Red neuronal y aprendizaje profundo CNN
1. Red neuronal artificial tradicional (ANN)
Una red neuronal artificial tradicional consta de tres capas: capa de entrada, capa oculta y capa de salida. Cada capa está compuesta de neuronas individuales. Cada línea de conexión corresponde a un peso diferente (su valor se llama peso), que necesita ser entrenado.
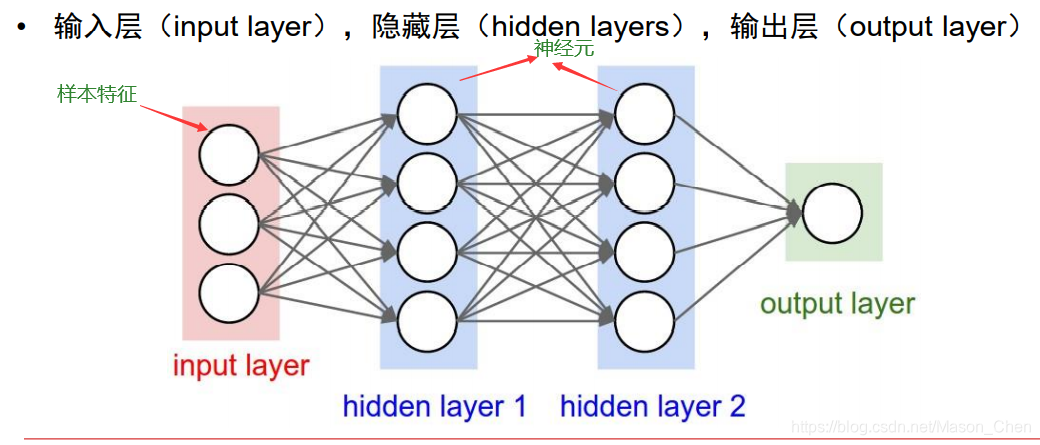
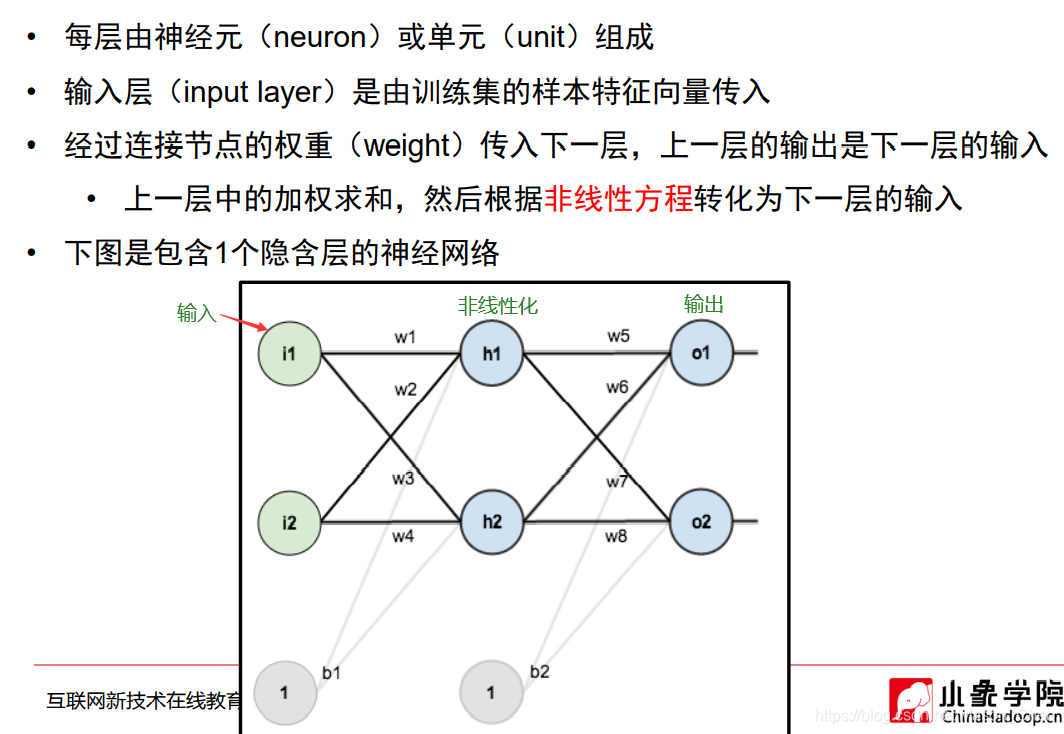
A excepción de la capa de entrada, los nodos de cada capa contienen una transformación no lineal. La no linealización requiere una función de activación.

El problema causado por las múltiples capas es que la complejidad es demasiado alta y conduce al sobreajuste, por lo que se requiere regularización. Se omite
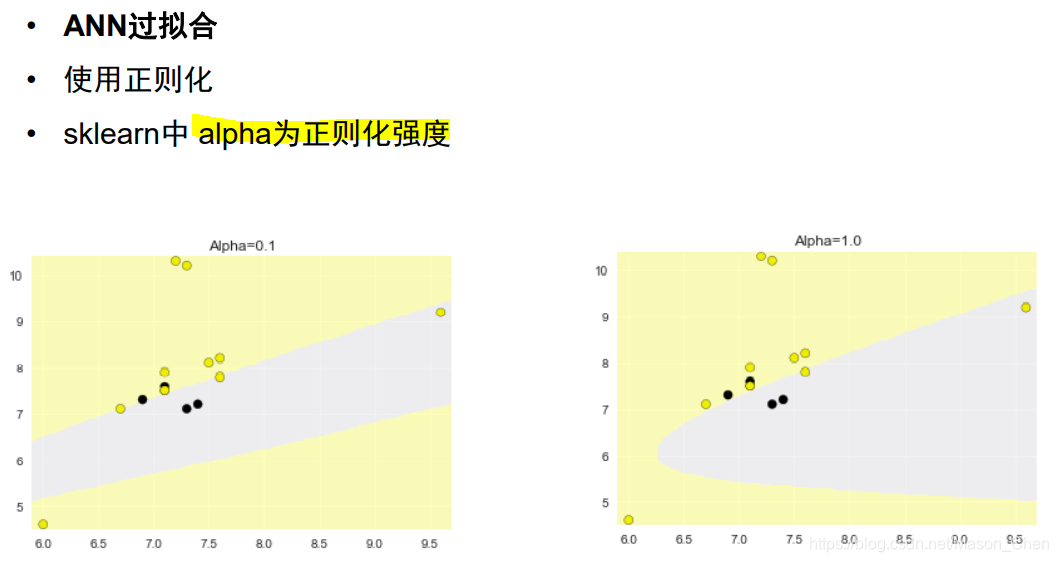

el proceso del algoritmo del algoritmo de retropropagación (bp) .


2. CNN
En la red neuronal artificial totalmente conectada, cada neurona entre cada dos capas adyacentes está conectada por un borde. Cuando la dimensión de la característica de la capa de entrada se vuelve muy alta, los parámetros que la red completamente conectada necesita entrenar aumentarán mucho y la velocidad de cálculo se volverá muy lenta.Por ejemplo, una imagen digital manuscrita en blanco y negro de 28 × 28, entrada Hay 784 neuronas en cada capa.
Si solo se usa una capa oculta en el medio, el parámetro w tendrá más de 784 × 15 = 11760; si la entrada es una imagen digital manuscrita en formato RGB con color de 28 × 28, la neurona de entrada tendrá 28 × 28 × 3 =2352... . Es fácil ver que usar una red neuronal completamente conectada para manejar imágenes requiere demasiados parámetros de entrenamiento.
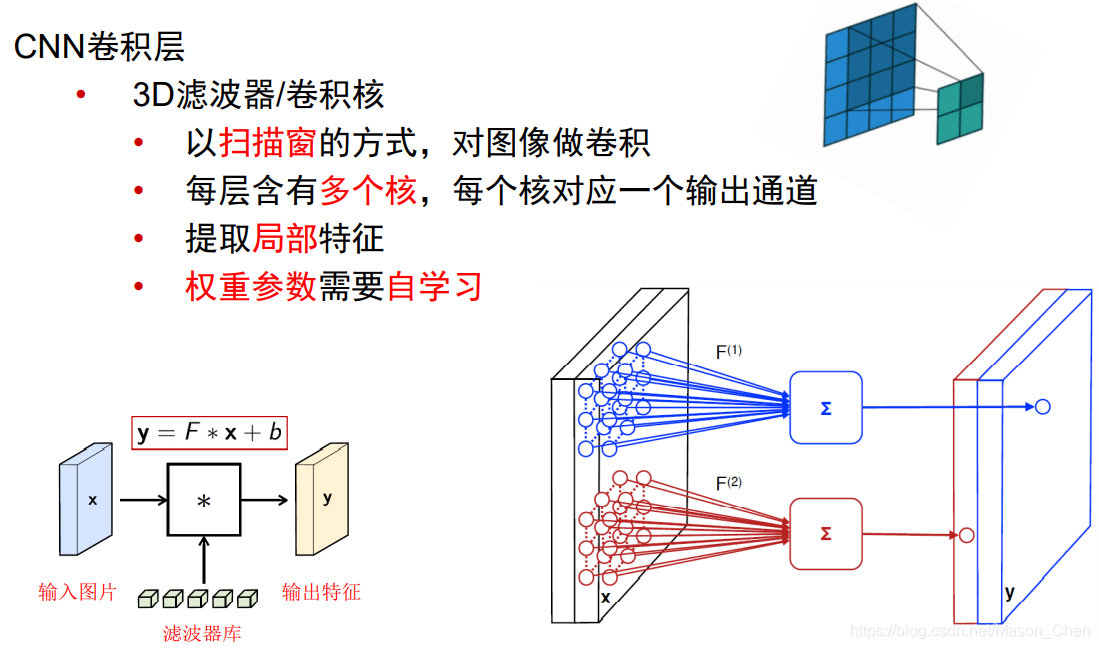
En Convolutional Neural Network (CNN), las neuronas de la capa convolucional solo están conectadas a algunos nodos de neuronas de la capa anterior, es decir, la conexión entre sus neuronas no está completamente conectada, y en la misma capa Los pesos w y compensaciones b de conexiones entre ciertas neuronas se comparten (es decir, lo mismo), lo que reduce en gran medida la cantidad de parámetros que necesitan ser entrenados.
1. Nivel CNN
La estructura de la red neuronal convolucional CNN generalmente incluye estas capas:
- Capa de entrada: para entrada de datos
- Capa de convolución: use el kernel de convolución para la extracción de características y el mapeo de características (extracción de características)
- Capa de excitación: dado que la convolución también es una operación lineal, se debe agregar un mapeo no lineal
- Capa de agrupación: realice un muestreo descendente, procese escasamente el mapa de características y reduzca la cantidad de cálculo de datos. (Reducción de dimensionalidad, prevención de sobreajuste)
- Capa completamente conectada: generalmente se reacondiciona al final de CNN para reducir la pérdida de información de características
- Capa de salida: utilizada para generar resultados
Por supuesto, algunas otras capas funcionales también se pueden usar en el medio:
- Capa de normalización (Batch Normalization): normalización de características en CNN
- Capa de corte: aprendizaje separado de algunos datos (imagen) en diferentes regiones
- Capa de fusión: fusión de ramas que realizan el aprendizaje de funciones de forma independiente
1.1 Capa de entrada
El formato de entrada de la capa de entrada de CNN conserva la estructura de la propia imagen. Para una imagen de 32x32 en formato RGB, la CNN ingresa 3x32x32 neuronas.
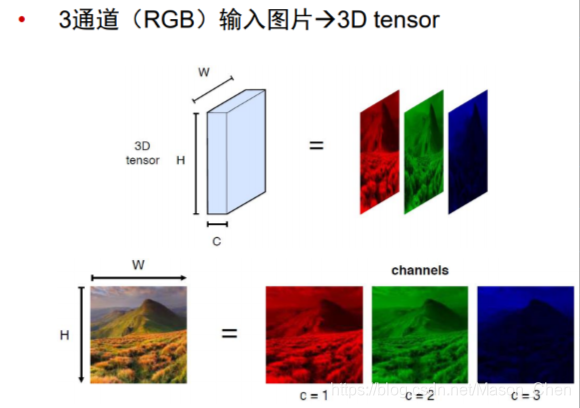

1.2 Capa de convolución
Es necesario aclarar varios conceptos:
-
Campo receptivo (campos receptivos locales)
es experimentar algunas características de la capa anterior. En la red neuronal convolucional, las neuronas en la capa oculta tienen un campo de visión sensorial relativamente pequeño y solo pueden ver algunas características del tiempo anterior. Otras características de la capa anterior se pueden obtener traduciendo el campo de visión sensorial a otro neuronas en la misma capa. -
El kernel de convolución
siente la matriz de peso en el campo de visión -
pesos compartidos
-
Longitud de paso (zancada)
El intervalo de exploración del campo de visión sensorial a la entrada se denomina longitud de zancada (zancada) -
Expansión de límites (almohadilla)
Cuando el tamaño del paso es relativamente grande (zancada> 1), para escanear algunas características del borde, el campo de visión sensorial puede estar "fuera de los límites", entonces se requiere la expansión de límites (almohadilla). -
La siguiente capa de matriz de neuronas generada por un mapa de características a través de un escaneo de campo de visión sensorial con un núcleo de convolución se denomina mapa de características (mapa de características)
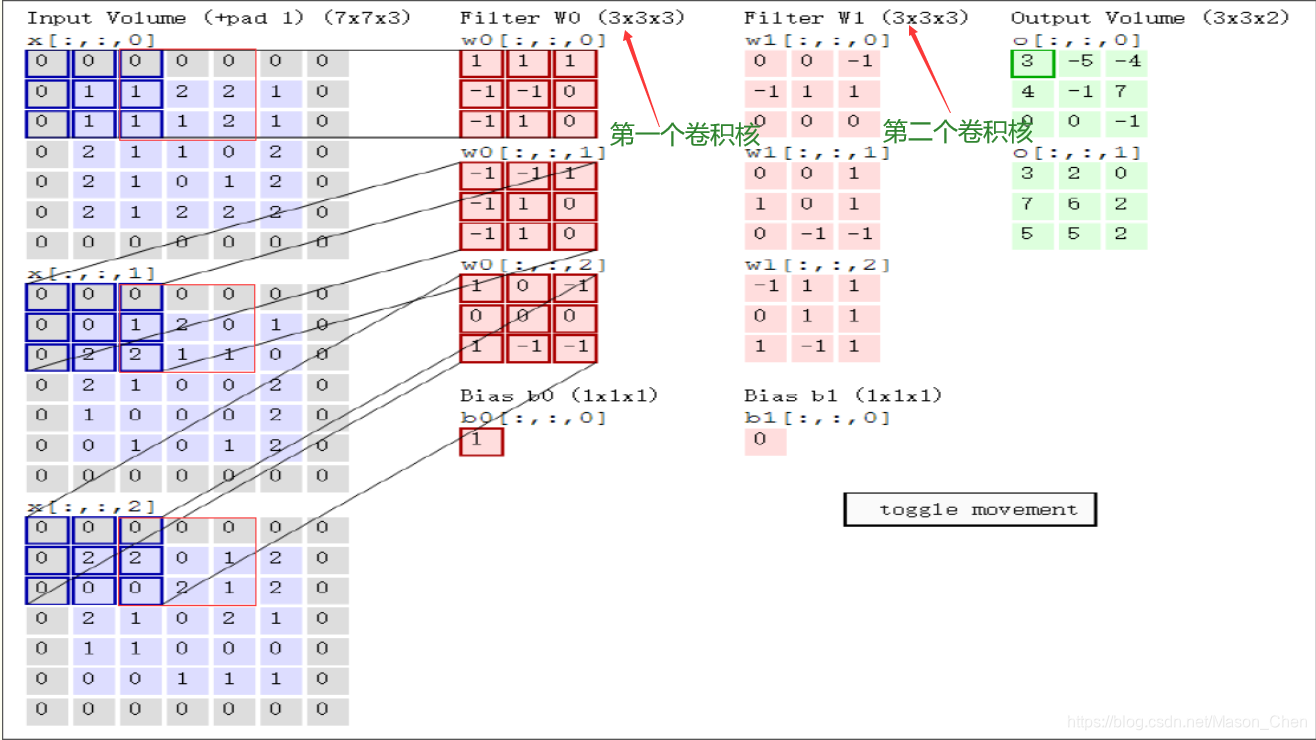
El ejemplo dado aquí es una imagen de entrada (5 5 3), kernel de convolución (3 3 3), hay dos (Filtro W0, W1) y hay dos sesgos b (Bios b0, b1), el resultado de la convolución Volumen de salida (3 3 2), paso = 2.
Entrada: 7 7 3 es porque pad = 1 (los ceros se rellenan tanto en las filas como en las columnas en el borde de la imagen, y el número de filas y sumas rellenadas con ceros es 1),
(Para imágenes en color, generalmente hay tres colores RGB, conocidos como 3 canales, 7*7 se refiere a la altura de la imagen h * ancho w)
, la función del relleno cero es poder extraer las características del límite de la imagen.
¿Por qué la profundidad del kernel de convolución debe establecerse en 3? Esto se debe a que la entrada es de 3 canales, por lo que la profundidad del kernel de convolución debe ser la misma que la profundidad de entrada. En cuanto al ancho del núcleo de convolución w, la altura h se puede cambiar, pero el ancho y la altura deben ser iguales.
El kernel de convolución da como resultado o[0,0,0] = 3 (el resultado del cuadro verde claro debajo del Volumen de salida), ¿cómo se obtiene este resultado? De hecho, la clave es multiplicar y sumar las posiciones correspondientes de la matriz (no lo confundas con la multiplicación de matrices)
=> w0[:,:,0] * x[:,:,0] matriz de área azul (canal R) + w0[:,:,1] * x[:,:,1] matriz de área azul (canal G ) + w0[:,:,2] * x[:,:,2] matriz de área azul (canal B) + b0 (no pierdas, porque y = w * x + b)
Primer elemento => 0*1 + 0*1 + 0*1 + 0*(-1) + 1*(-1) + 1*0 + 0*(-1) + 1*1 + 1*0 = 0
Segundo término => 0 * (-1) + 0 * (-1) + 0 * 1 + 0 * (-1) + 0 * 1 + 1 * 0 + 0 * (-1) + 2 * 1 + 2 * 0 = 2
Tercer término => 0*1 + 0*0 + 0*(-1) + 0*0 + 2*0 + 2*0 + 0*1 + 0*(-1) + 0*(-1) = 0
Salida del kernel de convolución o[0,0,0] = > primer elemento + segundo elemento + tercer elemento + b0 = 0 + 2 + 0 + 1 = 3
¿Cómo se obtiene o[0,0,1] = -5?
Porque stride = 2 aquí, la ventana de entrada tiene que deslizar dos pasos, que es el área del cuadro rojo, y la operación es la misma que antes
Primer elemento => 0*1 + 0*1 + 0*1 + 1*(-1) + 2*(-1) + 2*0 + 1*(-1) + 1*1 + 2*0 = - 3
Segundo término => 0 * (-1) + 0 * (-1) + 0 * 1 + 1 * (-1) + 2 * 1 + 0 * 0 + 2 * (-1) + 1 * 1 + 1 * 0 = 0
Tercer término => 0 * 1 + 0 * 0 + 0 * (-1) + 2 * 0 + 0 * 0 + 1 * 0 + 0 * 1 + 2 * (-1) + 1 * (-1) = - 3
Salida del kernel de convolución o[0,0,1] = > primer elemento + segundo elemento + tercer elemento + b0 = (-3) + 0 + (-3) + 1 = -5
Luego deslice la imagen de entrada con este tamaño de ventana del núcleo de convolución y convolucione para obtener el resultado, porque hay dos núcleos de convolución, por lo que hay dos resultados de salida.
Los amigos aquí pueden tener una pregunta, ¿cómo obtener la ventana de salida?
Aquí hay una fórmula: ancho de la ventana de salida w = (ancho de la ventana de entrada w - ancho del kernel de convolución w + 2 * pad)/zancada + 1, altura de salida h = ancho de la ventana de salida w
Tomando el ejemplo anterior, el ancho de la ventana de salida w = (5 - 3 + 2 * 1)/2 + 1 = 3, entonces el tamaño de la ventana de salida es 3 * 3, porque hay 2 salidas, entonces es 3 3 2 .

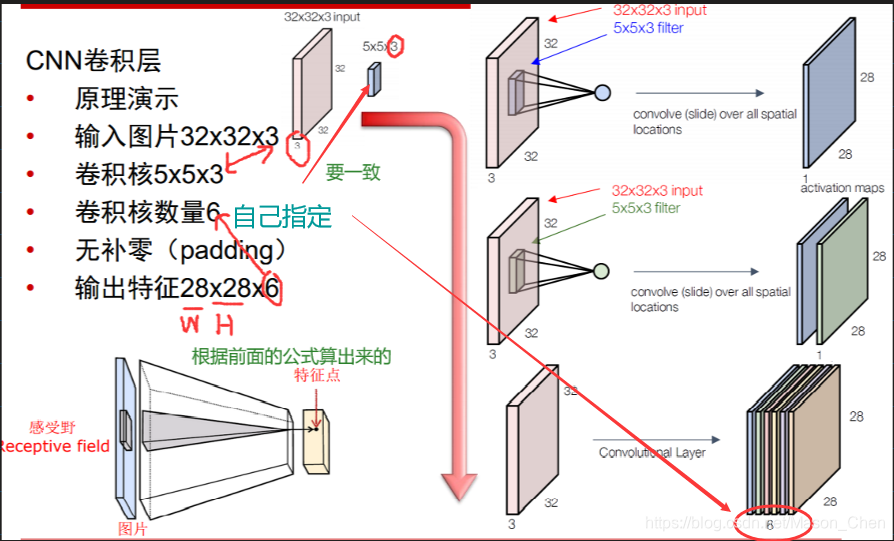
Un campo de visión receptivo tiene un núcleo de convolución. Nos referimos a la matriz de peso w en el campo de visión receptivo como el núcleo de convolución; el intervalo de exploración del campo de visión receptivo a la entrada se denomina zancada; cuando el tamaño del paso es relativamente grande (paso> 1) Para escanear algunas características del borde, el campo de visión puede estar "fuera de los límites". En este caso, se requiere la expansión del límite (almohadilla), y la expansión del límite se puede configurar en 0 u otros valores. El tamaño del paso y los valores de expansión de los límites son definidos por el usuario.
El usuario define el tamaño del kernel de convolución, es decir, el tamaño del campo de visión definido, el valor de la matriz de peso del kernel de convolución es el parámetro de la red neuronal convolucional. , el kernel de convolución se puede adjuntar con una Transposición compensada b, sus valores iniciales se pueden generar aleatoriamente y se pueden cambiar a través del entrenamiento.
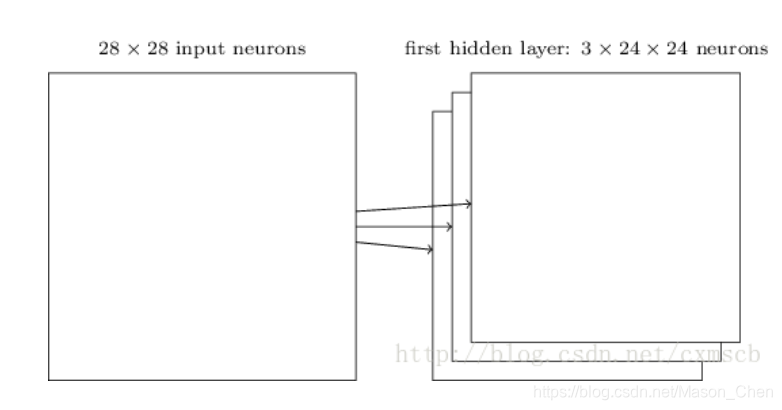
Llamamos a la siguiente capa de matriz de neuronas generada al escanear el campo de visión sensorial con un núcleo de convolución como un mapa de características (mapa de características). Los núcleos de convolución
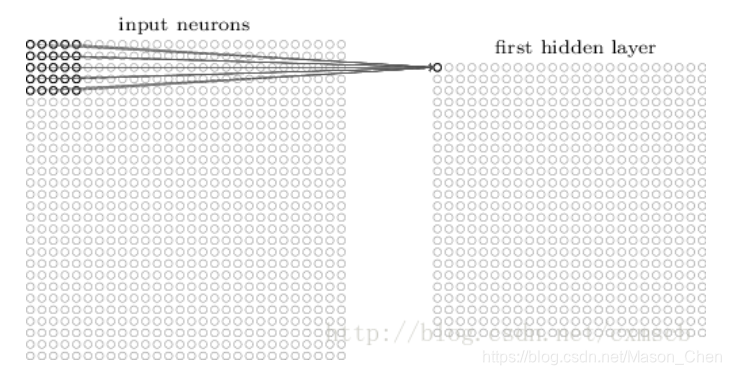
utilizados por las neuronas en el mismo mapa de características son los mismos, por lo que estas neuronas comparten pesos, compartiendo los pesos en el kernel de convolución y las compensaciones que lo acompañan. Un mapa de características corresponde a un núcleo de convolución.Si usamos 3 núcleos de convolución diferentes, podemos generar 3 mapas de características: (campo receptivo: 5 × 5, zancada: 1)
1.3 Capa de incentivos
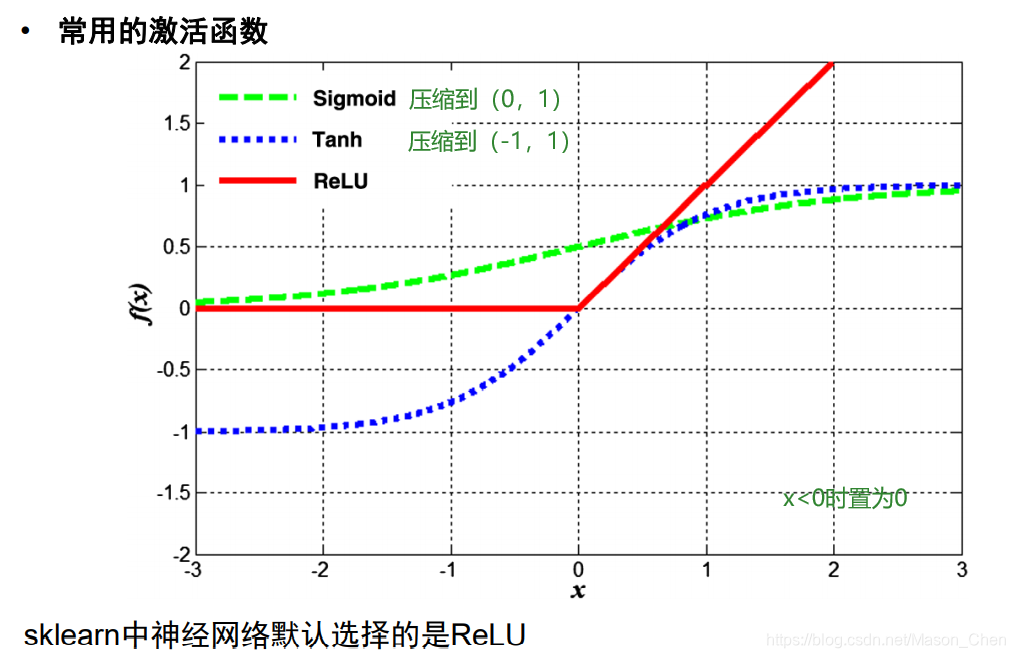
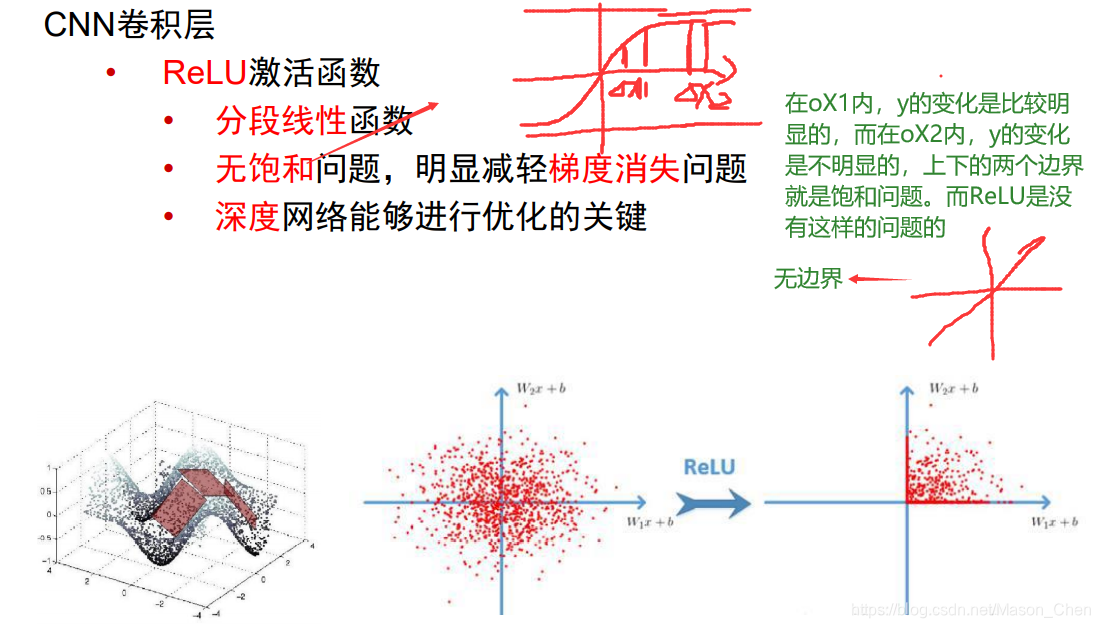
La capa de excitación realiza principalmente un mapeo no lineal en la salida de la capa convolucional, porque el cálculo de la capa convolucional sigue siendo un cálculo lineal. La función de activación utilizada es generalmente la función ReLu.
- ¿Por qué usar la función ReLU?
Se puede ver a partir de y = w * x + b que si no se usa la función de activación, la salida de cada capa de red es una salida lineal, y la escena real en la que nos encontramos es en realidad más una variedad de distribuciones no lineales.
Esto también muestra que la función de la función de activación es transformar la distribución lineal en una distribución no lineal, que puede estar más cerca de nuestra escena real.
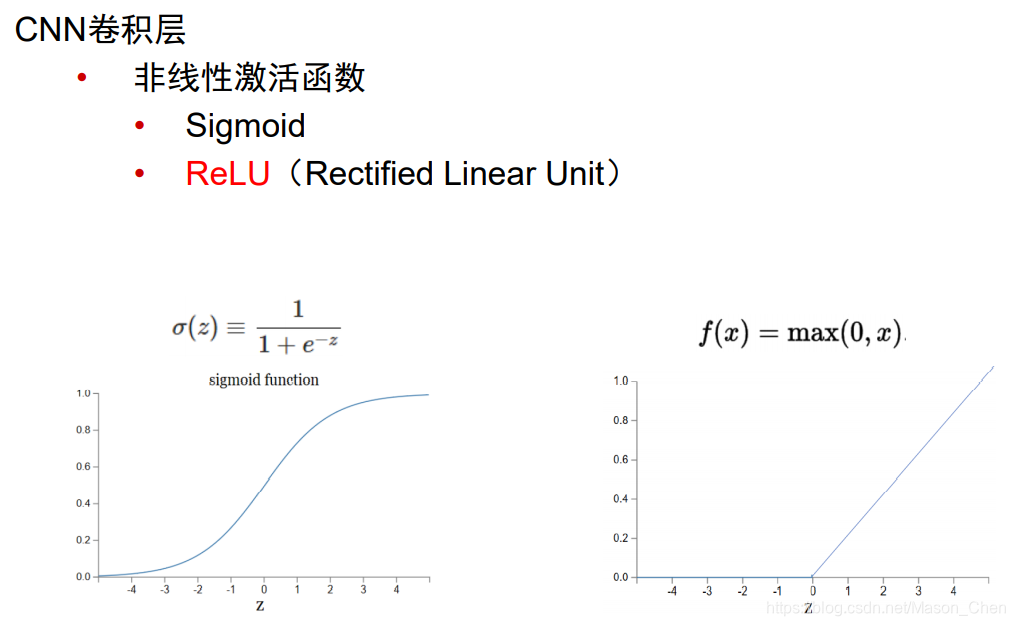
- ¿Por qué usar la función ReLU en lugar de la función sigmoidea?
Cuando son x ->, la salida se convierte en un valor constante, porque al encontrar el gradiente se necesita obtener la derivada parcial de primer orden de la función, y ya sea sigmoide o tanhx, sus derivadas parciales son 0, es decir, existe un llamado gradiente. El problema de la desaparición eventualmente hará que los parámetros de peso w y b no se actualicen. Por el contrario, Relu no tiene ese problema. Además, cuando x > 0, la derivación de Relu = 1, lo que puede simplificar enormemente el cálculo de dw y db para retropropagación.
El uso de sigmoid también tiene el problema de la explosión del gradiente. Por ejemplo, en el caso de una gran cantidad de iteraciones de propagación hacia adelante y hacia atrás, debido a que sigmoid es una función exponencial, algunos valores en el resultado se acumularán en las iteraciones y se convertirán en crece exponencialmente, lo que eventualmente conduce a NaN y desbordamiento.
1.4 Capa de agrupación
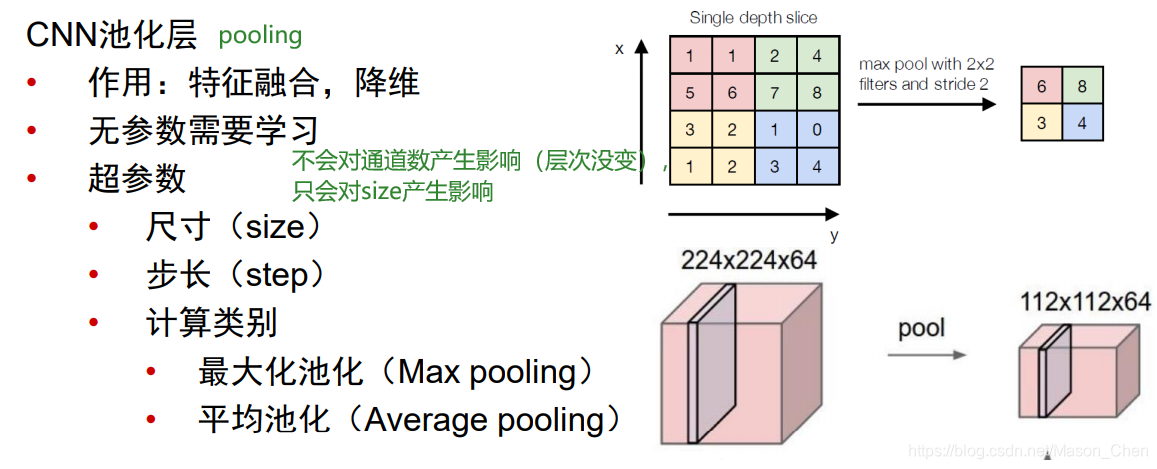
La capa de agrupación generalmente está después de la capa convolucional + Relu, y su función es:
1. Reduzca el tamaño de la matriz de entrada (solo ancho y alto, no profundidad) y extraiga las características principales. (Es innegable que después de la agrupación, las funciones tendrán una cierta pérdida, por lo que algunos modelos clásicos han eliminado la capa de agrupación).
Su finalidad es obvia, que es reducir los cálculos en operaciones posteriores.
2. En general, se utilizan mean_pooling (agrupación media) y max_pooling (agrupación máxima).Hay traducción (traslación) y rotación (rotación) para la matriz de entrada, lo que puede garantizar la invariancia de las características.
mean_pooling es para calcular el valor promedio del área de agrupación de la matriz de entrada. Cabe señalar aquí que el tamaño de paso de la ventana de agrupación que se desliza en la matriz de entrada está relacionado con la zancada. Generalmente, zancada = 2. max_pooling agrupación máxima es
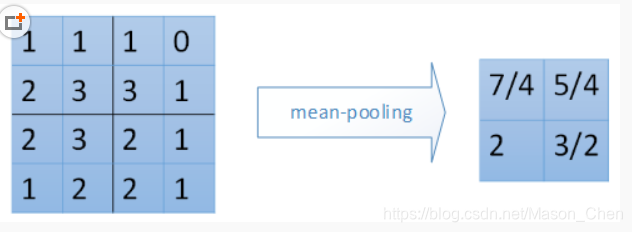
el valor máximo de cada área de agrupación en la posición de salida correspondiente.
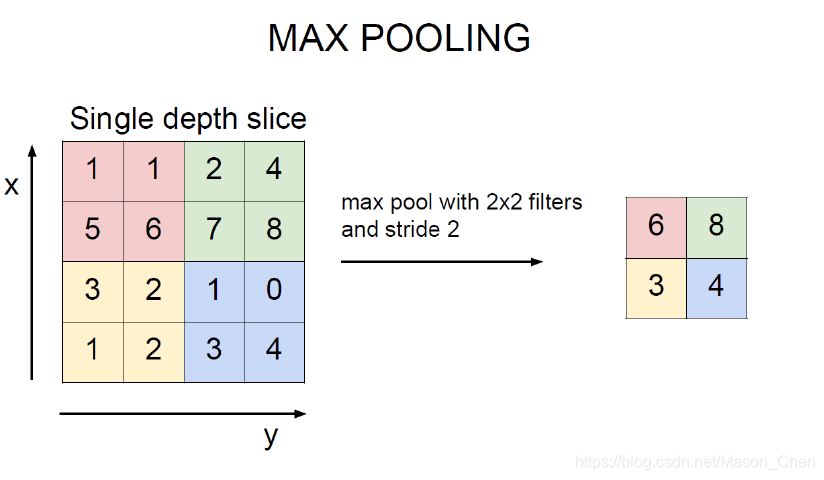
1.4 Capa completamente conectada
La capa completamente conectada reajusta principalmente las características para reducir la pérdida de información de características; la capa de salida está principalmente lista para generar el resultado objetivo final. Por ejemplo, el diagrama de estructura de VGG se muestra en la siguiente figura:
1.5 Capa de normalización
- Normalización por lotes
La normalización por lotes (normalización por lotes) realiza la operación de preprocesamiento en el medio de la capa de la red neuronal, es decir, la entrada de la capa anterior se normaliza antes de ingresar a la siguiente capa de la red, lo que puede prevenir efectivamente la "dispersión de gradiente", para acelerar el entrenamiento de la red.
El algoritmo específico de normalización por lotes se muestra en la siguiente figura:

cada vez que se entrena, se toman muestras de tamaño de lote para el entrenamiento. En la capa BN, una neurona se considera una característica, y las muestras de tamaño de lote tendrán valores de tamaño de lote en un determinada dimensión característica. , y luego llevar a cabo la media y la varianza de estas muestras en la dimensión xi de cada neurona, obtener xi∧ a través de la fórmula, y luego realizar un mapeo lineal a través de los parámetros γ y β para obtener la salida correspondiente yi de cada neurona. En la capa BN, se puede ver que cada dimensión de la neurona tiene un parámetro γ y β, que se pueden optimizar a través del entrenamiento al igual que el peso w.
Cuando la normalización por lotes se realiza en una red neuronal convolucional, el mapa de características que no ha sido activado por ReLu generalmente se normaliza por lotes, y la salida se usa como entrada de la capa de excitación, que puede lograr el efecto de ajustar el parcial. derivada de la función de excitación.
Un enfoque es utilizar las neuronas en el mapa de funciones como la dimensión de la función, y la suma de los parámetros γ y β es igual a 2 × fmapwidth×fmaplength×fmapnum, por lo que la cantidad de parámetros será mucho;
Otro enfoque es considerar un mapa de características como una dimensión de características. Las neuronas en un mapa de características comparten los parámetros γ y β de este mapa de características. La suma de los parámetros γ y β es igual a 2 × fmapnum, y la media y la varianza se calculan como la media y la varianza de cada dimensión del mapa de características en muestras de entrenamiento de tamaño de lote.
Nota: fmapnum se refiere al número de mapas de características de una muestra, y los mapas de características tienen un cierto orden como las neuronas.
La diferencia entre el proceso de entrenamiento y el proceso de prueba del algoritmo de normalización por lotes:
Durante el proceso de entrenamiento, colocaremos el número de tamaño de lote de muestras de entrenamiento en la red CNN para entrenar cada vez, y la media y la varianza requeridas para calcular la salida se pueden obtener naturalmente en la capa BN;
En el proceso de prueba, a menudo solo ingresamos una muestra de prueba en la red CNN, lo que significa que la media y la varianza calculadas en la capa BN serán 0, porque solo hay una entrada de muestra, por lo que la entrada de la capa BN también será parecen muy grandes El problema, que conduce a errores en la salida de la red CNN. Por lo tanto, en el proceso de prueba, necesitamos usar la media y la varianza de cada dimensión cuando todas las muestras en el conjunto de entrenamiento están normalizadas en la capa BN. Por supuesto, para facilitar el cálculo, podemos normalizar cada lote_num veces en el BN. capa Al normalizar, agregue la media y la varianza de cada dimensión, y finalmente calcule la media nuevamente.
- Normalización de respuesta local
El método de normalización de Normalización de respuesta local ocurre principalmente entre las salidas de diferentes núcleos de convolución adyacentes (después de ReLu), es decir, la entrada ocurre en diferentes mapas de características después de ReLu.
La fórmula de LRN es la siguiente:
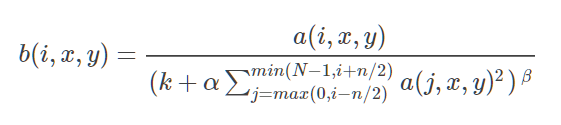
Entre ellos:
a(i,x,y) representa el valor en la posición (x, y) en el mapa de características de la salida del i-ésimo kernel de convolución (a través de la capa ReLu).
b(i,x,y) representa la salida de a(i,x,y) después de LRN.
N representa el número de núcleos de convolución, es decir, el número de mapas de características de entrada.
n representa el número de núcleos de convolución (o mapas de características) de los vecinos, que es determinado por uno mismo.
k, α, β son hiperparámetros, que son ajustados o determinados por el usuario.
La diferencia con BN: BN se basa en los datos del mini lote, y la normalización vecina solo necesita ser determinada por sí mismo. Hay parámetros de aprendizaje en el entrenamiento de BN; la normalización de BN ocurre principalmente entre diferentes muestras, y la normalización de LRN ocurre principalmente entre diferentes muestras Entre la salida del núcleo de convolución.
2. Escenarios de aplicación de CNN
La aplicación de la red neuronal convolucional no es insignificante.Hay dos categorías principales, predicción de datos y procesamiento de imágenes. Naturalmente, no hay necesidad de decir más sobre la predicción de datos, el procesamiento de imágenes incluye principalmente aplicaciones en clasificación, detección, reconocimiento y segmentación de imágenes.
-
Clasificación de imágenes: clasificación de escenas, clasificación de objetos
-
Detección de imágenes: detección de prominencia, detección de objetos, detección semántica, etc.
-
Reconocimiento de imágenes: reconocimiento facial, reconocimiento de caracteres, reconocimiento de matrículas, reconocimiento de comportamiento, reconocimiento de marcha, etc.
-
Segmentación de imágenes: Segmentación en primer plano, Segmentación semántica
referencia: