Directorio de artículos
1. Trabajo preliminar
- importar biblioteca
- función de generación de imágenes
- Datos de importacion
- generar función de conjunto de datos
2. Establecimiento del modelo CNN
3. Función del modelo de entrenamiento
4. Modelo de entrenamiento y resultados
5. Verificación
Hola a todos, soy Weixue AI. Hoy les traeré una herramienta de reconocimiento de OCR chino que utiliza la red neuronal convolucional (CNN) para realizar su propia herramienta de reconocimiento de OCR.
El propósito de un sistema de reconocimiento OCR es muy simple. Es solo convertir la imagen para que los gráficos en la imagen puedan continuar guardándose. Si hay una tabla, los datos en la tabla y el texto en la imagen serán todos convertirse en texto de computadora, de modo que se puedan lograr los datos de la imagen.La capacidad de almacenamiento se reduce y los caracteres reconocidos se pueden reutilizar y analizar, lo que puede ahorrar el tiempo de escritura manual.
Diagrama de flujo de atención del reconocimiento OCR chino:
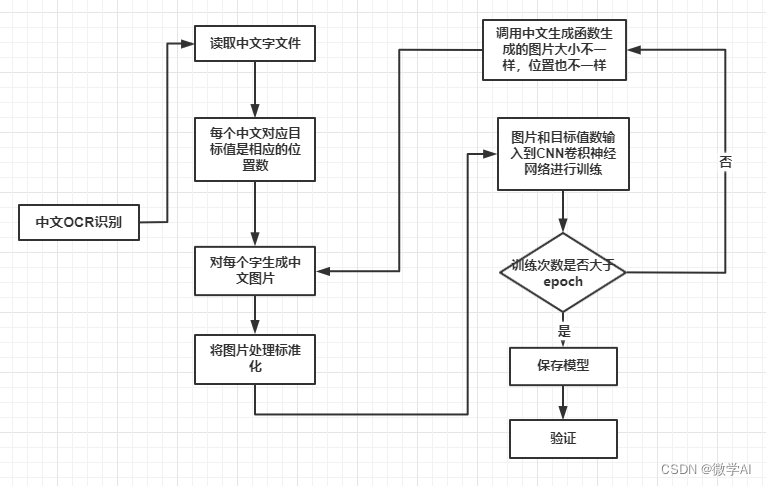
1. Trabajo preliminar
1. Importar biblioteca
import numpy as np
from PIL import Image, ImageDraw, ImageFont
import cv2
import tensorflow as tf
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Convolution2D, MaxPooling2D
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.utils import plot_model
import matplotlib.pyplot as plt
#导入字体
DroidSansFallbackFull = ImageFont.truetype("DroidSansFallback.ttf", 36, 0)
fonts = [DroidSansFallbackFull,]
2. Función de generación de conjuntos de datos
#生成图片,48*48大小
def affineTrans(image, mode, size=(48, 48)):
# print("AffineTrans ...")
if mode == 0: # padding移动
which = np.array([0, 0, 0, 0])
which[np.random.randint(0, 4)] = np.random.randint(0, 10)
which[np.random.randint(0, 4)] = np.random.randint(0, 10)
image = cv2.copyMakeBorder(image, which[0], which[0], which[0], which[0], cv2.BORDER_CONSTANT, value=0)
image = cv2.resize(image, size)
if mode == 1:
scale = np.random.randint(48, int(48 * 1.4))
center = [scale / 2, scale / 2]
image = cv2.resize(image, (scale, scale))
image = image[int(center[0] - 24):int(center[0] + 24), int(center[1] - 24):int(center[1] + 24)]
return image
#图片处理 除噪
def noise(image, mode=1):
# print("Noise ...")
noise_image = (image.astype(float) / 255) + (np.random.random((48, 48)) * (np.random.random() * 0.3))
norm = (noise_image - noise_image.min()) / (noise_image.max() - noise_image.min())
if mode == 1:
norm = (norm * 255).astype(np.uint8)
return norm
#绘制中文的图片
def DrawChinese(txt, font):
# print("DrawChinese...")
image = np.zeros(shape=(48, 48), dtype=np.uint8)
x = Image.fromarray(image)
draw = ImageDraw.Draw(x)
draw.text((8, 2), txt, (255), font=font)
result = np.array(x)
return result
#图片标准化
def norm(image):
# print("norm...")
return image.astype(np.float) / 255
3. Importar datos
char_set = open("chinese.txt",encoding = "utf-8").readlines()[0]
print(len(char_set[0])) # 打印字的个数
4. Generar función de conjunto de datos
# 生成数据:训练集和标签
def Genernate(batchSize, charset):
# print("Genernate...")
# pass
label = [];
training_data = [];
for x in range(batchSize):
char_id = np.random.randint(0, len(charset))
font_id = np.random.randint(0, len(fonts))
y = np.zeros(dtype=np.float, shape=(len(charset)))
image = DrawChinese(charset[char_id], fonts[font_id])
image = affineTrans(image, np.random.randint(0, 2))
# image = noise(image)
# image = augmentation(image,np.random.randint(0,8))
image = noise(image)
image_norm = norm(image)
image_norm = np.expand_dims(image_norm, 2)
training_data.append(image_norm)
y[char_id] = 1
label.append(y)
return np.array(training_data), np.array(label)
def Genernator(charset,batchSize):
print("Generator.....")
while(1):
label = [];
training_data = [];
for i in range(batchSize):
char_id = np.random.randint(0, len(charset))
font_id = np.random.randint(0,len(fonts))
y = np.zeros(dtype=np.float,shape=(len(charset)))
image = DrawChinese(charset[char_id],fonts[font_id])
image = affineTrans(image,np.random.randint(0,2))
#image = noise(image)
#image = augmentation(image,np.random.randint(0,8))
image = noise(image)
image_norm = norm(image)
image_norm = np.expand_dims(image_norm,2)
y[char_id] = 1
training_data.append(image_norm)
label.append(y)
y[char_id] = 1
yield (np.array(training_data),np.array(label))
2. Establecimiento del modelo CNN
def Getmodel(nb_classes):
img_rows, img_cols = 48, 48
nb_filters = 32
nb_pool = 2
nb_conv = 4
model = Sequential()
print("sequential..")
model.add(Convolution2D(nb_filters, nb_conv, nb_conv,
padding='same',
input_shape=(img_rows, img_cols, 1)))
print("add convolution2D...")
model.add(Activation('relu'))
print("activation ...")
model.add(MaxPooling2D(pool_size=(nb_pool, nb_pool)))
model.add(Dropout(0.25))
model.add(Convolution2D(nb_filters, nb_conv, nb_conv,padding='same'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(nb_pool, nb_pool)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(1024))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(nb_classes))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
return model
#评估模型
def eval(model, X, Y):
print("Eval ...")
res = model.predict(X)
3. Función de modelo de entrenamiento
#训练函数
def Training(charset):
model = Getmodel(len(charset))
while (1):
X, Y = Genernate(64, charset)
model.train_on_batch(X, Y)
print(model.loss)
#训练生成模型
def TrainingGenerator(charset, test=1):
set = Genernate(64, char_set)
model = Getmodel(len(charset))
BatchSize = 64
model.fit_generator(generator=Genernator(charset, BatchSize), steps_per_epoch=BatchSize * 10, epochs=15,
validation_data=set)
model.save("ocr.h5")
X = set[0]
Y = set[1]
if test == 1:
print("============6 Test == 1 ")
for i, one in enumerate(X):
x = one
res = model.predict(np.array([x]))
classes_x = np.argmax(res, axis=1)[0]
print(classes_x)
print(u"Predict result:", char_set[classes_x], u"Real result:", char_set[Y[i].argmax()])
image = (x.squeeze() * 255).astype(np.uint8)
cv2.imwrite("{0:05d}.png".format(i), image)
4. Modelo de formación y resultados
TrainingGenerator(char_set) #函数TrainingGenerator 开始训练
Epoch 1/15
640/640 [==============================] - 63s 76ms/step - loss: 8.1078 - accuracy: 3.4180e-04 - val_loss: 8.0596 - val_accuracy: 0.0000e+00
Epoch 2/15
640/640 [==============================] - 102s 159ms/step - loss: 7.5234 - accuracy: 0.0062 - val_loss: 6.2163 - val_accuracy: 0.0781
Epoch 3/15
640/640 [==============================] - 38s 60ms/step - loss: 5.9793 - accuracy: 0.0425 - val_loss: 4.1687 - val_accuracy: 0.3281
Epoch 4/15
640/640 [==============================] - 45s 71ms/step - loss: 5.0450 - accuracy: 0.0889 - val_loss: 3.1590 - val_accuracy: 0.4844
Epoch 5/15
640/640 [==============================] - 37s 58ms/step - loss: 4.5251 - accuracy: 0.1292 - val_loss: 2.5326 - val_accuracy: 0.5938
Epoch 6/15
640/640 [==============================] - 38s 60ms/step - loss: 4.1708 - accuracy: 0.1687 - val_loss: 1.9666 - val_accuracy: 0.7031
Epoch 7/15
640/640 [==============================] - 35s 54ms/step - loss: 3.9068 - accuracy: 0.1951 - val_loss: 1.8039 - val_accuracy: 0.7812
...
910
Predict result: 妻 Real result: 妻
1835
Predict result: 莱 Real result: 莱
3107
Predict result: 阀 Real result: 阀
882
Predict result: 培 Real result: 培
1241
Predict result: 鼓 Real result: 鼓
735
Predict result: 豆 Real result: 豆
1844
Predict result: 巾 Real result: 巾
1714
Predict result: 跌 Real result: 跌
2580
Predict result: 骄 Real result: 骄
1788
Predict result: 氧 Real result: 氧
Generar una imagen de fuente:

Cinco, verificación
model = tf.keras.models.load_model("ocr.h5")
img1 = cv2.imread('00001.png',0)
img = cv2.resize(img1,(48,48))
print(img.shape)
img2 = tf.expand_dims(img, 0)
res = model.predict(img2)
classes_x = np.argmax(res, axis=1)[0]
print(classes_x)
print(u"Predict result:", char_set[classes_x])
Caracteres chinos:

el resultado predicho es "Lai; ¡
envíame un mensaje privado para la adquisición del conjunto de datos! Habrá una función de reconocimiento OCR más profunda en la etapa posterior, ¡así que estad atentos!
Trabajos anteriores: Proyectos prácticos de aprendizaje
profundo
1. Práctica de aprendizaje profundo 1-(keras framework) análisis y predicción de datos empresariales
8. Deep Learning Combat 8-Life Photo Transformation Comic Photo Application
16. Práctica de aprendizaje profundo 16 (versión avanzada) - texto de reconocimiento de captura de pantalla virtual - puede hacer contrato en papel y reconocimiento de formulario
17. Práctica de aprendizaje profundo 17 (edición avanzada) - Caso de construcción y desarrollo del sistema de plataforma de edición de asistente inteligente
18. Deep Learning Combat 18 (Edición avanzada): 15 tareas del sistema de fusión NLP, que puede realizar las tareas de PNL que puede pensar en el mercado
19. Práctica de aprendizaje profundo 19 (edición avanzada): prueba de implementación de implementación local de ChatGPT, ChatGPT se puede implementar en su propia plataforma
…(actualización pendiente)