Después de comprender las ideas clave de la regresión lineal, es hora de implementar la regresión lineal con código.
Directorio de artículos
1.1 Implementación desde cero
Si bien los marcos modernos de aprendizaje profundo pueden automatizar casi todo esto, implementarlo desde cero garantiza que realmente sepa lo que está haciendo. Al mismo tiempo, comprender el principio de funcionamiento más detallado nos facilitará personalizar el modelo, la capa personalizada o la función de pérdida personalizada.
%matplotlib inline
import random
import torch
from d2l import torch as d2l
1.1.1 Generar conjunto de datos
Genere un conjunto de datos con 1000 muestras, cada muestra contiene 2 características muestreadas de una distribución normal estándar.
def synthetic_data(w, b, num_examples):
"""生成y=Xw+b+噪声"""
X = torch.normal(0, 1, (num_examples, len(w)))
y = torch.matmul(X, w) + b
y += torch.normal(0, 0.01, y.shape)
return X, y.reshape((-1, 1))
true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = synthetic_data(true_w, true_b, 1000)
Cada fila de características contiene una muestra de datos bidimensional y cada fila de etiquetas contiene un valor de etiqueta unidimensional (un escalar).
print('features:', features[0],'\nlabel:', labels[0])
features: tensor([ 0.6631, -0.7805])
label: tensor([8.1842])
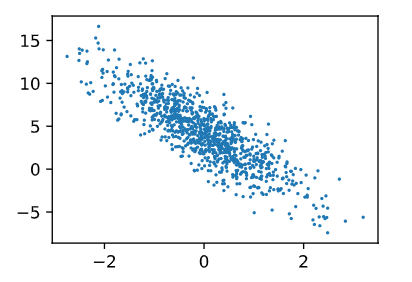
Al generar un gráfico de dispersión de las características de la segunda característica [:, 1] y las etiquetas, se puede observar visualmente la relación lineal entre las dos.
d2l.set_figsize()
d2l.plt.scatter(features[:, (1)].detach().numpy(), labels.detach().numpy(), 1);
1.1.2 Leer el conjunto de datos
Defina una función que mezcle las muestras en el conjunto de datos y obtenga los datos en mini lotes.
La función data_iter, que recibe el tamaño del lote, la matriz de características y el vector de etiquetas como entrada, genera mini lotes de tamaño batch_size. Cada minilote contiene un conjunto de funciones y etiquetas.
def data_iter(batch_size, features, labels):
num_examples = len(features)
indices = list(range(num_examples))
# 这些样本是随机读取的,没有特定的顺序
random.shuffle(indices)
for i in range(0, num_examples, batch_size):
batch_indices = torch.tensor(
indices[i: min(i + batch_size, num_examples)])
yield features[batch_indices], labels[batch_indices]
batch_size = 10
for X, y in data_iter(batch_size, features, labels):
print(X, '\n', y)
break
producción:
tensor([[-0.8841, 0.0372],
[-0.3387, 0.3164],
[ 0.3212, 2.0915],
[ 0.4819, -1.2344],
[-0.2791, -0.1832],
[ 1.6380, 0.6086],
[ 0.7341, 1.1638],
[ 1.0234, -1.5223],
[-2.6958, 0.1999],
[-1.5663, -2.0430]])
tensor([[ 2.2757],
[ 2.4552],
[-2.2666],
[ 9.3455],
[ 4.2686],
[ 5.4153],
[ 1.6975],
[11.4085],
[-1.8559],
[ 8.0139]])
1.1.3 Inicializar parámetros del modelo
Los pesos se inicializan muestreando números aleatorios de una distribución normal con media 0 y desviación estándar 0,01, y los sesgos se inicializan en 0.
w = torch.normal(0, 0.01, size=(2,1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
Después de inicializar los parámetros, nuestra tarea es actualizar estos parámetros hasta que estos parámetros sean suficientes para ajustarse a nuestros datos.
1.1.4 Definición del modelo
Para calcular la salida del modelo lineal, simplemente calculamos la multiplicación matriz-vector de las características de entrada X y los pesos del modelo w seguidos por el sesgo b. Xw es un vector y b es un escalar. Cuando agregamos un escalar a un vector, el escalar se agrega a cada componente del vector.
def linreg(X, w, b):
"""线性回归模型"""
return torch.matmul(X, w) + b
1.1.5 Definir la función de pérdida
Utilice una función de pérdida al cuadrado.
def squared_loss(y_hat, y):
"""均方损失"""
return (y_hat - y.reshape(y_hat.shape)) ** 2 / 2
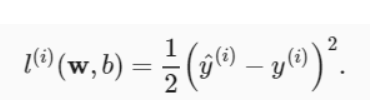
1.1.6 Definición del algoritmo de optimización
En cada paso, se utiliza un mini lote extraído aleatoriamente del conjunto de datos y luego se calcula el gradiente de la pérdida de acuerdo con los parámetros. Luego, actualice nuestros parámetros en la dirección de reducir la pérdida. La siguiente función implementa actualizaciones de descenso de gradiente estocástico en minilotes. La función acepta un conjunto de parámetros de modelo, tasa de aprendizaje y tamaño de lote como entrada.
def sgd(params, lr, batch_size):
"""小批量随机梯度下降"""
with torch.no_grad():
for param in params:
param -= lr * param.grad / batch_size
param.grad.zero_()
1.1.7 Formación
En cada iteración, leemos un pequeño lote de muestras de entrenamiento y pasamos nuestro modelo para obtener un conjunto de predicciones. Después de calcular la pérdida, comenzamos la retropropagación, almacenando el gradiente de cada parámetro. Finalmente, llamamos al algoritmo de optimización sgd para actualizar los parámetros del modelo. Para recapitular, ejecutaremos el siguiente bucle:
- Parámetros de inicialización
- Repita los siguientes entrenamientos hasta que termine

Use la función data_iter para recorrer todo el conjunto de datos y use todas las muestras en el conjunto de datos de entrenamiento una vez (suponiendo que la cantidad de muestras sea divisible por el tamaño del lote). El número de iteraciones num_epochs y la tasa de aprendizaje lr son ambos hiperparámetros, establecidos en 3 y 0,03, respectivamente.
lr = 0.03
num_epochs = 3
net = linreg
loss = squared_loss
for epoch in range(num_epochs):
for X, y in data_iter(batch_size, features, labels):
l = loss(net(X, w, b), y) # X和y的小批量损失
# 因为l形状是(batch_size,1),而不是一个标量。l中的所有元素被加到一起,
# 并以此计算关于[w,b]的梯度
l.sum().backward()
sgd([w, b], lr, batch_size) # 使用参数的梯度更新参数
with torch.no_grad():
train_l = loss(net(features, w, b), labels)
print(f'epoch {
epoch + 1}, loss {
float(train_l.mean()):f}')
epoch 1, loss 0.040067
epoch 2, loss 0.000148
epoch 3, loss 0.000049
print(f'w的估计误差: {
true_w - w.reshape(true_w.shape)}')
print(f'b的估计误差: {
true_b - b}')
w的估计误差: tensor([ 0.0005, -0.0003], grad_fn=<SubBackward0>)
b的估计误差: tensor([-0.0001], grad_fn=<RsubBackward1>)
1.2 Implementación concisa
Cite algunos marcos de código abierto que automatizan tareas repetitivas en algoritmos de aprendizaje basados en gradientes. Tales como iteradores de datos, funciones de pérdida, optimizadores y capas de redes neuronales, etc.
1.2.1 Generar conjunto de datos
import numpy as np
import torch
from torch.utils import data
from d2l import torch as d2l
true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = d2l.synthetic_data(true_w, true_b, 1000)
1.2.2 Leer el conjunto de datos
def load_array(data_arrays, batch_size, is_train=True):
"""构造一个PyTorch数据迭代器"""
dataset = data.TensorDataset(*data_arrays)
return data.DataLoader(dataset, batch_size, shuffle=is_train)
batch_size = 10
data_iter = load_array((features, labels), batch_size)
Construya un iterador de Python con iter y use next para obtener el primer elemento del iterador.
next(iter(data_iter))
[tensor([[ 0.3142, -0.9088],
[ 0.3454, -0.0573],
[ 0.6141, 0.2420],
[-0.6898, 1.4459],
[ 0.8067, -0.3340],
[ 0.4517, -0.0349],
[-0.0894, 1.7150],
[-0.2578, -1.3239],
[ 1.8576, -0.1634],
[-0.1818, -2.7210]]),
tensor([[ 7.9111],
[ 5.0854],
[ 4.6106],
[-2.0876],
[ 6.9367],
[ 5.2169],
[-1.8110],
[ 8.1817],
[ 8.4688],
[13.1087]])]
1.2.3 Definición del modelo
Para los modelos estándar de aprendizaje profundo, podemos usar las capas predefinidas del marco. Esto nos permite centrarnos solo en qué capas se utilizan para construir el modelo, en lugar de los detalles de implementación de las capas. Primero definimos una variable modelo net, que es una instancia de la clase Sequential. La clase Sequential concatena varias capas juntas. Cuando se le dan datos de entrada, la instancia Sequential pasa los datos a la primera capa, luego usa la salida de la primera capa como la entrada de la segunda capa, y así sucesivamente. En el siguiente ejemplo, nuestro modelo contiene solo una capa, por lo que en realidad no se necesita Sequential. Pero dado que casi todos los modelos en el futuro tienen varias capas, usar Sequential aquí lo familiarizará con las "tuberías estándar".
En PyTorch, las capas completamente conectadas se definen en la clase Lineal. Vale la pena señalar que pasamos dos parámetros a nn.Linear. El primero especifica la forma de la entidad de entrada, que es 2, y el segundo especifica la forma de la entidad de salida, que es un solo escalar, por lo que es 1.
# nn是神经网络的缩写
from torch import nn
net = nn.Sequential(nn.Linear(2, 1))
1.2.4 Inicializar parámetros del modelo
Antes de usar net, necesitamos inicializar los parámetros del modelo. Tales como pesos y sesgos en modelos de regresión lineal. Los marcos de aprendizaje profundo suelen tener métodos predefinidos para inicializar parámetros. Aquí especificamos que cada parámetro de ponderación se debe muestrear aleatoriamente a partir de una distribución normal con media 0 y desviación estándar 0,01, y el parámetro de sesgo se inicializará en cero.
net[0].weight.data.normal_(0, 0.01)
net[0].bias.data.fill_(0)
1.2.5 Definir la función de pérdida
El error cuadrático medio se calcula utilizando la clase MSELoss, también conocida como norma L2 cuadrática. De forma predeterminada, devuelve el promedio de todas las pérdidas de muestra.
loss = nn.MSELoss()
1.2.6 Definición del algoritmo de optimización
El algoritmo de descenso de gradiente estocástico de mini lotes es una herramienta estándar para optimizar redes neuronales, y PyTorch implementa muchas variantes de este algoritmo en el módulo optim. Cuando creamos una instancia de SGD, especificamos los parámetros para optimizar (disponibles en nuestro modelo a través de net.parameters() ) y un diccionario de hiperparámetros requerido por el algoritmo de optimización. El descenso de gradiente estocástico de mini lotes solo necesita establecer el valor lr, que aquí se establece en 0,03.
trainer = torch.optim.SGD(net.parameters(), lr=0.03)
1.2.7 Formación
En cada ciclo de iteración, recorreremos el conjunto de datos (train_data) por completo y seguiremos obteniendo un mini lote de entradas y las etiquetas correspondientes. Para cada mini-lote, hacemos los siguientes pasos:
- Genere predicciones llamando a net(X) y calcule la pérdida l (propagación directa).
- Los gradientes se calculan haciendo backpropagation.
- Actualice los parámetros del modelo llamando al optimizador.
Para medir mejor el efecto del entrenamiento, calculamos la pérdida después de cada época y la imprimimos para monitorear el proceso de entrenamiento.
num_epochs = 3
for epoch in range(num_epochs):
for X, y in data_iter:
l = loss(net(X) ,y)
trainer.zero_grad()
l.backward()
trainer.step()
l = loss(net(features), labels)
print(f'epoch {
epoch + 1}, loss {
l:f}')
epoch 1, loss 0.000275
epoch 2, loss 0.000107
epoch 3, loss 0.000108
Compare los parámetros reales del conjunto de datos generado con los parámetros del modelo obtenidos mediante el entrenamiento con datos limitados. Para acceder a los parámetros, primero accedemos a la capa deseada desde la red, luego leemos los pesos y sesgos de esa capa. Como en la implementación desde cero, nuestros parámetros estimados están muy cerca de los parámetros reales de los datos generados.
w = net[0].weight.data
print('w的估计误差:', true_w - w.reshape(true_w.shape))
b = net[0].bias.data
print('b的估计误差:', true_b - b)
w的估计误差: tensor([-0.0002, -0.0001])
b的估计误差: tensor([0.0014])