden.shape)
En el ejemplo anterior, primero definimos las dimensiones de los datos de entrada, los parámetros del modelo RNN (tamaño de entrada, tamaño del estado oculto y número de capas), así como el tamaño del lote y la longitud de la secuencia. Luego, creamos un tensor de entrada con forma (longitud_secuencia, tamaño_lote, tamaño_entrada). A continuación, utilizamos el módulo nn.RNN para crear un modelo RNN multicapa con dos capas. Finalmente, realizamos la propagación directa pasando el tensor de entrada al método directo del modelo RNN e imprimimos el tamaño del tensor de salida y el estado oculto.
Tenga en cuenta que el tensor de salida tiene forma (longitud_secuencia, tamaño_lote, tamaño_oculto), donde longitud_secuencia y tamaño_lote permanecen constantes y tamaño_oculto es el tamaño del estado oculto. La forma del estado oculto es (núm_capas, tamaño de lote, tamaño_oculto), donde núm_capas es el número de capas del modelo RNN.
Desventajas de RNN
Problemas de gradiente explosivo y desaparecido
En la práctica, los diversos RNN introducidos anteriormente no pueden manejar bien secuencias más largas. Los RNN son propensos a la explosión y desaparición del gradiente durante el entrenamiento, lo que hace que el gradiente no se transmita en secuencias más largas, lo que hace que el RNN no pueda capturarlo a larga distancia. efectos.
En términos generales, la explosión de gradiente es más fácil de manejar. Porque cuando el gradiente explote, nuestro programa recibirá un error de NaN. También podemos establecer un umbral de gradiente y, cuando el gradiente excede este umbral, se puede interceptar directamente.
Los gradientes que desaparecen son más difíciles de detectar y un poco más difíciles de abordar. En general, tenemos tres métodos para abordar el problema del gradiente evanescente:
1. Valores de peso de inicialización razonables. Inicializa los pesos para que cada neurona no tome un valor máximo o mínimo en la medida de lo posible para evitar la zona donde desaparece el gradiente.
2. Utilice relu en lugar de sigmoide y tanh como función de activación. .
3. Utilice RNN de otras estructuras, como la red de memoria a corto plazo (LTSM) y la unidad recurrente cerrada (GRU), que es el enfoque más popular.
memoria de corto plazo
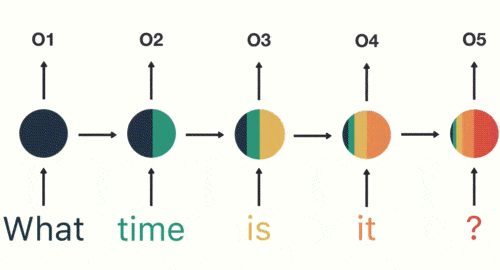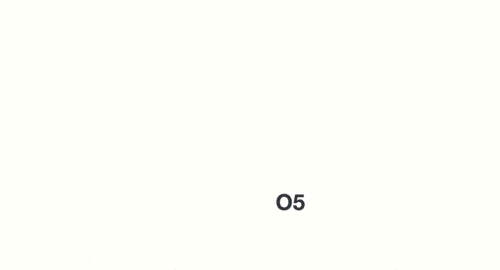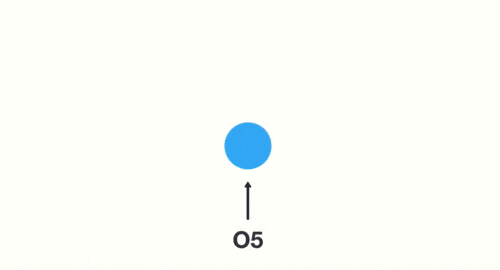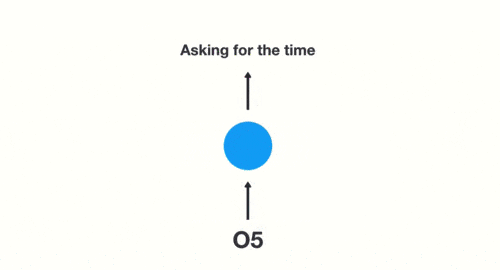
Si necesitamos determinar la intención del usuario al hablar (preguntar por el tiempo, preguntar por la hora, poner un despertador...), y el usuario dice "¿qué hora es?" primero debemos segmentar la frase: luego Ingresamos RNN en orden, primero dividimos

"lo" que se usa como entrada de RNN y se obtiene la salida "01".
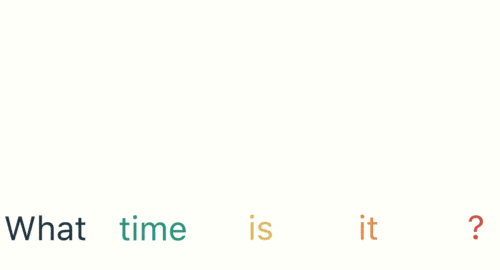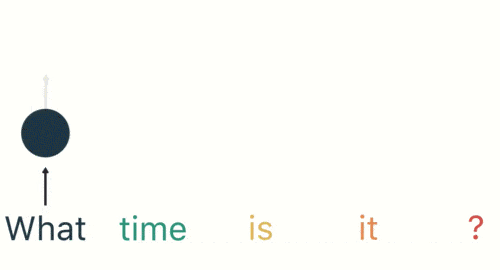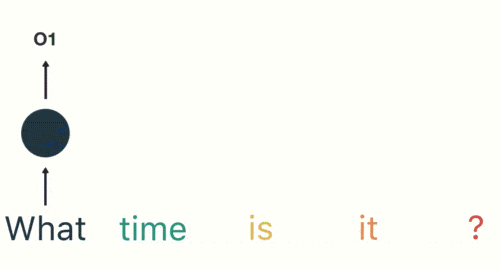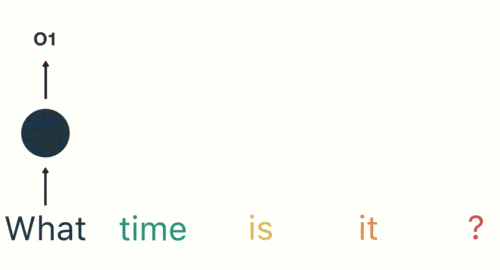
Luego, ingresamos "tiempo" en la red RNN en secuencia, y la salida "02" es obtenido.
En este proceso, podemos ver que cuando se ingresa "tiempo", la salida del "qué" anterior también tiene un impacto (la mitad de la capa oculta es negra).

Por analogía, todas las entradas anteriores tienen un impacto en la salida futura. Puede ver que la capa circular oculta contiene todos los colores anteriores. Como se muestra en la siguiente figura:
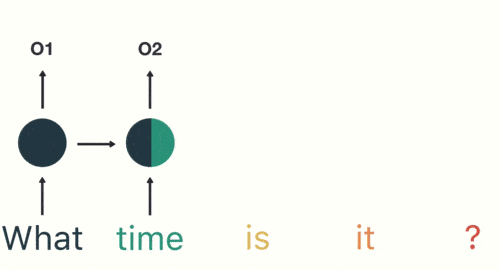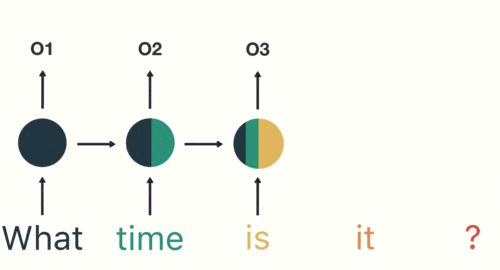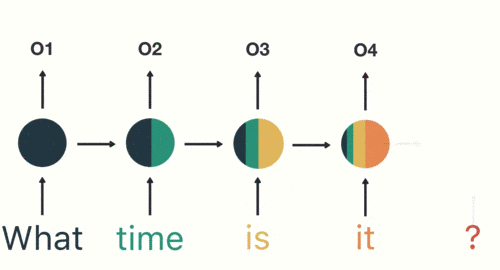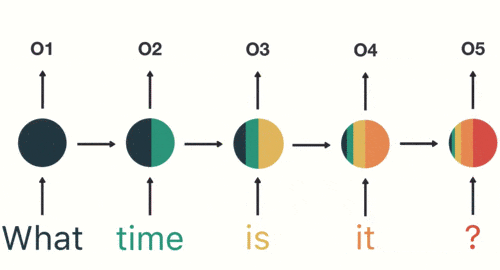
cuando juzgamos la intención, solo necesitamos la salida "05" de la última capa, como se muestra en la siguiente figura:
Las deficiencias de RNN también son obvias.
A través del ejemplo anterior, hemos descubierto que La memoria a corto plazo tiene un mayor impacto (como el área naranja), pero el impacto en la memoria a largo plazo es muy pequeño (como las áreas negra y verde), este es el problema de la memoria a corto plazo de RNN.
- RNN tiene problemas de memoria a corto plazo y no puede manejar secuencias de entrada muy largas
- Entrenar a RNN requiere un costo enorme
Algoritmo de optimización de RNN
LSTM: red de memoria a corto plazo
RNN es una lógica rígida: cuanto más tarde la entrada tiene un mayor impacto, antes la entrada tiene un impacto menor y esta lógica no se puede cambiar.
El mayor cambio realizado por LSTM es romper esta lógica rígida y utilizar una lógica flexible, reteniendo solo información importante.
En pocas palabras: ¡concéntrate en los puntos clave!

Por ejemplo, leamos rápidamente el siguiente párrafo:

una vez que terminemos de leerlo rápidamente, es posible que solo recordemos los siguientes puntos clave:

LSTM es similar a los puntos resaltados anteriormente. Puede retener la "información importante" en datos de secuencia más largos". ignorando información sin importancia. Esto resuelve el problema de la memoria a corto plazo RNN.
principio
La capa oculta del RNN original tiene solo un estado h, que es muy sensible a entradas a corto plazo. Luego, si agregamos otro mecanismo de puerta para controlar la circulación y la pérdida de características, es decir, c, y dejamos que guarde el estado a largo plazo, esta es la red de memoria a largo plazo (Long Short Term Memory, LSTM).
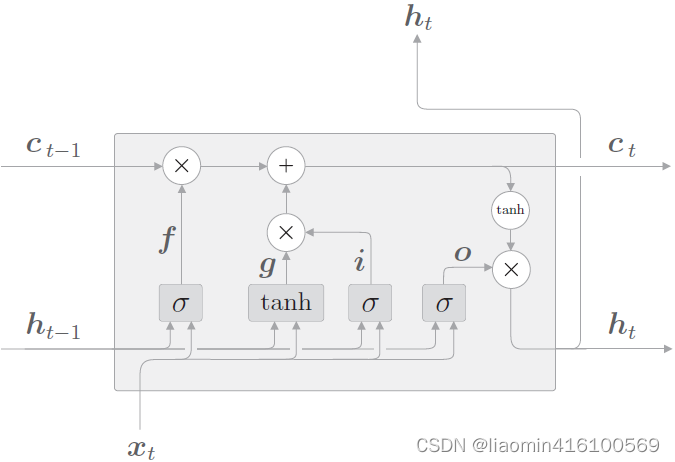
El estado c recién agregado se llama estado unitario. Ampliamos el LSTM según la dimensión temporal:
donde el logo en la imagen σ \sigmaLa bandera σ se activa usando sigmod a [0-1],tanh \tanhtanh se activa a [-1,1]
⨀ es un símbolo matemático que representa el producto por elementos o producto de Hadamard. Cuando dos matrices, vectores o tensores de las mismas dimensiones se multiplican por elementos, se puede utilizar el símbolo ⨀ para indicarlo.
Por ejemplo, para dos vectores [a1, a2, a3] ⨀ [b1, b2, b3]=[a1 b1 , a2 b2, a3*b3], se puede expresar su producto por elementos.
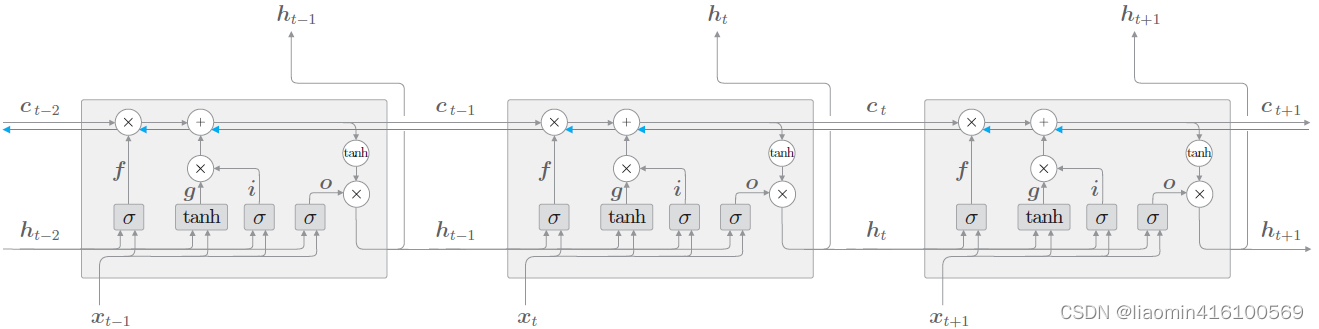
Se puede ver que en el momento t,
Hay tres entradas para LSTM: el valor de salida de la red en el momento actual xt x_tXt, el valor de salida de LSTM en el momento anterior ht − 1 h_{t−1}ht - 1, y el vector unitario de memoria ct − 1 c_{t−1} del momento anteriorCt - 1;
Hay dos salidas de LSTM: el valor de salida de LSTM del momento actual ht h_tht, el vector de estado oculto ht h_t en el momento actualhty el vector de estado de la unidad de memoria ct c_t en el momento actualCt。
Nota: La unidad de memoria c finaliza su trabajo dentro de la capa LSTM y no genera salida a otras capas. La salida de LSTM es solo el vector de estado oculto h.
La clave de LSTM es el estado de la celda, que es la línea horizontal que atraviesa la parte superior del gráfico, un poco como una cinta transportadora. Esta parte generalmente se denomina estado celular y existe en todo el sistema de cadena de LSTM de principio a fin.
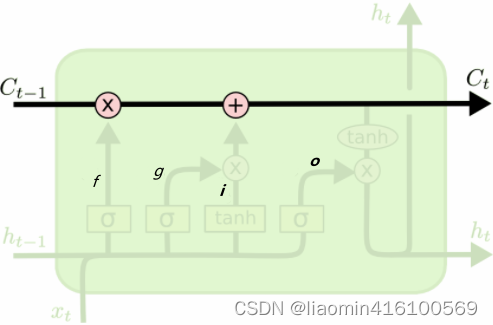
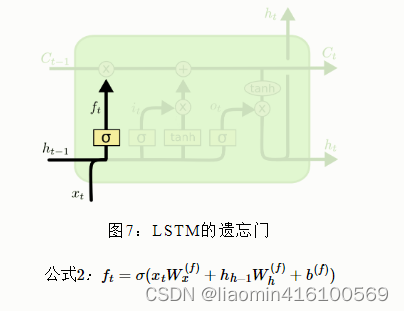
puerta del olvido
pies f_tFtSe llama puerta del olvido , que significa C t − 1 C_{t−1}Ct - 1¿Qué características se utilizan para calcular C t C_t?Ct。ft f_tFtes un vector y cada elemento del vector está en el rango (0 ~ 1). Por lo general, usamos sigmoide como función de activación. La salida de sigmoide es un valor entre (0 ~ 1), pero cuando observa un LSTM entrenado, encontrará que la mayoría de los valores de la puerta están muy cerca de 0. O 1 y muy pocos valores más.
puerta de entrada
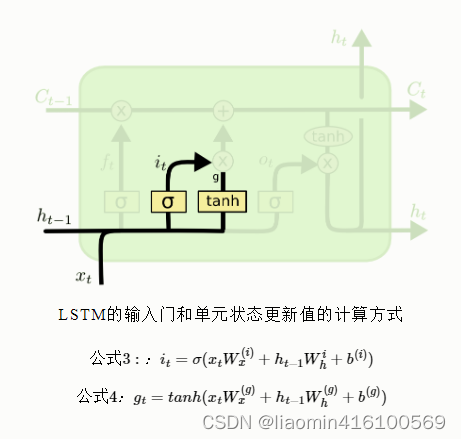
C t C_tCtRepresenta el valor de actualización del estado de la unidad, que está determinado por los datos de entrada xt x_tXty nodo oculto ht − 1 h_{t−1}ht - 1Obtenido a través de una capa de red neuronal, la función de activación del valor de actualización del estado unitario generalmente usa tanh. eso esoitSe llama puerta de entrada, igual que ft f_tFtTambién es un vector cuyos elementos están en el rango (0~1), también representado por xt x_tXty ht − 1 h_{t−1}ht - 1Calculado a través de la función de activación sigmoidea.
puerta de salida
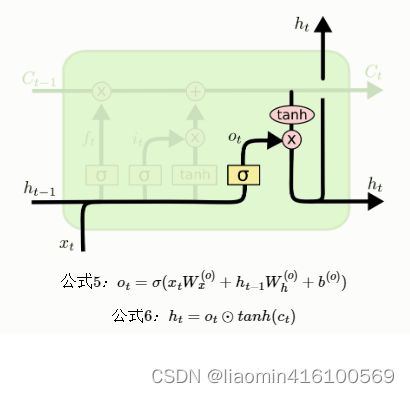
Finalmente, para calcular el valor predicho yty^tyt y generar la entrada completa del siguiente segmento de tiempo, necesitamos calcular la salida del nodo ocultoht h_tht。
lstm escribe poesía
Primero, estudiemos el uso de lstm en pytorch
.
sequence_length =3
batch_size =2
input_size =4
#这里如果是输入比如[张三,李四,王五],一般实际使用需要通过embedding后生成一个[时间步是3,批量1(这里是1,但是如果是真实数据集可能有分批处理,就是实际的批次值),3(三个值的坐标表示一个张三或者李四)]
input=t.randn(sequence_length,batch_size,input_size)
lstmModel=nn.LSTM(input_size,3,1)
#其中,output是RNN每个时间步的输出,hidden是最后一个时间步的隐藏状态。
output, (h, c) =lstmModel(input)
#因为是3个时间步,每个时间步都有一个隐藏层,每个隐藏层都有2条数据,隐藏层的维度是3,最终(3,2,3)
print("LSTM隐藏层输出的维度",output.shape)
#
print("LSTM隐藏层最后一个时间步输出的维度",h.shape)
print("LSTM隐藏层最后一个时间步细胞状态",c.shape)
producción
LSTM隐藏层输出的维度 torch.Size([3, 2, 3])
LSTM隐藏层最后一个时间步输出的维度 torch.Size([1, 2, 3])
LSTM隐藏层最后一个时间步细胞状态 torch.Size([1, 2, 3])
Lstm de doble capa
sequence_length =3
batch_size =2
input_size =4
input=t.randn(sequence_length,batch_size,input_size)
lstmModel=nn.LSTM(input_size,3,num_layers=2)
#其中,output是RNN每个时间步的输出,hidden是最后一个时间步的隐藏状态。
output, (h, c) =lstmModel(input)
print("2层LSTM隐藏层输出的维度",output.shape)
print("2层LSTM隐藏层最后一个时间步输出的维度",h.shape)
print("2层LSTM隐藏层最后一个时间步细胞状态",c.shape)
Salida:
Dimensión de la salida de la capa oculta de la antorcha LSTM de 2 capas. Tamaño ([3, 2, 3]) Dimensión de la
salida del último paso de tiempo de la capa oculta de la antorcha LSTM de 2 capas. Tamaño ([ 2, 2, 3])
Oculto de LSTM de 2 capas El estado de la celda del último paso de tiempo de la antorcha de capa. Tamaño ([2, 2, 3])
Para 2 capas, la salida es la salida de la última capa oculta. hyc son dos capas de capas ocultas y celdas de memoria en un paso de tiempo.
Ejemplo de inicio de un poema
Esta es la estructura de directorios del proyecto
Descargar datos
Los datos experimentales provienen de más de 50.000 poemas Tang recopilados por entusiastas chinos en Github. El autor realizó algunos procesamientos de datos sobre esta base. Dado que el procesamiento de datos requiere mucho tiempo y no es el foco del aprendizaje de pytorch, se omite aquí. El autor proporciona un paquete comprimido numeroso tang.npz, la dirección de descarga
puede hacer referencia a la estructura específica de los datos, la parte principal del código a continuación
from torch.utils.data import Dataset,DataLoader
import numpy as np
class PoetryDataset(Dataset):
def __init__(self,root):
self.data=np.load(root, allow_pickle=True)
def __len__(self):
return len(self.data["data"])
def __getitem__(self, index):
return self.data["data"][index]
def getData(self):
return self.data["data"],self.data["ix2word"].item(),self.data["word2ix"].item()
if __name__=="__main__":
datas=PoetryDataset("./tang.npz").data
# data是一个57580 * 125的numpy数组,即总共有57580首诗歌,每首诗歌长度为125个字符(不足125补空格,超过125的丢弃)
print(datas["data"].shape)
#这里都字符已经转换成了索引
print(datas["data"][0])
# 使用item将numpy转换为字典类型,ix2word存储这下标对应的字,比如{0: '憁', 1: '耀'}
ix2word = datas['ix2word'].item()
print(ix2word)
# word2ix存储这字对应的小标,比如{'憁': 0, '耀': 1}
word2ix = datas['word2ix'].item()
print(word2ix)
# 将某一首古诗转换为索引表示,转换后:[5272, 4236, 3286, 6933, 6010, 7066, 774, 4167, 2018, 70, 3951]
str="床前明月光,疑是地上霜"
print([word2ix[i] for i in str])
#将第一首古诗打印出来
print([ix2word[i] for i in datas["data"][0]])
Definir modelo
import torch.nn as nn
class Net(nn.Module):
"""
:param vocab_size 表示输入单词的格式
:param embedding_dim 表示将一个单词映射到embedding_dim维度空间
:param hidden_dim 表示lstm输出隐藏层的维度
"""
def __init__(self, vocab_size, embedding_dim, hidden_dim):
super(Net, self).__init__()
self.hidden_dim = hidden_dim
#Embedding层,将单词映射成vocab_size行embedding_dim列的矩阵,一行的坐标代表第一行的词
self.embeddings = nn.Embedding(vocab_size, embedding_dim)
#两层lstm,输入词向量的维度和隐藏层维度
self.lstm = nn.LSTM(embedding_dim, self.hidden_dim, num_layers=2, batch_first=False)
#最后将隐藏层的维度转换为词汇表的维度
self.linear1 = nn.Linear(self.hidden_dim, vocab_size)
def forward(self, input, hidden=None):
#获取输入的数据的时间步和批次数
seq_len, batch_size = input.size()
#如果没有传入上一个时间的隐藏值,初始一个,注意是2层
if hidden is None:
h_0 = input.data.new(2, batch_size, self.hidden_dim).fill_(0).float()
c_0 = input.data.new(2, batch_size, self.hidden_dim).fill_(0).float()
else:
h_0, c_0 = hidden
#将输入的数据embeddings为(input行数,embedding_dim)
embeds = self.embeddings(input) # (seq_len, batch_size, embedding_dim), (1,1,128)
output, hidden = self.lstm(embeds, (h_0, c_0)) #(seq_len, batch_size, hidden_dim), (1,1,256)
output = self.linear1(output.view(seq_len*batch_size, -1)) # ((seq_len * batch_size),hidden_dim), (1,256) → (1,8293)
return output, hidden
tren
El siguiente código: entrada, destino = (datos[:-1, :]), (datos[1:, :])Explicación:
Cuando se utiliza LSTM para la predicción de palabras, la entrada y las etiquetas se configuran para alinear la secuencia de entrada con la secuencia objetivo.
En un modelo de lenguaje, queremos predecir la siguiente palabra en función de las palabras anteriores. Por lo tanto, la secuencia de entrada es la palabra anterior y la secuencia de destino es la siguiente palabra.
Considere el siguiente ejemplo:
Supongamos que tenemos una oración: "Me encanta el aprendizaje profundo".
Podemos dividirla en secuencias de entrada y de destino de la forma:
Secuencia de entrada: ["I", "love", "deep"]
Secuencia de destino : ["amor", "profundo", "aprendizaje"]
En este ejemplo, la secuencia de entrada es la palabra anterior ["yo", "amor", "profundo"] y la secuencia de destino es la siguiente palabra correspondiente ["amor", "profundo", "aprendizaje"].
En el código, los datos son un conjunto de datos que contiene todas las palabras, donde cada fila representa una palabra. Al dividir datos en entrada y destino, usamos datos[:-1, :] como secuencia de entrada, es decir, excepto la última palabra. Y data[1:, :] sirve como secuencia objetivo, comenzando desde la segunda palabra.
El propósito de configurar las secuencias de entrada y de destino de esta manera es alinear la entrada y las etiquetas para que el modelo pueda predecir la siguiente palabra basándose en las palabras anteriores.
import fire
import torch.nn as nn
import torch as t
from data.dataset import PoetryDataset
from models.model import Net
num_epochs=5
data_root="./data/tang.npz"
batch_size=10
def train(**kwargs):
datasets=PoetryDataset(data_root)
data,ix2word,word2ix=datasets.getData()
lenData=len(data)
data = t.from_numpy(data)
dataloader = t.utils.data.DataLoader(data, batch_size=batch_size, shuffle=True, num_workers=1)
#总共有8293的词。模型定义:vocab_size, embedding_dim, hidden_dim = 8293 * 128 * 256
model=Net(len(word2ix),128,256)
#定义损失函数
criterion = nn.CrossEntropyLoss()
model=model.cuda()
optimizer = t.optim.Adam(model.parameters(), lr=1e-3)
iteri=0
filename = "example.txt"
totalIter=lenData*num_epochs/batch_size
for epoch in range(num_epochs): # 最大迭代次数为8
for i, data in enumerate(dataloader): # 一批次数据 128*125
data = data.long().transpose(0,1).contiguous() .cuda()
optimizer.zero_grad()
input, target = (data[:-1, :]), (data[1:, :])
output, _ = model(input)
loss = criterion(output, target.view(-1)) # torch.Size([15872, 8293]), torch.Size([15872])
loss.backward()
optimizer.step()
iteri+=1
if(iteri%500==0):
print(str(iteri+1)+"/"+str(totalIter)+"epoch")
if (1 + i) % 1000 == 0: # 每575个batch可视化一次
with open(filename, "a") as file:
file.write(str(i) + ':' + generate(model, '床前明月光', ix2word, word2ix)+"\n")
t.save(model.state_dict(), './checkpoints/model_poet_2.pth')
def generate(model, start_words, ix2word, word2ix): # 给定几个词,根据这几个词生成一首完整的诗歌
txt = []
for word in start_words:
txt.append(word)
input = t.Tensor([word2ix['<START>']]).view(1,1).long() # tensor([8291.]) → tensor([[8291.]]) → tensor([[8291]])
input = input.cuda()
hidden = None
num = len(txt)
for i in range(48): # 最大生成长度
output, hidden = model(input, hidden)
if i < num:
w = txt[i]
input = (input.data.new([word2ix[w]])).view(1, 1)
else:
top_index = output.data[0].topk(1)[1][0]
w = ix2word[top_index.item()]
txt.append(w)
input = (input.data.new([top_index])).view(1, 1)
if w == '<EOP>':
break
return ''.join(txt)
if __name__=="__main__":
fire.Fire()
5 épocas, 10 lotes, PC normal, GTX1050, memoria de vídeo de 2 GB, el tiempo de entrenamiento es de 30 minutos.
50epoch 128batch colab free gpu 16GB de memoria, tiempo de entrenamiento 1 hora
prueba
def test():
datasets = PoetryDataset(data_root)
data, ix2word, word2ix = datasets.getData()
modle = Net(len(word2ix), 128, 256) # 模型定义:vocab_size, embedding_dim, hidden_dim —— 8293 * 128 * 256
if t.cuda.is_available() == True:
modle.cuda()
modle.load_state_dict(t.load('./checkpoints/model_poet_2.pth'))
modle.eval()
name = input("请输入您的开头:")
txt = generate(modle, name, ix2word, word2ix)
print(txt)
Dado que solo ha sido entrenado durante 5 épocas, el efecto no es muy bueno. Después de visualizar la pérdida, puede ver el efecto en varias épocas. Hay otro problema. Si la entrada no cambia, los resultados generados serán los mismos. por lo que esto puede requerir interferencias de ruido.
efecto de versión de 5 épocas
(env380) D:\code\deeplearn\learn_rnn\pytorch\4.nn模块\案例\生成古诗\tang>python main.py test
请输入您的开头:唧唧复唧唧
唧唧复唧唧,不知何所如?君不见此地,不如此中生。一朝一杯酒,一日相追寻。一朝一杯酒,一醉一相逢。
(env380) D:\code\deeplearn\learn_rnn\pytorch\4.nn模块\案例\生成古诗\tang>python main.py test
请输入您的开头:我儿小谦谦
我儿小谦谦,不是天地间。有时有所用,不是无为名。有时有所用,不是无生源。有时有所用,不是无生源。
efecto de versión de 50 épocas
(env380) D:\code\deeplearn\learn_rnn\pytorch\4.nn模块\案例\生成古诗\tang>python main.py test
请输入您的开头:我家小谦谦
我家小谦谦,今古何为郎。我生不相识,我心不可忘。我来不我见,我亦不得尝。君今不我见,我亦不足伤。
(env380) D:\code\deeplearn\learn_rnn\pytorch\4.nn模块\案例\生成古诗\tang>python main.py test
请输入您的开头:床前明月光
床前明月光,上客不可见。玉楼金阁深,玉瑟风光紧。玉指滴芭蕉,飘飘出罗幕。玉堂无尘埃,玉节凌风雷。
(env380) D:\code\deeplearn\learn_rnn\pytorch\4.nn模块\案例\生成古诗\tang>python main.py test
请输入您的开头:唧唧复唧唧
唧唧复唧唧,胡儿女卿侯。妾本邯郸道,相逢两不游。妾心不可再,妾意不能休。妾本不相见,妾心如有钩。
gru
Unidad recurrente cerrada: GRU es una variante de LSTM. Conserva las características de LSTM de resaltar y olvidar información sin importancia, y no se perderá durante la propagación a largo plazo.
LSTM tiene demasiados parámetros y lleva mucho tiempo calcularlos. Por lo tanto, la industria ha propuesto recientemente GRU (Unidad Recurrente Cerrada). GRU conserva el concepto de utilizar puertas en LSTM, pero reduce los parámetros y acorta el tiempo de cálculo.
En comparación con LSTM, que usa dos líneas: estado oculto y unidad de memoria, GRU solo usa estado oculto. Las similitudes y diferencias son las siguientes:
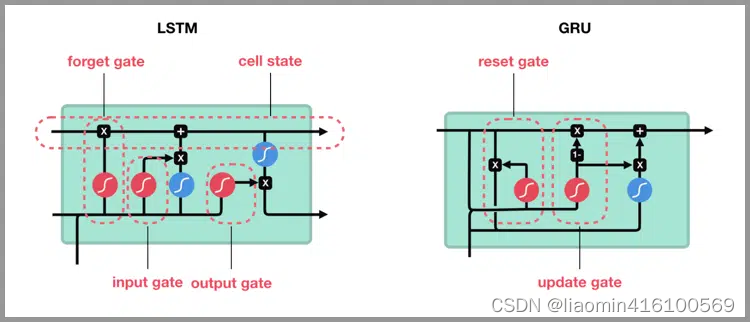
Gráfico de cálculo de GRU Gráfico
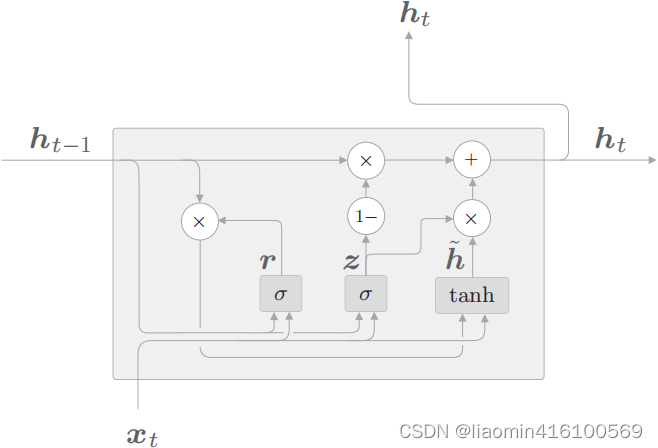
de cálculo de GRU, los nodos σ y los nodos tanh tienen pesos dedicados, y la transformación afín se realiza dentro de los nodos (el nodo "1-" ingresa x y genera 1 - x). Las operaciones realizadas en GRU se componen de los 4 anteriores
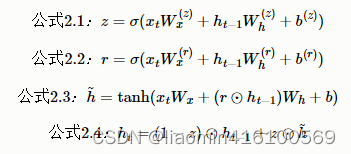
Expresado mediante una ecuación (aquí xt y ht−1 son vectores de fila), como se muestra en la figura, GRU no tiene unidad de memoria y solo un estado oculto h se propaga en la dirección del tiempo. Aquí se utilizan dos puertas, r y z (LSTM usa 3 puertas), r se llama puerta de reinicio y z se llama puerta de actualización.
r (puerta de reinicio) determina hasta qué punto se "ignoran" los estados ocultos pasados. Según la Ecuación 2.3, si r es 0, el nuevo estado oculto h~ sólo depende de la entrada xt x_tXt. Es decir, los estados ocultos del pasado en este punto serán completamente ignorados.
z (puerta de actualización) ** es una puerta que actualiza el estado oculto y desempeña las dos funciones de puerta de olvido y puerta de entrada de LSTM. (1−z)⊙ ht − 1 h_{t−1} de la Fórmula 2.4ht - 1Funciona parcialmente como una puerta de olvido, eliminando información que debería olvidarse de su estado oculto pasado. z⊙hh ^~h La pieza actúa como una puerta de entrada para ponderar la información recién agregada.